- The paper demonstrates a hierarchical DRL approach that decouples UAV trajectory planning and bandwidth allocation to improve data collection.
- The proposed TBH-DDPG method achieves a 44.44% faster convergence and a 58.05% reduction in compute cost compared to non-hierarchical models.
- Numerical experiments show robust obstacle avoidance and near-linear scalability with IoT node density, ensuring effective real-time network operations.
Hierarchical Deep Reinforcement Learning for UAV-Aided IoT Data Collection: TBH-DDPG Approach
Problem Setting and Motivation
The proliferation of low-altitude intelligent IoT paradigms is fundamentally transforming real-time sensing and data acquisition infrastructure in smart cities and industrial environments. Unmanned aerial vehicles (UAVs) equipped with Integrated Sensing and Communication (ISAC) are pivotal for adaptive, scalable data collection, especially under the constraints posed by power, environmental obstacles, and dynamic interference. The paper explicitly addresses the optimization of UAV trajectory and bandwidth allocation in such environments where IoT nodal data volume evolves in real-time, interference locations are unknown, and obstacles are multi-type and heterogeneous.
Figure 1: Data collection for the food processing industry in low-altitude IoT system scenario.
The scenario incorporates multi-faceted challenges: UAVs must maximize aggregate data acquisition from spatially distributed IoT nodes, while circumventing no-fly zones, communication obstacles, and jamming sources. Critical parameters such as time slot division (Figure 2), channel and interference modeling (Figure 3), and trajectory abstraction (Figure 4) are rigorously instantiated to reflect practical deployment constraints.
Figure 2: Time slot division.
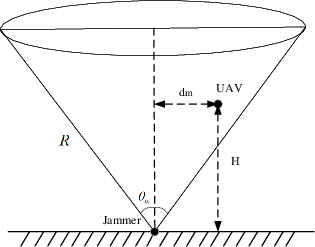
Figure 3: Interference model.
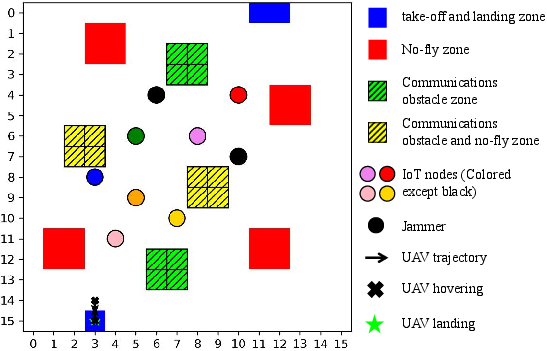
Figure 4: Scenario map of the system after abstraction.
The system is organized into a square region partitioned into various zone types: no-fly zones, communication obstacles, and hybrid zones. The UAV model assumes fixed-height operations and discrete flight-speed choices (v or $0$), with the mission chunked into multiple flight periods and subordinate communication slots.
A key innovation is the hierarchical abstraction of the optimization process:
- Upper-level (Trajectory Planning): Decision making at coarse granularity, determining the UAV's movement direction per macro time slot
- Lower-level (Bandwidth Allocation): Fine-grained decisions on how to apportion FDMA bandwidth among IoT nodes during each communication slot within the flight period
The communication model employs LoS/NLoS channel gain, stochastic shadowing, and an explicit jammer antenna model. Transmission rates and SINR are parameterized to account for spatial positions and time-varying jamming intensity. The optimization objective is to maximize cumulative data collected, subject to energy and bandwidth constraints, formulated as a constrained SMDP.
Hierarchical DRL Algorithm: TBH-DDPG
Hierarchical Structure and State Processing
To ameliorate the computational burden and acceleration of policy convergence, the authors propose TBH-DDPG—a hierarchical architecture leveraging deep deterministic policy gradients (DDPG). State abstraction leverages five layered maps (Figure 5), capturing obstacles, nodal status, and interference levels, centralized around UAV coordinates and processed via convolutional pools to provide both global and local observability.
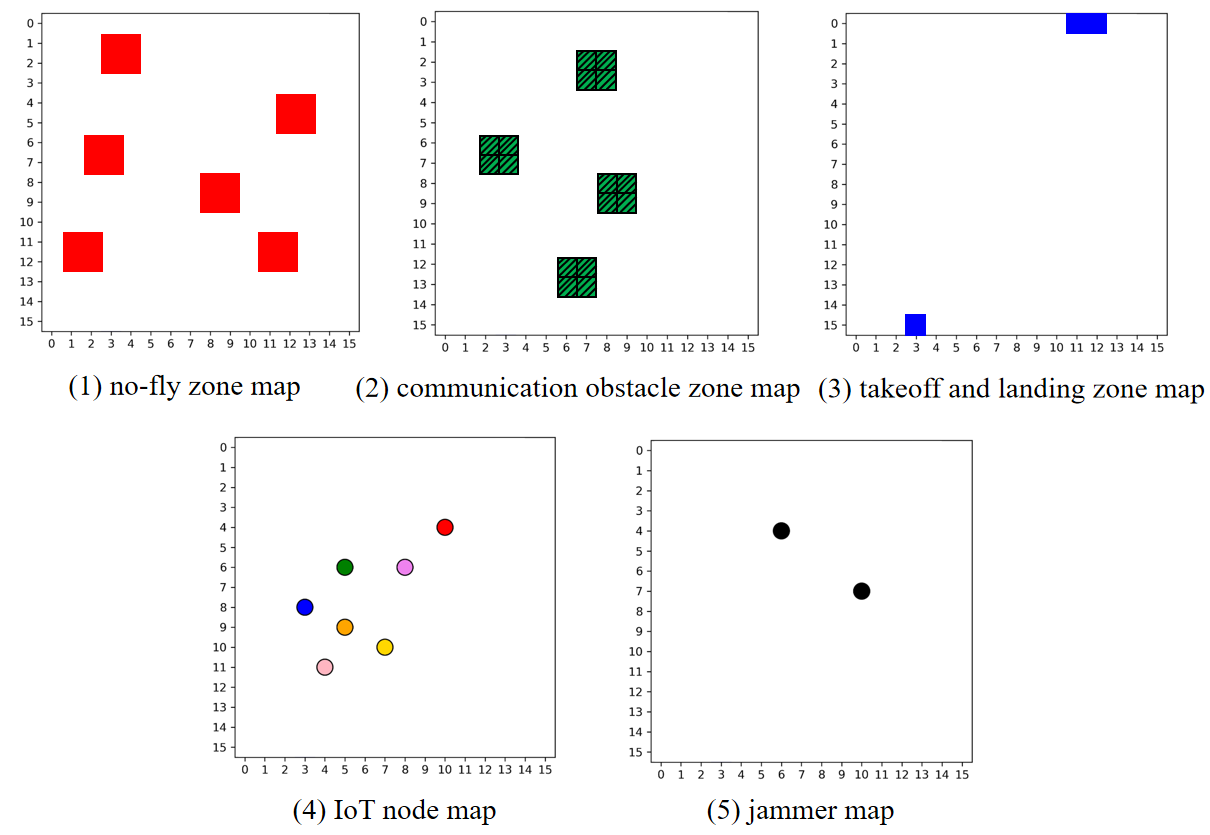
Figure 5: Five layered maps.
