- The paper presents a novel framework (StyleVAR) that integrates visual autoregressive modeling with blended cross-attention for reference-based image style transfer.
- It combines supervised fine-tuning with GRPO reinforcement to jointly optimize discrete token predictions and perceptual image quality.
- Experimental results demonstrate improved SSIM, LPIPS, and CLIP similarity while highlighting challenges in inference efficiency and content diversity.
StyleVAR: Controllable Image Style Transfer via Visual Autoregressive Modeling
Introduction
StyleVAR presents a conditional image generation framework for reference-based image style transfer, in which the objective is to synthesize outputs that preserve the semantic structure of a given content image while adopting the texture characteristics of a reference style image. Addressing the persistent challenge of balancing content preservation and style fidelity, StyleVAR is built atop the Visual Autoregressive Modeling (VAR) paradigm. By leveraging a multi-scale, discrete sequence tokenization of images via VQ-VAE and a tailored transformer architecture with blended cross-attention, StyleVAR models the distribution over target latent tokens conditioned on both style and content, with explicit scale-dependent control of information blending. The framework incorporates both supervised fine-tuning and reinforcement learning using Group Relative Policy Optimization (GRPO) with perceptual rewards, yielding strong performance across datasets.
Visual Autoregressive Modeling Backbone
The StyleVAR architecture is rooted in the multi-scale VAR formulation, which decomposes an image into hierarchical representations. Each scale is tokenized into codebook indices via a VQ-VAE encoder, allowing the transformer to model coarse-to-fine latent variable dependencies. Unlike token-level raster-scan next-token prediction, next-scale autoregressive modeling achieves significantly improved efficiency and fidelity in image generation. The multi-scale approach sequentially predicts token maps from global structure (low resolution) to fine detail, with transformer blocks aligned to this hierarchy.
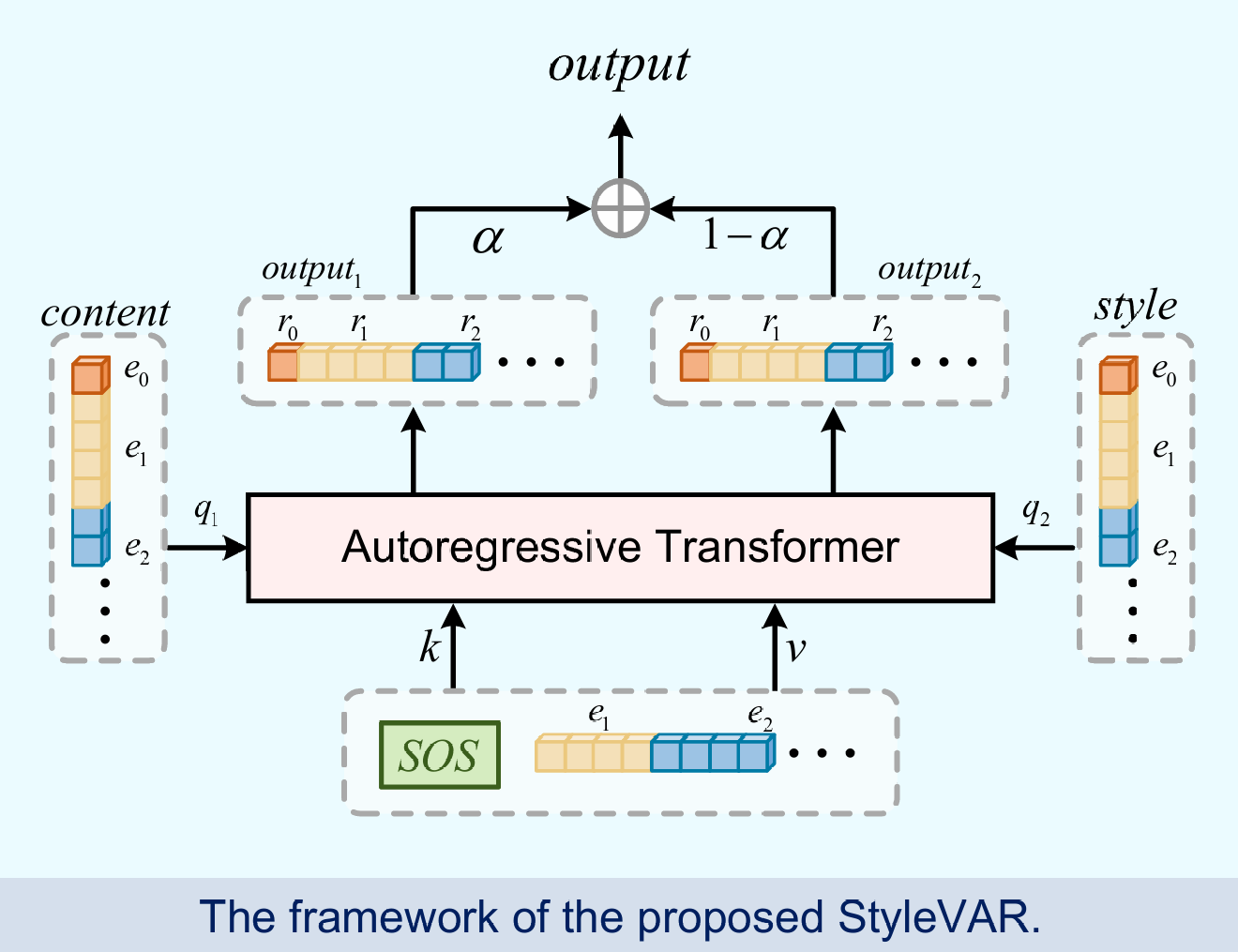
Figure 1: Structure of StyleVAR Transformers, showing multi-scale injection of style and content via blended cross-attention.
