- The paper demonstrates that fine-tuned LLMs produce code with significantly fewer high-severity issues compared to human-written solutions.
- It employs comprehensive statistical analysis and SonarQube to assess code quality across three difficulty levels in a curated Python dataset.
- The findings reveal that while LLM-generated code generally requires less bug-fix effort, challenges remain in complex, competition-level tasks.
Comparative Analysis of Maintainability and Reliability in LLM-Generated vs. Human-Written Code
Introduction
This paper presents a rigorous empirical evaluation of code quality attributes—specifically maintainability and reliability—of code generated by LLMs compared to human-written code. The study leverages a comprehensive infrastructure integrating SonarQube for static analysis, a curated Python code dataset spanning three difficulty levels, and multiple LLM prompting strategies (zero-shot, few-shot, and fine-tuning). The central research question addresses whether LLM-generated code is more maintainable and reliable than human-written code, with a focus on quantifiable metrics and the effort required to resolve code issues.
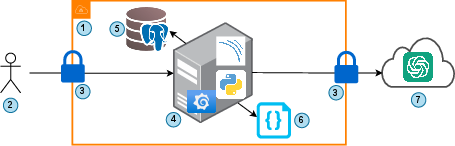
Figure 1: Overview of the experimentation architecture, illustrating the integration of LLMs, SonarQube, and database management for systematic code quality analysis.
Experimental Design and Workflow
The experimentation pipeline is built on a secure Linux VM, orchestrating code generation via the GPT-4o API, dataset management in PostgreSQL, and code quality assessment through SonarQube. The workflow encompasses the following stages: dataset curation, LLM code generation (using zero-shot, few-shot, and fine-tuned models), static analysis, and statistical comparison.

Figure 2: Overview of the experimentation workflow, detailing the sequential process from dataset ingestion to code quality evaluation.
The dataset comprises 10,000 Python coding problems and solutions, categorized into introductory, interview, and competition levels. Human-written solutions are sourced from established coding platforms, ensuring a robust baseline for comparison. LLM-generated solutions are produced for each problem using three distinct prompting strategies, enabling a granular analysis of prompt engineering effects on code quality.

