Trust in AI emerges from distrust in humans: A machine learning study on decision-making guidance
Abstract: This study explores the dynamics of trust in AI agents, particularly LLMs, by introducing the concept of "deferred trust", a cognitive mechanism where distrust in human agents redirects reliance toward AI perceived as more neutral or competent. Drawing on frameworks from social psychology and technology acceptance models, the research addresses gaps in user-centric factors influencing AI trust. Fifty-five undergraduate students participated in an experiment involving 30 decision-making scenarios (factual, emotional, moral), selecting from AI agents (e.g., ChatGPT), voice assistants, peers, adults, or priests as guides. Data were analyzed using K-Modes and K-Means clustering for patterns, and XGBoost models with SHAP interpretations to predict AI selection based on sociodemographic and prior trust variables. Results showed adults (35.05\%) and AI (28.29\%) as the most selected agents overall. Clustering revealed context-specific preferences: AI dominated factual scenarios, while humans prevailed in social/moral ones. Lower prior trust in human agents (priests, peers, adults) consistently predicted higher AI selection, supporting deferred trust as a compensatory transfer. Participant profiles with higher AI trust were distinguished by human distrust, lower technology use, and higher socioeconomic status. Models demonstrated consistent performance (e.g., average precision up to 0.863). Findings challenge traditional models like TAM/UTAUT, emphasizing relational and epistemic dimensions in AI trust. They highlight risks of over-reliance due to fluency effects and underscore the need for transparency to calibrate vigilance. Limitations include sample homogeneity and static scenarios; future work should incorporate diverse populations and multimodal data to refine deferred trust across contexts.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper asks a simple question: when do people turn to AI (like ChatGPT) for help, and why? The authors introduce a new idea called “deferred trust.” It means that when people don’t trust humans (like peers, adults, or priests) to guide them, they may “defer” or shift their trust to AI instead—especially when they see AI as more neutral, smart, or fair.