The architecture explicitly reflects these design principles, where style and content conditioning tokens are introduced at each scale through blended cross-attention mechanisms.
Blended Cross-Attention Injection
The attention mechanism in StyleVAR deviates from canonical cross-attention in transformer architectures. In each transformer block, target features are set as Keys and Values, while style and content tokens are supplied as Queries. This configuration ensures that at each scale, the generative trajectory remains autoregressive, driven by accumulated target history, while style and content features act as selectors that modulate which elements of history are emphasized. A blending coefficient αk is heuristically assigned at each scale to modulate the relative influence between style and content. This blending is critical for aligning the generated image to both content geometry and stylistic appearance.
This design is analytically justified: assigning the target sequence as Q (with content/style as K/V) would result in excessive reliance on static conditioning, undermining autoregressive continuity.
Training Procedure: Supervised and Reinforcement Phases
Training StyleVAR proceeds in two stages:
- Supervised Fine-Tuning (SFT): Given aligned content, style, and target triplets, the model is optimized via cross-entropy over discrete token predictions using a fixed VQ-VAE. Teacher forcing ensures the network learns both hierarchical structure progression and condition injection.
- GRPO Reinforcement Fine-Tuning: To close the gap between discrete token accuracy and perceptual image quality, StyleVAR is further refined using GRPO with a DreamSim-based reward that directly optimizes perceptual similarity post-decoding. GRPO computes trajectory advantages by group-normalizing rewards over multiple parallel rollouts, obviating the need for a learned value network and better exploiting the diversity of plausible stylizations.
A key innovation in GRPO application to VAR is scale-aware credit assignment. Due to the exponential growth in token map size across scales, fine-scale tokens could dominate the policy gradient under naive averaging. StyleVAR addresses this by employing Per-Action Normalization Weighting (PANW): each token's contribution scales inversely with spatial resolution (power law with exponent α=0.7), ensuring global structural decisions at coarse scales drive the optimization signal appropriately.
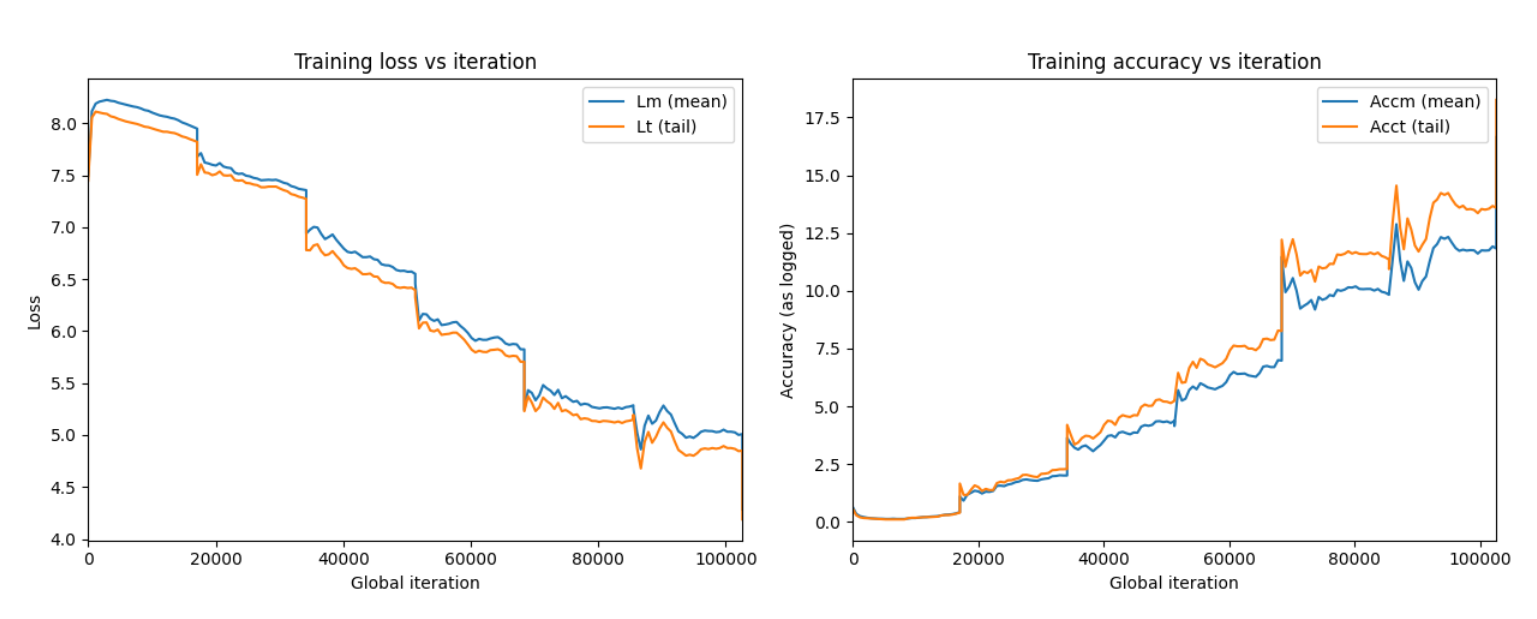
Figure 2: Loss and accuracy of training set across iterations during the supervised fine-tuning phase.
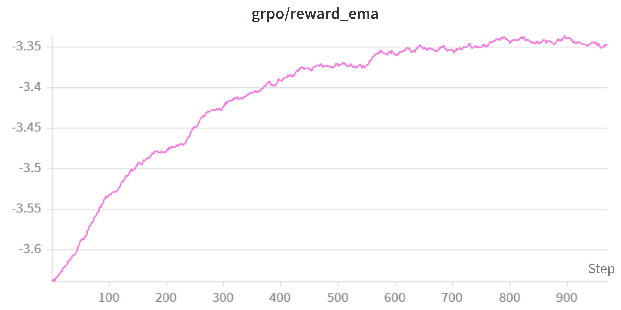
Figure 3: GRPO Reward-EMA over RL iterations, showing improvement attributable to reinforcement fine-tuning.
Experimental Results
Quantitative Evaluation
