- The paper introduces frozen LLM checkpoints as time-stamped digests of public text, creating reproducible outlook scores for assessing latent market information.
- It validates that these LLM-derived outlook scores predict future economic outcomes, such as 12-month revenue growth and analyst price target revisions, with strong statistical significance.
- The study highlights narrative congestion as a key mechanism, where aggregated qualitative signals remain underpriced due to market frictions in processing dispersed information.
ChatGPT as a Time Capsule: The Limits of Price Discovery
The paper introduces the use of frozen LLM checkpoints as auditable, time-stamped digests of publicly available text for the purpose of quantifying latent information relevant to price discovery in financial markets. Each LLM checkpoint, with a fixed knowledge cutoff, is treated as a compressed summary of all public textual information—SEC filings, earnings calls, news, macro commentary—available at that date. The approach circumvents standard limitations where information proxies (e.g., earnings surprises, headline sentiment) capture only narrow slices of the public record, enabling instead a broad, sector-neutral quantification of business prospects for ~7,000 US equities at each checkpoint.
A sector-neutral Outlook Score is extracted via a standardized prompt, leveraging the frozen LLM's internalized textual knowledge without reference to post-cutoff events or prices. This methodology provides a reproducible and ex-ante proxy for what could have been inferred from the public corpus at a fixed point, and mitigates look-ahead and memorization biases inherent in na\"ive LLM backtests.
The empirical design operationalizes four key hypotheses:
H1: Validates that the LLM outlook score predicts realized future economic outcomes—12-month revenue growth (t=10.89) and analyst target-price revisions (t=4.80)—establishing the signal's real economic content.
H2: Tests whether the LLM outlook score predicts post-cutoff cross-sectional returns after controlling for contemporaneous market-implied valuation measures (inverse P/E, implied cost of equity, inverse EV/EBITDA) and standard factor exposures. A significant coefficient (γ) indicates that prices do not immediately or fully reflect the qualitative information the LLM can extract from public text.
H3: Assesses mechanism by interacting outlook-score predictability with proxies for the information environment (analyst coverage, trading volume). The positive coverage interaction in pooled panel regressions (t=2.44) supports a “narrative congestion” mechanism: predictive frictions are caused by the cost of aggregating dispersed qualitative information even in high-attention environments, and not by mere investor neglect.
H4: Examines horizon dynamics and model sophistication by comparing γ across return horizons and model generations. The outlook-score coefficient broadly increases with horizon (Spearman r=0.91 for single-model), indicating gradual price convergence toward LLM-implied valuations. Newer and larger model checkpoints produce stronger signals, with significant positive Spearman correlation between knowledge cutoff recency and the coefficient (r=0.62, p=0.03).
Results: Robust Return and Fundamental Predictability
The central finding is that across twelve OpenAI model checkpoints (spanning 2021–2025) and post-cutoff return horizons, the sector-neutral LLM outlook score exhibits statistically robust cross-sectional return predictability after controlling for market-implied valuations and standard factors. For the primary specification (GPT-4.1, June 2024 cutoff), the outlook-score coefficient is γ=0.0122 (t=4.25) at the one-month horizon and persists at longer horizons. In pooled panels with model fixed effects (t=4.800), the coefficient remains strongly significant (t=4.801).
