- The paper introduces SAVAREdit, incorporating coarse-to-fine token localization and reinforcement learning-based adaptive feature injection to preserve spatial structure during editing.
- It demonstrates state-of-the-art performance with highest SSIM (0.8521) and lowest LPIPS (0.0636) compared to baseline diffusion and VAR methods.
- The study reveals that intermediate FFN activations hold critical spatial priors, offering actionable insights for designing high-fidelity autoregressive image editors.
Structure-Preserving Text-Guided Image Editing with Visual Autoregressive Models
Introduction
Text-guided image editing has become a prominent paradigm for high-fidelity manipulation of visual content at both local and global levels. Recent progress in generative modeling revealed the capabilities of visual autoregressive (VAR) models to surpass diffusion-based approaches in efficiency and flexibility. However, existing VAR-based editors—typically reliant on token-level reassembling and cross-attention manipulation—still suffer from suboptimal localization of editable tokens and limited preservation of fine-grained structures. The paper "Rethinking Structure Preservation in Text-Guided Image Editing with Visual Autoregressive Models" (2603.28367) introduces SAVAREdit, addressing these deficiencies via novel region localization and feature-injection mechanisms, empirically and theoretically grounded in intermediate representation analysis within VAR architectures.
Methodology Overview
SAVAREdit builds on a multi-pronged strategy: coarse-to-fine token localization (CFTL) to precisely determine editable regions, feature injection (FI) leveraging structure-aware VAR representations to enforce spatial consistency, and a reinforcement learning–based adaptive feature injection (AFI) that automatically discovers optimal injection configurations.
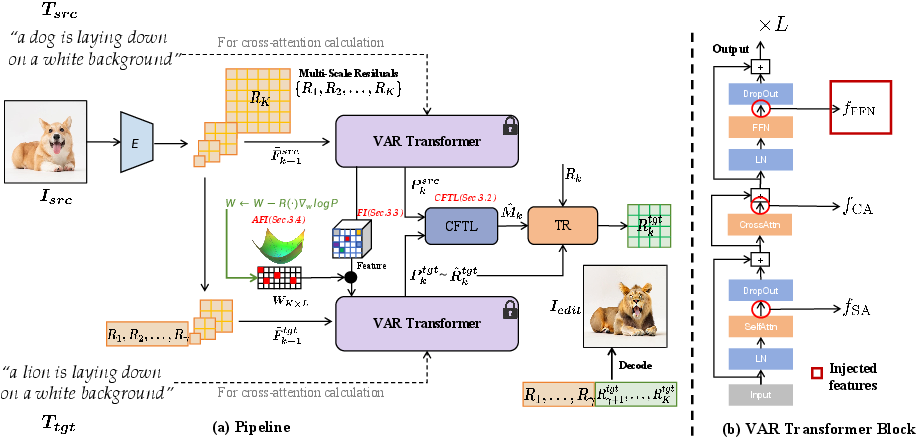
Figure 1: Method overview for SAVAREdit, demonstrating the dual-branch VAR editing pipeline, multi-scale tokenization, and selective intermediate feature injection.
Coarse-to-Fine Token Localization (CFTL)
Token reassembly in VAR image editing is fundamentally dependent on precise localization masks. Empirical analysis established that classification-free guidance (CFG) significantly influences the spatial and textural specificity of these masks: low CFG preserves non-edited regions but diminishes edit fidelity, whereas high CFG enhances edits at the cost of background degradation. SAVAREdit dynamically intersects coarse (low-CFG) and fine (high-CFG) masks, yielding superior spatial accuracy without redundant inference. This dual-thresholding aligns sensitivity to probability changes with spatial edit localization requirements.

Figure 2: Effect of CFG on background preservation vs. editing fidelity; the hybrid method balances these factors, as quantified by token replacement counts.
Structure-Preserving Feature Injection
Dissecting the internal mechanics of next-scale prediction VAR models, the study identifies that FFN (FeedForward Network) and, to a lesser extent, self-attention block representations encapsulate rich spatial priors. Principal Component Analysis (PCA) visualizations reveal that cross-attention provides coarse semantic localization, but only FFN activations reliably encode spatial configurations necessary for structural consistency during edits.

