- The paper presents SRICL, a novel framework that integrates supervised fine-tuning, retrieval-augmented generation, and in-context learning for robust job skill extraction.
- The methodology stabilizes token boundaries and improves recall across diverse datasets using span balancing, connector normalization, and multi-source retrieval.
- Empirical results demonstrate that SRICL outperforms baseline LLM models with notable STRICT-F1 gains and better domain adaptability.
Motivation and Challenges in Skill Extraction
Skill extraction from job advertisements is critical for downstream applications in recruitment matching, recommendation, and labor market analytics. The task is formalized as span-level information extraction (IE) under the BIO (Begin, Inside, Outside) tagging scheme. Traditional architectures—supervised neural NER models and prompt-based LLMs—exhibit significant domain and terminology brittleness, high labeling requirements, and a tendency toward hallucinated spans or malformations, particularly with rare skill terms and under cross-domain scenarios. LLMs, despite their generalization ability, amplify these problems due to boundary drift and unreliable BIO compliance, stressing the necessity for both reliability and controllability at deployment scale.
SRICL Framework: Design and Technical Components
The proposed SRICL (Supervised Fine-Tuning + Retrieval-Augmented Generation + In-Context Learning) framework re-architects LLM pipelines for robust job skill extraction. The system integrates supervised instruction fine-tuning, multi-source retrieval-augmented generation, prompt engineering within in-context learning, and deterministic output verification.
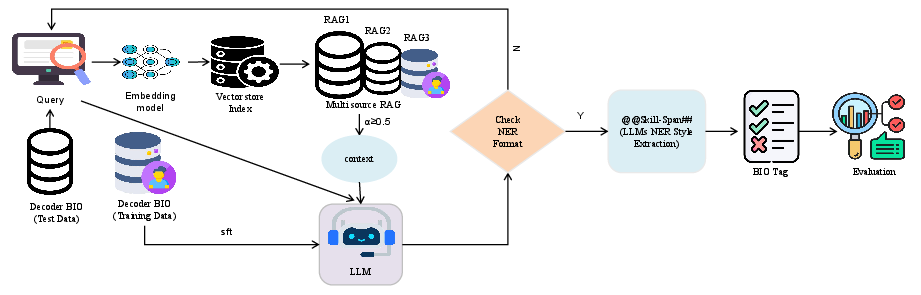
Figure 1: The overall architecture of the proposed SRICL framework, illustrating the multi-module workflow integrating SFT, RAG, ICL, and verifier for reliable span extraction.
Supervised Fine-Tuning with Span Anchoring
The core LLM is fine-tuned using a bracketed target format that explicitly marks skill spans, improving the token-boundary alignment required by BIO. Fine-tuning leverages span-balanced sampling to address head-skill bias, connector normalization to enable robust multi-token matching, and hard negatives to curtail overfitting. These strategies collectively stabilize extraction boundaries and elevate overall precision.
Multi-Source Retrieval-Augmented Generation (RAG)
SRICL incorporates three RAG modules per input: RAG-1 retrieves in-domain annotated sentences as few-shot demonstrations, RAG-2 draws from authoritative ontologies (notably ESCO) for robust definition anchoring, and RAG-3 fetches cross-domain near-neighbors to enhance adaptability. Candidate retrieval is executed via dense cosine similarity over learned representations, with a gating/weighting mechanism for demonstration selection. This approach not only assists sense disambiguation but also regularizes span boundaries through lexical and semantic context, particularly valuable under domain shift or coverage expansion.
Modular In-Context Learning with Format-Constrained Decoding
ICL prompts are engineered for specificity, incorporating explicit system personas (restricting extraction to eligible skills and enforcing legality), detailed task definitions, and clear BIO-output contracts. Retrieved demonstrations and definitions are embedded in the prompt, with output strictly constrained to valid BIO tags via decoding strategies. This results in more reliable, format-compliant outputs and improved handling of compositional skills or coordination errors.
Verification Module and Targeted Retry
A deterministic, model-agnostic checker is employed post-generation, validating output against legality constraints (BIO tagging, no span overlap, taxonomy consistency). On any violation, the system triggers targeted reprompting with minimal retries, efficiently eliminating illegal or hallucinated skills while maintaining production throughput.
