- The paper introduces a 770-hour, multi-embodiment surgical robotics dataset that overcomes data scarcity and supports foundation model evaluation.
- It presents GR00T-H, a vision-language-action policy that achieves significant gains in autonomous suturing and cross-embodiment transfer.
- The dataset and accompanying simulator enable scalable, risk-free evaluation and set a new benchmark for advancements in surgical autonomy.
Open-H-Embodiment: Scaling Foundation Models in Medical Robotics via Cross-Embodiment, Multimodal Surgical Datasets
Introduction
Autonomous medical robotics is constrained by severe data scarcity, particularly in domains requiring high-skill, multi-step procedures with sensitive patient outcomes. The field faces unique bottlenecks relative to general-purpose robotics: clinical safety protocols, dominant single-embodiment datasets, and highly specialized sensorimotor settings restrict both scale and diversity in available benchmarks. "Open-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics" (2604.21017) directly addresses this challenge by introducing the first community-driven, cross-institution, multi-embodiment surgical robotics dataset sufficient for foundation model development and evaluation. The work demonstrates, through rigorous downstream evaluations, that this new class of corpus resolves critical limitations in transferability, robustness, and policy scaling for complex surgical tasks.
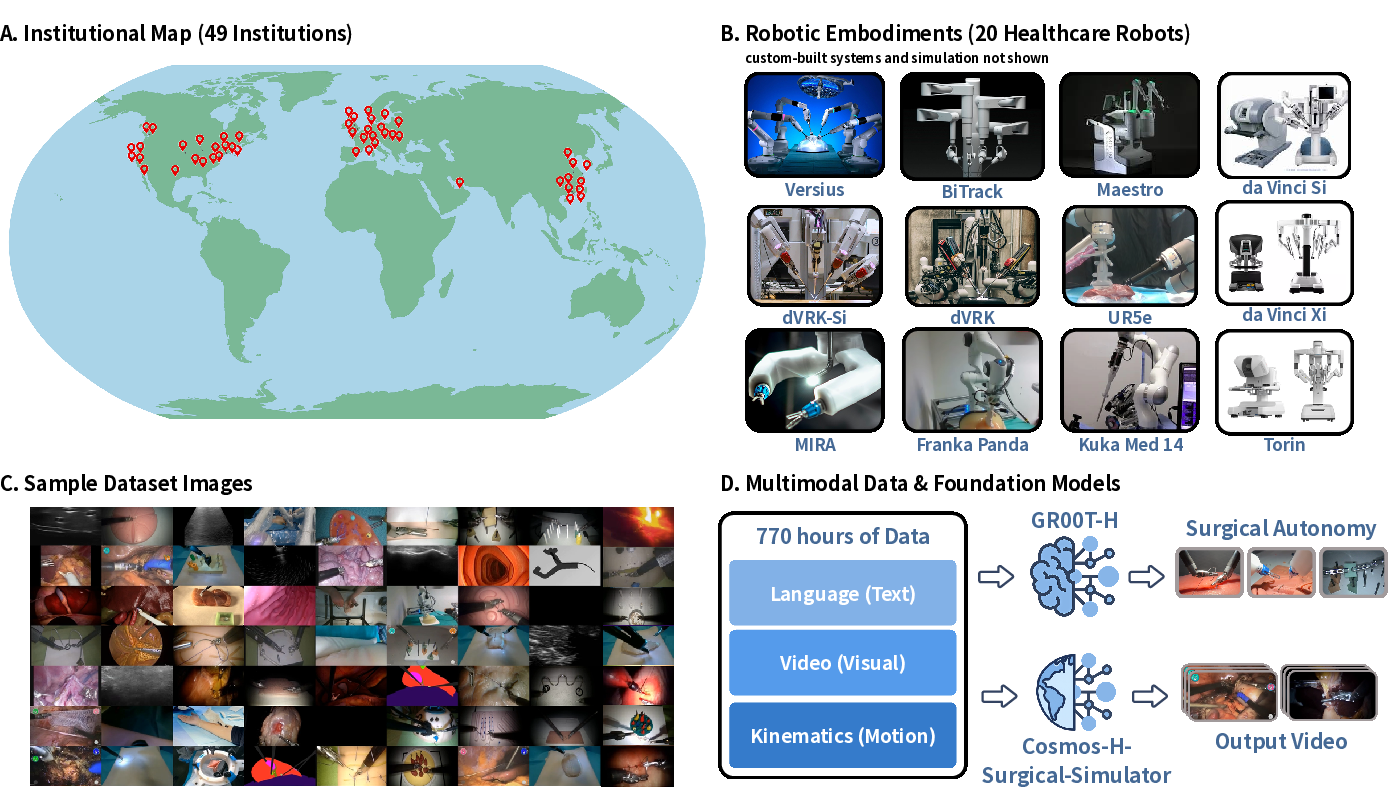
Figure 1: Overview of Open-H-Embodiment, including geographic dispersion, multimodal platform diversity, task coverage, and key training applications.
