- The paper proposes a teacher-student framework that uses multi-level distillation to recover semantic features from corrupted images.
- It aligns global, patch, and attention representations to maintain high accuracy under heavy distortions like noise, blur, and masking.
- The method demonstrates impressive label efficiency and transferability across datasets such as ImageNet-100, CIFAR, and STL-10.
Introduction and Motivation
Robust visual recognition in the presence of severe image distortions remains an unsolved problem for deep neural networks, especially when access to clean observations is limited or impossible. Traditional supervised pipelines and even state-of-the-art self-supervised approaches show significant performance degradation under complex perturbations such as heavy masking, Gaussian noise, or blur. This paper introduces a teacher-student framework for robust representation learning, leveraging strong pretrained Vision Transformers (ViTs) as teachers and applying multi-level knowledge distillation to train students exclusively on corrupted data. The methodology achieves improved resilience and transferability, bypassing the need for explicit pixel-level image restoration or heavy reliance on labels.
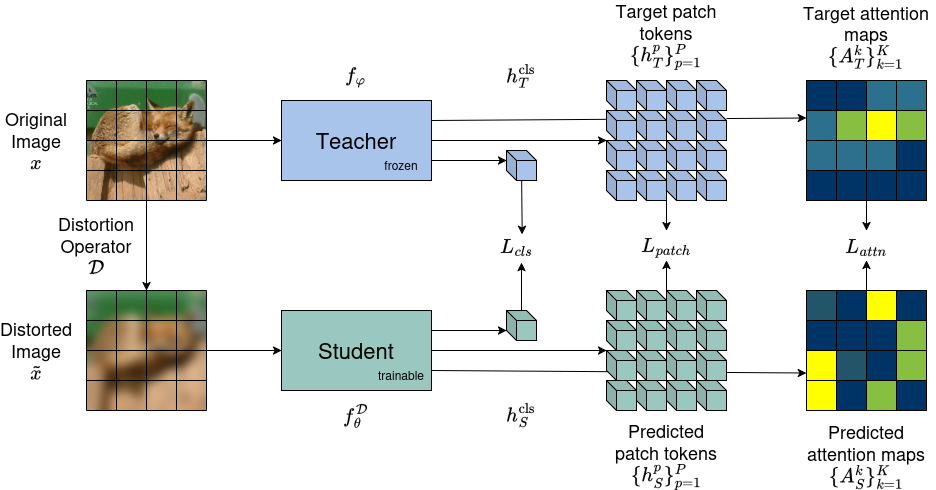
Figure 1: Overview of the multi-target distillation framework, where a frozen teacher ViT processes clean images and a student ViT receives distorted inputs, with supervision at global, patch, and attention levels.
Methodology
Distillation Setup
The core of the proposed framework is an asymmetric distillation scheme. Both teacher and student are initialized from the same pretrained ViT backbone, but only the student ever encounters distorted images, while the teacher interacts solely with clean inputs. The teacher remains frozen, serving as an invariance anchor in the semantic space. The student is trained by aligning its internal representations with those of the teacher across three complementary axes:
- Global Semantic Alignment: The student’s [CLS] token embedding is matched to that of the teacher to enforce global semantic consistency.
- Local Spatial Alignment: Patch token embeddings are aligned positionally, preserving local structure under severe corruption.
- Attention Map Alignment: The student replicates the teacher’s attention distributions at the class token, preserving interpretability and relational focus.
All objectives are combined with task-dependent weights, with KL divergence applied to attention probabilities and MSE for embedding matches. No class labels are used during distillation; supervision is entirely in the feature space.
Training and Corruption Paradigms
Distillation is conducted on the ImageNet-100 subset using DINO-pretrained ViT-B/16 backbones. Input images are subjected to one of three distortion families—random masking, additive Gaussian noise, or Gaussian blur—with augmentations exceeding those seen during the student’s supervised fine-tuning. Dedicated student models are trained for each corruption type, specializing the encoder for a specific degradation distribution.
Experimental Analysis
Robustness Against Distortion
Evaluation on ImageNet-100 with increasing distortion severity demonstrates notable robustness gains over both supervised and the contrastive inversion (CI) baselines. Particularly under high-variance Gaussian noise and large-kernel blur, the multi-level distilled encoders maintain substantially higher accuracy.