Goals and questions the study tried to answer
The study explored how people choose between AI and humans for advice in different situations. It focused on four easy-to-understand questions:
- Which helper (AI, voice assistant, peer, adult, or priest) do people pick most often?
- Do people prefer different helpers in different kinds of situations?
- What personal factors (like age, tech habits, or prior trust in humans) predict choosing AI?
- What makes some people more likely than others to trust AI?
How the study worked (methods, in simple terms)
The researchers asked 55 university students to go through 30 short scenarios and choose one guide for each scenario. The scenarios were of three types:
- Factual (e.g., finding the year the light bulb was invented)
- Emotional (e.g., advice about feelings)
- Moral (e.g., whether to seek revenge)
For each scenario, students picked one guide: an AI chatbot (like ChatGPT), a voice assistant (like Siri/Alexa), a peer (someone their age), an adult, or a priest.
The researchers also collected information about each student, like:
- How much they use technology
- Their socioeconomic level (a general sense of resources and access)
- How much they already trust AI, priests, peers, and adults
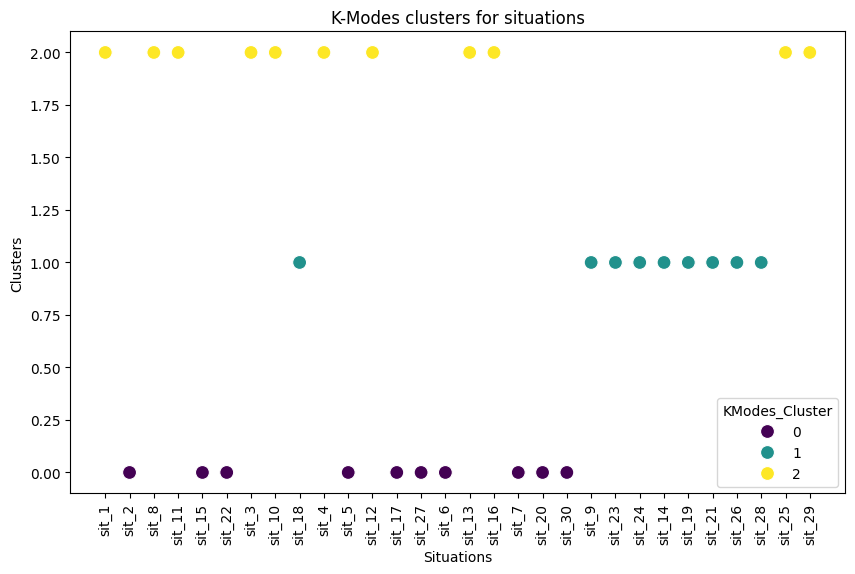
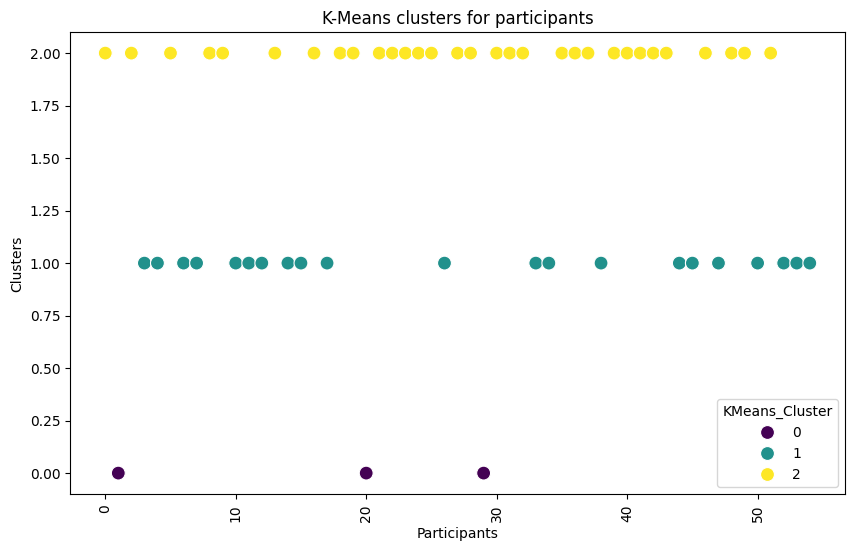
To find patterns in the choices, they used:
- Clustering (grouping): Think of it like sorting socks. K-Means and K-Modes are methods that group similar things together—either similar scenarios or similar people based on their choices.
- A prediction model (XGBoost): Imagine a big team of simple “if-then” rules voting together to predict whether someone will choose AI.
- SHAP (explanations): This shows which factors mattered most in the predictions, like a scoreboard that gives “credit” to each factor for the final decision.
What they found and why it matters
Here are the main takeaways from the study:
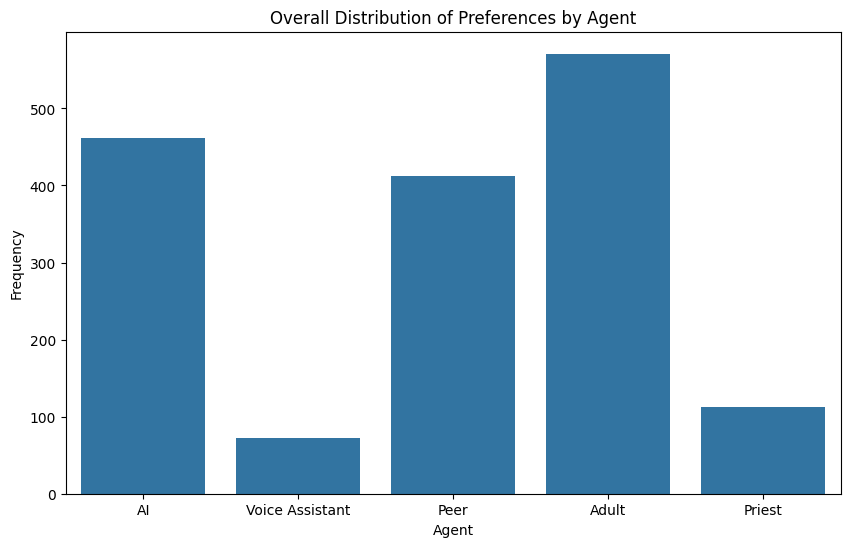
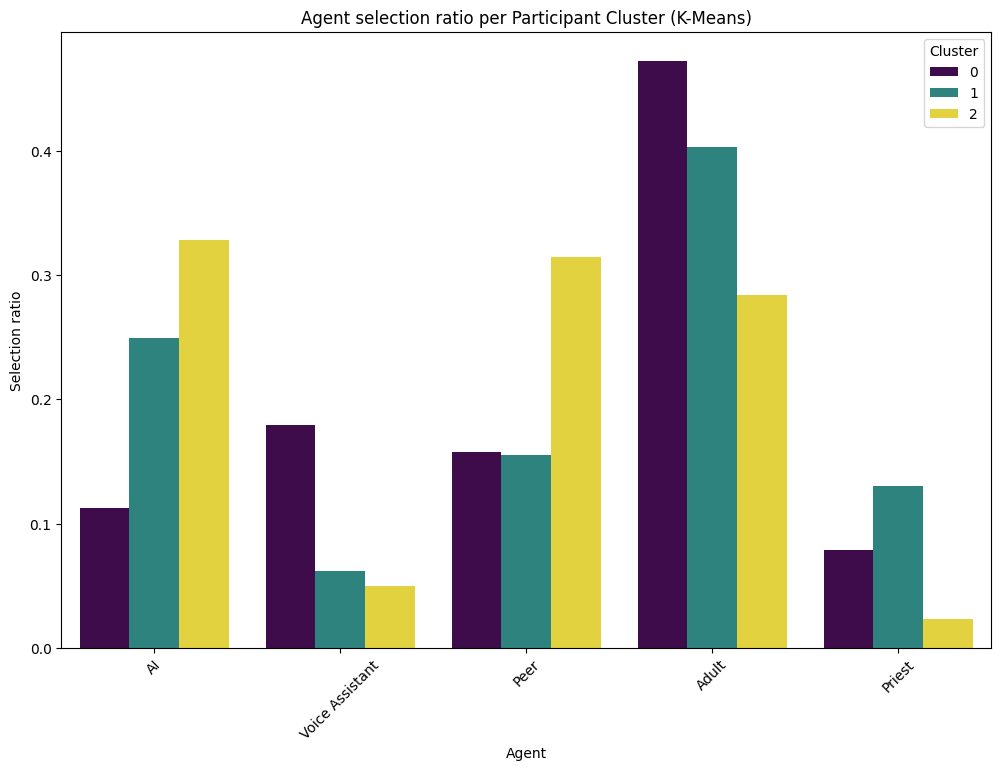
- Adults were chosen most often overall, but AI was a close second.
