- The paper introduces Reference Attention to efficiently integrate control signals, enhancing stability in text-to-image synthesis.
- It employs LoRA-based fine-tuning and multi-scale tokenization to achieve precise text-image alignment and improve computational speed.
- Experimental results demonstrate that ScaleWeaver outperforms diffusion models in controllability, fidelity, and efficiency.
ScaleWeaver: Efficient Controllable Text-to-Image Generation via Multi-Scale Reference Attention
Introduction
ScaleWeaver addresses the challenge of efficient, high-fidelity, and controllable text-to-image (T2I) generation within the visual autoregressive (VAR) paradigm. While diffusion-based models have dominated controllable image synthesis, VAR models offer significant advantages in inference efficiency and scalability. However, prior attempts at controllable VAR-based generation have been limited in scope, often restricted to class-conditional settings and requiring resource-intensive fine-tuning. ScaleWeaver introduces a parameter-efficient framework that enables precise, flexible control over image synthesis by integrating a novel Reference Attention mechanism and leveraging LoRA-based parameter reuse. The approach is validated across a diverse set of control signals, demonstrating strong controllability, text-image alignment, and substantial improvements in computational efficiency.
Methodology
Visual Autoregressive Generation and Multi-Scale Conditioning
VAR models decompose image generation into a sequence of next-scale predictions, where each scale refines the image conditioned on coarser representations and the text prompt. ScaleWeaver extends this paradigm by introducing an auxiliary visual condition (e.g., edge, depth, sketch, blur, colorization, or palette map), which is tokenized using the same multi-scale tokenizer as the image. This ensures spatial and scale alignment between the image and condition tokens.
Reference Attention: Efficient and Stable Condition Injection
The core innovation is the Reference Attention module, which is integrated into the MMDiT-style transformer backbone at each scale. Unlike standard multi-modal attention, Reference Attention eliminates the image-to-condition attention path, focusing solely on condition-to-image cross-attention and self-attention within each stream. This asymmetry reduces computational overhead and representational entanglement, concentrating parameter updates on the conditional branch and stabilizing the injection of control signals.
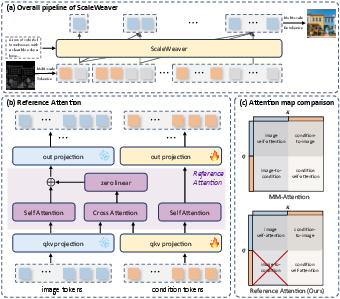
Figure 1: The ScaleWeaver framework, highlighting multi-scale tokenization, LoRA-based conditional branch, and Reference Attention for efficient condition injection.
Reference Attention employs a zero-initialized linear projection for the cross-attention term, ensuring that the module initially behaves as standard self-attention and only gradually incorporates conditional information during training. The image-side projections are frozen, while the condition-side projections are LoRA-tuned with a small rank, minimizing the number of trainable parameters and preserving the generative prior of the base model.
Parameter-Efficient Fine-Tuning with LoRA
ScaleWeaver leverages LoRA modules exclusively in the conditional branch, reusing the pretrained backbone for both image and text processing. This design enables efficient adaptation to new control signals with minimal additional parameters and computational cost. During training, classifier-free guidance is extended to the conditional modality by randomly dropping the condition input, exposing the model to both conditional and unconditional regimes.
Experimental Results
Quantitative and Qualitative Evaluation
ScaleWeaver is evaluated on six conditional generation tasks using the COCO 2017 validation set, with metrics including FID, CLIP-IQA, CLIP Score, F1 (for edge control), and MSE (for other conditions). Across all tasks, ScaleWeaver achieves strong generative quality and text-image consistency, with controllability that matches or surpasses state-of-the-art diffusion-based baselines. Notably, for challenging conditions such as depth and blur, ScaleWeaver demonstrates superior control fidelity.

Figure 2: Qualitative comparison showing ScaleWeaver's high-fidelity synthesis and precise control across diverse conditions, outperforming diffusion-based baselines.
Diversity and Robustness
ScaleWeaver supports diverse generation under fixed structural guidance, producing varied outputs for different text prompts while preserving the semantic structure imposed by the condition.

Figure 3: Conditional generation results on diverse condition types, illustrating the flexibility of ScaleWeaver across multiple control modalities.

Figure 4: Diverse generation with Canny or sketch images as control, demonstrating the model's ability to maintain structure while varying content.

Figure 5: Diverse generation with blur or depth map as control, highlighting robustness to different types of visual guidance.

Figure 6: Diverse generation with grey image or palette map as control, further illustrating adaptability to appearance-based conditions.
Ablation Studies
Ablation experiments confirm the effectiveness of Reference Attention compared to spatial addition and standard MM-Attention. Reference Attention achieves the best trade-off between controllability and generation quality, with the zero-initialized linear gate being critical for stable control injection. Early integration of the condition (in the first 16 blocks) is found to be optimal, and reducing the number of conditional blocks or LoRA rank degrades performance.

Figure 7: Visualization comparison for ablation study, showing qualitative differences between injection mechanisms.
Efficiency Analysis
ScaleWeaver achieves a significant reduction in model size (2.3B parameters) and inference latency (7.6s for 1024×1024 images) compared to diffusion-based baselines, which require 12–15B parameters and 39–71s per image. This efficiency is achieved without sacrificing generation quality or controllability, making ScaleWeaver suitable for real-world deployment.
Implications and Future Directions
ScaleWeaver demonstrates that efficient, high-quality, and controllable T2I generation is feasible within the VAR paradigm, challenging the dominance of diffusion-based approaches for controllable synthesis. The modularity of Reference Attention and the parameter-efficient fine-tuning strategy suggest that the framework can be readily extended to multi-condition control and scaled to larger VAR backbones. The approach also opens avenues for integrating more complex or dynamic control signals, as well as for unifying pixel-to-pixel vision tasks under a single autoregressive generative framework.
Conclusion
ScaleWeaver establishes a new standard for controllable T2I generation in the autoregressive setting, combining a novel Reference Attention mechanism with LoRA-based parameter reuse to achieve precise, flexible control and high generation quality at a fraction of the computational cost of diffusion-based methods. The results indicate that VAR models, when equipped with efficient condition injection mechanisms, can match or exceed the controllability and fidelity of diffusion models while offering substantial gains in efficiency and scalability. Future work should explore multi-condition integration, dynamic control balancing, and further scaling of the VAR backbone to enhance both the flexibility and performance of controllable generative models.