Figure 3: PCA visualizations of intermediate VAR block features and attention maps, highlighting spatial layout properties in FFN layers.
The FI mechanism selectively injects spatially-correlated intermediate features from the source branch into the editing pipeline at targeted scales and layers, identified via statistical analysis and reinforced by genetic-algorithm search.
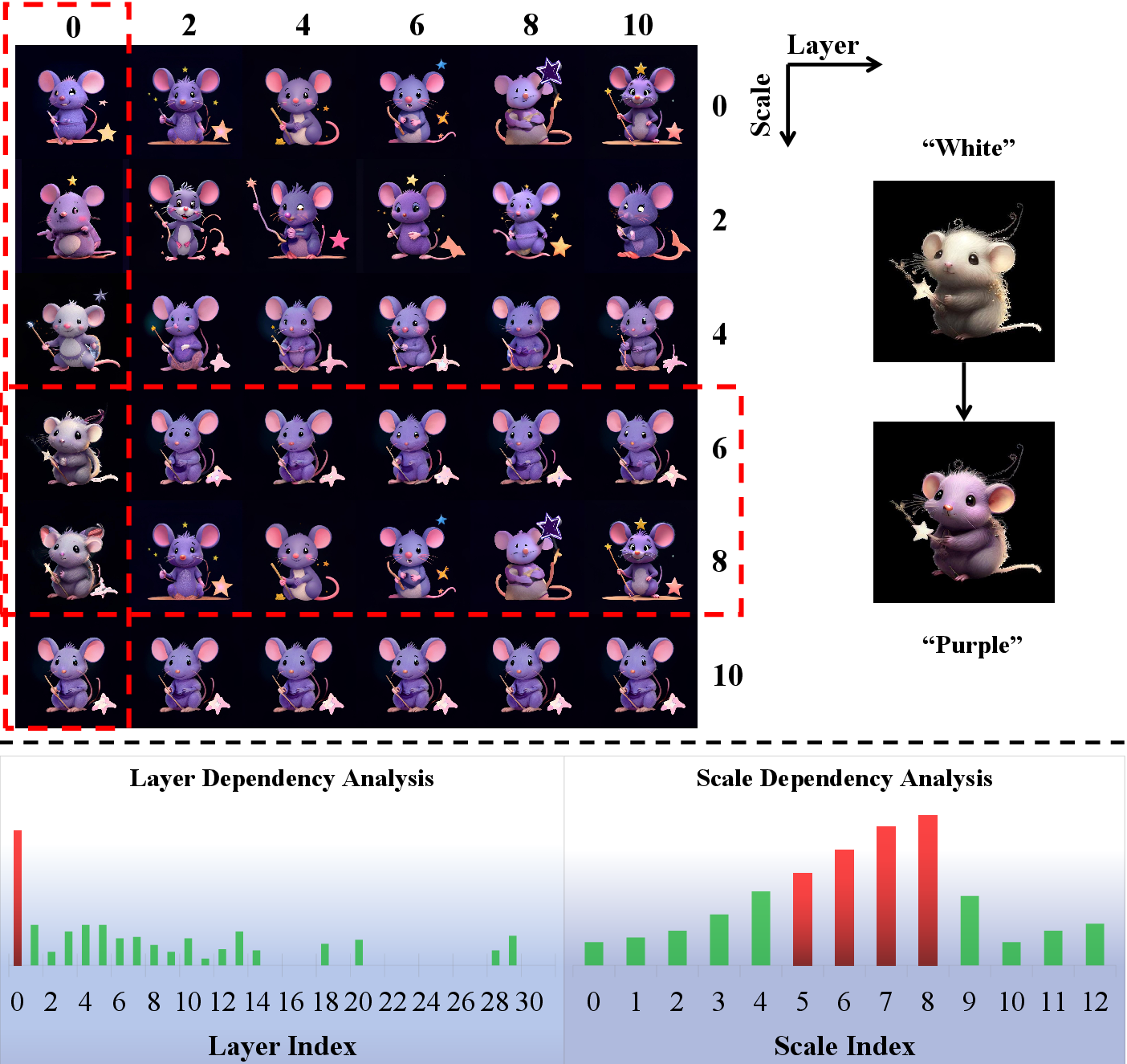
Figure 4: Dependency analysis showing the impact of injecting features at specific layers and scales, and distribution of learned injection ratios.
Adaptive Feature Injection via Reinforcement Learning
Recognizing that optimal feature-injection configurations are neither binary nor static, AFI deploys a policy gradient–based adaptation scheme. The continuous blending weights for scale-layer pairs are treated as policy parameters, updated to maximize a composite reward balancing semantic fidelity (via CLIP similarity) and structural retention (via SSIM). SPSA-based warm-up expedites convergence in the high-variance sampling regime of VAR generation.
Experimental Results
Evaluation across a diverse set of real and synthetic edits from PIE-Bench demonstrates SAVAREdit's systematic outperformance of state-of-the-art diffusion and VAR alternatives, including P2P, MasaCtrl, and AREdit. SAVAREdit exhibits marked superiority in structural retention (lowest DINO-ViT feature distance) and achieves the highest SSIM (0.8521), PSNR (25.73), and lowest LPIPS (0.0636) in unedited regions, while preserving competitive CLIP similarity scores.
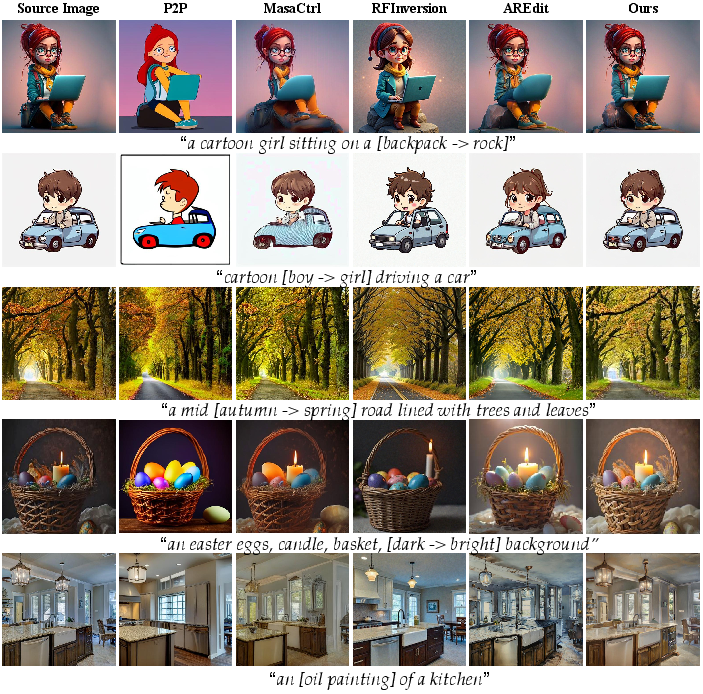
Figure 5: Qualitative comparison—SAVAREdit achieves higher background fidelity and structure preservation than all baselines in local and global edits.
Ablation Analysis
Component-wise ablation confirms the efficacy and necessity of each architectural innovation:
- CFTL delivers finely localized edits with clear improvements in background preservation.
- FI enables structure retention even with no source-token reuse (γ=0) and surpasses token-reuse strategies in flexibility and edit realism.
- AFI further refines the trade-off, adaptively tuning injection weights for optimal visual and structural outcomes.

