- The paper demonstrates that ensemble-based ML models, particularly Random Forest with SMOTE, significantly enhance anomaly detection in Zero Trust IoT networks.
- It details a methodology using supervised learning on the KDD Cup 1999 dataset to effectively mitigate class imbalance and detect advanced cyber threats.
- Results show high test accuracy and reduced false negatives, reinforcing ML-driven contextual risk scoring as vital for robust IoT cybersecurity.
Advanced Anomaly Detection and Threat Intelligence for Zero Trust IoT with Machine Learning
Introduction
The proliferation of Internet of Things (IoT) devices, accompanied by increasingly dynamic network architectures, necessitates robust and adaptive security frameworks. Traditional perimeter-centric approaches are increasingly inadequate in the face of distributed, heterogeneous IoT deployments, especially given the sophistication and persistence of advanced cyber threats such as Advanced Persistent Threats (APTs). This paper systematically investigates the deployment of supervised ML models within a Zero Trust Security (ZTS) framework to enhance both anomaly detection and cyber threat intelligence in IoT environments (2604.23332).
Key contributions encompass the use of Decision Tree (DT), Random Forest (RF), and Support Vector Machine (SVM) classifiers, explicit management of class imbalance through the Synthetic Minority Oversampling Technique (SMOTE), and integration of these techniques into the context of actionable threat intelligence under ZTS paradigms. The research utilizes the KDD Cup 1999 benchmark dataset to facilitate rigorous, reproducible comparative analyses.
IoT systems introduce unique challenges for security due to device heterogeneity, limited computational resources, and expanded attack surfaces. APTs and sophisticated network-level attacks, in particular, are characterized by unobtrusive, multi-stage signatures that blend seamlessly with legitimate traffic. Traditional security mechanisms fail to detect such anomalies reliably, resulting in high false negative rates and unacceptable operational risk.
ZTS provides a conceptual foundation for ensuring that no implicit trust is assigned to any device or network segment. However, practical realization of ZTS for IoT depends on the ability to continuously assess device and session risk through context-aware detection of deviations from normative behavioral baselines. Machine learning models, especially those resistant to overfitting and capable of handling high-dimensional data, emerge as necessary components for achieving these aims.
Methodology
The experimental design focuses on supervised anomaly detection leveraging labeled network flow data from the KDD Cup 1999 dataset. Data preprocessing includes elimination of corrupted/duplicate records, categorical encoding, and feature scaling where necessary. Critically, class imbalance—ubiquitous in intrusion datasets—was mitigated through SMOTE, ensuring minority-class representation in the training process.
Model selection is motivated as follows:
- Decision Tree (DT): Provides high interpretability but prone to variance.
- Random Forest (RF): Ensemble-based, offering variance reduction and robust feature importance estimation.
- Support Vector Machine (SVM): Effective for binary classification in high-dimensional feature spaces, though kernel and parameter selection are crucial.
For reference, deep neural networks and RNNs were also implemented but served primarily for comparative analysis, given that RNNs are less suitable for non-sequential, tabular data common in network flows.
Performance metrics include overall accuracy, F1-score, precision, and recall—with particular emphasis on weighted F1-score to gauge performance on minority (attack) classes. All experiments adhered to rigorous train–test splits and cross-validation protocols.
Results
Random Forest with SMOTE decisively outperformed all alternative models in both test accuracy and F1-score, achieving 99.69% test accuracy and a near-equivalent F1-score. This is a direct consequence of both the ensemble's robustness and the class rebalancing effect of SMOTE. Decision Trees yielded comparable, though slightly lower, test score and were more susceptible to overfitting. SVMs, while stable, underperformed relative to tree-based ensembles—particularly in multiclass and imbalanced regimes.
The quantitative superiority of Random Forest with SMOTE is evident in the performance comparison between models. Notably, RNNs demonstrated extremely poor F1-score, confirming the inappropriateness of sequence models when temporal structure is absent or poorly represented. Deep learning models achieved high accuracy but did not surpass the ensemble tree baseline on structured tabular data.
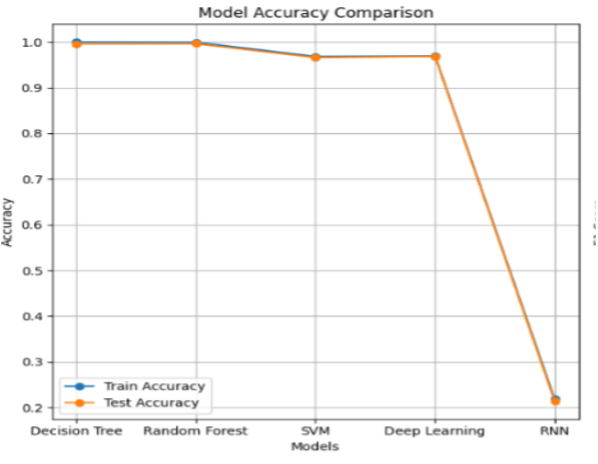
Figure 1: Train vs Test accuracy of DT, RF, SVM, deep learning, and RNN models. RF with SMOTE achieves the highest test accuracy and lowest generalization gap.
Importantly, the application of SMOTE reduced the generalization gap (i.e., overfitting), especially for Random Forest, and significantly improved detection rates of minority attack classes, thereby reducing false negatives—a critical consideration for operational security deployments.
Discussion
Implications for Zero Trust and IoT Security
The findings substantiate that ensemble-based tree models, when combined with systematic class rebalancing (SMOTE), are highly effective for anomaly detection in IoT-like networks under Zero Trust requirements. The results strengthen the argument for ML-powered contextual risk scoring as an integral element of ZTS, enabling continuous and adaptive verification at both the device and flows levels. This is particularly salient in IoT deployments, where perimeter-based trust models fail due to scale, heterogeneity, and the distributed nature of network contexts.
Explicitly, the precision and recall improvements delivered by Random Forest (with SMOTE) satisfy ZTS demands for actionable intelligence, low false positive rates, and scalable learning in the face of novel threats and nonstationary environments. The methodology accommodates integration into distributed security operations—centralized SOC pipelines, gateway-based filtering at network edges, or federated learning deployments aligned with IoT constraints.
Strengths, Limitations, and Future Work
The explicit incorporation of class imbalance remediation in the evaluation pipeline is a methodological strength, as reliance on accuracy alone is misleading in intrusion detection. The comprehensive benchmarking against deep and traditional models further validates the selection of model architectures.
A noted limitation is the continued reliance on the KDD Cup 1999 dataset, which, while standard, does not necessarily capture modern encrypted and multi-protocol IoT telemetry. This suggests a need for future work involving up-to-date IoT traffic datasets, online learning scenarios, and lightweight model compression/pruning for deployment on constrained devices.
Future directions include:
- Extension to online and federated learning schemes for distributed IoT.
- Integration of explainability techniques (e.g., SHAP, LIME) for operational trust and compliance.
- Evaluation under adversarial conditions and with encrypted traffic patterns.
- Deployment-focused research for efficient inference on edge hardware.
Conclusion
The paper provides compelling evidence that supervised, ensemble-based machine learning models—especially Random Forest with class rebalancing via SMOTE—deliver highly accurate and robust anomaly detection in Zero Trust IoT environments. Interpretability, scalability, and reduced false negative rates position these models as foundational components for adaptive, context-aware threat intelligence platforms. Addressing dataset limitations and extending evaluations to live, heterogeneous IoT environments remain important future steps. Ensemble models augmented by informed data engineering and explainability are essential for effective and sustainable deployment in the evolving landscape of IoT cybersecurity.