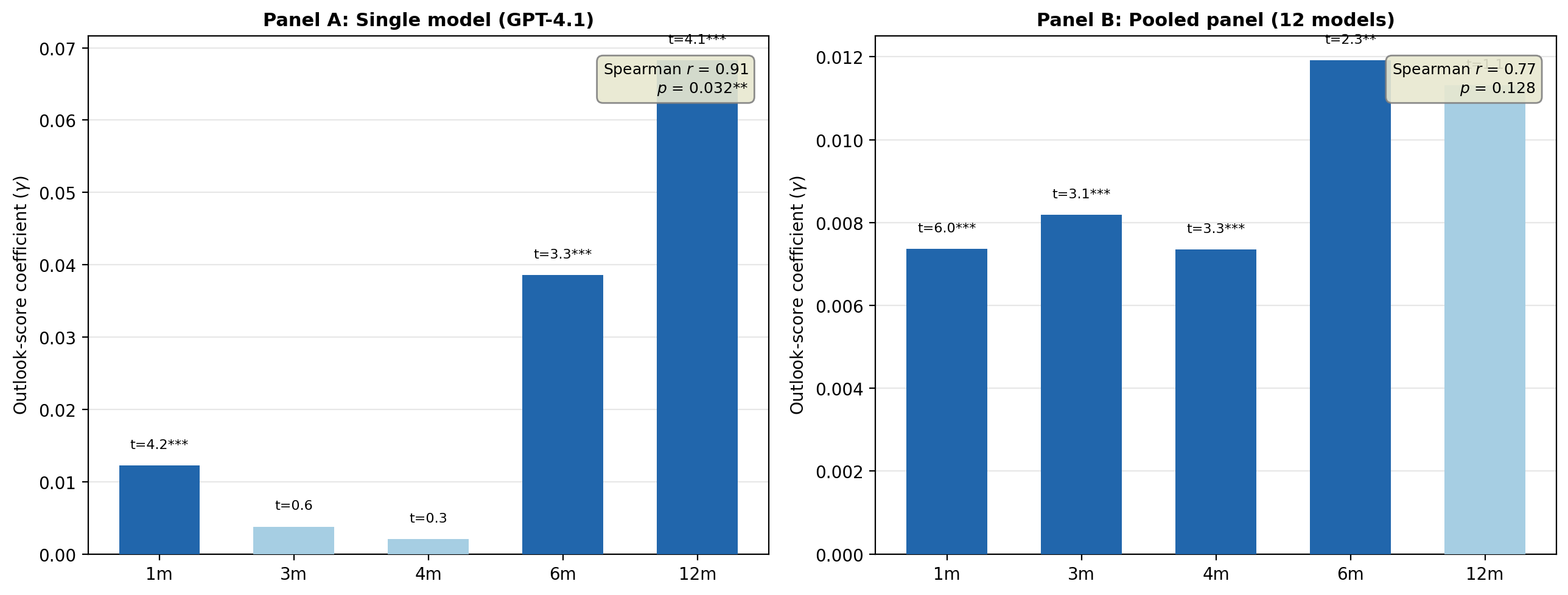
Figure 1: Outlook-score coefficient t=4.802 across return horizons for single-model and pooled panel specifications, demonstrating horizon-dependent growth consistent with gradual information diffusion.
Portfolio sorts by the outlook score yield large spreads: a control-adjusted long-short portfolio earns t=4.803 monthly (t=4.804 annualized), exceeding the S&P 500 price index on risk-adjusted metrics and producing lower drawdowns. The signal is not subsumed by standard factors, and remains significant across robustness checks including micro-cap exclusion, aggressive winsorisation, and alternative inference procedures.
Cross-model analysis reveals a statistically significant relationship between model cutoff recency and outlook-score predictability. Larger models within the same cutoff yield stronger coefficients—GPT-4.1 (t=4.805) versus GPT-4.1-nano (t=4.806)—implying that model capability amplifies the extracted signal even when the information set is held constant.
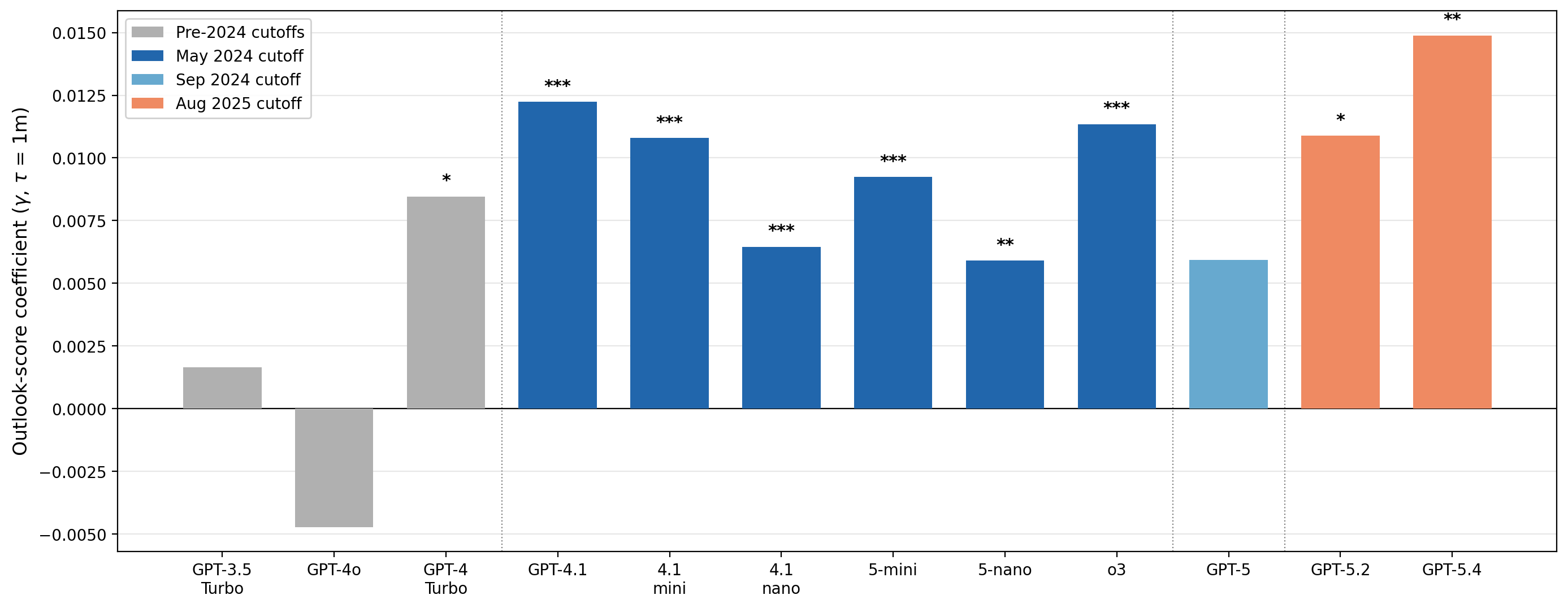
Figure 2: Outlook-score coefficient t=4.807 at t=4.808 month for twelve model checkpoints; significant results are concentrated in the May/June 2024 cutoff cluster, with larger models showing stronger predictive power.
Mechanisms: Narrative Congestion vs. Limited Attention
The paper evidences that return predictability from the LLM outlook score is stronger for firms with higher analyst coverage and richer information environments. This contradicts classic limited-attention theories, which would predict stronger effects for neglected, low-coverage firms. Instead, the bottleneck appears to be narrative congestion: even well-monitored firms with abundant coverage are subject to frictions in aggregating and synthesizing qualitative information across many documents, a task at which LLMs outperform market participants.
This distinction carries practical implications. If narrative congestion is the dominant friction, the informational gap may persist or intensify as disclosure volume increases, and technological adoption (e.g., widespread use of LLM-based tools by investors) may eventually attenuate the anomaly via diffusion.
Practical and Theoretical Implications
The findings document an economically and statistically significant disconnect between qualitative information extractable from pre-cutoff public text and price incorporation, after controlling for market-implied cheapness, with robust evidence against confounding by standard risk factors. This has implications both for asset pricing theory—challenging the completeness of price reflection of public information under the Efficient Market Hypothesis—and for practical signal construction in quantitative finance.
