- The paper introduces AstroVink, a vision transformer leveraging DINOv2 to pioneer high-throughput strong lens detection in Euclid Q1 data.
- It evaluates eight input representations and employs staged domain adaptation to optimize recovery rates and handle class imbalance.
- Extensive experiments demonstrate near-complete lens recovery with improved inspection efficiency compared to traditional CNN methods.
Introduction
The identification of strong gravitational lenses is essential for advancing the precision of astrophysical and cosmological measurements. Traditional manual and classical automated methods have been severely limited by the rarity and morphological complexity of strong lenses in wide-area optical surveys. The paper "Euclid Quick Data Release (Q1). AstroVink: A vision transformer approach to find strong gravitational lens systems" (2604.21977) develops AstroVink, a vision transformer (ViT) leveraging DINOv2 for robust high-throughput lens discovery within the Euclid Q1 data release, establishing quantitative performance upper limits and workflow best practices for future wide-field lens-search pipelines.
AstroVink is trained and evaluated on Euclid Q1 survey imaging, covering approximately 63deg2 and delivering high-resolution photometry in VIS (I-band) and near-infrared via NISP (Y, J, H). Training and evaluation exploit both simulated and real cutouts ($10\arcsec \times 10\arcsec$) of galaxies, with positive samples derived from state-of-the-art strong lens simulations (Lenstronomy-based and GLAMER-based), augmented for orientation and positional variance, and a curated set of non-lenses including challenging morphologies (rings, mergers, spirals). Real lens candidates and hard false positives from SLDE and Space Warps citizen science vetting supplement the Q1 domain adaptation phase.
Eight input representations spanning different band combinations and scaling methods (arcsinh and MTF) are benchmarked for lens-discriminative efficiency. AstroVink performance is systematically compared across these combinations.
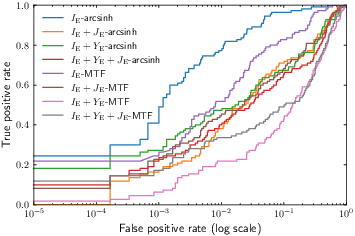
Figure 2: ROC curves for all band and scaling combinations; pure VIS (I-band)-arcsinh yields the highest AUC, demonstrating the optimality of this representation for the transformer in this data regime.
AstroVink Architecture and Training Pipeline
AstroVink is built on the DINOv2 ViT-S/14 backbone, leveraging large-scale self-supervised visual feature learning. During fine-tuning, all 12 transformer layers can be unfrozen or partially frozen to balance generalisation and domain adaptation. The classification head is a three-layer MLP with GELU activations and dropout for regularisation; the cross-entropy loss is adopted initially, with focal loss introduced during severe class imbalance and domain-shift retraining phases.
AstroVink reaches its best performance in the baseline phase with the I-band arcsinh input, AdamW optimizer, cosine learning-rate schedule, and batch size of 32. Extensive controlled experiments explore the effect of random seed, separate learning-rates for encoder and classifier, and the impact of mixing simulated and real samples. The model’s internal attention maps provide interpretability of its morphological focus.

Figure 1: Attention maps for various cutouts show that the ViT predominantly allocates attention to arcs and curved features crucial for distinguishing true lenses from analogues.
Baseline Results on Simulated-Only Training
When trained exclusively on high-fidelity lens simulations and labelled non-lenses, AstroVink achieves:
- AUC = 0.983 on the Q1 test set (110 confirmed lenses, ∼30,000 non-lenses)
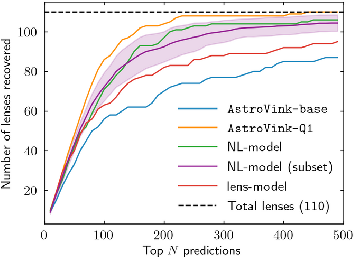
- 88/110 lens recovery in the top 500 predictions (inspection efficiency: 5.7 objects per lens)
- F1, precision, and recall metrics near 0.986 in 5-fold cross-validation
Impact of Q1 Real-Data Retraining
Domain adaptation using real Q1 confirmed lenses and hard non-lenses is critical. Naive retraining induces catastrophic forgetting; a staged, block-wise unfreezing and progressive replacement scheme, combined with focal loss and hard-negative mining, yields superior results.
Domain Adaptation and Model Generalisation
The catastrophic forgetting observed when exposing the ViT to domain-shifted Q1 data is addressed by selective freezing of early transformer blocks, ascertained through CLS token latent probing and CKA similarity analyses. Discriminative class information concentrates in blocks 9–12; freezing blocks 1–8 maintains transfer learning benefits while allowing high-level adaptation.
The transition from cross-entropy to focal loss further reduces misclassification on rare, ambiguous Q1-hard negatives, demonstrating the necessity of loss adaptation to rare-class detection. Additionally, a comprehensive K-fold validation framework is established across all training phases.
Automated Vetting and Discovery of Novel Candidates
AstroVink-Q1 is deployed on the full Q1 parent sample (∼1.08 million galaxies), identifying several dozen new high-grade (A/B) lens candidates not previously catalogued, validated through expert inspection and citizen science. The new discoveries exhibit morphologies underrepresented in simulations (e.g., edge-on lenses), highlighting the evolutionary interplay between training set diversity and detection sensitivity.

Figure 6: Montage of novel Grade~A/B lens candidates found exclusively by AstroVink-Q1, representative of the enrichment capacity from large-scale transformer models.
Implications and Prospects
AstroVink demonstrates that transformer-based architectures, when carefully adapted and augmented with both simulated and real data, significantly reduce the human bottleneck for lens discoveries in wide-field surveys, and probability-rank candidates with high completeness and purity. The strong AUC and inspection efficiency gains over CNN baselines are quantifiable and reproducible.
The interpretability granted by ViT attention maps promotes acceptance for science-driven candidate vetting. The efficacy of staged domain adaptation and hard-negative mining will generalise to other rare-phenomenon searches in cosmological imaging.
Future iterations should utilise loss surfaces tailored to extremely low positive rates, explore direct usage of full multi-channel calibration data rather than JPEG approximations, and scale to Euclid full mission area and other legacy imaging surveys. As ViTs become the default for astronomical image classification, the methodology pioneered in this work will underpin both supervised and self-supervised pipelines for rare-object discovery.
Conclusion
AstroVink establishes the state of the art for high-throughput, high-purity strong lens candidate identification in Euclid, achieving near-complete recovery of all Q1-confirmed lenses in a small candidate set. The workflow—leveraging DINOv2, staged domain-adaptive retraining, and interpretability diagnostics—provides a robust template for transformer-based rare-object searches in future large-scale surveys.