Figure 3: Example of a coding question and its corresponding solution, illustrating the format and complexity of the dataset.
Code Quality Metrics and Statistical Analysis
SonarQube is employed to assess code quality across four datasets (human, zero-shot, few-shot, fine-tuned), focusing on bugs (reliability), code smells (maintainability), and estimated effort to fix issues. Severity levels (blocker, critical, major, minor) are used to stratify issue impact. Statistical tests (Mann-Whitney U, Cliff's delta, Odds Ratio) quantify differences in issue prevalence and effort across strategies and difficulty levels.
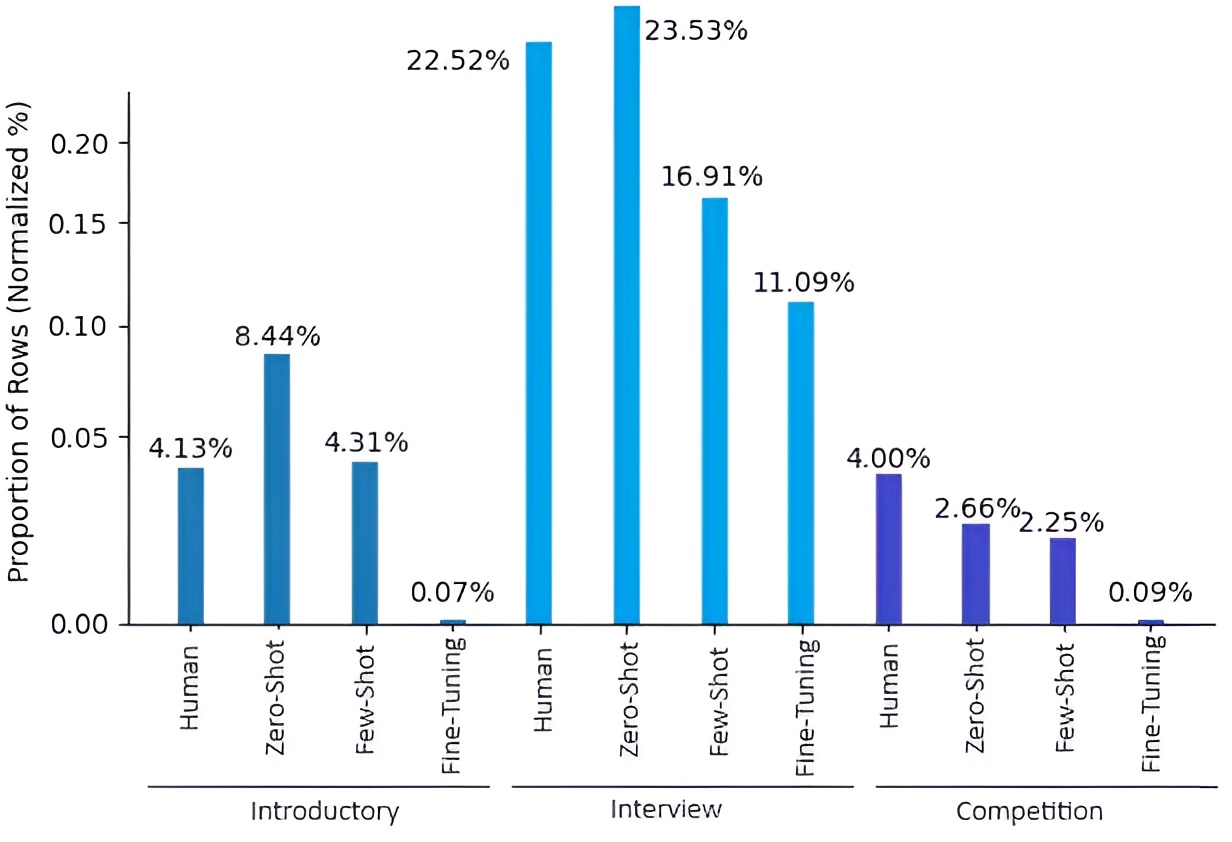
Figure 4: Normalized percentage of issues per dataset, highlighting the distribution of code quality problems across human and LLM-generated solutions.
Results
Issue Prevalence and Severity
LLM-generated code, particularly from fine-tuned models, exhibits a lower overall issue rate compared to human-written code, especially for introductory and interview-level problems. Fine-tuning effectively reduces high-severity issues (blocker, critical) and shifts them to minor categories. However, in competition-level tasks, LLMs occasionally introduce structural critical issues absent in human solutions.
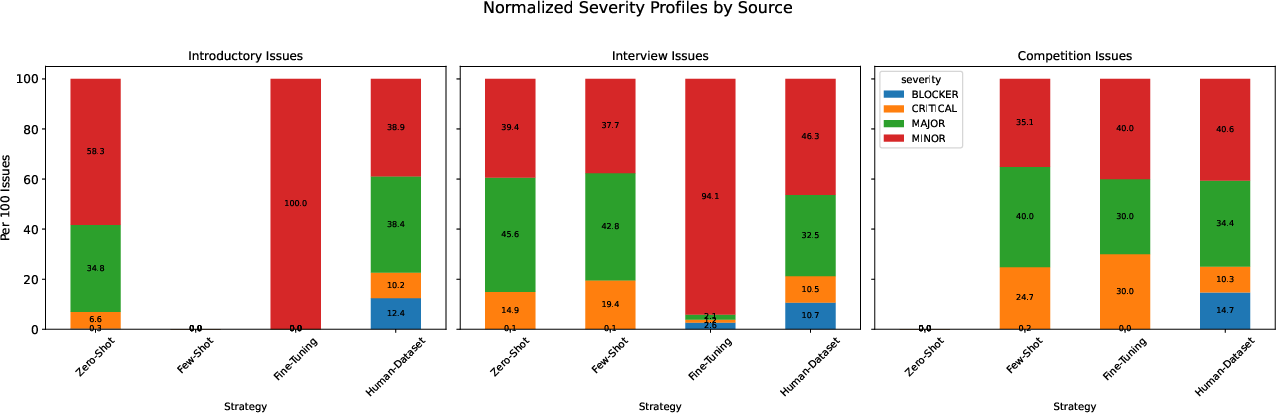
Figure 5: Normalized issues per dataset, stratified by severity and difficulty level, demonstrating the impact of prompting strategy on code quality.
Statistical analysis reveals that the odds of encountering bugs in LLM-generated code are significantly lower than in human-written code (Odds Ratio ≤0.19% for reliability). For maintainability (code smells), LLMs outperform humans in complex tasks, though zero-shot approaches may introduce more code smells in simpler problems.
Effort to Fix Issues
SonarQube's effort estimates indicate that LLM-generated code generally requires less time to fix issues than human-written code for introductory and interview-level tasks. This advantage diminishes for competition-level problems, where the complexity of issues increases.