The knowledge-cutoff design assures that predictive power is not attributable to post-cutoff memory contamination. As adoption of LLM-based tools becomes more common in the financial industry, the cycle of anomaly attenuation (as documented in prior literature) is expected to accelerate, narrowing the edge from LLM-derived textual signals. Further, mechanisms of narrative congestion suggest that future advances in LLM capability or prompt engineering may deepen the signal extraction, but also that information flows will become increasingly symmetric as technology diffuses.
Portfolio applications demonstrate that LLM outlook scores can be operationalized as alpha signals, achieving Sharpe ratios and drawdowns superior to standard price-only benchmarks within the sample window; however, factor tilts toward profitability and quality indicate partial overlap with known risk premia. Formal time-series alpha analysis is precluded by the limited number of unique cutoff dates.
Limitations and Directions for Future Research
The analysis is confined to OpenAI checkpoints; replication with other model families (Anthropic, Google, Meta) is required for external validity. The post-cutoff window for frontier models is short, limiting horizon analysis. The single-prompt construction of the outlook score could be diversified via alternative elicitation strategies. Expansion to global markets and decomposition by textual source remain open avenues.
Further research could clarify whether the residual predictability reflects market misprocessing or priced risk dimensions unabsorbed by the factor controls, and how the anomaly evolves as LLM adoption saturates market participants.
Conclusion
The paper establishes that frozen LLM checkpoints provide a powerful proxy for the qualitative information available in public text at a fixed date, and that their sector-neutral outlook scores encode information not fully reflected in contemporaneous market valuations. Robust cross-sectional evidence indicates that this information gap is associated with economically meaningful return and fundamental predictability. The results favor an information-processing friction rooted in narrative congestion over simple investor neglect, and highlight the practical utility of LLM-derived scores in quantitative asset management. The durability of this edge depends on the evolution of narrative complexity and market adoption of advanced information aggregation tools, portending shifts in the landscape of price discovery and financial forecasting.