- Adults: about 35% of the time
- AI: about 28% of the time
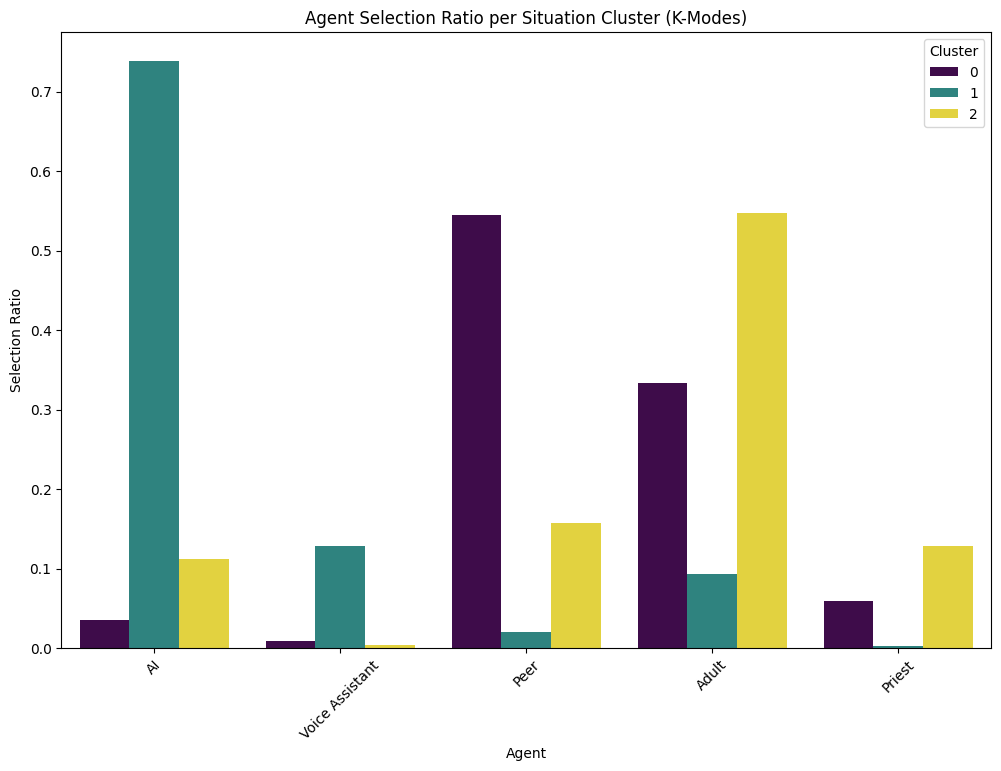
- People preferred AI in fact-based situations (like looking up exact information).
- People preferred humans (especially adults or peers) for social, emotional, or moral situations.
The most important pattern:
- When someone trusted human guides (peers, adults, priests) less, they were more likely to choose AI. This supports the “deferred trust” idea: distrust in humans can push people to rely on AI.
Who tended to trust AI more?
- People who had lower trust in human guides
- People with higher socioeconomic status
- Surprisingly, people who reported lower general technology use sometimes trusted AI more (possibly because heavy tech users are more cautious and “fact-check” more)
Why this matters:
- It shows that people don’t just pick AI because it’s useful—sometimes they pick it because they doubt humans.
- It also warns that AI’s smooth, confident answers can make people lower their guard, even when AI might be wrong. This is called a “fluency effect”—when something sounds polished, we believe it more.
What this could mean for the future
- For designers and companies: Make AI tools more transparent and explain how answers are produced. Help users check sources and spot uncertain answers. This can prevent blind trust.