Dataset Composition and Coverage
Open-H-Embodiment aggregates 770 hours of tightly synchronized video, kinematics, and multimodal demonstrations from over 49 institutions, spanning 20 distinct healthcare robotic platforms. This corpus represents a step change: prior datasets rarely exceeded 20 hours or a single embodiment. The data curation covers not only surgical manipulation (e.g., da Vinci Si/Xi, dVRK-Si, MIRA, BiTrack, Versius, Maestro), but also general-purpose arms adapted for clinical use and emerging platforms. Key to clinical translation, the dataset includes benchtop, ex vivo, tissue phantom, animal, and real clinical operating room environments.
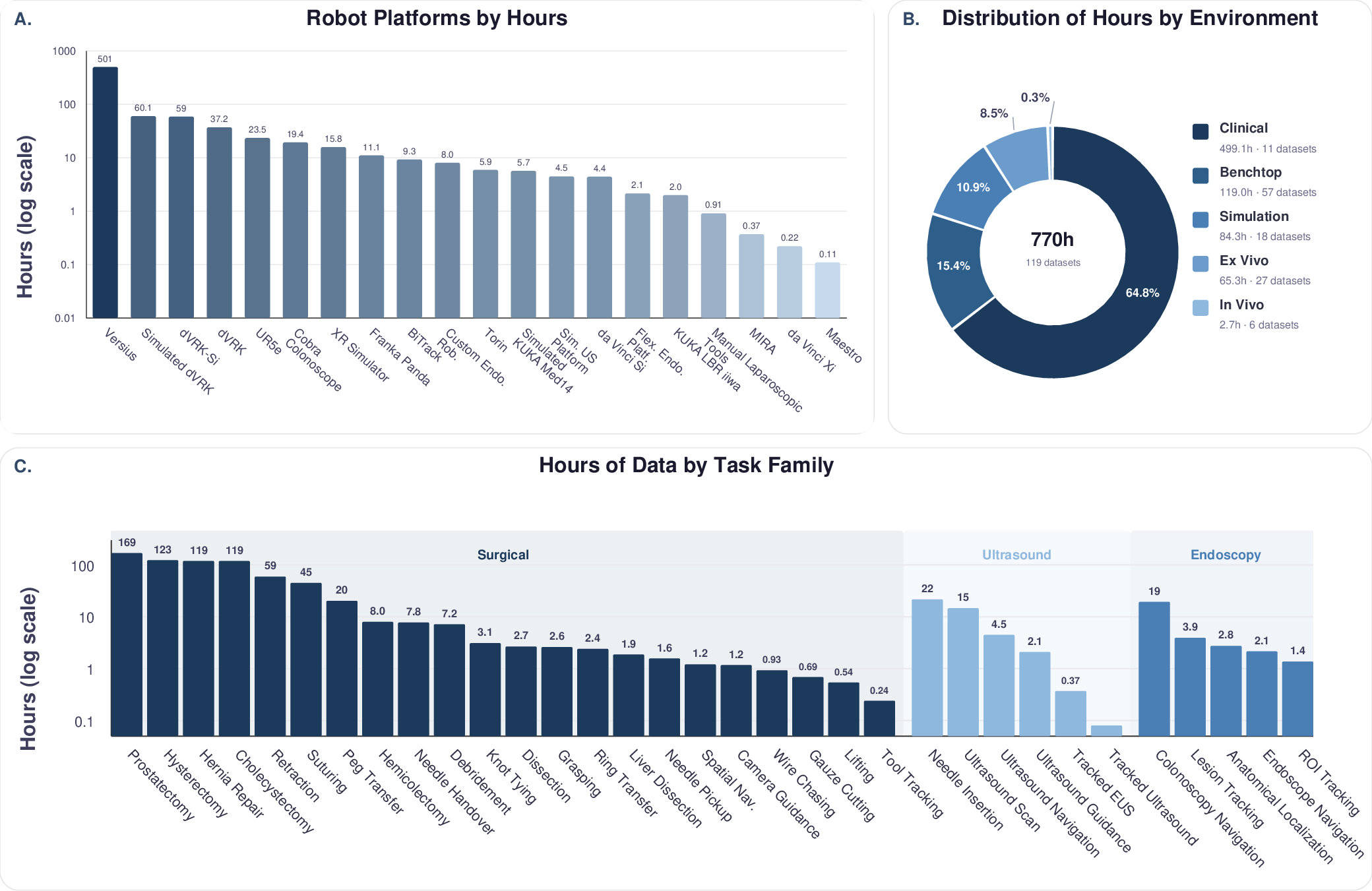
Figure 2: Summary statistics showing distribution of data volume by platform, environment, and both high-level procedure and low-level task family.
Notably, the scale and diversity of Open-H address the entire autonomy hierarchy, from isolated manipulation primitives to full real-world procedural trajectories. Modalities extend beyond video and kinematics to include stereo endoscopy, depth sensing, ultrasound, wrist/eye-gaze cameras, and synthetic simulator-generated labels (e.g., surface normals, segmentation, optical flow). By supporting both multimodal model pretraining and fine-grained task annotation, the dataset enables a unified benchmark for transferable, generalist robotics research in the medical domain.