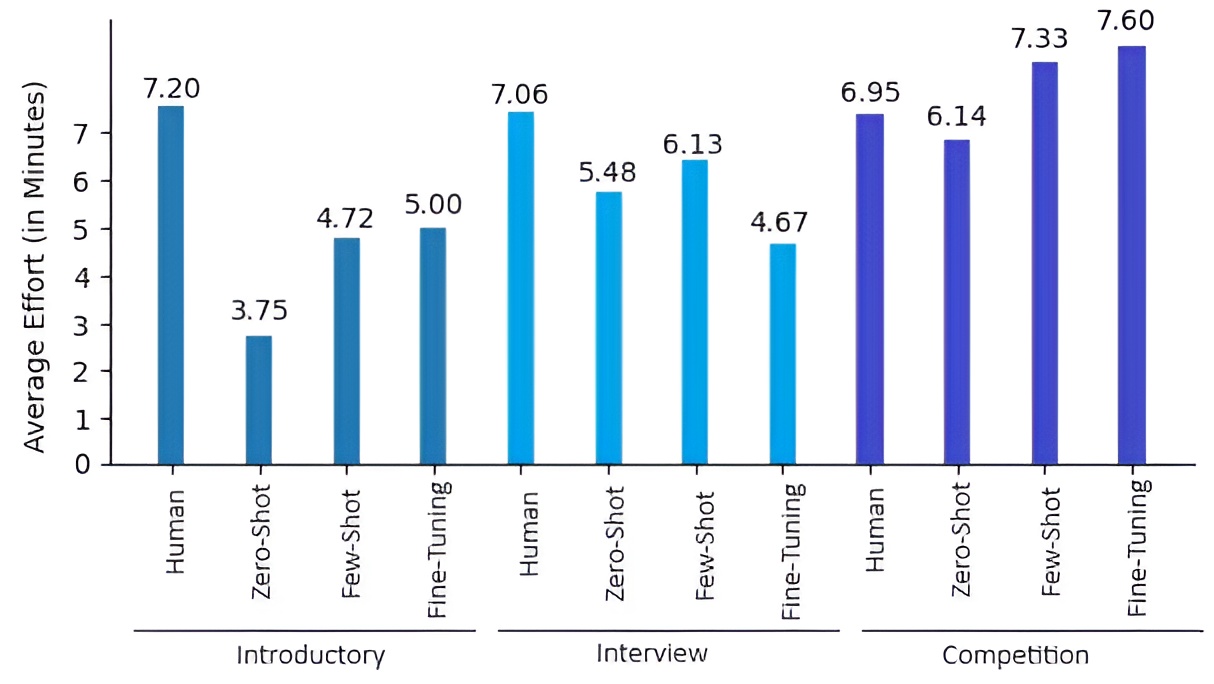
Figure 6: Average effort in minutes to fix bugs or code smells, comparing human and LLM-generated code across task categories.
Pass@1 accuracy is highest for human-written solutions (1.0), with few-shot LLM prompting outperforming zero-shot and fine-tuned models (0.87 vs. 0.53 and 0.47, respectively). Fine-tuned models, despite superior quality metrics, struggle with complex problems, often failing test cases or introducing runtime errors.
Discussion
The findings demonstrate that LLMs, especially when fine-tuned, can generate code with fewer high-severity issues and reduced effort for bug resolution in less complex scenarios. However, the introduction of critical structural issues in competition-level tasks and the lower Pass@1 performance of fine-tuned models highlight limitations in current LLM capabilities. The trade-off between maintainability and reliability is evident: LLMs excel at reducing functional bugs but may not fully address structural code quality concerns.
The study underscores the importance of systematic evaluation and validation of LLM-generated code, particularly in production and educational contexts. The experimental infrastructure and methodology provide a replicable framework for future research and industry adoption.
Implications and Future Directions
Practically, the results suggest that LLMs can be leveraged to automate code generation and refactoring in educational and professional settings, with fine-tuning offering substantial improvements in code quality. However, careful validation is required for complex tasks to mitigate the risk of critical issues. Theoretically, the study advances understanding of the strengths and limitations of LLMs in software engineering, informing the development of more robust quality assessment frameworks.
Future research should explore advanced fine-tuning strategies (e.g., PEFT, RAG), expand analyses to additional programming languages, and investigate the relationship between code quality metrics and real-world developer effort. Integrating performance testing and ethical considerations into the evaluation pipeline will further support the responsible adoption of LLMs in software engineering.
Conclusion
This study provides a comprehensive comparative analysis of maintainability and reliability in LLM-generated versus human-written code. LLMs, particularly when fine-tuned, reduce high-severity issues and effort required for bug resolution in simpler tasks, but face challenges in complex scenarios. The results inform best practices for integrating LLMs into software development workflows and highlight avenues for future research in AI-assisted code generation and quality assurance.