- The paper introduces a framework where AI highlights a selective subset of features to assist human decision-makers under limited information bandwidth.
- It rigorously analyzes optimal policies for both sophisticated and naive agents, revealing NP-hard computational challenges and unbounded loss tradeoffs.
- It demonstrates that contextual, data-driven feature highlighting via greedy heuristics significantly outperforms fixed subset methods in simulations and empirical studies.
Algorithmic Feature Highlighting for Human-AI Decision-Making
The paper "Algorithmic Feature Highlighting for Human-AI Decision-Making" (2604.22236) introduces a formal and computational perspective on selective feature revelation: rather than outputting a complete prediction or decision, an AI assistant selectively highlights a small, context-specific subset of input features for a human decision-maker under information bandwidth constraints. The central model adopts a principal-agent framework: an algorithm (principal) observes the full high-dimensional feature vector of a decision instance and selects up to k coordinates to reveal to a human agent with aligned objectives. The agent subsequently forms a belief and acts to minimize expected loss. The paper's principal technical innovation is the analysis of optimal highlighting with different human belief-formation models, and the study of computational and robustness properties of resulting policies.
Two polar agent models are considered: (i) the sophisticated agent, who conditions on both the selected feature values and the selection rule itself (i.e., who understands what was revealed and why); and (ii) the naive agent, who conditions only on the observed feature values and ignores the informational content of the subset selection. The designer's goal is to minimize expected loss, either for a specific agent type or in a robust sense.
Differences between Naive and Sophisticated Updating
The paper exposes a strict separation between optimal policies for naive and sophisticated agents. An optimal highlighting policy for one agent type can perform arbitrarily poorly when evaluated under the other, as established by explicit finite-sample constructions. The "price of complexity" (loss of deploying a sophisticated-optimal policy to a naive agent) and the "price of simplicity" (loss from using a naive-optimal policy with a sophisticated recipient) are unbounded even for simple binary domains.
Computational Complexity of Policy Optimization
A primary contribution is the complexity analysis of optimal contextual highlighting. For sophisticated recipients, the designer must account for how selection itself conveys information, essentially turning the problem into a version of algorithmic Bayesian Persuasion with endogenous signal structure. The authors prove that, even in binary domains with bandwidth constraint k=1, computing the optimal contextual policy is NP-hard via a reduction from the Euclidean 2-means clustering problem.
For naive recipients, the optimization admits efficient algorithms as long as k is fixed: the optimal choice for each instance reduces to minimizing realized loss over all subsets of size at most k, and this can be solved in polynomial time for small k via enumeration. Moreover, greedy heuristics—to be discussed below—achieve near-optimality in canonical settings (e.g., independent Bernoulli features under quadratic loss), and often generalize well with limited correlations among features.
Contextual vs. Fixed Subset Highlighting
The work rigorously differentiates contextual (data-driven) highlighting from the classical fixed subset selection. A fixed subset policy reveals the same k coordinates for every instance, analogous to standard feature selection. Contextual highlighting, by contrast, dynamically chooses features to reveal depending on the realized instance, optimizing informativeness at the instance-level.
An explicit asymptotic analysis is provided for the case of independent binary features and squared recovery loss. Whereas fixed policies emphasize features with highest marginal variance (those closest to p=0.5), contextual policies reveal features with largest realized deviation ("surprises") per instance, leading to qualitatively different selection regimes, prioritizing extremes of p. This divergence is detailed through both theoretical equations and visual illustrations.
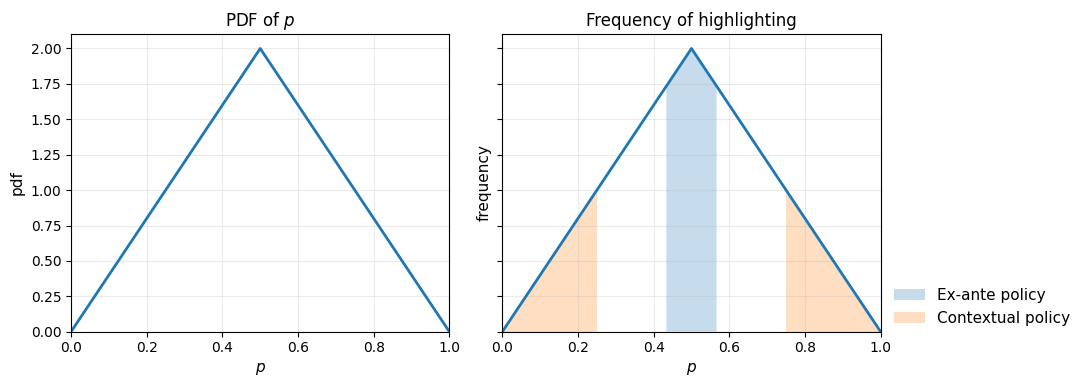
Figure 1: The left shows a density f(p)=4p for p∈[0,1/2] and k=10 for k=11; the right panel shows that, while ex-ante fixed policies concentrate selection near k=12, contextual policies asymptotically prioritize features with extreme means (orange triangles), reflecting the largest instance-specific surprise.
This result is underpinned by new explicit characterizations of asymptotic loss for both agent types under different policies. The analysis demonstrates that contextual highlighting strictly improves upon any fixed subset, and the improvement is first-order as the number of features grows.