Vision-Language-Action Foundation Model: GR00T-H
Leveraging Open-H, the authors introduce GR00T-H, a foundational Vision-Language-Action (VLA) policy adapted from NVIDIA's GR00T-N1.6. This architecture augments a Cosmos-2B vision transformer backbone with embodiment-specific action heads, supporting relative 6D EEF control and robust kinematic normalization across heterogeneous robots.
Downstream evaluation focused on autonomous surgical suturing—an established, challenging benchmark for long-horizon policy robustness, distribution shift, and compounding error tolerance. GR00T-H was systematically benchmarked against domain-specialist (ACT), generalist (GR00T-N1.6), and world-model-based (LingBot-VA) policies:
- End-to-End Task Completion: GR00T-H achieved successful completion on 25% of SutureBot benchmark attempts. All baselines failed to complete any trial in this regime.
- Generalization: When evaluated on previously unseen wound geometries and lighting, GR00T-H maintained 54% average subtask success, outperforming GR00T-N1.6 (30%) and ACT (5%).
- Data Efficiency: With only 33% of fine-tuning data, GR00T-H matches ACT performance, but at full data outperforms all baselines (73% vs. 50% [ACT] and 37% [GR00T-N1.6]).
- Cross-Embodiment Transfer: On three distinct robotic platforms (da Vinci dVRK-Si, Versius, MIRA), GR00T-H exhibited significant cross-system and cross-task performance gains, establishing statistical robustness (p<0.001) to embodiment- and setup-dependent variations.
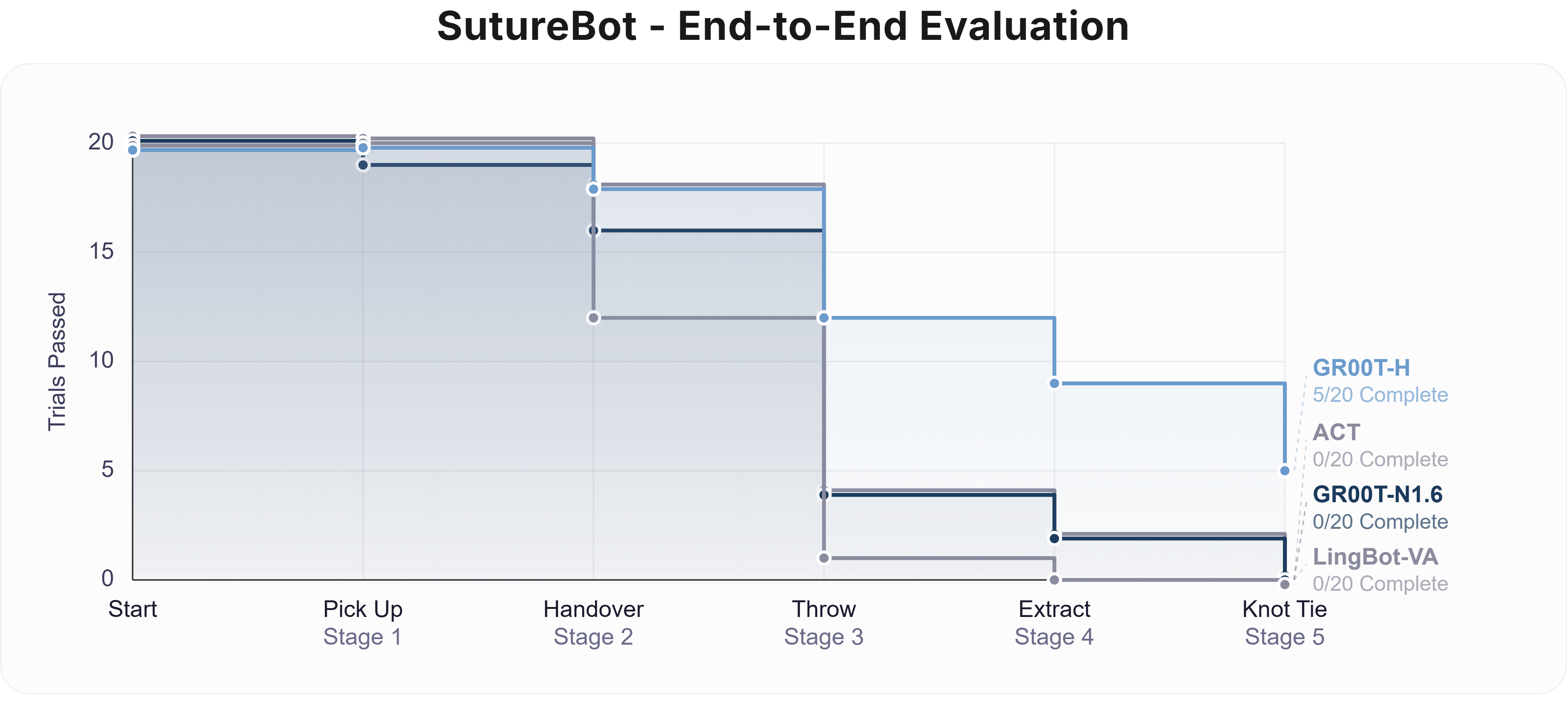
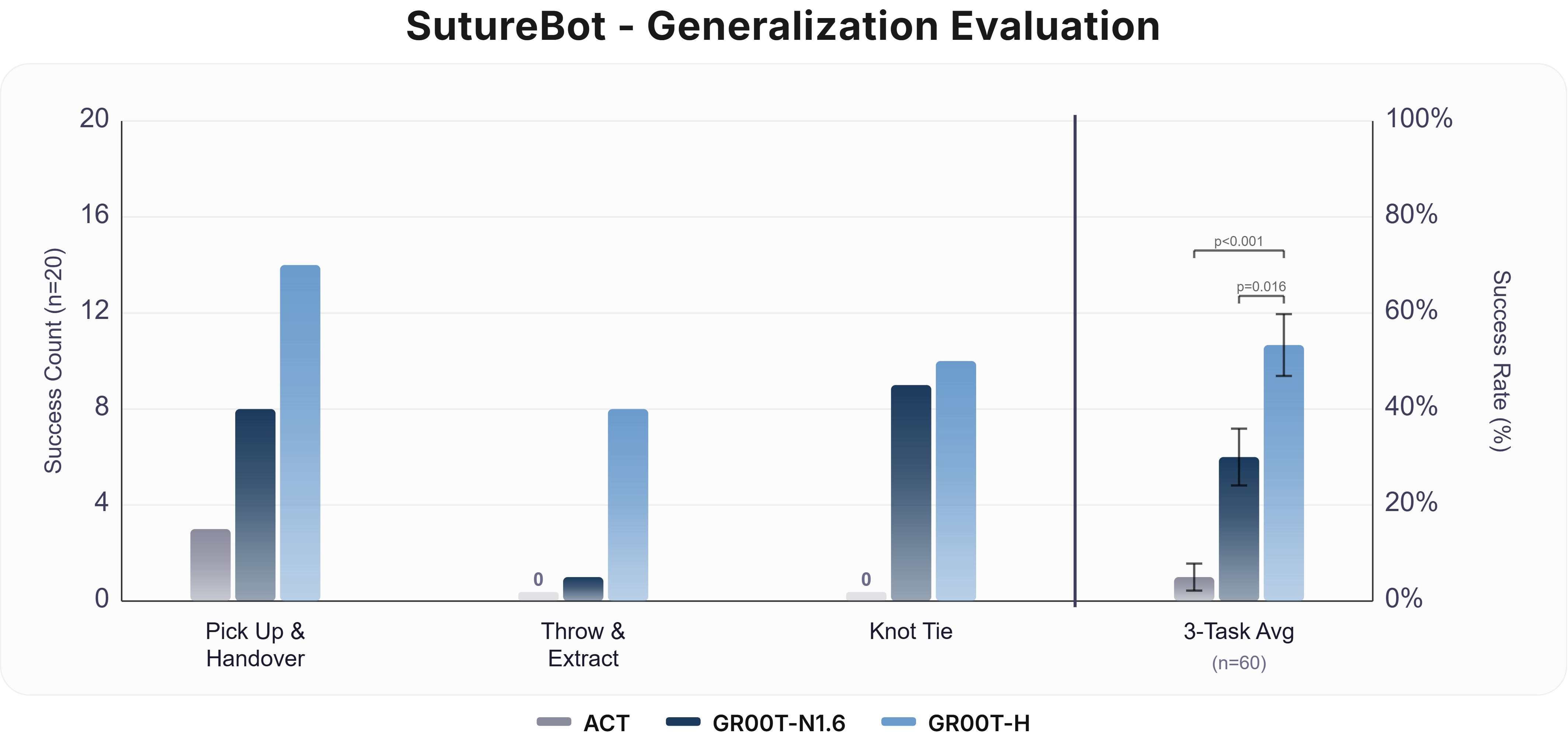
Figure 3: End-to-end and OOD SutureBot suturing results, contrasting GR00T-H against state-of-the-art baselines in both canonical and distribution-shifted scenarios.