SMDP and Option Framework
The decision process is mapped as a semi-Markov decision process (SMDP), exploiting option hierarchies to decouple the flight trajectory and communication allocation tasks. Options entail a triplet of initial state, policy, and termination condition, creating flexible temporal abstraction for the trajectory planning layer.
TBH-DDPG Algorithmic Details
The hierarchical algorithm (Figure 6) comprises:
- Upper-level actor/critic networks for trajectory control (discrete actions)
- Lower-level actor/critic networks for bandwidth allocation (continuous actions via softmax on output coefficients)
Replay buffers and target networks are maintained for both hierarchy levels. The reward structure includes upper-level penalties (collision, return-to-base, incomplete landing) and lower-level rewards (data collection and loss).
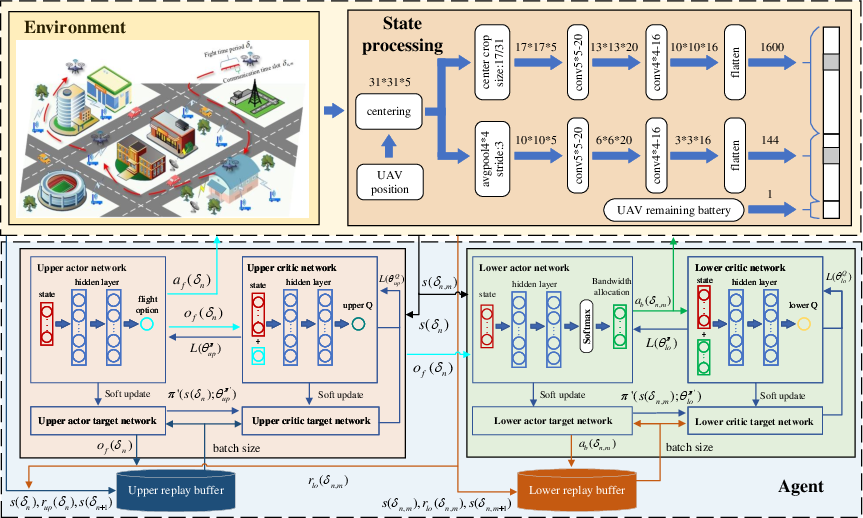
Figure 6: TBH-DDPG algorithm framework diagram.
Numerical Results and Comparative Analysis
Convergence Dynamics
Empirical evaluations substantiate strong numerical claims: TBH-DDPG achieves a 44.44% gain in convergence speed and a 58.05% reduction in compute cost versus non-hierarchical DDPG (TBJN-DDPG). Reward training curves are displayed in Figure 7, confirming faster and more stable policy learning.
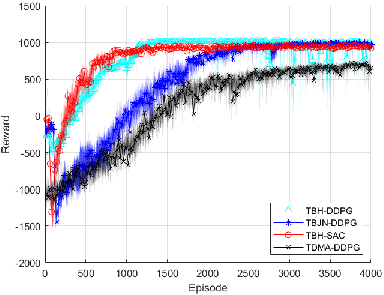
Figure 7: Reward training curves.
Trajectory, Data Collection, and Resource Allocation
The multi-column analysis in Figure 8 explores policy behaviors post-convergence: trajectory mapping, cumulative collection per IoT node, and bandwidth allocation ratios. TBH-DDPG demonstrates dynamic route adjustment and equitable bandwidth distribution, maximizing aggregate data transfer and adapting priority as nodal states evolve.