- For schools and families: Teach “AI fact-checking” habits—treat AI like a smart assistant, not a perfect authority. Encourage questions like: Where did this answer come from? Is there bias? Is this the kind of problem a human should handle?
- For society: Be careful about “trust displacement.” If people lose trust in each other and always turn to algorithms, we could weaken important human relationships. The goal should be healthy teamwork between humans and AI, not replacing one with the other.
Note on limitations:
- The study used a small group of university students from one place, and the scenarios were text-based. Real-life situations are messier. Future studies should include more diverse people and more realistic interactions (like live conversations with AI or long-term use).
Overall, this study suggests that trust in AI sometimes grows not because AI is perfect, but because people feel unsure about human guides. Recognizing that shift can help us design safer AI, teach better digital habits, and keep human trust strong where it matters most.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of unresolved issues, methodological limitations, and actionable open questions that future research could address.
- Causal inference is missing: deferred trust is inferred from correlations; no experimental manipulation of human-agent distrust or transparency to test whether distrust causes increased AI reliance.
- No direct measurement of epistemic vigilance, fluency effects, automation bias, or algorithm appreciation; claims rely on theory rather than task-based or scale-based assessments.
- The “Trust in AI: Situations by Specific Nature” instrument lacks standard psychometric validation (content validity, factor structure, reliability coefficients, test–retest); clustering is not an adequate substitute.
- Scenario taxonomy (factual vs emotional vs moral) is not independently validated; mapping of K-Modes clusters to these types is asserted but not empirically checked.
- Scenario presentation and order effects are unreported (e.g., randomization/counterbalancing); potential priming or fatigue biases remain unexamined.
- Static, text-only scenarios do not involve real interactions or outputs from LLMs/voice assistants; fluency, explainability, source cues, or error exposure cannot be observed.
- Multi-level data structure is ignored: 30 repeated decisions nested within participants are analyzed with standard CV, not hierarchical models; within-subject dependence and participant-level leakage likely inflate model performance.
- Cross-validation appears to mix decisions from the same participants across folds; group-wise CV by participant is needed to avoid leakage and overoptimistic metrics.
- Overfitting risk with XGBoost and Bayesian hyperparameter tuning on a very small sample (N=55) and many models; no external validation or holdout test set is provided.
- Model calibration is not evaluated (e.g., Brier score, calibration curves); conclusions about predictive reliability omit how well predicted probabilities reflect outcomes.
- Binary classifiers per agent ignore mutual exclusivity and interdependence among agent choices; a multinomial/mixed-effects approach could better capture the choice structure.
- Cluster validity is weak (e.g., K-Means DB index ≈ 2.06); cluster number (k=3) is pre-set without robust selection (silhouette/elbow/bootstrapped stability), and poor separation is not discussed.
- Feature engineering and data quality issues: near-zero-variance features (e.g., “Energy = 1.0”; “Internet = 1.0”) are included; no feature selection or assessment of their impact is reported.
- Prior trust variables (AI, peers, adults, priests) are not described in terms of item content, scale anchors, or validation; how these scales capture “trust” versus “trustworthiness” is unclear.
- Socioeconomic status measurement is not defined (e.g., local strata vs income); potential confounding with access to technology, urbanicity, and institutional trust is not addressed.
- Religiosity and religious affiliation are not measured, limiting interpretation of “priest trust” and its role in deferred trust; cultural specificity (Colombia, predominantly Catholic) constrains generalization.
- Sample is demographically narrow (55 undergraduates, 82% women, age ≈ 19.4) from a single institution and country; gender, age, program (Psychology vs Nursing), and cultural differences are not analyzed.
- Voice assistants vs LLMs distinction may be unclear to participants; perceived overlap could confound comparisons; manipulation checks of agent understanding are not reported.
- No assessment of risk severity or stakes in scenarios; without quantifying vulnerability/uncertainty, it’s unclear when deferred trust is more likely to emerge.
- No outcomes-based evaluation: trust calibration is discussed theoretically, but actual accuracy, fairness, or harm from agents’ guidance is not measured; selection behavior is not tied to downstream results.
- Longitudinal stability of preferences and trust transfer is unknown; repeated exposure, error encounters (e.g., hallucinations), or learning effects are not examined.
- Cross-cultural and cross-linguistic generalizability is untested; the experiment is in Spanish with locally salient agents (e.g., priests); boundary conditions in secular or different cultural settings remain open.
- The role of AI literacy, transparency cues, and explanations is hypothesized but not manipulated; which interventions actually reduce uncritical deference remains untested.
- Ethical/moral domain boundaries are not examined (e.g., severity, moral foundations, personal vs societal harm); conditions for appropriate vs inappropriate AI reliance in moral decisions remain unclear.
- No statistical tests of differences across clusters or scenario types (beyond descriptive ratios); effect sizes, confidence intervals, and significance for key contrasts are not reported.