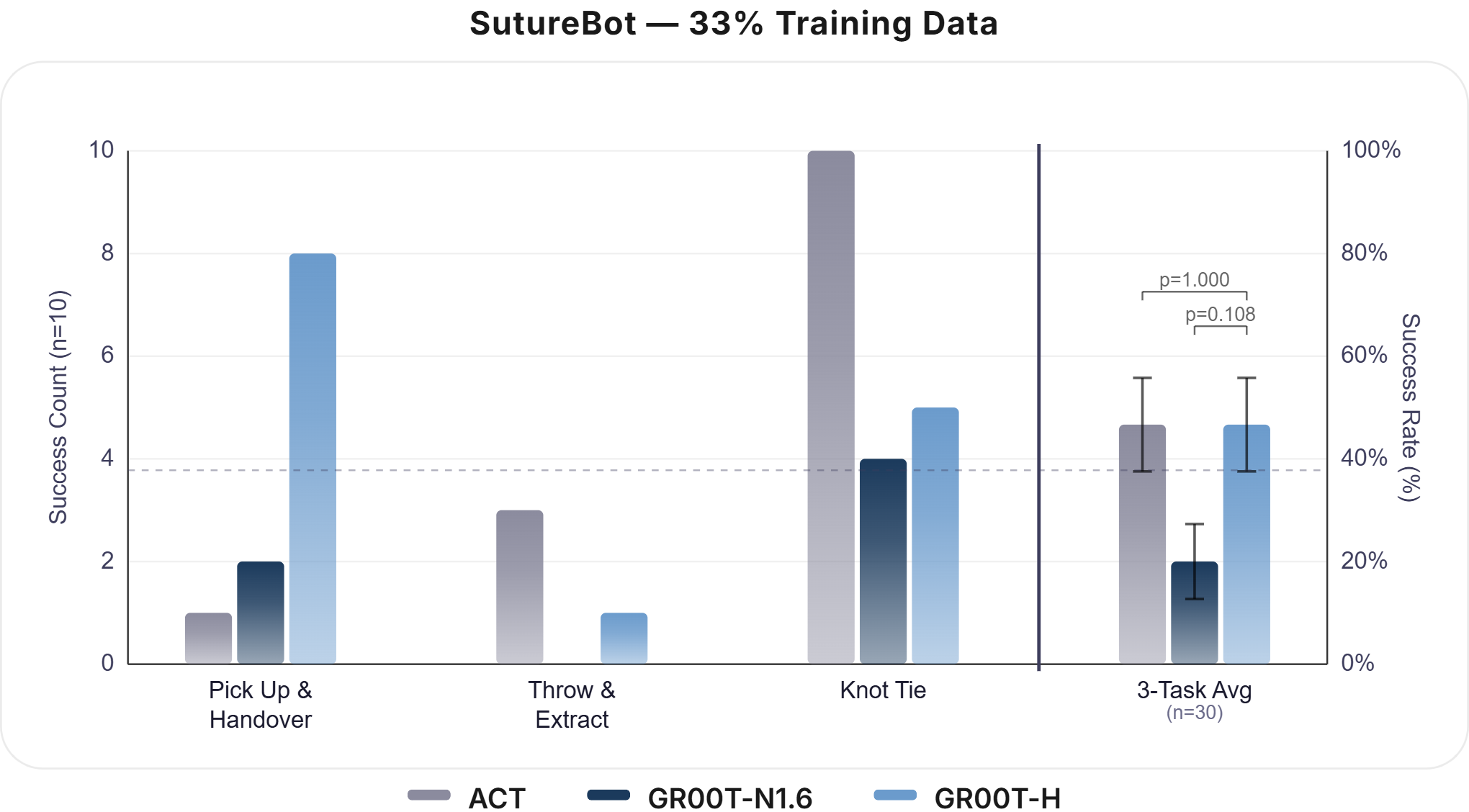
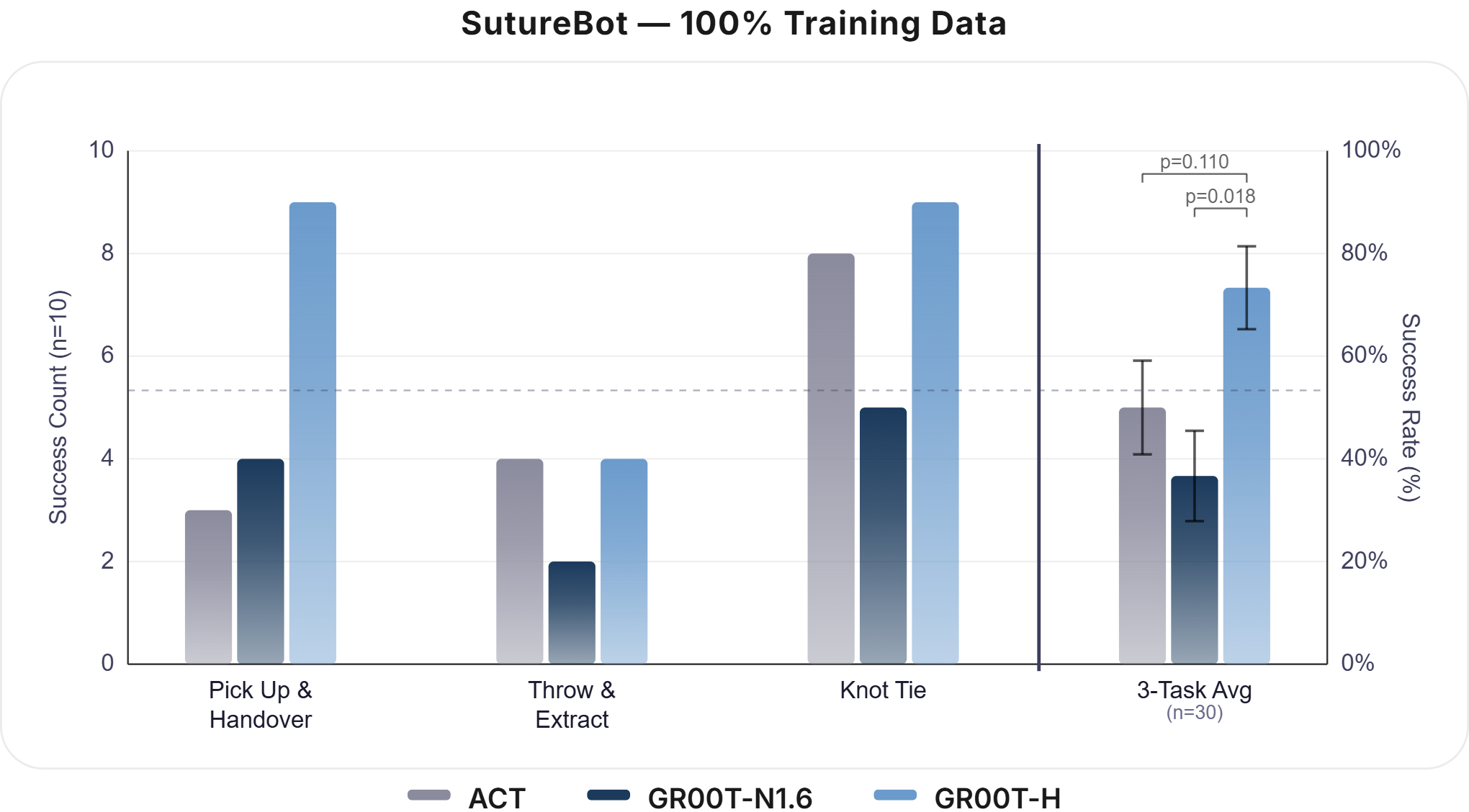
Figure 4: GR00T-H displays strong data efficiency across fine-tuning fractions, enabling high-performance learning with limited task data.
