- The paper introduces AgileLens, a scalable CNN-based pipeline designed for identifying strong gravitational lenses within the Euclid Q1 data.
- Iterative human-in-the-loop methodologies enhance the CNN model, achieving a 65.8% recovery of expected strong lenses and identifying new candidates.
- Validated through expert inspections, AgileLens integrates real Euclid data with minimal simulations, showcasing a robust lens discovery approach.
Scalable CNN-Based Strong Gravitational Lens Identification in Euclid Q1: The AgileLens Pipeline
Introduction
"Euclid Quick Data Release (Q1). AgileLens: A scalable CNN-based pipeline for strong gravitational lens identification" (2604.06648) presents an end-to-end iterative pipeline for efficient discovery of strong galaxy-galaxy lensing systems within the initial Euclid Q1 imaging survey. Leveraging both the Visible (VIS) and Near-Infrared (NISP) instruments aboard Euclid, this work addresses the challenge of gravitational lens detection in vast, high-dimensional data, where manual approaches are infeasible. The pipeline introduces a human-in-the-loop, CNN-driven workflow with tailored cleaning, data augmentation, and repeated refinement stages, validated through expert visual inspection and graded candidate assessment.
Pipeline Overview and Data Preparation
The AgileLens pipeline is structured as an iterative, human-in-the-loop system that refines a CNN-based lens identification model through repeated cycles of data curation and network fine-tuning. The high-level workflow comprises (i) candidate ranking, (ii) training set update with newly identified lenses and hard negatives, and (iii) model fine-tuning, with iterations continuing until convergence (no additional lenses among top candidates). This systematic process is crucial for maximizing completeness and purity in the highly imbalanced lens detection problem.
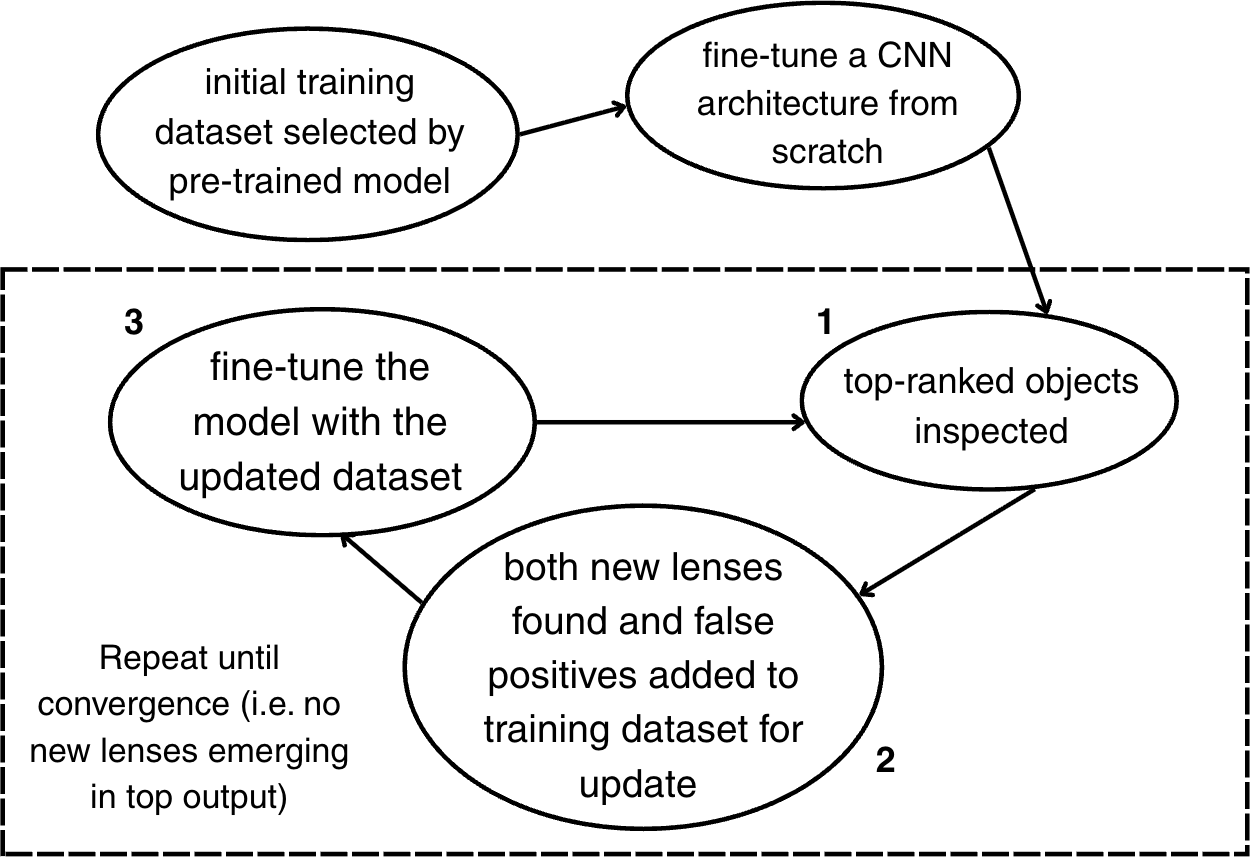
Figure 1: Schematic overview of the iterative pipeline showing candidate inspection, dataset update, and model fine-tuning steps.
