- The paper introduces an automated framework that evaluates LLM-generated patches against real commit tasks in open-source C projects.
- Static and dynamic analyses reveal significant challenges in code generation as file and function sizes increase and bug fixes prove more complex than feature enhancements.
- Empirical results show limited success in producing compilable and functionally correct patches, underlining key scalability and context sensitivity issues with current LLMs.
Assessing LLMs as Code Contributors: An In-depth Evaluation on Open-source C Projects
Introduction
This paper presents a rigorous empirical analysis of modern LLMs' capacity to serve as autonomous code contributors to substantial open-source C projects, with a particular focus on real-world commit tasks such as bug fixes and feature enhancements. The study targets three prominent LLMs—GPT-4o (cloud-based), Ministral3-14B, and Qwen3-Coder-30B (local)—across eight large and diverse open-source projects (e.g., FFmpeg, wolfSSL, jansson). The methodology combines automated static and dynamic verification pipelines, as well as manual inspection, to provide a comprehensive understanding of current LLMs’ strengths, limitations, and error modes in realistic software evolution scenarios.
Methodology and Experimental Framework
The research introduces a fully automated framework for evaluating LLM-prompted code generation against actual historical project commits, emphasizing two main axes: verification via static analysis and validation via execution of project test suites.
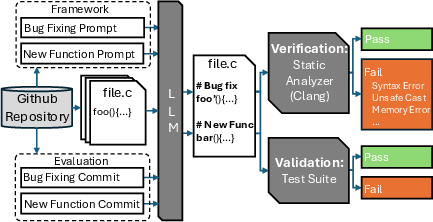
Figure 2: The framework evaluates whether an LLM, when prompted with a commit message and relevant code context, can produce a high-quality, verifiable patch satisfying real-world constraints.
Commits were selected with strict criteria to ensure relevance, diversity, and manageable complexity:
- Single-file/single-function changes,
- Well-formed commit messages,
- Coverage of both common C errors (e.g., null pointer dereferences, use-after-free) and intricate, project-specific issues.
Three LLMs with varying parameter scales and deployment models (API/local) were used, and both syntactic correctness (compilability) and behavioral correctness (test suite pass rates) were assessed, supplemented with manual code audits for patches where automated checks were inconclusive.
Empirical Results: Static and Dynamic Verification
The quantitative findings show that while LLMs achieve passing rates on certain tasks—especially when project and problem scales are smaller—the overall robustness, correctness, and reliability of generated patches remain limited in realistic open-source maintenance contexts.
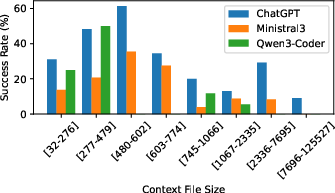
Figure 4: LLM-generated patch success rates degrade notably as the context file size (in LOC) increases, with a marked decline beyond moderate file sizes.
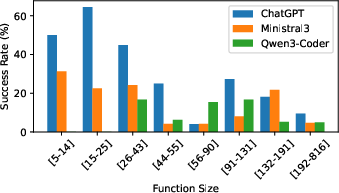
Figure 6: Similarly, function size directly impacts LLM performance, displaying severe success rate drop-offs when task-relevant functions are large.
Key numerical results and observations include:
- Code generation fails to compile for up to 32 out of 212 tasks, depending on LLM.
- Among tasks where code compiles, static analysis uncovers 9–18 null pointer dereferences, and up to 72 unsafe casts for certain models; undeclared identifiers are a frequent source of errors.
- Even after passing static analysis, LLMs frequently fail project test suites, primarily due to partial fixes, empty patches, or modifications unrelated to the commit goals.
- Manual inspection reveals that success rates for producing functionally correct patches vary drastically by project and task type, ranging from 0% to 60%, with high rates only for small, familiar, and non-buggy code contexts.
- Context sensitivity is significant: larger files and functions severely degrade LLM performance, and unknown (post-cutoff) commit tasks yield markedly lower success rates.
- Feature additions have higher LLM success rates compared to bug fixes, despite the former having higher median LOC per change.
Detailed Failure Taxonomy and Examples
A comprehensive breakdown of failure modes shows that LLM models, including state-of-the-art, are susceptible to both shallow and deep issues:
- Generation of syntactically invalid or uncompilable code due to hallucinated APIs, missing variable declarations, or broken control flow.
- Semantic errors such as unsafe casts, undetected null dereferences, and free-related vulnerabilities (double or use-after-free).
- "Silent" failures, where the patch superficially passes tests but does not address the actual defect—often due to incomplete or irrelevant code changes in the absence of strong associated test cases.
- LLMs frequently output empty or duplicate code when context is large or when training data may contain overlapping artifacts (raising concerns about model memorization and data poisoning).
Empirical analysis further establishes that the length and completeness of prompt/context are double-edged: minimal context starves the model, but larger inputs overwhelm its reasoning capabilities, leading to increased failure rates.
Implications for Practical and Theoretical Software Evolution
The findings underscore critical limitations for using current-generation LLMs in nontrivial software maintenance or feature development on production-scale code:
- Scaling remains the core bottleneck: LLM code quality degrades rapidly as task and codebase size increases, establishing sharp practical ceilings for their autonomous use.
- Task type sensitivity: LLMs are distinctly more effective at implementing new, isolated features than at diagnosing and repairing location-dependent bugs, contradicting expectations around their “few-shot” adaptability.
- Vulnerability to data leakage and memorization: Evidence of parroted code and false citations points to significant risks associated with LLM training on open-source corpora with incomplete or contaminated histories.
- Static and dynamic analysis are necessary but insufficient: Many errors slip past both verification and test suites if developer-supplied coverage is limited or not tailored to the induced changes, suggesting that LLM outputs should always be subject to extensive manual scrutiny in real development pipelines.
- Model size and deployment tradeoffs: While larger, proprietary cloud models (e.g., GPT-4o) outperform local, smaller models, they still fall short on complex, unseen, or context-rich engineering tasks. Local models lag sharply in correctness as project specificity increases.
Recommendations and Future Directions
To enhance LLM integration for practical code contribution, the following are recommended:
- Keep context file (< 600 LOC) and function sizes (< 60 LOC) as small as possible for each LLM session.
- Use the largest available model for nontrivial generating or fixing tasks; smaller models are better suited for routine, transparent edits.
- Apply stricter review and testing to LLM outputs, especially for tasks postdating the model’s training cutoff, and for all bug-fix-related changes.
- Augment verification with coverage-guided test case evolution, and explore research in test suite generation targeted specifically at LLM-generated patches.
- Investigate architectural modifications or cascaded prompting strategies to improve scaling and context-handling robustness—possibly integrating retrieval-augmented mechanisms or fine-tuned context selection layers.
Theoretically, the persistent shortfall of LLMs on unseen, large-context, and integration-heavy tasks motivates deeper research into model architectures that marry token-level prediction with explicit symbolic/program analysis and modularity. Research should also more systematically investigate model memorization, data contamination, and context representation effects on code generalization.
Conclusion
LLMs are not currently effective as reliable code contributors for large, real-world open-source C projects, particularly for bug-fixing scenarios or code evolution in unknown or large contexts. While they attain moderate success for isolated, “seen” tasks involving feature additions or trivial patches, the error modes, context sensitivity, and brittleness exposed in this study demand significant improvements in model design, verification strategy, and human-in-the-loop processes before LLMs can be truly trusted in production workflows. The presented evaluation framework provides a strong basis for future research and benchmarking of advancements in this area.