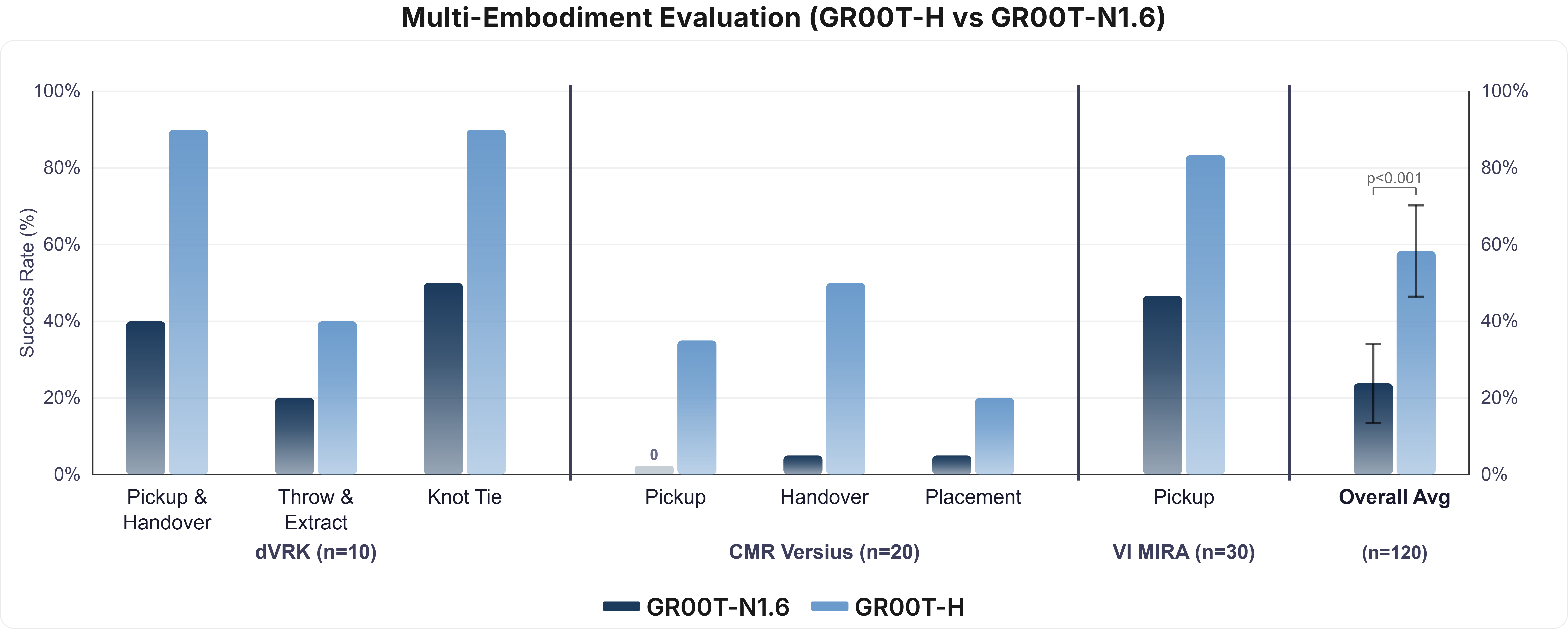
Figure 5: Multi-embodiment evaluation reveals the broad transfer gains achieved by Open-H–driven post-training across da Vinci, Versius, and MIRA systems.
Ex Vivo Surgical Workflow and Failure Analysis
In a rigorous 29-subtask ex vivo suturing sequence on real tissue, GR00T-H attained an average success rate of approximately 64% (10 trials per subtask). The model achieved near-perfect performance in structured manipulation (e.g., needle pickup, handover, knot tying), with pronounced declines in steps requiring fine-contact manipulation and rapid instrument interactions (e.g., suture cutting). Failure patterns were spatially and procedurally localized, suggesting fine-tuning or additional data in these domains could close remaining autonomy gaps.