Catalog-based pre-filtering is performed: sources are selected from VIS catalogs, with a point-source rejection, magnitude cuts at $\IE \leq 24$, and aggressive artefact/noise filtering. Subsequent image cleaning removes both large and small pixel-level defects and noisy fields, further ensuring high-quality 96×96 pixel cutouts suitable for CNN ingestion.
Positive seed lenses are initially sourced using a pre-trained VIS-only classifier, enabling selection in the absence of substantial labeled data. Scarce true positives are heavily augmented by geometric transformations, contrast/brilliance scaling, and, in later rounds, synthetic artistic lens injections (hand-drawn morphologies capturing visual diversity).

Figure 2: Examples of strong lens images constituting the initial positive set, expanded via geometric and photometric augmentation.
Balanced negative sets are generated through false-positive mining and subclassification, with an EfficientNetB0-based model deployed to stratify the primary negative morphologies: spiral arms, ellipticals, edge-on disks, and diffraction spike sources.
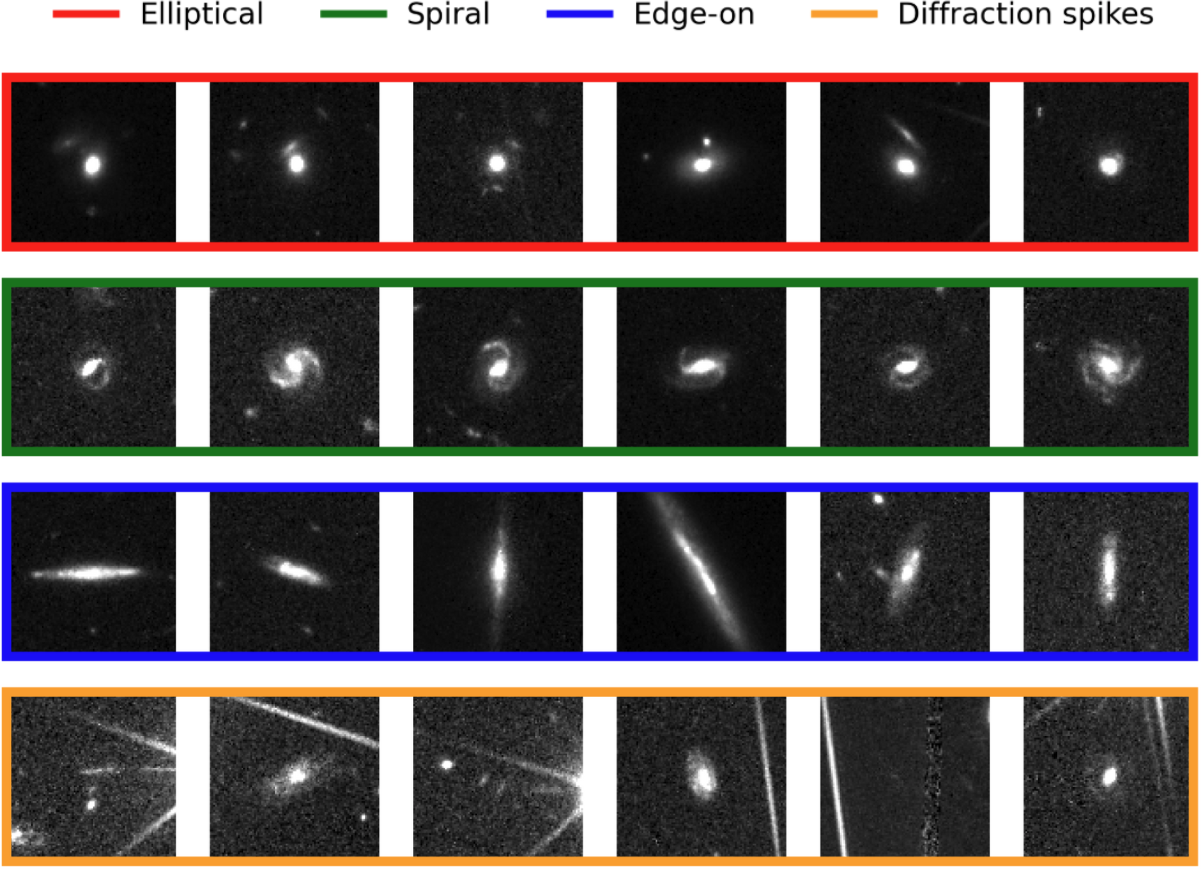
Figure 3: Representative false-positive morphologies misidentified as lenses in the initial supervised model.