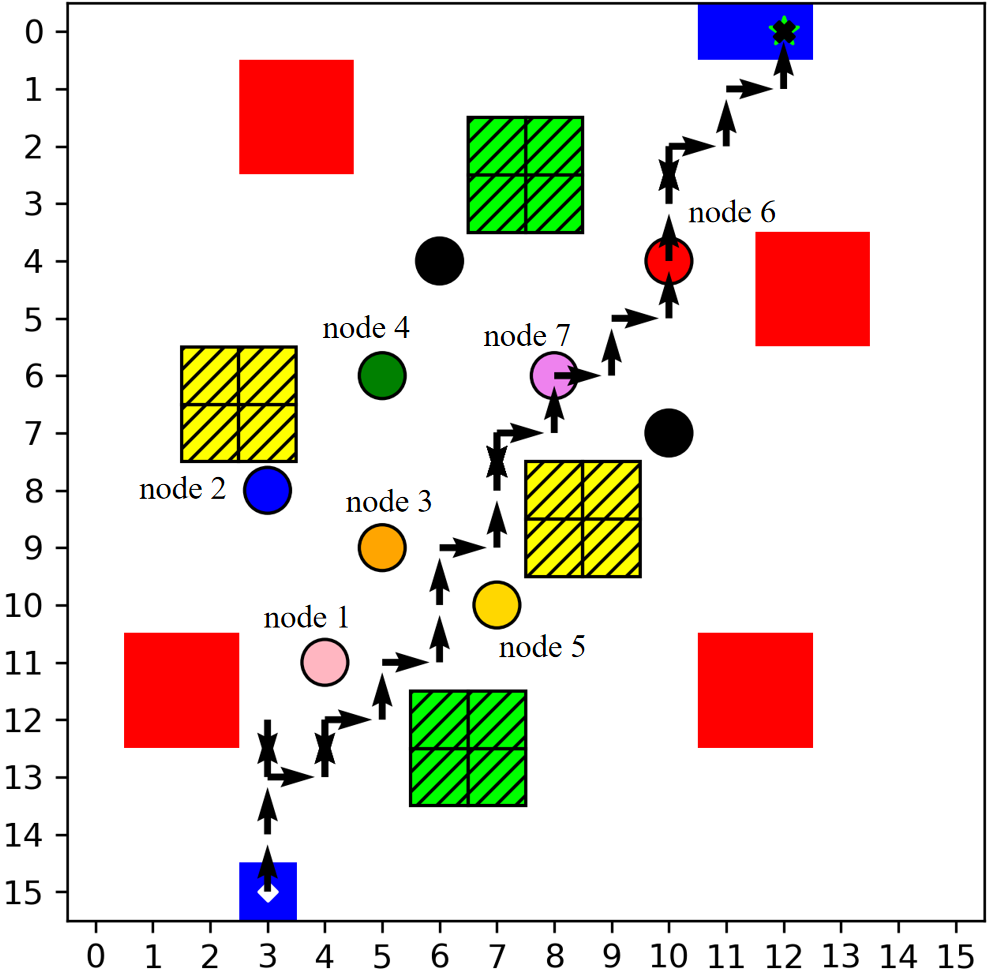
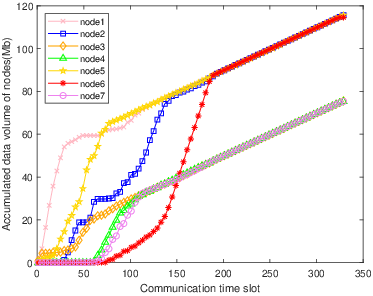
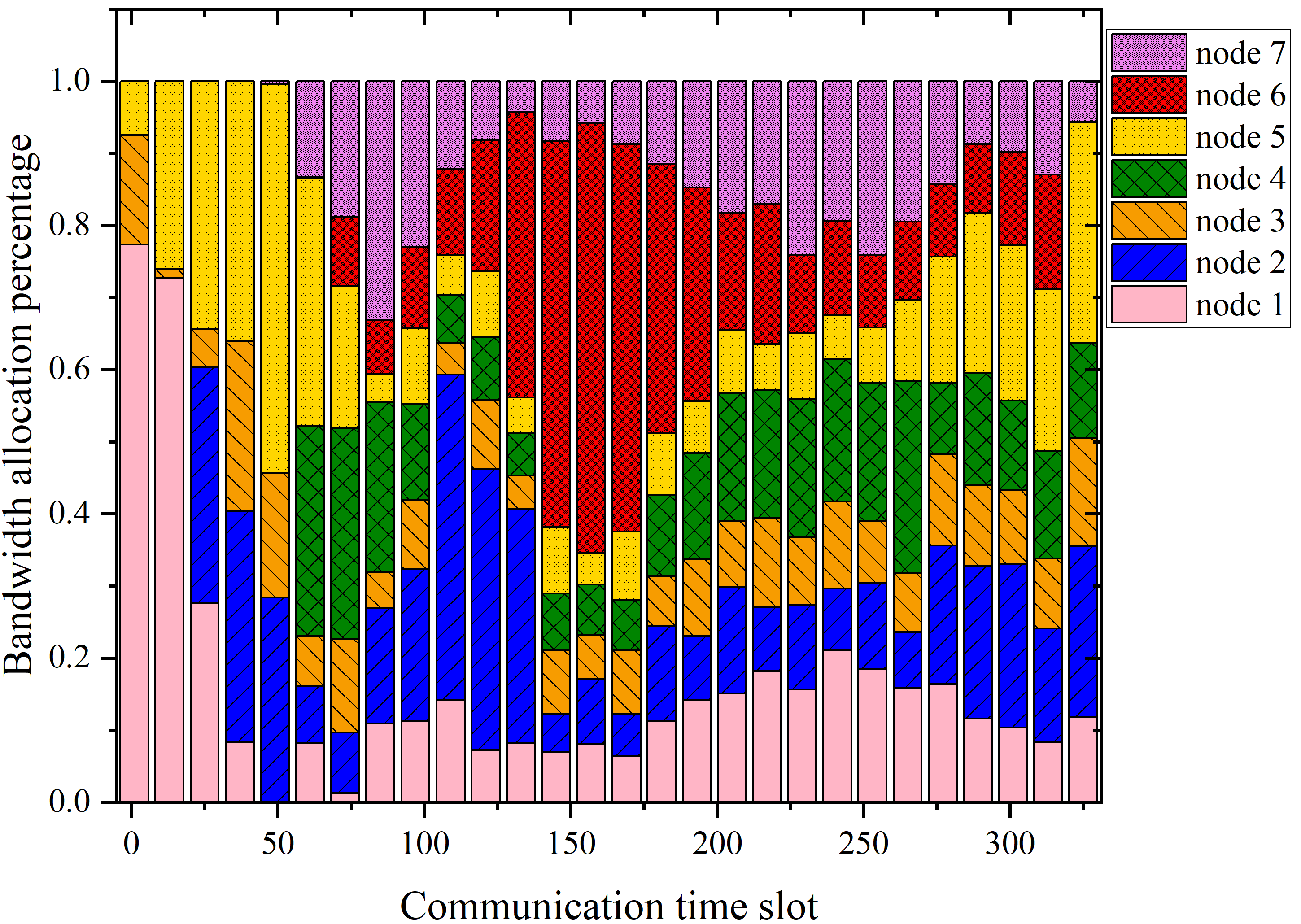
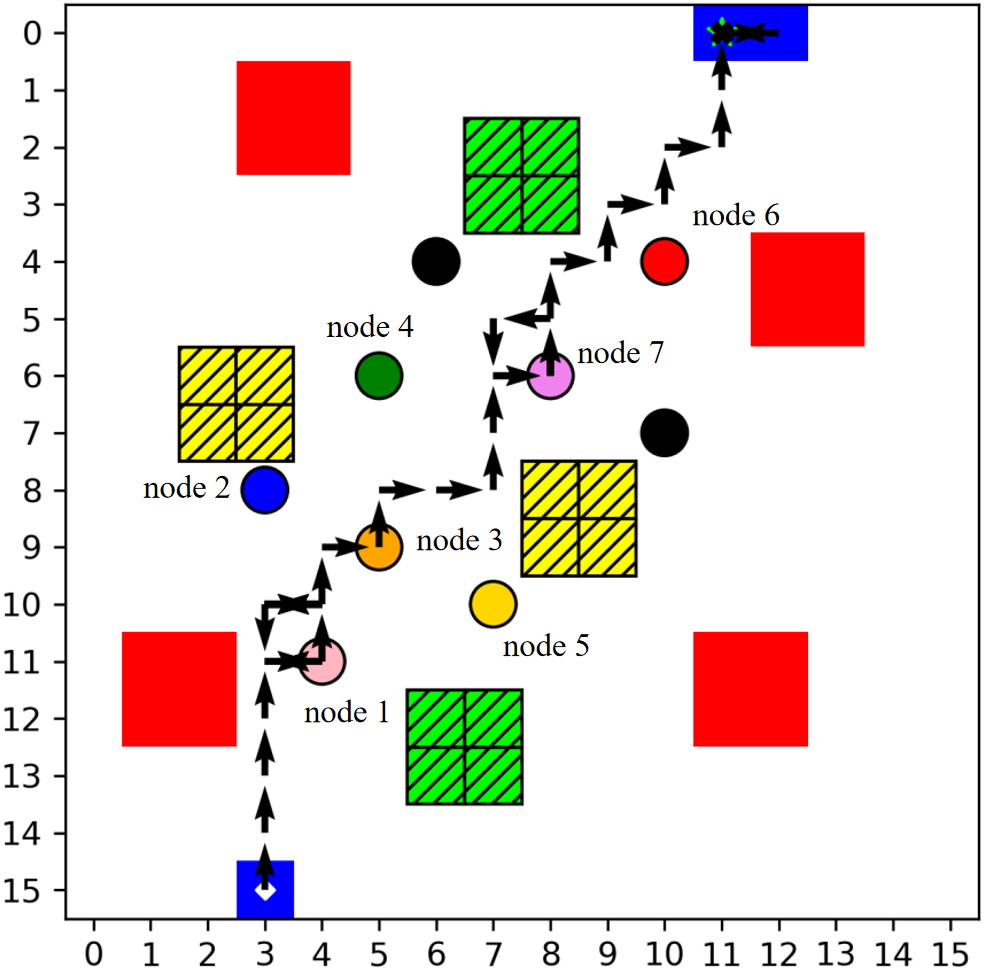
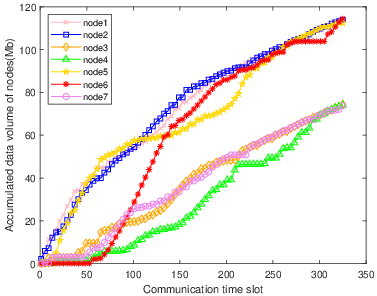