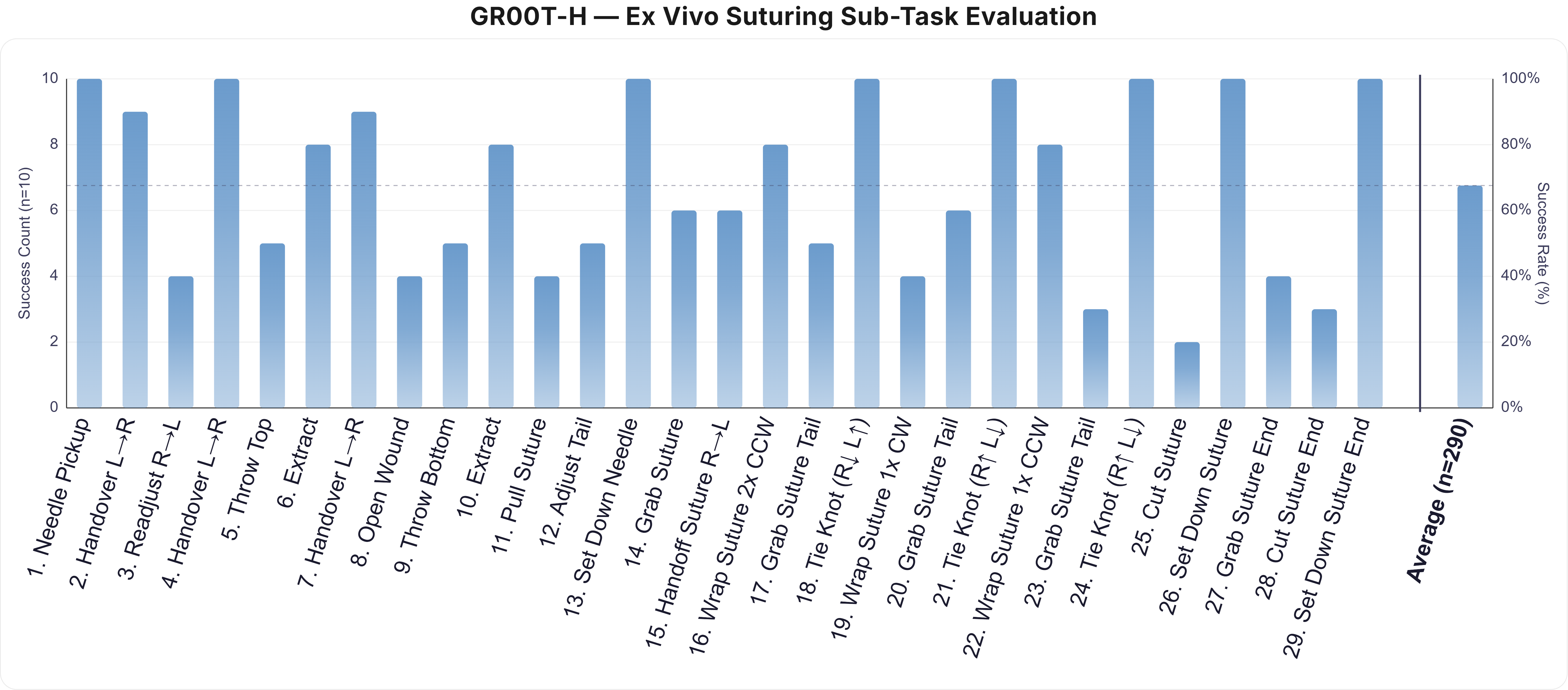
Figure 6: Success rate distribution for the 29-subtask ex vivo sequence, highlighting robust instrument manipulation versus remaining challenges in fine-contact and cutting.
Surgical World Model: Cosmos-H-Surgical-Simulator
Complementing the policy advances, the authors introduce the first multi-embodiment, action-conditioned surgical world model, Cosmos-H-Surgical-Simulator (C-H-S-S), extending Cosmos-Predict 2.5. This model autoregressively generates surgical scene videos conditioned on current observations and action sequences for any of nine supported robot systems, enabling scalable simulation, policy evaluation, and synthetic data generation.
- Video Prediction Quality: On held-out test episodes, benchtop/phantom environments achieved low L1 error and high SSIM across 72-frame rollouts, while tissue-based (clinical/cadaver/ex vivo) datasets exhibited expected higher error and variability due to the intrinsic visual complexity of in situ surgeries.
- Single Checkpoint, Many Embodiments: C-H-S-S supports all training-distribution platforms without need for per-embodiment retraining or manual checkpointing.