Figure 6: CFTL ablation—demonstrates superior editable region localization and background separation.

Figure 7: FI ablation—shows the advantage of direct feature injection for structure retention.

Figure 8: AFI ablation—highlights adaptability in balancing editing fidelity with structure consistency.
Theoretical and Practical Implications
This work substantiates that:
- Token-level edit frameworks in autoregressive T2I models are intrinsically sensitive to CFG-induced probability scaling, requiring adaptive mask generation for precise, high-fidelity localization.
- Intermediate spatial representations, especially post-FFN activations, are structurally informative, and their selective transplantation is empirically and computationally optimum for edit realism and controllability.
- Reinforcement learning–based adaptation of feature-injection ratios harnesses the stochastic, non-differentiable VAR pipeline for robust region- and layer-aware manipulation.
Practically, SAVAREdit reduces computational overhead compared to diffusion-based approaches and eliminates the need for paired data in structure-preserving text-guided editing. Theoretically, it elucidates the spatial inductive biases inherent in VAR block organizations, informing architectural choices for future autoregressive generative designs.
Future Directions
Potential advances include integrating SAVAREdit into larger, multimodal generative backbones and hybridizing with diffusion-based latent-space editors for enhanced generalization. Further investigation into learned spatial priors in VARs could yield transferable mechanisms beneficial for cross-domain generative modeling.
Conclusion
SAVAREdit represents a rigorous advance in text-guided image editing, leveraging intrinsic VAR spatial features and adaptive feature-injection, confirmed by both qualitative and quantitative benchmarks (2603.28367). The framework demonstrates that structure-aware intervention in autoregressive generation is both feasible and highly effective, informing future developments in efficient, high-fidelity visual editing systems.