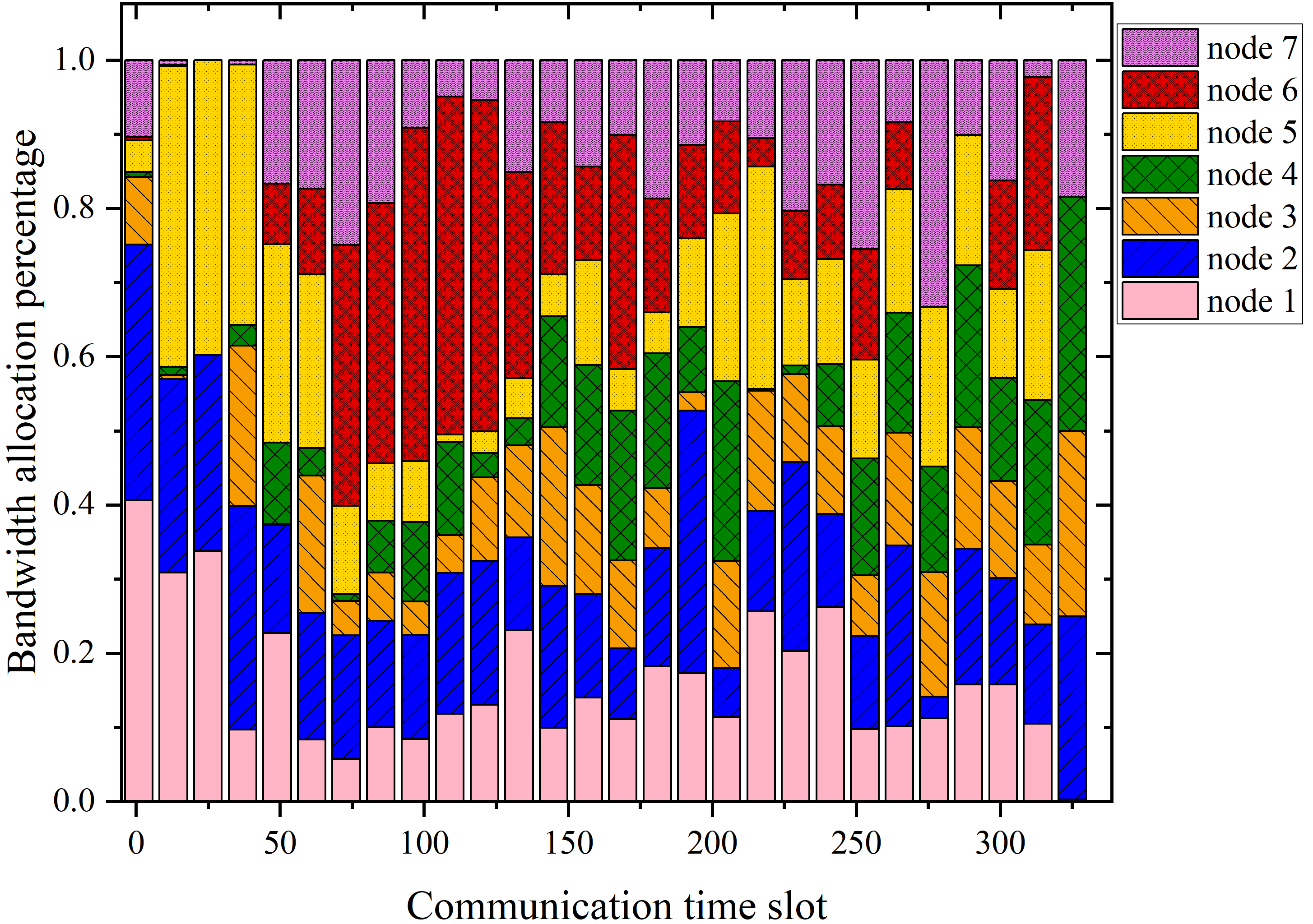
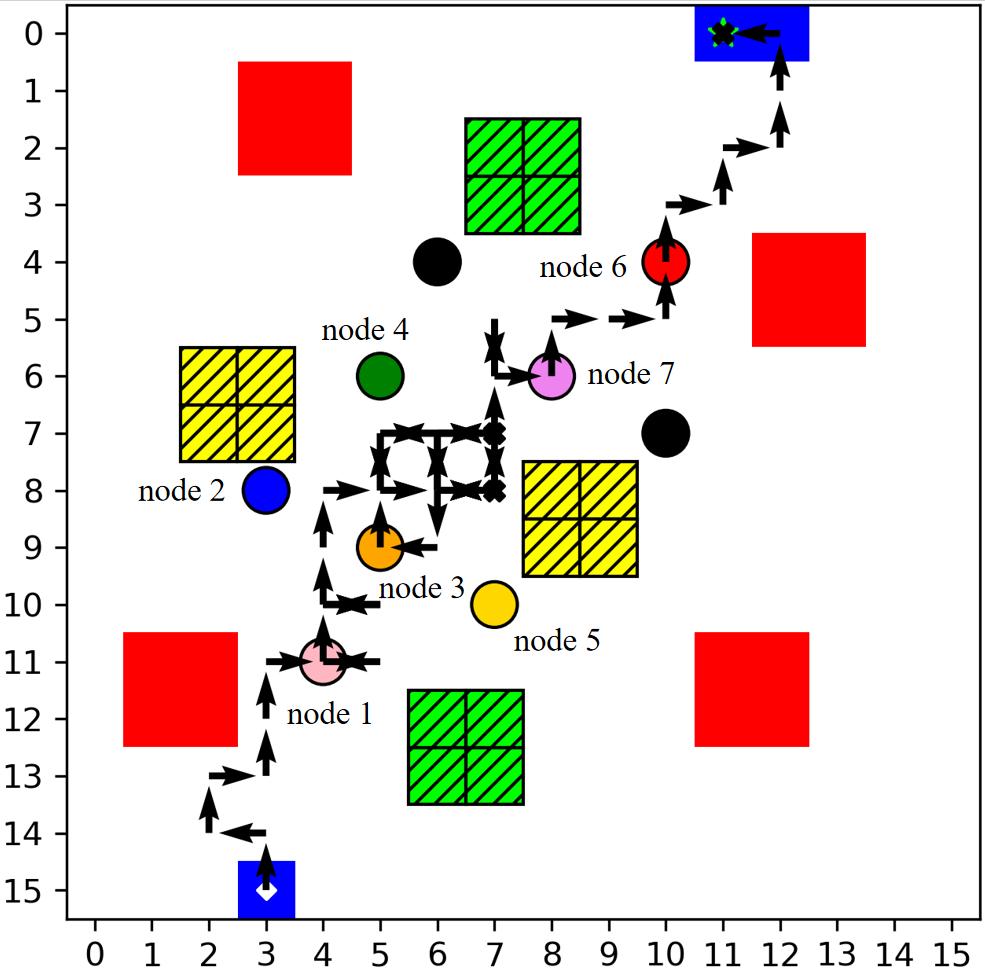
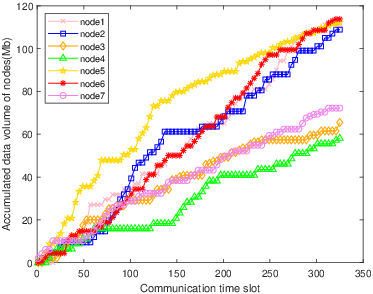
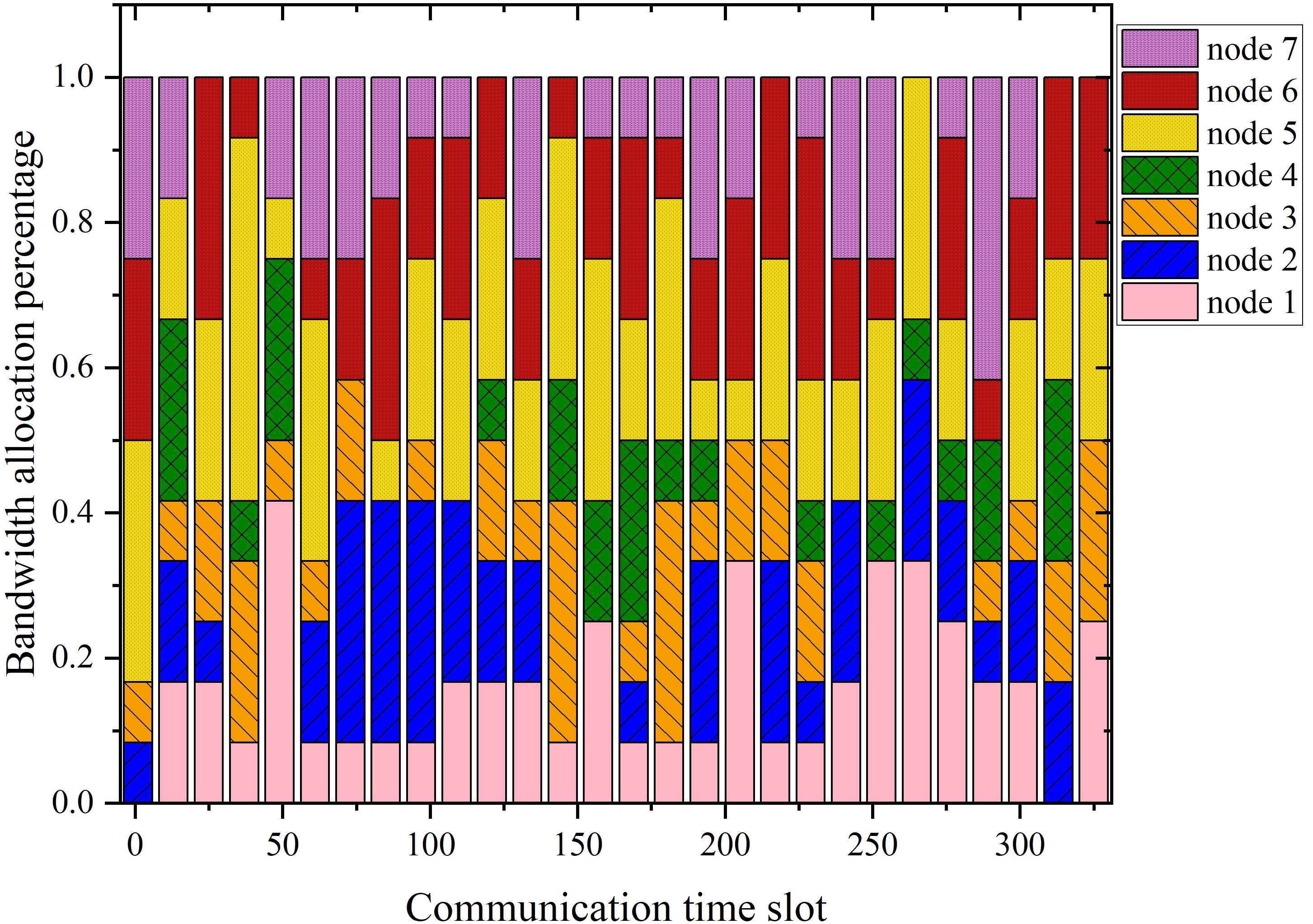
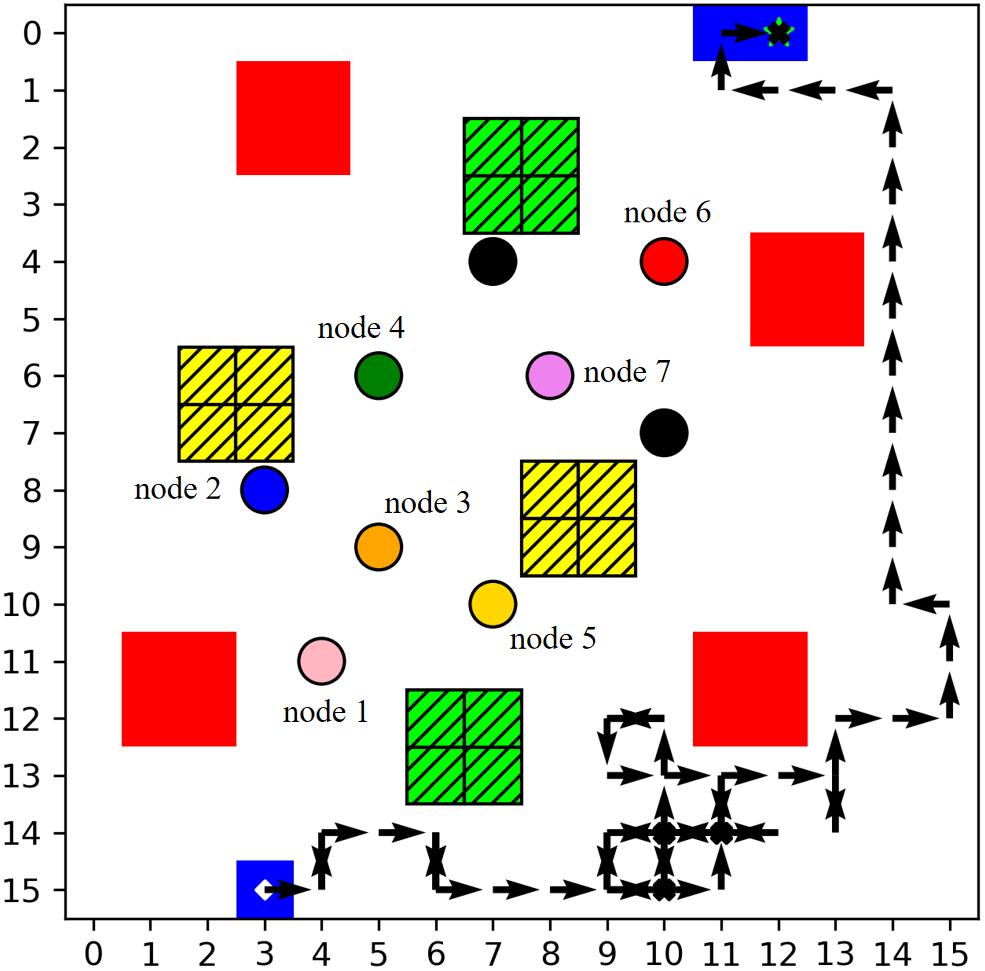
