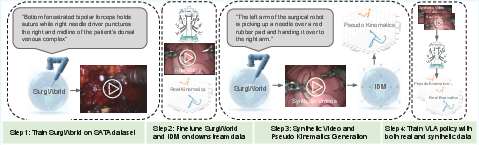
SurgWorld: Learning Surgical Robot Policies from Videos via World Modeling
Abstract: Data scarcity remains a fundamental barrier to achieving fully autonomous surgical robots. While large scale vision language action (VLA) models have shown impressive generalization in household and industrial manipulation by leveraging paired video action data from diverse domains, surgical robotics suffers from the paucity of datasets that include both visual observations and accurate robot kinematics. In contrast, vast corpora of surgical videos exist, but they lack corresponding action labels, preventing direct application of imitation learning or VLA training. In this work, we aim to alleviate this problem by learning policy models from SurgWorld, a world model designed for surgical physical AI. We curated the Surgical Action Text Alignment (SATA) dataset with detailed action description specifically for surgical robots. Then we built SurgeWorld based on the most advanced physical AI world model and SATA. It's able to generate diverse, generalizable and realistic surgery videos. We are also the first to use an inverse dynamics model to infer pseudokinematics from synthetic surgical videos, producing synthetic paired video action data. We demonstrate that a surgical VLA policy trained with these augmented data significantly outperforms models trained only on real demonstrations on a real surgical robot platform. Our approach offers a scalable path toward autonomous surgical skill acquisition by leveraging the abundance of unlabeled surgical video and generative world modeling, thus opening the door to generalizable and data efficient surgical robot policies.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching surgical robots new skills by learning from videos. The big problem today is that we don’t have enough paired data that shows both what the robot sees (video) and exactly what the robot did (its precise movements). There are lots of surgery videos online, but they don’t come with the robot’s actions. The authors build a system called SurgWorld that “imagines” realistic surgery videos and, from those, guesses the actions a robot would take. This creates a lot of extra training data so surgical robots can learn better and faster.
Key Objectives
The researchers set out to answer three simple questions:
- How can we use the huge number of unlabeled surgery videos to train surgical robots?
- Can a “world model” (a video generator that understands how things move) make believable surgical videos that match text instructions?
- If we create pairs of videos and estimated actions from these generated videos, will robots perform better in the real world?
Methods and Approach (in everyday language)
Think of teaching a robot like coaching a player in a sport:
- If you have full game footage and the player’s exact moves, training is easy. But in surgery, you mostly have videos without the “move list.”
- This paper builds a way for the robot to practice by using imagination plus smart guessing.
Here’s how they did it:
- Building a clear “playbook” of surgical actions (the SATA dataset)
- They collected 2,447 short surgery clips covering four basic suturing actions and wrote detailed text descriptions for each.
- The four actions are:
- Needle grasping (picking up the needle)
- Needle puncture (pushing the needle through tissue)
- Suture pulling (pulling the thread through)
- Knotting (tying the thread)
- These descriptions explain what tool is doing what, where, and to which body part. That helps the AI understand not just what it sees, but what it means.
- Teaching a world model to “imagine” surgery videos (SurgWorld)
- A world model is like a smart movie-maker in the AI’s head. It learns the rules of how the scene changes over time, so it can predict future frames or create new videos that look real.
- The authors started from a powerful video model and trained it on their surgery clips plus the text descriptions. Now, when given a starting frame and a prompt (like “perform a needle handover”), it can generate a realistic short surgery video that follows the instruction.
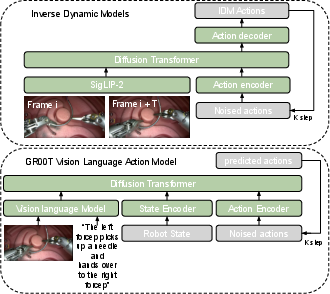
- Guessing the hidden “move list” (inverse dynamics)
- Inverse dynamics is like watching two frames of a sports video and figuring out what moves the player must have made in between.