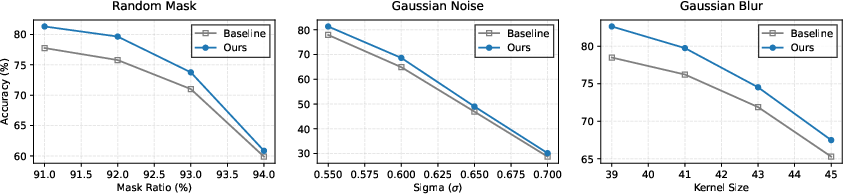
Figure 2: Top-1 validation accuracy on ImageNet-100 as distortion intensity increases beyond training conditions.
The measured resilience under out-of-distribution corruptions highlights the efficacy of multi-level semantic recovery. While accuracy for all models degrades at extreme severity, the distilled student preserves semantic features to a significantly greater extent.
Label Efficiency and Transferability
The distilled representations show pronounced advantages in low-label regimes. When fine-tuned with only 0.5%–10% of the training labels, the student model retains high validation accuracy, indicating that semantic structure is effectively captured during unsupervised pretraining.
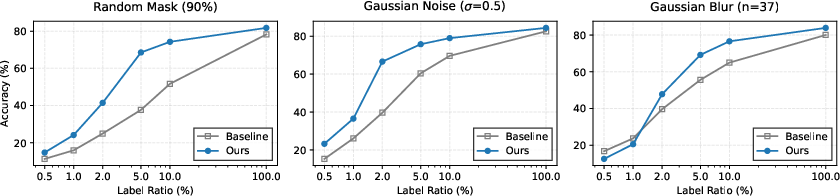
Figure 3: Top-1 accuracy on ImageNet-100 under various distortions, plotted against the fraction of training labels.
Further experiments extend to CIFAR-10/100, STL-10, RESISC45 (remote sensing), and CAMELYON17 (medical pathology). Across all transfer tasks and distortions, the distillation framework consistently outperforms supervised and CI-based baselines, with the largest margins observed on cross-domain tasks exhibiting stark distribution shift.
Attention Map Interpretability
Visual examination of attention maps corroborates that the distilled student can recover semantically meaningful focus regions even from highly degraded inputs. Unlike supervised models, which display collapsed or erratic attention under severe distortion, the student localizes objects of interest in a manner consistent with the teacher.

Figure 4: Attention maps from validation images under various distortions, comparing supervised baselines and distilled encoders. Distilled models maintain fidelity to clean-image semantics.
Ablation on Distillation Components
Ablation reveals that each distillation term—global, patch, attention—contributes independently to robustness, with their combination yielding the highest performance. Local patch alignment is especially critical for masking and noise, while attention alignment further boosts performance under spatially diffuse corruptions.
Theoretical and Practical Implications
The results substantiate that semantic feature recovery in the latent space is a viable route to distortion-robust representation learning. Distillation at multiple levels imparts invariance and spatial/relational structure, which pure output or single-level alignment cannot achieve. The approach is especially compelling in label-scarce domains, such as medical imaging or remote sensing, where obtaining large clean and annotated datasets is infeasible.
Practically, the technique obviates the need for distort-and-train or explicit image restoration pipelines. Theoretically, it probes the nature of ViT representations under heavy corruption and points to a modular design where generalization and robustness can be decoupled from raw pixel distributions.
Current limitations include the need for training a separate student for each corruption type and lack of a unified model handling mixed or unknown distortions. Joint training for multi-corruption or zero-shot robustness to unseen degradations remains open for further research.
Conclusion
By leveraging asymmetric distillation from clean-image ViT teachers, this framework develops students with exceptional robustness to diverse and severe image distortions. Multi-level representation alignment—across global, local, and attention-specific axes—proves critical to recovering clean semantic spaces from corrupted observations, facilitating downstream transfer and label-efficient learning. The method sets a new bar for distortion-robust visual representations, while highlighting future avenues for generalized multi-corruption resilience and single-model universality.