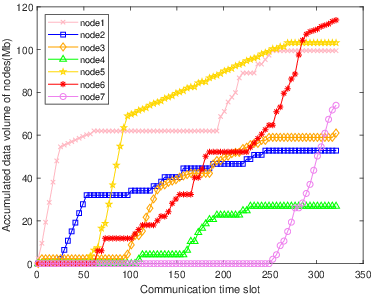
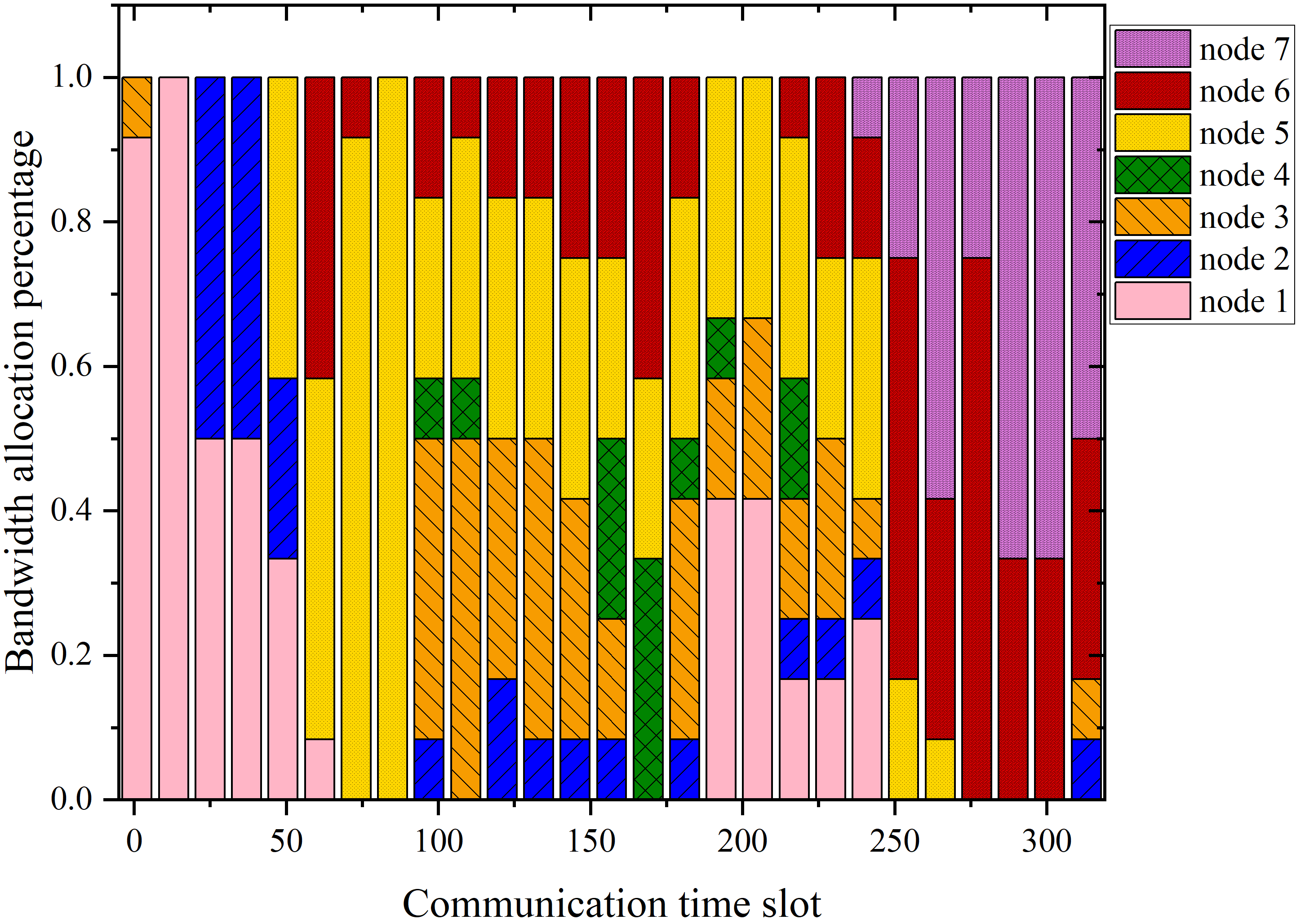
Figure 8: The first column illustrates the trajectories, the second shows per-node cumulative data, and the third depicts average bandwidth allocation ratio for every 12 communication time slots across algorithms.
Robustness and Scalability
Scalability with IoT Node Count
As demonstrated by Figure 11, TBH-DDPG achieves near-linear increases in aggregate data collection as IoT node density rises—superior to non-hierarchical and TDMA policies which plateau due to action-space bottlenecks.