Empirical Evaluation and Ablation Analysis
SRICL was benchmarked on six diverse, public span-annotated job-ad datasets spanning different languages and sectors: SkillSpan, Kompetencer, Green, FIJO, Sayfullina, and GNEHM. Metrics focused on token-level Precision, Recall, and STRICT-F1 under exact span agreement. The SRICL-Qwen2.5-14B implementation achieved an average STRICT-F1 of 41.51 across datasets, outperforming all GPT-3.5 zero/few-shot configurations and the open-source LLaMA-3-8B variant.
Strong numerical results are highlighted in SkillSpan (54.59 F1) and Sayfullina (61.18 F1), demonstrating marked improvements over the closest prompting-based baselines and closed/open LLMs. Notably, on languages with pronounced domain/lexicon shifts (e.g., Kompetencer—Danish; Green—ecological), SRICL maintains competitive F1, though remaining below domain-specific supervised classifiers where available.
Component Ablation
Ablation experiments (Figure 2) demonstrated that SFT with span anchoring is the primary source of boundary stability and precision, while RAG modules, especially demonstration and ontology retrieval, enhance recall and domain robustness, sometimes incurring a precision trade-off. Data-specific prompting marginally improves span-level F1, especially in technical or jargon-rich datasets.
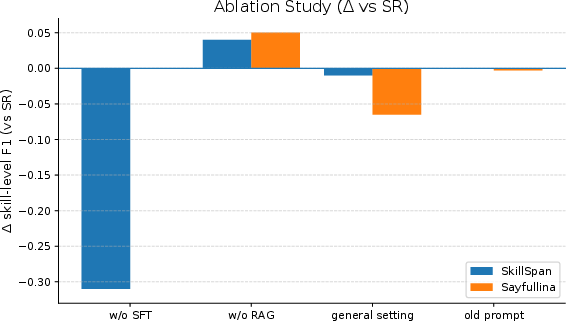
Figure 2: Ablation study quantifying the effect of removing SFT, RAG, and prompt engineering on F1 across SkillSpan and Sayfullina, underscoring the dominant impact of SFT on overall structure quality.
Sensitivity to Retrieval Hyperparameters
RAG sensitivity analysis (Figure 3) revealed that increasing the number of retrieved demonstrations (k) boosts recall up to a practical limit, after which computational cost quickly outweighs incremental F1 gains. A low-to-moderate k with high-quality, filtered retrieval achieves an optimal trade-off for real-world deployment.
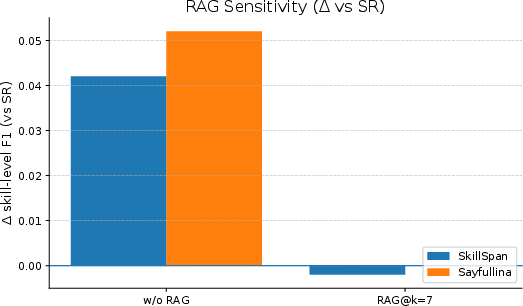
Figure 3: RAG@k sensitivity curve showing recall and F1 as functions of the number of retrieved examples, indicating diminishing return beyond moderate values of k.
Implications and Outlook
The SRICL framework establishes a strongly controllable, modular pipeline for span-level skill extraction without the annotation or retraining costs typical of supervised neural models. Its methodological design—combining SFT, evidentiary retrieval, task-aware prompt engineering, and deterministic verification—significantly reduces boundary drift, tag illegality, and hallucinated extractions. This positions SRICL as a competitive open-model solution even in low-resource, multi-domain or cross-lingual contexts. Practically, the framework supports auditable extraction pipelines, making it suitable for integration into regulatory-sensitive or high-stakes automation contexts within HR analytics or labor economics.
From a theoretical standpoint, SRICL exemplifies the efficacy of retrieval and prompt modularization paired with output validation, potentially generalizing to other taxonomy-driven, low-resource IE tasks. The dataset-dependent utility of RAG components and prompt engineering signals future work in adaptive retrieval selection and prompt optimization. The architecture is amenable to multi-task extensions, knowledge integration from evolving taxonomies, and feedback-driven learning for continual domain adaptation.
Conclusion
SRICL advances job skill extraction by harmonizing supervised fine-tuning, retrieval-informed demonstration, and verification-aware LLM generation. Empirical results substantiate consistent F1 and legality improvements over prominent LLM prompting approaches, with ablation confirming the modular value of SFT and RAG components. The framework provides a practical and extensible foundation for dependable, domain-adaptive information extraction in labor market and HR technology sectors, opening promising directions for both scalable deployment and methodological research in controllable IE systems.