Colour images for CNN input are constructed by merging VIS (morphology anchor) with NISP bands, after normalization and luminance projection to preserve spatial structure and color contrast.
CNN Architecture and Model Fine-Tuning
A comparative benchmarking of six compact CNN architectures is conducted using the curated Q1 training data. Modified VGG16 is selected as the primary classifier for its robust performance in expert-based validation. The custom architecture replaces the fully connected layers with a GlobalAveragePooling2D layer and 256/128-unit dense stacks, culminating in a sigmoid output for binary lens flagging.
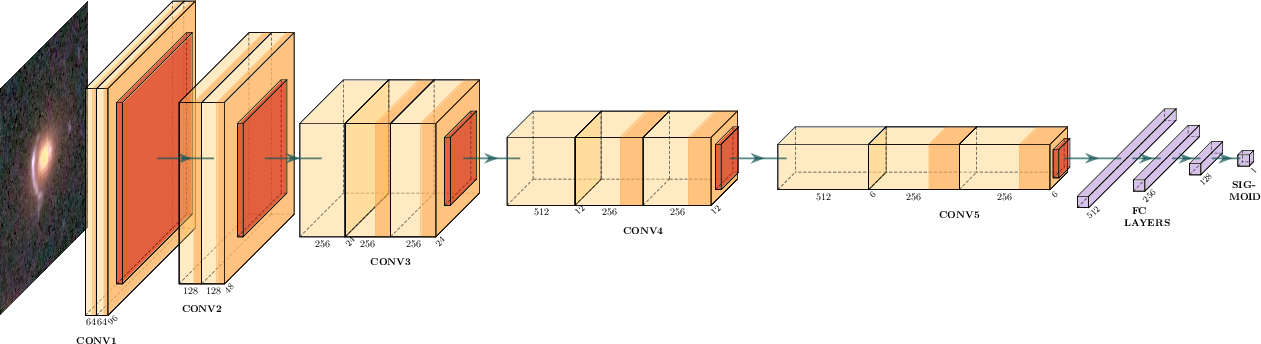
Figure 4: Modified VGG16 architecture with customized dense layers and terminal sigmoid output for binary classification.
Fine-tuning is carried out by unfreezing the last nine layers, balancing between adaptation to real Euclid data and overfitting suppression. Iterative retraining exploits hard-negatives and newly surfaced lenses at each iteration, with continual expert validation of the top-ranked CNN outputs, thus incrementally refining the classifier's discriminative boundary.
