- The paper introduces a hybrid model that combines a SqueezeNet-style CNN and a MobileViT-inspired transformer with an Adaptive Attention Gate to dynamically fuse local and global features.
- The approach achieves 97.60% accuracy and near-perfect ROC-AUC scores on a diverse MRI dataset, outperforming single-branch and traditional fusion methods.
- The adaptive feature weighting enhances interpretability and offers potential for efficient, clinically deployable solutions, especially on edge devices.
CNN-ViT Fusion with Adaptive Attention Gate for Brain Tumor MRI Classification: Technical Overview and Implications
Introduction
MRI-based classification of brain tumors is a clinically vital yet technically demanding problem due to complex spatial patterns, nuanced local features, and the operational heterogeneity in MRI acquisition. Traditional CNNs have demonstrated capability in modeling localized, texture-rich information, but are limited in capturing global spatial dependencies. Conversely, Vision Transformers (ViTs) excel at global contextual understanding but typically require large-scale pretraining and may underperform in data-limited medical settings. The paper “CNN-ViT Fusion with Adaptive Attention Gate for Brain Tumor MRI Classification: A Hybrid Deep Learning Model” (2604.23137) addresses these gaps through a hybrid approach integrating a SqueezeNet-derived CNN, a MobileViT-inspired transformer, and a novel Adaptive Attention Gate (AAG) to enable dynamic, per-sample, per-feature weighting of local and global feature representations.
Dataset and Preprocessing
The study employs the publicly available Brain Tumor MRI Dataset (Kaggle), comprising 7,023 color MRI slices across four classes: glioma, meningioma, pituitary tumors, and non-tumor. The dataset is characterized by heterogeneous imaging parameters and anatomical orientations.
Figure 1: Representative brain MRI samples from the dataset illustrating inter-class and acquisition variability.
All images are resized to 128×128, pixel values normalized to [0,1], and augmented online through flipping, rotation, and zoom transformations to enhance robustness and counter class imbalance. The training/testing split follows the benchmark protocol, ensuring direct comparability with prior work.
Hybrid Model Architecture
The proposed architecture consists of:
- SqueezeNet-style CNN branch: Captures multiscale local features using an efficient hierarchy of Fire modules and max pooling.
- MobileViT-style ViT branch: Performs global spatial reasoning via MBConv layers followed by lightweight transformer blocks.
- Adaptive Attention Gate (AAG): Learns a feature-dimension-wise sigmoid gate, dynamically fusing the embeddings from CNN and ViT branches based on sample-specific and feature-specific information.
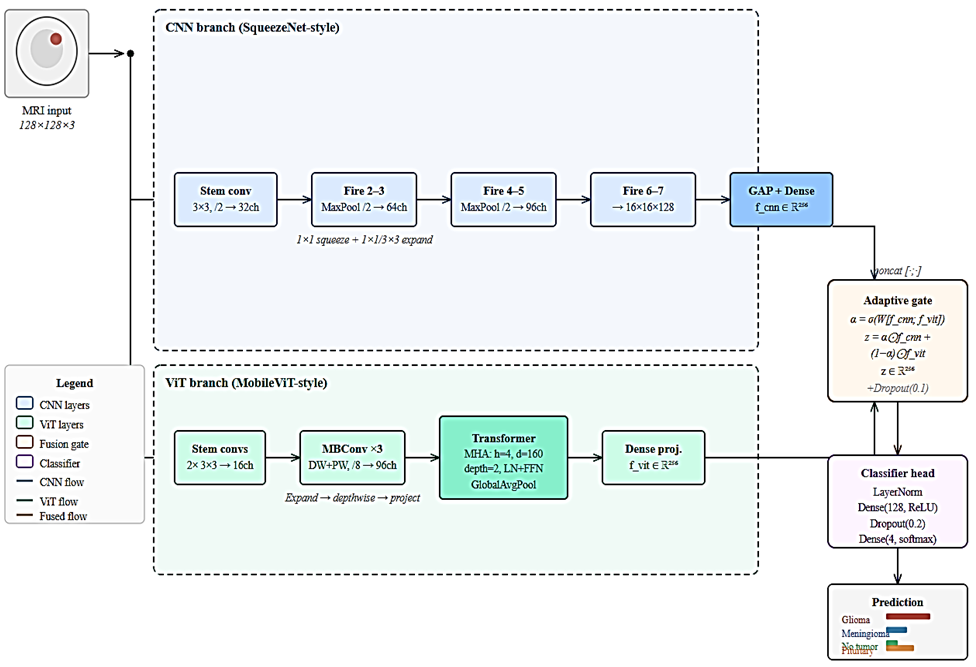
Figure 2: Schematic of the hybrid fusion model, combining local CNN and global ViT branches with an adaptive gating mechanism.