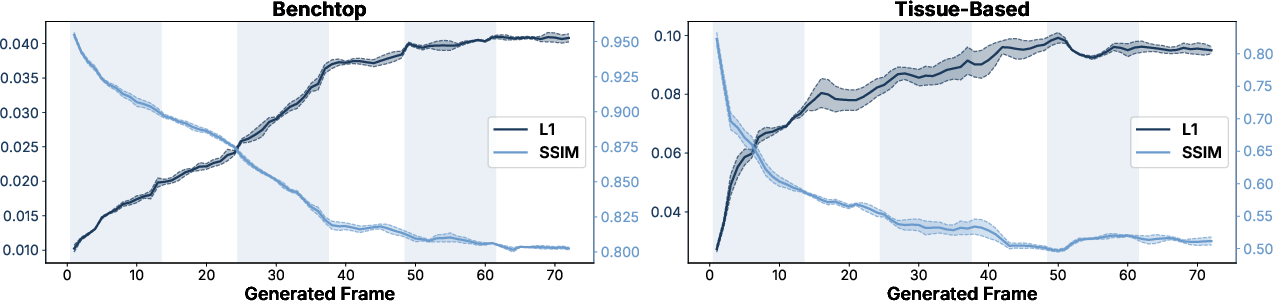
Figure 7: Quantitative world model evaluation via L1 and SSIM, stratified by benchtop (phantom) vs. tissue-based (clinical, cadaver, ex vivo) domains.
Experimental Setups and Qualitative Results
Experimental platforms include benchtop SutureBot, out-of-distribution wound generalization settings, emergent robots (MIRA, Versius), and ex vivo porcine tissue tasks, with extensive video documentation of successful policy executions and simulation rollouts.
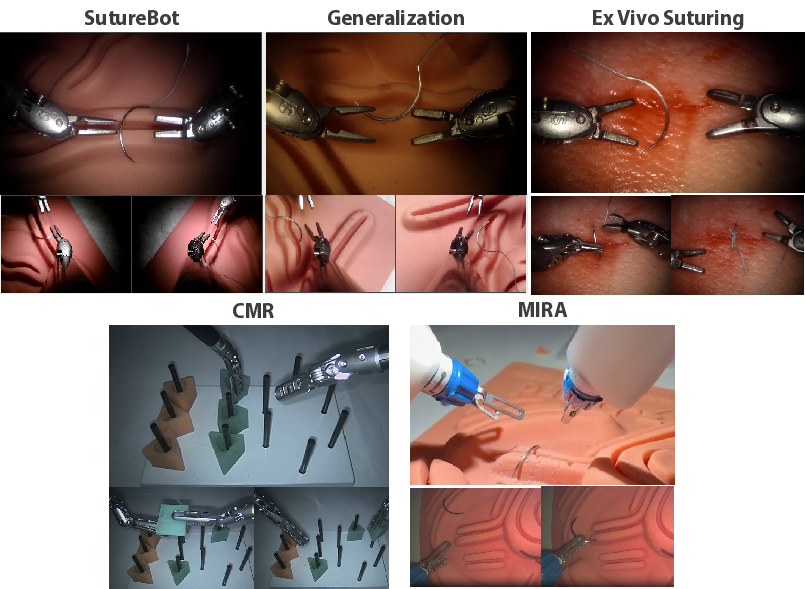
Figure 8: Overview of experimental platforms for policy and world model evaluation, spanning phantom, OOD, multi-embodiment, and ex vivo testbeds.
Implications and Future Directions
Open-H-Embodiment and its downstream foundation models provide direct empirical evidence that diverse, multi-institution surgical corpora unlock transfer, robustness, and scaling behaviors previously observed only in generalist robot learning or vision-language domains. The results substantiate that the transfer deficit between generalist and surgical policies can be addressed with domain-appropriate, high-capacity pretraining. The public release of all datasets, models, and code establishes the first widely usable infrastructure for reproducible and generalizable research in surgical autonomy.
Practically, the increases in policy robustness to both distribution shift and hardware variation (e.g., instrument wear, camera replacements) are critical for clinical deployment. Theoretical implications include the extension of scaling laws for VLA architectures into high-stakes, low-tolerance error settings—where compounding error and long-horizon procedural reasoning are essential. The availability of first-of-kind action-conditioned video models for surgical simulation introduces a new axis for risk-free policy evaluation and domain randomization.
Limitations remain: average task success rates do not reach clinical reliability, particularly for fine-contact or high-precision subtasks. All policy evaluations were conducted in controlled non-living environments—generalization to animal or human tissue, especially under unanticipated events (tissue tearing, equipment failure), remains future work. Annotated failure modes and richer instrument/tissue interaction labeling are required to close current performance gaps. Extending domain-specific evaluation metrics for action-conditioned video prediction, as well as closed-loop simulation via world models, is an open research problem that may require new instrumentation or automated benchmarks.
Conclusion
"Open-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics" (2604.21017) marks a pivotal shift in the resources available for surgical autonomy research. Through the construction and open release of a 770-hour, multi-embodiment, multimodal platform, the authors eliminate longstanding data bottlenecks, enabling the construction and rigorous evaluation of generalist, transfer-robust policies and action-conditioned world models tailored to the intricacies of surgical robotics. The empirical results demonstrate substantial gains in end-to-end task success, data efficiency, cross-system generalization, and simulation fidelity. These contributions are poised to function as essential infrastructure for subsequent advances in robot learning, surgical AI, and the practical realization of autonomous medical systems.