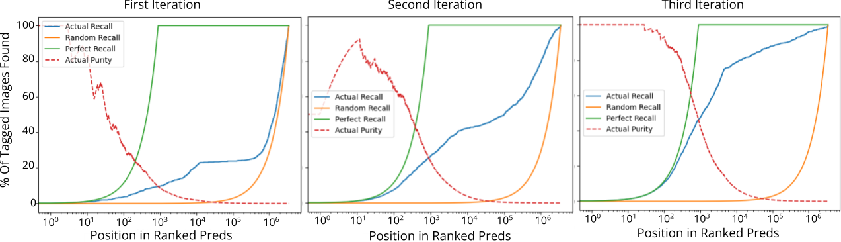
Figure 5: Evolution of recall and precision over three model retrainings, demonstrating convergence toward near-perfect recovery in the highest-ranked candidates.
Hand-crafted lens images further enhance the training set's morphological span, counterbalancing over-specialization to typical lens morphologies recovered in early iterations.

Figure 6: Hand-drawn lens simulations included in later rounds to diversify and regularize the positive training set.
After three pipeline iterations, the model achieves high lens concentration among the top predictions, demonstrably optimizing both purity and recall. Visual inspection and expert grading of the top-4000 ranked candidates—via the Galaxy Judges Zooniverse platform—yield:
- 441 grade A/B lensing systems identified in the ranking, comprising 311 overlapping with the existing Q1 catalogue and 130 new A/B candidates (9 grade A, 121 grade B) not previously reported.
- 81.8% (740/905) of high-confidence Q1 lens candidates (including off-centered samples) surfaced within the top 20,000 predictions.
Histograms of "raw scores" (i.e., pre-sigmoid last dense layer output) show strong separation between lens and non-lens classifications, and "raw score" distributions correlate monotonically with human-assigned grade.
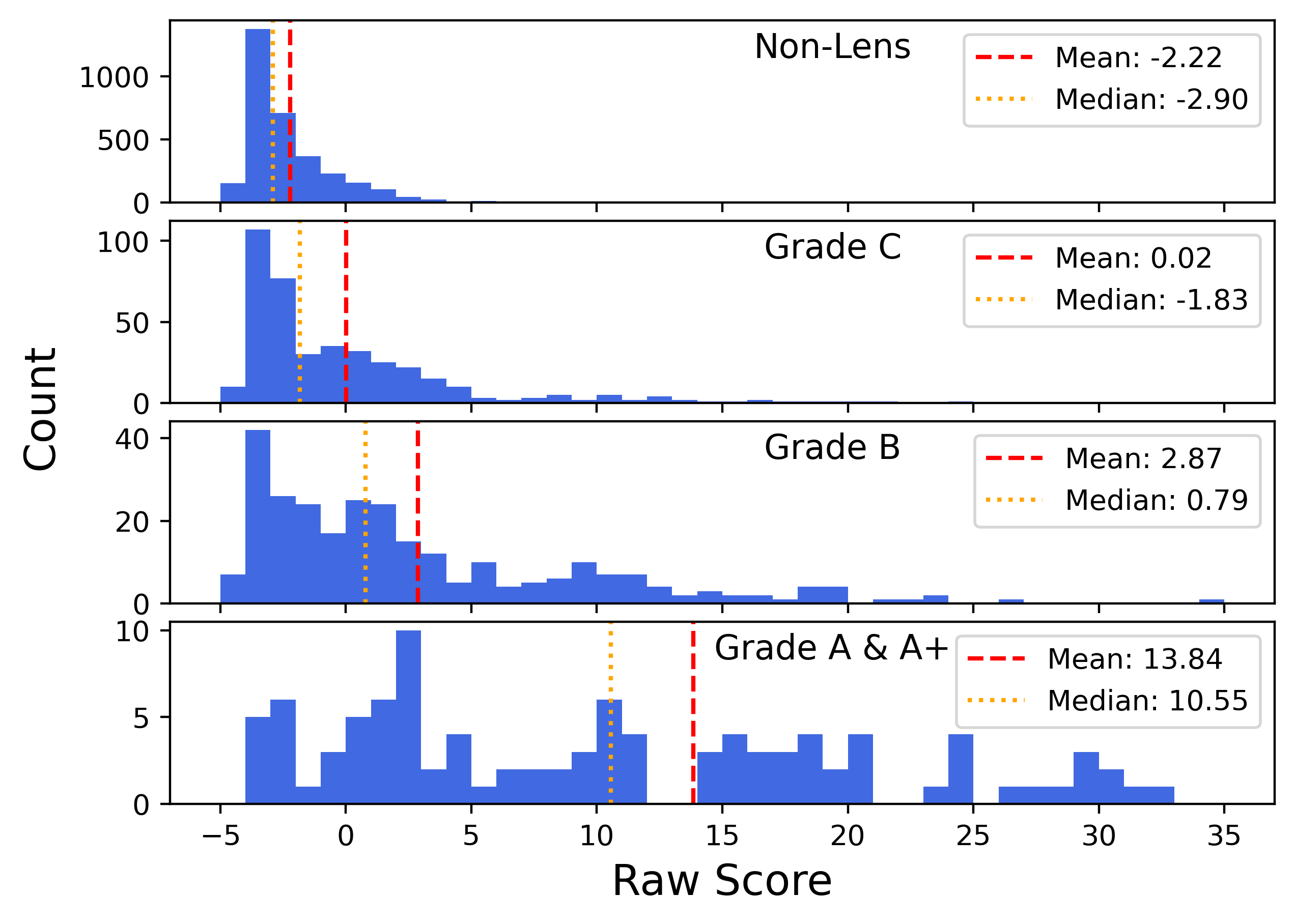
Figure 7: Model prediction score distributions, stratified by human grade, confirming monotonic correlation of score with lensing confidence.
Photometric analysis reveals that confirmed lenses are redder in $\YE-\HE$ and possess fainter $\IE$ magnitudes (median 21.3 AB mag), consistent with massive early types. The model achieves a lens recovery fraction of 65.8% of the estimated ∼670 strong lenses expected in Q1 within the inspected range, even under strict candidate budget constraints.