Each branch outputs a 256-dimensional embedding, which the AAG fuses through an elementwise convex combination. The fused representation is subsequently processed by a normalization, dropout, and dense layer classifier.
Training Protocol and Optimization
The hybrid model is optimized using Adam (learning rate 1×10−4), with callbacks for early stopping (patience=6), learning rate reduction on plateau, and model checkpointing. Training operates under mixed-precision (FP16), facilitating larger batch sizes. The optimization objective is categorical cross-entropy over four output classes.
The model consistently converges within 30 epochs; early stopping frequently triggers prior to the 50-epoch maximum, reflecting efficient training dynamics.
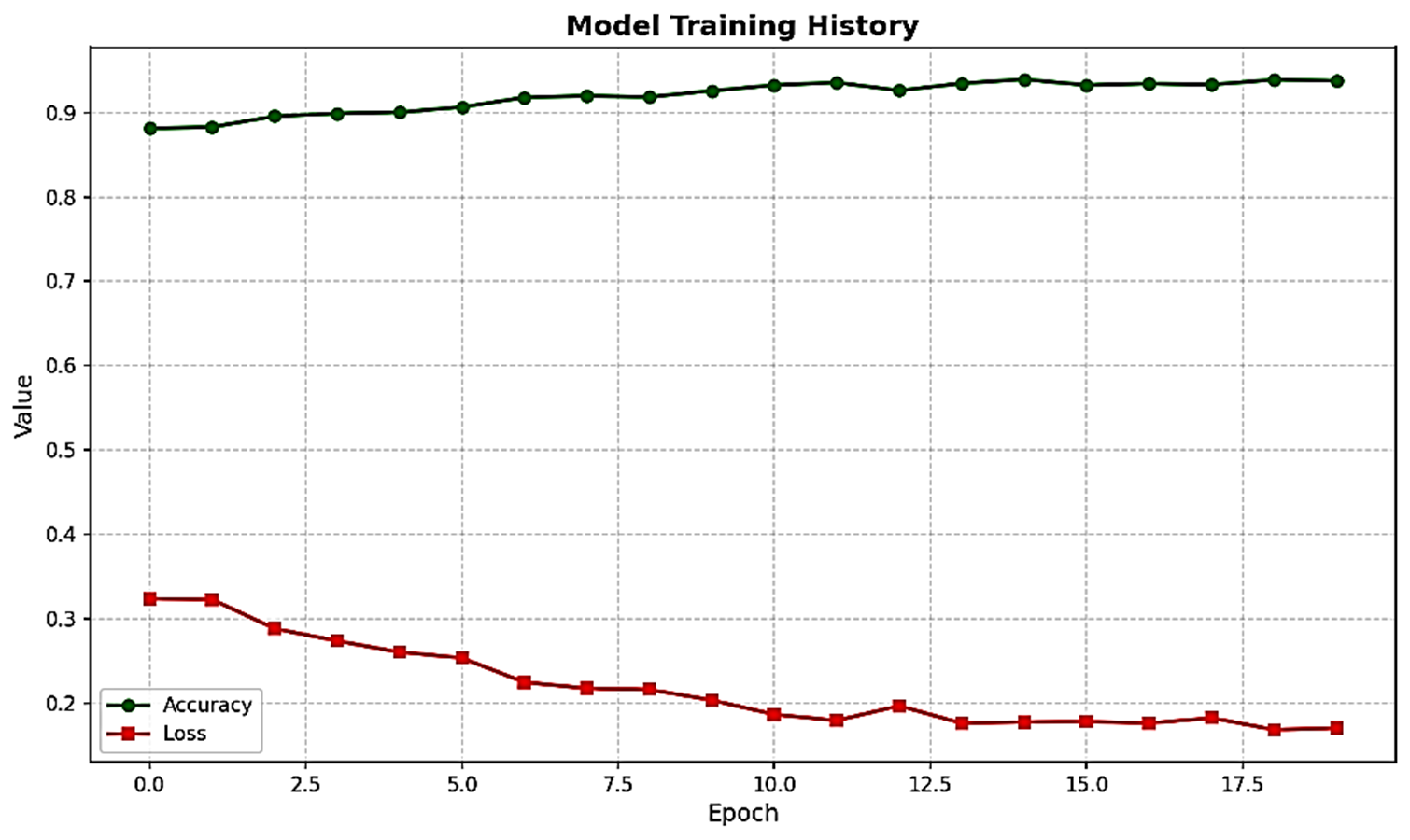
Figure 3: Training curves showing rapid convergence of accuracy and steady minimization of loss via the adaptive fusion strategy.