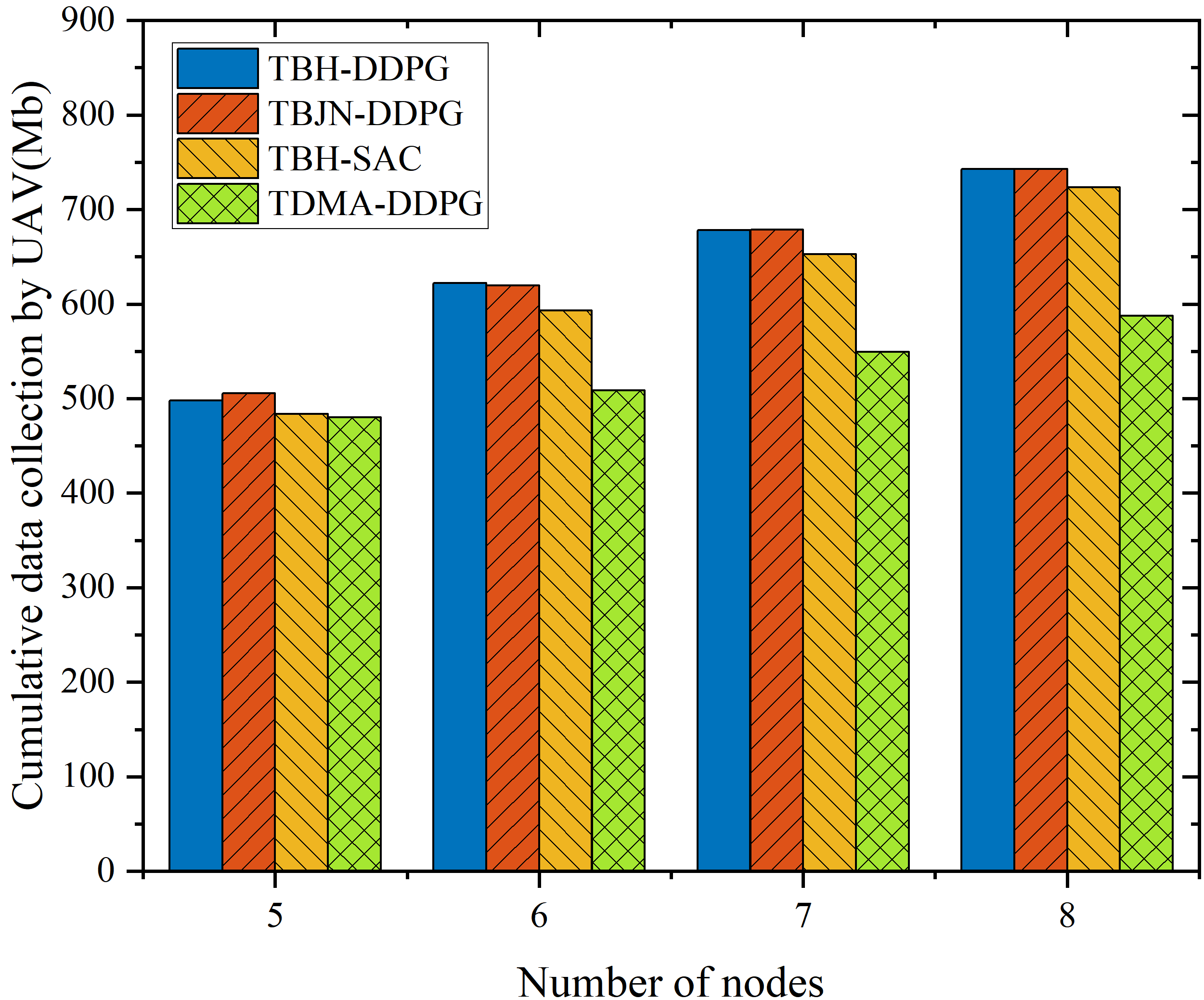
Figure 11: Impact of the number of IoT nodes on the amount of data collected by the algorithm.
Algorithmic Efficiency
Experimental throughput and hardware resource utilization indicate that TBH-DDPG requires significantly fewer hidden units and achieves optimal performance with a network size reduction by up to 6x compared to TBJN-DDPG, supporting deployment suitability for resource-constrained UAVs.
Implications and Future Prospects
The TBH-DDPG approach presents decisive evidence of the benefits of hierarchical DRL structures in handling high-dimensional, temporally decomposed mission tasks in UAV-IoT settings. The explicit separation of trajectory and bandwidth subpolicies enables rapid convergence, computational tractability, and flexibility in mission-adaptive management. Hierarchical DRL is well-suited for extension to multi-UAV collaborative paradigms, with potential to leverage flexible option design for distributed agents, further reducing per-device computational burdens and enabling scalable task orchestration.
Practically, the results indicate that policy granularity and autonomous bandwidth allocation can directly impact throughput and reliability in UAV-IoT networks, especially under constraints like jamming and dynamic data generation. The architecture can be adapted for real hardware, with strong prospects for real-time embedded AI enhancements and continuous adaptation in diverse operational scenarios.
From a theoretical perspective, the option-based SMDP decomposition proffers a template for future research in hierarchical RL for cyber-physical systems, where action space partitioning and reward shaping are crucial to balance exploration, exploitation, and robustness.
Conclusion
The paper systematically develops a hierarchical DDPG-based policy architecture for simultaneous UAV trajectory and bandwidth allocation optimization under dynamic, uncertain low-altitude IoT environments. Numerical validations confirm superior convergence speed, computational efficiency, and robustness to environmental disturbances. The methodology is extensible, with meaningful implications for multi-agent collaboration and real-world autonomous drone network deployments. Future avenues include field hardware validation, hyperparameter adaptation, and scaling hierarchical DRL for cooperative UAV swarms.