Model Analysis: False Positives and Human Grading Variance
Detailed inspection of residual false positives identifies recurring confounders: spiral structures, ellipticals with close companions, and diffraction-spike artifacts. A significant proportion of candidate grading discrepancies with prior catalogues is attributed to visualization methods (color scaling, panelization), grader heterogeneity, and subtle differences in lens morphology representation among composites.

Figure 8: Example false positives in the top 4000 rankings, including spirals, mergers, and instrumental artifacts.
Pie-chart analysis of overlapping and novel candidate grades confirms both upgrades and downgrades relative to prior expert efforts, indicating a robust and complementary expansion of the discovered lens set.
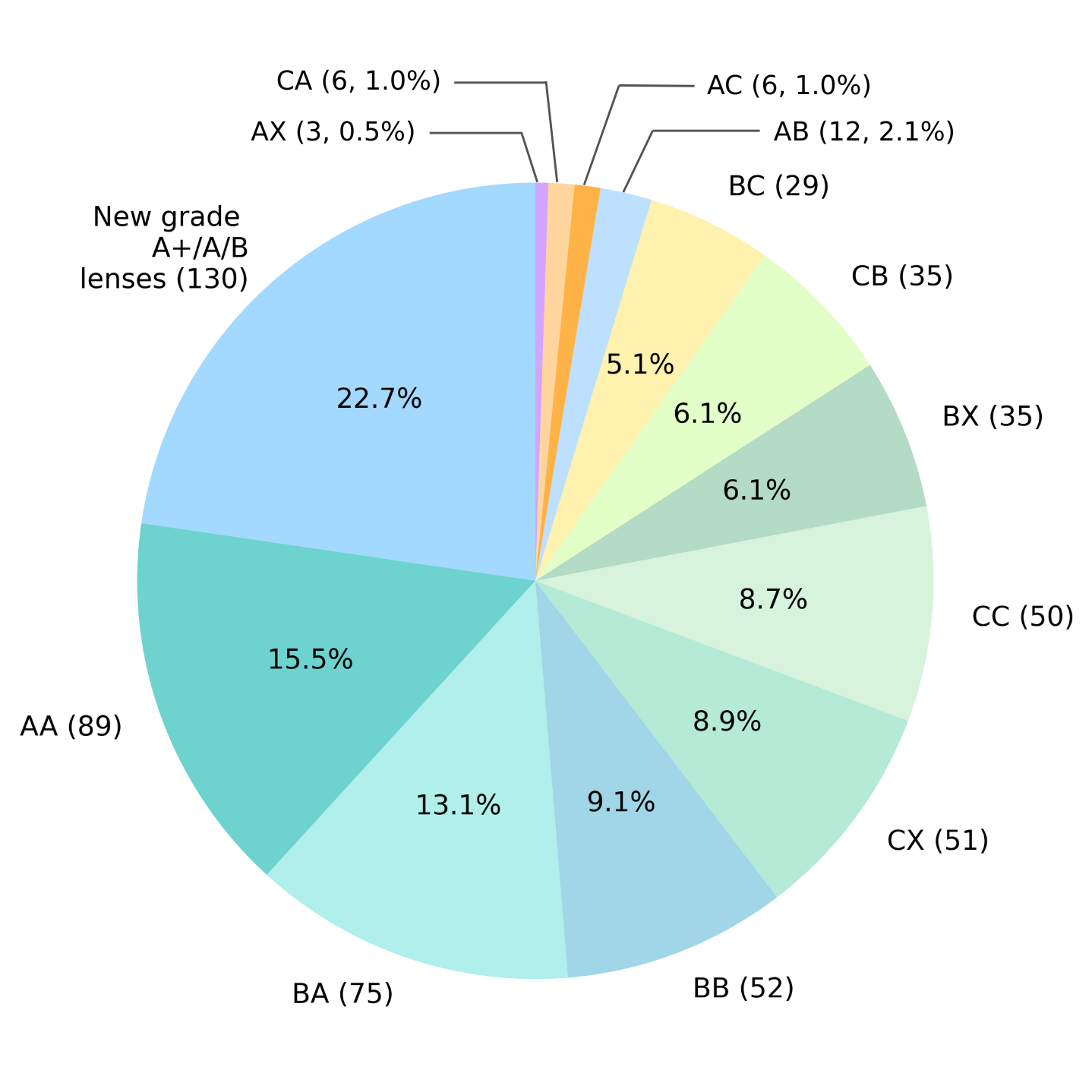
Figure 9: Distribution of grades for 130 new lenses vs. previous SLDE A identifications in the top 4000.
Discussion: Selection Effects, Pipeline Strengths, and Future Work
Efficiency is a principal strength: each pipeline iteration, comprising expert inspection and retraining, is completed in about one week for a small team, making the approach scalable to future Euclid releases. The iterative, hard-negative-driven training loop rapidly increases the purity of top-ranked candidates, sharply reducing human vetting requirements and enabling tractable candidate surface even as the survey volume grows.
Selection effects and sample completeness are examined. The focus on model-driven surfacing and inspection of only the top-ranked 4000 implies some loss in recall, reflecting inherent precision-recall trade-offs imposed by human resource constraints. Selection bias toward typical lens morphologies present in the early training set was identified, necessitating future characterization via injection of simulated systems and diversity-aware active learning.