- Pre-registration and analytic transparency are absent; many modeling choices (k selection, hyperparameter spaces, preprocessing) could introduce researcher degrees of freedom.
- Reproducibility claim lacks a link to code/data; without access, independent verification and robustness checks are limited.
- Open question: Does deferred trust vary by type of distrusted human agent (e.g., peers vs experts vs institutions), and does domain expertise moderate the transfer?
- Open question: What transparency/credibility cues (e.g., sources, uncertainty displays, inconsistency flags) effectively calibrate deferred trust without eroding justified reliance?
- Open question: How do real-time conversational qualities (fluency, politeness, anthropomorphism) modulate vigilance thresholds in interactive settings compared to static prompts?
- Open question: Under what conditions does deferred trust lead to harmful over-reliance (e.g., in health, finance, law), and which hybrid human–AI oversight designs mitigate those risks?
- Open question: How do individual differences (e.g., cognitive reflection, need for cognition, skepticism, prior negative AI experiences) shape the emergence and boundaries of deferred trust?
- Open question: Is deferred trust stronger when human agents are perceived as biased (ideological, religious, or social) versus incompetent, and can interventions distinguish and address these drivers?
- Open question: Do error transparency and post-hoc accountability (for AI and humans) differentially recalibrate trust transfer over time?
Practical Applications
Practical applications derived from the paper
The paper introduces deferred trust—a compensatory mechanism whereby lower prior trust in human agents predicts higher reliance on AI—validated via clustering (K-Modes, K-Means) and interpretable prediction (XGBoost + SHAP). It also shows context effects (AI favored for factual tasks; humans for social/moral) and identifies user profiles (e.g., higher SES, lower tech use, and lower trust in humans linked to higher AI selection). Below are applications grounded in these findings and methods.
Immediate Applications
- Trust-aware routing of guidance requests — software, customer service, public sector
- What: Automatically route factual queries to AI and social/moral/values-laden cases to human agents.
- How: Use a lightweight scenario classifier (inspired by the paper’s K-Modes clusters) embedded in chatbots/help desks.
- Tools/workflows: Intent detection + scenario tags; rules for escalation; audit logs.
- Assumptions/dependencies: Reliable scenario detection; adequate human staffing; clear policy for edge cases.
- Trust calibration UX patterns — software, healthcare, finance, education
- What: Interfaces that reduce over-reliance on fluent but fallible AI (e.g., show uncertainty, citations, source links, alternative viewpoints).
- How: Add confidence indicators, provenance, and “second opinion” prompts; expose model limits for moral/personal topics.
- Tools/workflows: Citation retrieval, uncertainty heuristics, explanation templates.
- Assumptions/dependencies: Access to sources/references; feasible uncertainty estimation; user-testing for comprehension.
- Personalized trust profiles for adaptive safeguards — software, enterprise, education
- What: Short intake items probing prior trust in human advisors (e.g., peers, adults, authority figures) to trigger extra safeguards when deferred trust is likely.
- How: A brief questionnaire or behavioral proxy to set caution modes (e.g., require multiple sources, human review).
- Tools/workflows: Profile → policy engine; SHAP-like logic for explainable triggers.
- Assumptions/dependencies: Privacy-safe collection and storage; consent; fairness controls to avoid stereotyping.
- Hybrid human–AI escalation policies — healthcare, legal, finance, HR
- What: Require human oversight for social/moral decisions; use AI for bounded factual work (summaries, retrieval).
- How: Decision trees linking scenario type to oversight level; audit trails documenting rationale.
- Tools/workflows: Case triage, role-based approvals, red-teaming for moral risk.
- Assumptions/dependencies: Clear delineation of “moral/personal” vs “factual”; regulatory alignment; training for staff.
- Epistemic vigilance training — education, corporate L&D, public literacy
- What: Teach users to spot fluency-driven over-reliance and calibrate trust in AI vs humans.
- How: Microlearning modules with adversarial examples; checklists for verifying claims; compare AI and human outputs.
- Tools/workflows: Interactive lessons; scenario-based quizzes adapted from the study’s items.
- Assumptions/dependencies: Curriculum time; localized content; assessment rubrics.
- Auditing trust displacement with the 30-scenario instrument — academia, product research, policy pilots
- What: Use or adapt the study’s scenario battery to assess where users over-select AI due to human distrust.
- How: Pre/post assessments in schools, workplaces, or public service portals; cluster analysis to segment contexts/profiles.
- Tools/workflows: Survey platform; K-Means/K-Modes analysis; dashboarding.
- Assumptions/dependencies: Cultural adaptation; IRB/ethics where needed; basic analytic capacity.
- Customer support triage with safety guardrails — software, e-commerce, telecom
- What: AI handles factual tasks (billing info, status checks); human takes retention, grievance, or sensitive cases.