Across three benchmarks (OmniStyle, ImagePulse, COCO+WikiArt), both SFT and GRPO-finetuned StyleVAR models consistently outperform the AdaIN baseline on six evaluation metrics: Style Loss, Content Loss, LPIPS, SSIM, DreamSim, and CLIP similarity. The improvements are most prominent in SSIM and LPIPS, reflecting superior structural preservation and perceptual alignment. The additional GRPO phase yields further, statistically significant improvements on DreamSim and CLIP similarity, directly corresponding to the reward signal. Inference time remains considerably higher than AdaIN, inherent to the autoregressive and multi-scale generation protocol.
Qualitative Evaluation
Generated samples validate that StyleVAR achieves strong texture transfer without sacrificing underlying spatial structure. The model demonstrates robustness for scenes involving rigid geometry (e.g., landscapes, architecture), but exhibits gaps in generalization for out-of-distribution internet images and semantically complex content (notably human faces), attributable primarily to limited content diversity in training data.

Figure 4: The generated images demonstrate that the model successfully transfers texture while maintaining the semantic structure of the content.
Limitations and Implications
Despite strong empirical performance, StyleVAR exposes limitations characteristic of both its architecture and data regime. The principal constraint is the generalization gap connected to content diversity: with only ∼1,800 unique content images in OmniStyle-150K, the model risks memorizing structural layouts rather than acquiring general content priors. This is evidenced by diminished performance on web-scraped content images and human faces, where minor geometric anomalies are perceptually salient.
From an architectural perspective, the computational cost of deep multi-scale autoregressive inference currently limits practical deployment. This underscores the need for efficient decoding strategies, potential model distillation, or alternative token parallelization techniques.
Conclusion
StyleVAR introduces a principled and empirically validated framework for reference-based style transfer leveraging conditional multi-scale autoregressive visual modeling, blended cross-attention for content/style modulation, and GRPO-based reinforcement learning on perceptual rewards. The approach consistently advances perceptual and structural fidelity over normalization-based baselines. Its major theoretical contribution is the explicit scale-aware credit normalization in the RL context for visual sequence models. Future avenues include enhancing content diversity in training, scaling to high-complexity object domains, and developing decoding or distillation techniques to ameliorate inference efficiency without compromising image quality.