The model's approach is contrasted with prior simulation-heavy and transfer-learning-based strategies employed in SLDE C and related efforts. While avoiding limitations of unrealistic simulations, the reliance on real data constrains the total volume available for training and risks under-sampling atypical lens systems unless iteratively counteracted.
This design and set of methods, including quality filtering, augmentation, iterative retraining, and ranking-based evaluation, is immediately scalable to DR1 and larger Euclid datasets and may be adapted to Rubin, Roman, and other next-generation surveys with minimal modification.
Conclusion
This work demonstrates a scalable, efficient, and robust pipeline for strong lens discovery in ultra-large astronomical surveys using compact CNNs, iterative self-training, and targeted human-in-the-loop verification (2604.06648). The modified VGG16-based classifier, trained primarily on real Euclid data and augmented with minimal simulation and high-variance hand-crafted lenses, surfaces a new set of high-confidence lensing systems, complementing legacy catalogues and substantially increasing the confirmed candidate base. Future directions include rigorous selection function measurement, integration of uncertainty-aware post-processing and fast lens model vetters, extension beyond fixed candidate budgets, and deployment to larger cosmological datasets as they become available.
The approach sets a new standard for agile, adaptive, survey-scale lens finding under real-world resource and data constraints, and serves as a template for forthcoming automated discovery frameworks in astronomical big data.