- How: Conversation classifiers; policy-driven handoffs; transparency banners explaining routing.
- Tools/workflows: Intent taxonomy; playbooks; QA sampling.
- Assumptions/dependencies: Intent accuracy; SLAs for handoff; training data diversity.
- Patient and client education “dual-justification” content — healthcare, finance, government
- What: Present AI-generated explanations with human-endorsed summaries to avoid undermining human experts when users distrust them.
- How: Pair AI outputs with clinician/advisor review notes; highlight convergence/divergence.
- Tools/workflows: Co-authoring templates; provenance tags; version control.
- Assumptions/dependencies: Time for review; medico-legal compliance; accessible language.
- Small-sample, interpretable ML pipeline for behavioral insights — academia, user research, policy analytics
- What: Reuse the paper’s XGBoost + SHAP + careful CV/imbalance protocol for transparent prediction on limited datasets.
- How: Open-source packages; reproducible scripts; SHAP for stakeholder explanations.
- Tools/workflows: scikit-learn, xgboost, shap; reproducible configs.
- Assumptions/dependencies: Analyst expertise; careful validation; avoidance of overfitting.
- Personal decision hygiene practices — daily life
- What: Simple self-checks when seeking guidance: if I distrust a person/group, am I over-weighting AI? Have I verified sources?
- How: A 3-step checklist (identify scenario type, check at least two sources, get a human view for moral/personal issues).
- Tools/workflows: Browser extensions or printable prompts.
- Assumptions/dependencies: User willingness; accessible source material.
Long-Term Applications
- Trust-aware orchestration layers for AI systems — software platforms, multi-agent systems
- What: Real-time “deferred trust estimators” that adapt model behavior, uncertainty displays, and oversight based on inferred user trust states and context.
- How: Behavioral signals + brief probes → policy engine; dynamic escalation; diversity-of-opinion generation.
- Tools/workflows: Context classifiers; user-state models; risk-tiered responses.
- Assumptions/dependencies: Reliable user-state inference; privacy-by-design; robust evaluation against bias.
- Sector standards for reliability metadata — policy, standards bodies, software ecosystem
- What: Require machine-readable provenance, confidence, and limitation statements in public-facing AI.
- How: Schema definitions; compliance tests; UI guidelines.
- Tools/workflows: Open standards; conformance suites; audits.
- Assumptions/dependencies: Multi-stakeholder buy-in; feasible uncertainty quantification; international harmonization.
- Cross-cultural, longitudinal validation of deferred trust — academia, policy
- What: Large-scale, diverse studies (age, culture, SES) and multimodal measures (e.g., gaze, GSR, EEG) to refine the theory and tools.
- How: Standardized scenario banks; preregistered protocols; open datasets.
- Tools/workflows: Mixed methods; federated data governance; ethics frameworks.
- Assumptions/dependencies: Funding; data protections; interoperable measures.
- Governance to prevent trust displacement — policy, public institutions, education
- What: Safeguards so AI complements rather than erodes interpersonal trust (e.g., “human-relational minimums” in health, education, justice).
- How: Mandate human options; transparency on when AI is used; appeal mechanisms.
- Tools/workflows: Ombuds processes; civic literacy campaigns.
- Assumptions/dependencies: Legislative action; institutional capacity; monitoring.
- Domain-specific co-pilot protocols with calibrated refusals — healthcare, legal, finance, HR
- What: AI that gracefully refuses or defers in moral/personal contexts and offers resource pathways.
- How: Safety policies tuned to scenario classes; refusal UX; referral directories.
- Tools/workflows: Risk taxonomies; human-in-the-loop queues; incident reviews.
- Assumptions/dependencies: Accurate topic/risk detection; alignment with duty-of-care norms.
- Ethical segmentation and marketing guidelines — platforms, advertising, content moderation
- What: Prevent exploiting groups more prone to defer to AI due to human distrust (e.g., targeted persuasion).
- How: Limits on microtargeting; fairness audits for “trust state” personalization.
- Tools/workflows: Policy checklists; bias/impact assessments.
- Assumptions/dependencies: Enforcement mechanisms; third-party audits.
- Public-service chatbots with institutional trust bridging — government, public health, emergency comms
- What: AI agents that present institution-backed content with multi-source corroboration and rapid human escalation during crises.
- How: Content provenance pipelines; uncertainty-aware messaging; community liaison integration.
- Tools/workflows: Source registries; escalation rotas; message testing.
- Assumptions/dependencies: Trusted content sources; surge capacity; misinformation monitoring.
- Educational benchmarks and curricula on AI trust — academia, edtech
- What: Open benchmark suites of scenarios to assess and teach appropriate reliance and epistemic vigilance.
- How: Grade-level scenario sets; analytics dashboards; teacher PD modules.
- Tools/workflows: LMS integrations; adaptive assessments.