Empirical Results
The model achieves:
- Test accuracy: 97.60%
- Precision: 97.30%
- Recall: 97.50%
- F1-score: 97.40%
- Macro-average AUC: 0.9946
These scores surpass those of single-branch CNN and ViT baselines, as well as existing fusion approaches including linear and ensemble-based methods.
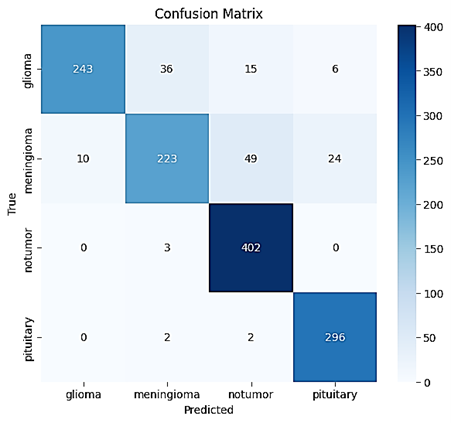
Figure 4: Confusion matrix for all classes, with minimal off-diagonal errors, demonstrating strong per-class discriminative capacity.
The ROC-AUC analysis indicates near-perfect discrimination capability across all classes, with the minimum per-class AUC exceeding 0.991.
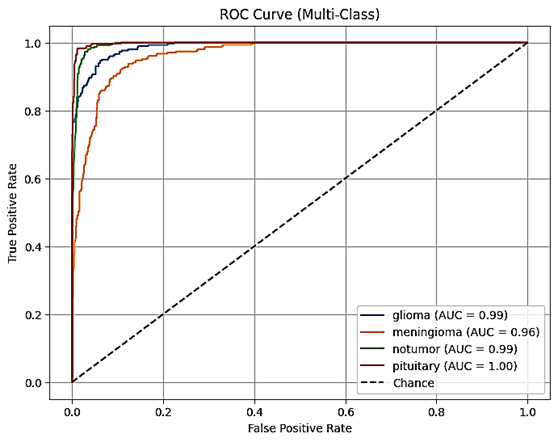
Figure 5: ROC-AUC curves for one-vs-rest classification, revealing robust predictive probabilities in multiclass tumor categorization.
Crucially, the confusion matrix shows the model rarely confuses meningioma and glioma—the two most challenging classes—validating the utility of dynamic local-global fusion.
Adaptive Attention Gate Analysis and Model Interpretability
The AAG's learned gating behavior is data-adaptive: the average per-feature α is higher for glioma and pituitary tumors, emphasizing CNN-derived local features, whereas meningioma cases skew towards lower α values, utilizing ViT’s global context. This interpretable pattern confirms the model’s ability to modulate feature reliance in a pathology-specific manner, supporting the hypothesis that hybrid architectures with dynamic feature fusion are preferable to static or naive fusion methods.
Discussion and Theoretical Implications
The results substantiate the claim that instance- and feature-level adaptivity in local-global feature fusion can enhance both performance and interpretability in medical image classification. Existing approaches, such as simple concatenation or linear weighting, are insufficiently flexible to accommodate the heterogeneity in real-world imaging data.
The SqueezeNet/MobileViT backbone selection enables high accuracy with modest parameter count (~4.2M), underlining the feasibility of edge-device deployment. However, the methodology remains constrained to 2D slices, potentially limiting clinical applicability where 3D information is available and crucial. Further, dataset biases (source institution, acquisition hardware) must be addressed before claims of clinical utility can be generalized.
Theoretically, the success of the AAG module encourages future exploration of more nuanced attention-based fusions, potentially leveraging mutual information or uncertainty for gate modulation, and the adaptation of similar mechanisms in volumetric or multimodal medical frameworks.
Future Directions
Subsequent work should target:
- 3D extension: Volumetric CNN and transformer modules to capture inter-slice dependencies.
- Generalization studies: Evaluation on multi-institutional datasets and scans from diverse hardware.
- Granular interpretability: Integration of attention visualization and attribution methods directly leveraging the AAG outputs.
- Clinical integration: Real-world testing in radiological workflow, including prospective reader studies.
Conclusion
This work proposes a hybrid SqueezeNet/MobileViT network for brain tumor MRI classification, augmented with a per-feature, per-sample Adaptive Attention Gate. The model achieves state-of-the-art performance on a multilabel public dataset, empirically validating the effectiveness of dynamic local-global fusion. The adaptive fusion design not only yields numerical superiority but also enhances interpretability, a critical aspect in high-stakes clinical decision support. This research supports adaptive deep learning fusion strategies as a promising avenue for future medical image analysis systems.