Greedy Algorithms and Robustness
The study proposes and analyzes several practical algorithms for contextual highlighting, including:
- A deviation heuristic, revealing the k=13 features with largest absolute deviation from marginal means, which is provably optimal in the independent case.
- Marginal value and greedy information gain heuristics, which are sequential and handle correlated features by updating posteriors after each selection.
A key finding is that, even in the presence of weak correlations, the deviation heuristic and its greedy variants are nearly optimal when the mean-shift induced by conditional dependence is controlled. However, with strong feature correlation, revealing additional information can be non-monotonic for naive agents: in some cases, withholding information strictly reduces loss, as small-feature reveals may amplify posterior uncertainty through covariance structures.
Empirical Illustration on Real Data
The paper reports an extensive simulation study using American Housing Survey data (1,521 homes, 44 features) and Gaussian priors. Multiple fixed and contextual highlighting policies are compared on the task of jointly reconstructing all features and predicting log market value. The principal takeaways:
- Contextual greedy policies outperform all fixed highlighting approaches by a large margin, more than halving the average normalized loss at modest budgets (k=14).
- Accounting for feature covariance is essential; simple marginal or deviation heuristics underperform compared to posterior-updating greedy algorithms.
- The optimal number of highlights is not monotonic—contextual policies with judicious early stopping achieve lower loss than full reveal by avoiding the inclusion of highly correlated, low-informative features.
- Robustness studies show that sophisticated updating always weakly improves over naive updating in synthetic data but may not in misspecified real data due to empirical conditioning errors.
The formal analysis places this model within the broader area of algorithmic information design and connects it to Bayesian persuasion and constrained evidence selection. The conceptual extension to continuous feature spaces (e.g., with Gaussian features) highlights that optimal highlighting for sophisticated agents becomes an instance of constrained information design with highly non-trivial solutions—much more complex than for naive agents.
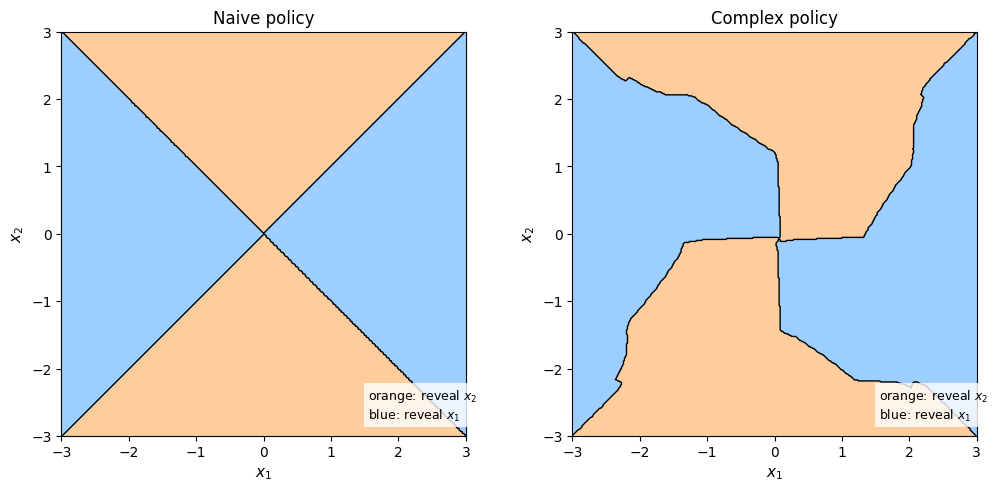
Figure 2: The highlighted regions under a naive policy (vertical stripes) versus a numerically optimized complex policy for a sophisticated agent in the Gaussian recovery case, evidencing the complexity of optimal sophisticated highlighting.
The framework is extensible to more general belief models (stereotype-based agents, agents with private information), as well as environments with misaligned priors or loss functions, incorporating elements of robust and persuasion-theoretic design.
Theoretical and Practical Implications
The results underscore that modeling human inference about the selective highlighting process is central in designing effective human-AI decision systems. Optimizing only for sophisticated agents is computationally intractable and not robust, while policies optimized for naive updating are not necessarily optimal for more sophisticated recipients. However, practical greedy algorithms—especially those robust to mis-optimization—offer computational and interpretability benefits, achieving near-optimal tradeoffs in realistic settings.
Highlighting as information support mechanisms, rather than producing black-box recommendations or summaries, enables verifiable, interpretable, and trust-enhancing AI assistance. The findings advocate for algorithmic feature highlighting as a tool for human-algorithm complementarity, particularly in domains where the ultimate decision rests with a human agent with limited attention and uneven belief sophistication.
Conclusion
The paper delivers a rigorous conceptual, computational, and empirical account of algorithmic feature highlighting for human-AI joint decision-making. It demonstrates that:
- Human interpretation of selective feature highlighting dramatically impacts loss and thus must be explicitly modeled in system design.
- Contextual, instance-wise highlighting dominates fixed subset methods, and greedy policies are both tractable and effective under broad conditions.
- Sophisticated belief-formation on the part of the human complicates policy design, producing NP-hard computational problems, intricate optimal policies, and exposes naive agents to potential manipulation or confusion when such policies are deployed.
The results motivate a research agenda focused on developing robust, transparent, and context-adaptive highlighting systems as central components of interpretable and trustworthy AI-human collaborations.