- The paper introduces the first fully reproducible full-duplex system for Hindi by adapting the Moshi architecture with a custom Hindi tokeniser, effectively handling overlaps and natural dialogue dynamics.
- The methodology leverages 26,000 hours of stereo conversational data and a hierarchical RQ-Transformer, achieving optimal convergence at around 4,812 training steps.
- Human evaluations highlight near-human naturalness and high conversational interactivity, setting a new benchmark for dialogue systems in resource-scarce languages.
Human-1: Full-Duplex Conversational Modeling in Hindi
Motivation and Contributions
"Human-1 by Josh Talks: A Full-Duplex Conversational Modeling Framework in Hindi using Real-World Conversations" (2604.23295) systematically addresses the lack of full-duplex spoken dialogue systems for Indian languages by adapting the Moshi architecture to Hindi. Leveraging a new, large-scale corpus of real, spontaneous, stereo Hindi conversations, the authors overcome critical limitations in tokenisation, training dynamics, and conversational data collection. Their methodology establishes the first fully reproducible open full-duplex architecture for Hindi, enabling sophisticated modeling of interruptions, backchannels, and overlaps inherent to natural human dialogue.
System Architecture and Language Adaptation Strategies
The framework is based on Moshi, integrating the Mimi neural audio codec and a hierarchical RQ-Transformer comprising Temporal and Depth Transformers. The key technical adaptation involves replacing the original English SentencePiece tokeniser with a Hindi variant trained on Devanagari corpus, requiring reinitialisation of all vocabulary-dependent parameters. Pre-trained audio weights are retained, but text embeddings and projection layers are trained from scratch, shifting the paradigm from standard fine-tuning to partial pre-training.
Massive spontaneous conversational data (26,000 hours from 14,695 unique speakers, recorded in stereo for each participant) is collected, notably avoiding artifacts from artificial diarisation or synthetic turn-taking. The curated training set ensures signal quality and conversational naturalness, essential for turn-taking and overlap modeling.