- Assumptions/dependencies: Curriculum adoption; accessibility; teacher training.
- Multi-perspective AI advisors — software, media, civic tech
- What: Systems that automatically generate contrasting expert perspectives to reduce uncritical deference to a single source.
- How: Diverse model ensembles; retrieval from heterogeneous sources; argument mapping.
- Tools/workflows: Evidence weighting; conflict resolution UX.
- Assumptions/dependencies: Source diversity; guardrails against false balance; user comprehension.
- Organization-wide “trust dashboards” — enterprises, hospitals, governments
- What: Monitor AI reliance patterns, escalation rates, and over-reliance indicators across teams and services.
- How: Telemetry on scenario types and handoffs; alerts when moral/personal topics lack human review.
- Tools/workflows: BI dashboards; KPI definitions; governance forums.
- Assumptions/dependencies: Data privacy; thoughtful metrics; change management.
Notes on feasibility across applications:
- Generalizability limits: findings are from a small, relatively homogeneous sample (Spanish-speaking undergraduates), so pilots should include local validation.
- Model and UI reliability: uncertainty estimates, scenario classifiers, and explanations must be properly evaluated to avoid false reassurance.
- Privacy and fairness: collecting “trust profiles” requires explicit consent, minimal data practices, and bias monitoring.
- Organizational readiness: hybrid workflows need staffing, training, and clear accountability to work in practice.
Glossary
- Algorithm appreciation: Tendency to favor algorithmic judgments over human ones when perceived as more accurate or impartial. "automation bias and algorithm appreciation, whereby humans tend to over-rely on automated outputs even when these are imperfect"
- Anthropomorphism: Attributing human characteristics or intentions to AI systems. "higher perceptions of anthropomorphism, perceived cognitive competencies of AI agent"
- Automation bias: Systematic over-reliance on automated systems, sometimes despite errors. "phenomena such as automation bias and algorithm appreciation"
- Average precision: A performance metric summarizing precision across recall levels (area under the precision–recall curve). "Average precision (Sit 24 = 0.8813 ± 0.0872, Sit 26 = 0.8638 ± 0.0995, Sit 9 = 0.8705 ± 0.0801)"
- Bayesian optimization: Strategy for tuning hyper-parameters using probabilistic models to efficiently explore the search space. "hyper-parameters were tuned separately for each agent-scenario combination using Bayesian optimization BayesSearchCV from scikit-optimization"
- BayesSearchCV: Scikit-optimize tool for Bayesian hyper-parameter search with cross-validation. "using Bayesian optimization BayesSearchCV from scikit-optimization"
- Bee-swarm: Beeswarm-style summary visualization of SHAP values showing feature impact across samples. "Summary plots (bee-swarm) and individual dependence plots were generated for each trained model."
- Class imbalance: Unequal distribution of classes in a dataset that can bias model training. "Class imbalance was addressed by automatically setting \texttt{scale_pos_weight = negative /positive} (or a slightly higher value when SMOTE was applied)."
- Cross-validation: Model evaluation procedure that partitions data into folds to assess generalization. "Cross-validation strategy was adaptive: RepeatedStratifiedKFold (5 folds × 3--5 repeats) when sufficient minority-class samples were available; otherwise a reduced StratifiedKFold (2--4 folds) was employed"
- Davies-Bouldin Index: Cluster validity metric measuring average similarity between clusters; lower is better. "Clusters by k-modes algorithm obtained Davies-Bouldin Index = 0.809, Dunn-like Index = 1.052, SD Index: 0.768."
- Deferred trust: Cognitive mechanism where distrust in human agents redirects reliance toward AI perceived as more neutral or competent. "introducing the concept of 'deferred trust', a cognitive mechanism where distrust in human agents redirects reliance toward AI perceived as more neutral or competent."