Training Dynamics
Pre-training is conducted with learning rate and batch size settings aligned to original Moshi architecture, utilizing 8×NVIDIA H100 GPUs. The authors provide detailed analysis of the convergence behavior of text and audio token streams, noting rapid loss reduction and plateau within 2,000–4,000 steps. Text accuracy stabilizes at ≈70% (non-PAD tokens), and audio accuracy reaches 48–53% (all codebook layers).
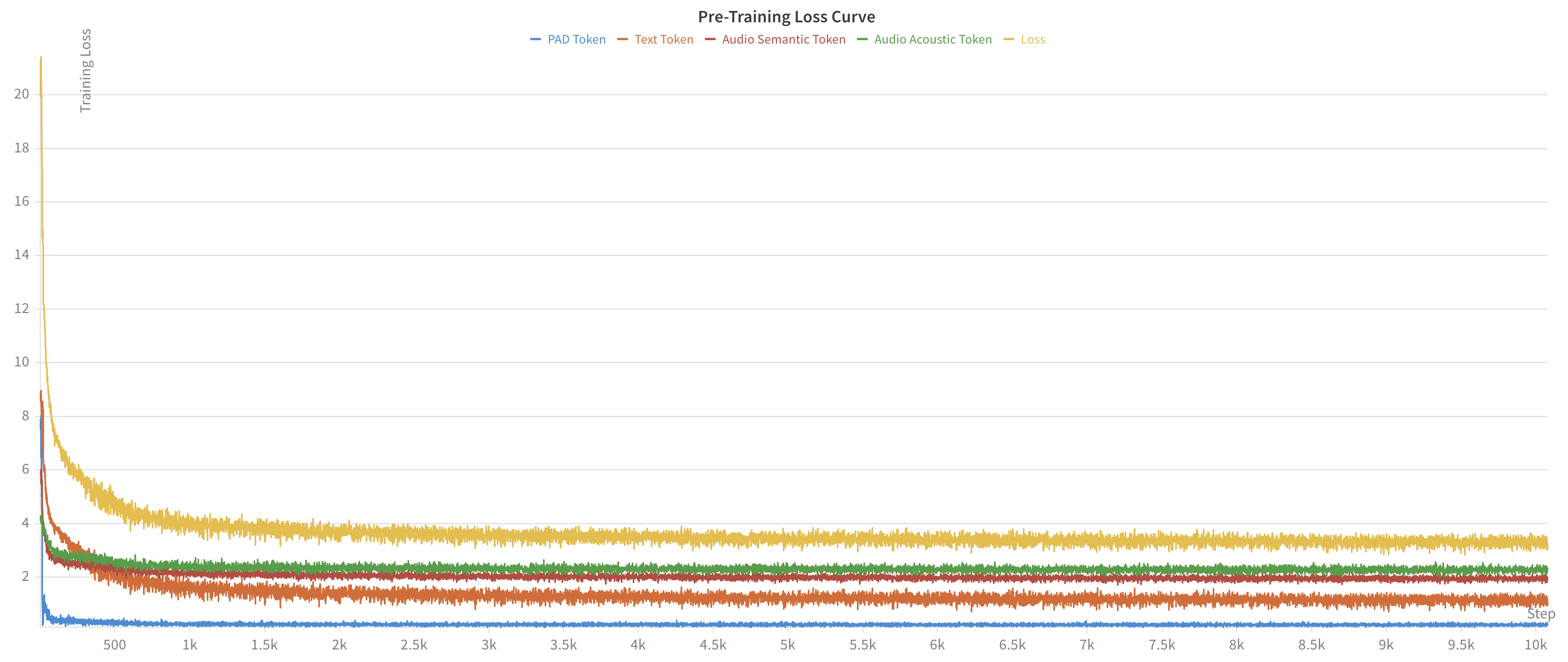
Figure 1: Training loss during pre-training on 26,000 hours of Hindi speech. All metrics converge within 2,000–4,000 steps.
Subsequent fine-tuning on 1,000 hours of highly curated conversation data reveals differential overfitting in text and audio losses, illuminating the necessity of early stopping for optimal generalization. The optimal checkpoint is determined at step 4,812, with total validation loss at 3.37 (text: 1.474, audio: 1.896).
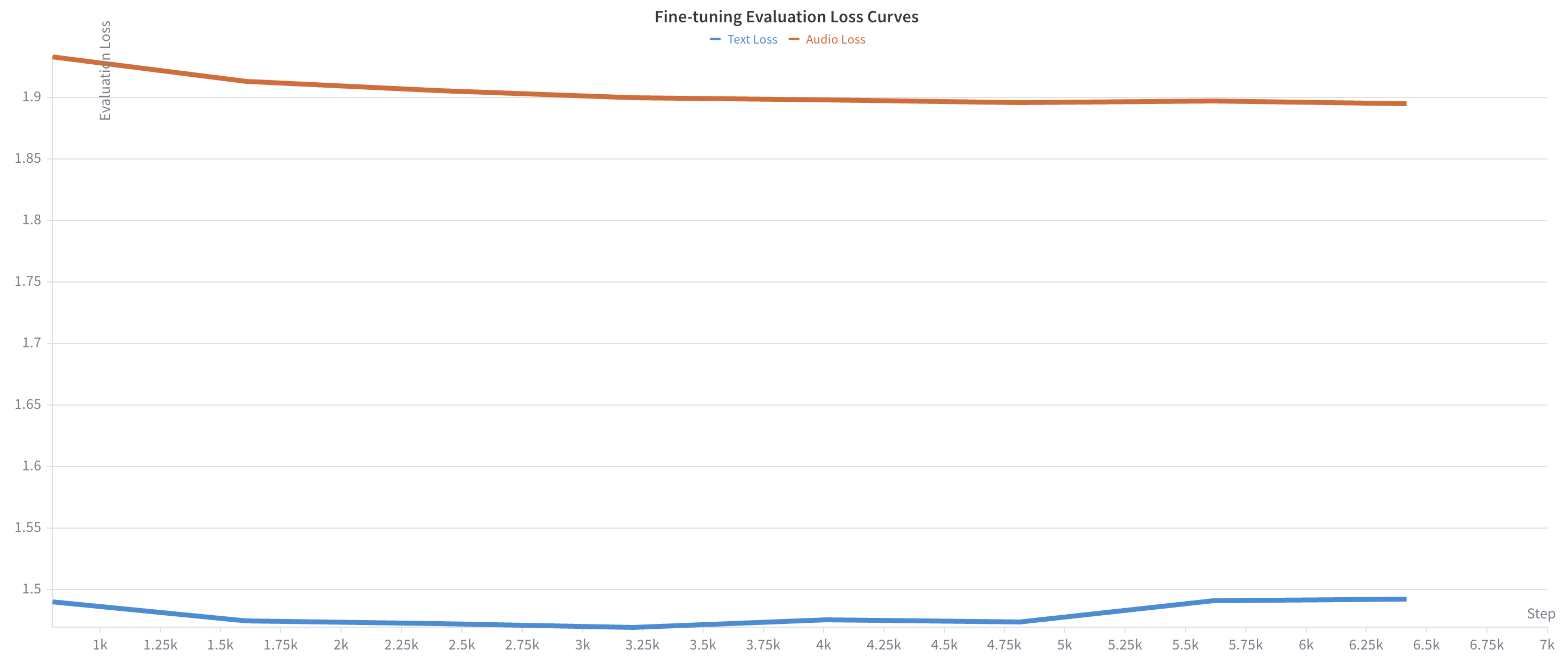
Figure 2: Evaluation loss during fine-tuning. Text loss overfits after approx step 4,800, while audio loss continues to improve marginally. Optimal checkpoint at step 4,812.
The training analysis demonstrates that effective language adaptation requires careful hyperparameter selection and that text components are susceptible to overfitting when fine-tuning on limited data.
Evaluation: Codec, Perplexity, Human Judgments, and Turn-Taking
The Mimi codec retains high speech intelligibility (STOI: 0.878) and moderate PESQ (2.55) on Hindi segments even without retraining, validating the decision to freeze its weights during adaptation.
For generated dialogue, perplexity evaluation with Sarvam-1 (2B) shows that fluent Hindi is achieved at lower temperature (τ=0.8, PPL: 356.9), with coherence degrading as sampling temperature increases.
Human evaluation, comprising 2,125 paired comparisons by 130 native speakers, delivers naturalness scores of 4.10 (model) versus 4.55 (human), with 66.9% of judgments tied. Clarity, contextual relevance, and completion rates highlight persistent gaps to human performance, though conversational dynamics (human-like interaction: 85%) are well modeled.
Turn-taking statistics confirm that the adapted model replicates natural conversational dynamics, especially at τ=0.9, closely matching ground-truth gap and pause durations while adjusting IPU and overlap rates as sampling temperature is varied.
Implications and Theoretical Significance
The adaptation of Moshi to Hindi, enabled by large-scale quality-controlled stereo data and strategic tokeniser and embedding reinitialisation, demonstrates that full-duplex architecture generalizes successfully to typologically distinct languages without retraining audio codecs. The findings indicate that real-world domain-matched conversational corpora are indispensable for modeling interleaved speech phenomena, challenging prior reliance on synthetic augmentation or monophonic diarisation.
The practical implication is that full-duplex conversational modeling in resource-scarce languages is attainable with judicious architectural adjustments and sufficient spontaneous data. This approach unlocks applications in voice-based assistants and interactive systems for the vast Hindi-speaking population and sets a precedent for similar adaptations to other Indian and non-English languages.
Theoretically, this work suggests that acoustic and semantic representations learned by large speech models (e.g., Mimi, RQ-Transformer) are robust across substantial phonological and script variance, provided the text embedding layers are retrained. Future research will likely explore cross-lingual transfer, scaling datasets, and joint optimization of multilingual speech codecs.
Conclusion
The Human-1 system constitutes the first open, reproducible full-duplex spoken dialogue model for Hindi, achieved via a targeted Moshi adaptation, Hindi tokeniser integration, and two-stage training on extensive real-world stereo conversational data. The results underscore the primacy of large-scale, domain-matched corpora for replicating rich conversational phenomena and establish practical protocols for adapting full-duplex architectures to new languages without retraining audio encoders. This work prefigures scalable advances in conversational AI for Indian languages, with anticipated progress contingent on further data collection, architectural refinement, and rigorous evaluation.