- Dummy variables: Binary indicator features representing categories for modeling. "Each scenario was decomposed into dummy variables representing the selection or non-selection of each agent"
- Dunn-like Index: Cluster validity index assessing cluster compactness and separation. "Dunn-like Index = 1.052"
- Embodied agents: AI systems with a physical or virtual body that interact in immersive environments. "leveraging conversational interfaces, embodied agents, or virtual reality contexts"
- Epistemic deference: Yielding one’s judgment to a source presumed to have superior knowledge. "deferred trust functions as a compensatory redirection of epistemic deference"
- Epistemic trust: Trust grounded in perceived competence, accuracy, and reliability of an agent. "This concept can be sub-categorized into epistemic trust, related to perception of the competence and reliability of the evaluated agent"
- Epistemic vigilance: Cognitive safeguards that assess credibility, coherence, and relevance to filter unreliable information. "Epistemic vigilance functions as a safeguard in human communication, enabling individuals to filter unreliable information by assessing credibility, coherence, and relevance"
- Epistemic vulnerability: Susceptibility to being misled due to limitations in monitoring source reliability. "has introduced new forms of epistemic vulnerability"
- External validity: Degree to which results generalize to other settings, populations, or contexts. "To assess its internal consistency and explore its external validity, clustering analyses were conducted"
- Generative artificial intelligence: AI capable of producing novel content (text, images, etc.) from learned patterns. "AI has permeated human practices through the dynamics of generative artificial intelligence"
- Huang initialization: Initialization method for KModes clustering proposed by Huang to seed modes. "initialization method = Huang"
- Hybrid human-AI oversight: Governance approach combining human supervision with AI systems to ensure reliability. "such as reliability metadata, calibration training, or hybrid human-AI oversight"
- Hyper-parameters: Configuration settings for learning algorithms that are set prior to training. "hyper-parameters were tuned separately for each agent-scenario combination"
- K-Means: Centroid-based clustering algorithm for continuous data. "K-Means was performed with the scikit-learn implementation using KMeans(n_clusters = 3, init = 'k-means++', n_init = 10, max_iter = 300, random_state = 42)"
- K-Modes: Clustering algorithm for categorical data using modes and dissimilarity measures. "We first applied a K-Modes clustering algorithm to the 30 experimental scenarios"
- k-means++: Improved centroid initialization scheme for K-Means that speeds up convergence. "init = 'k-means++'"
- LLMs: High-parameter AI models trained on vast text corpora to perform language tasks. "LLMs, such as ChatGPT, Gemini, or Claude"
- Log-uniform: Probability distribution where the logarithm of the variable is uniformly distributed; used for sampling hyper-parameters. "learning_rate ∈ 0.005, 0.3"
- One-hot encoding: Encoding categorical variables as mutually exclusive binary vectors. "transformed the data into a binary classification format using one-hot encoding."
- Positive machine heuristics: Cognitive bias favoring machine outputs as objective or superior. "supports notions of algorithm appreciation and positive machine heuristics"
- RepeatedStratifiedKFold: Cross-validation scheme that repeats stratified K-fold splits multiple times. "RepeatedStratifiedKFold (5 folds × 3--5 repeats)"
- Reliability metadata: Supplementary information indicating the trustworthiness or accuracy of sources or models. "external safeguards, such as reliability metadata"
- ROC-AUC: Area under the Receiver Operating Characteristic curve, measuring discrimination across thresholds. "ROC-AUC (Sit 24 = 0.6118 ± 0.1779, Sit 26 = 0.5431 ± 0.2380, Sit 9 = 0.6347 ± 0.1508)"
- scale_pos_weight: XGBoost parameter that weights the positive class to mitigate imbalance. "scale_pos_weight = negative /positive"
- SD Index: Cluster validity metric combining measures of scatter/density. "SD Index: 0.768."
- SDbw Index: Cluster validation index integrating scatter and density between and within clusters. "SDbw Index = 1.631"
- Selective trust: Reliance on certain sources without verifying all information, often based on perceived expertise. "including epistemic trust (perceived competence and reliability), selective trust (reliance on unverified knowledge), and the activation of epistemic vigilance"
- SHapley Additive exPlanations (SHAP): Game-theoretic method that attributes model output to feature contributions. "SHapley Additive exPlanations (SHAP) were computed using TreeExplainer on the final models."
- SMOTE: Synthetic Minority Over-sampling Technique to balance minority classes by creating synthetic examples. "when SMOTE was applied"
- StandardScaler: Preprocessing tool that scales features to zero mean and unit variance. "standardized using StandardScaler (zero mean, unit variance)."
- StratifiedKFold: Cross-validation that preserves class proportions within each fold. "otherwise a reduced StratifiedKFold (2--4 folds) was employed"
- TAM (Technology Acceptance Model): Framework explaining technology adoption via perceived usefulness and ease of use. "Traditional technology acceptance models like TAM, UTAUT and UTAU2"
- TreeExplainer: SHAP explainer tailored for tree-based models. "computed using TreeExplainer on the final models."
- Trust transfer theory: Theory that trust can be transferred from familiar entities to new agents or contexts. "This mechanism aligns with the trust transfer theory"
- UTAUT: Unified Theory of Acceptance and Use of Technology for modeling technology adoption. "Traditional technology acceptance models like TAM, UTAUT and UTAU2"
- UTAU2: Extended acceptance model (as referenced) building on UTAUT constructs. "Traditional technology acceptance models like TAM, UTAUT and UTAU2"
- XGBoost: eXtreme Gradient Boosting framework for efficient, regularized gradient-boosted trees. "eXtreme Gradient Boosting (XGBoost) decision tree models were used"
- XGBClassifier: XGBoost’s classification estimator implementation. "All models were trained with the XGBClassifier from the xgboost Python package"
Collections
Sign up for free to add this paper to one or more collections.