- They trained an inverse-dynamics model that takes a short piece of video and estimates the robot’s actions (positions, rotations, and gripper opening) that would produce what you see.
- Training the robot’s policy using both real and synthetic data
- A policy is the robot’s decision-maker: given what it sees and a goal in words, it outputs the actions to take next.
- They trained a vision–language–action (VLA) policy using:
- A small set of real robot demos with true action data (limited and expensive to collect).
- Many synthetic videos generated by SurgWorld, labeled with estimated actions from the inverse-dynamics model.
- This mix lets the robot learn from far more examples without needing risky or costly real surgeries.
Main Findings and Why They Matter
What they tested:
- Video quality and understanding: Does SurgWorld make realistic videos that match the text prompt?
- Few-shot learning: Can the world model adapt to a new surgical task with very little real data?
- Real robot performance: Does adding synthetic video–action pairs help a robot do a real task better?
What they found:
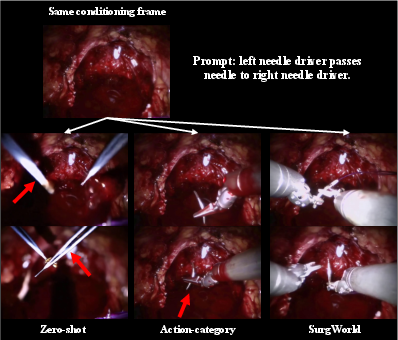
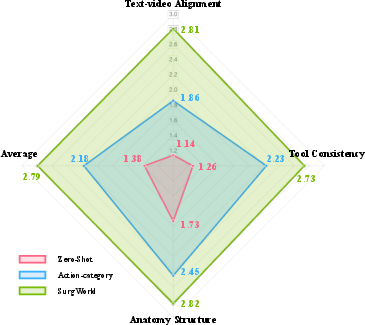
- More realistic, better-aligned videos: SurgWorld produced higher-quality videos that matched the text instructions better than baseline versions. Human surgical experts also rated these videos as more accurate and believable.
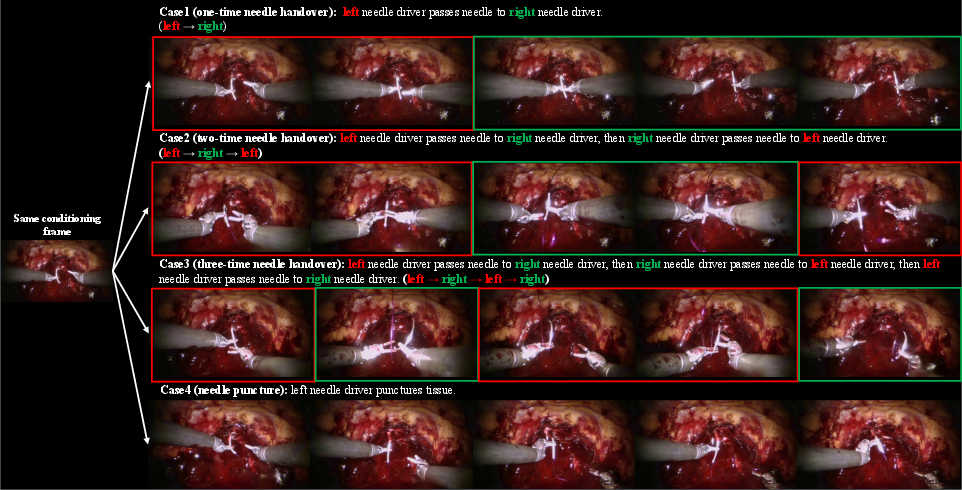
- Learns new behaviors from prompts: With the same starting image, changing the instruction (“one handover,” “two handovers,” “needle puncture”) made SurgWorld produce the appropriate, distinct action sequences. This shows strong text-to-video understanding.
- Adapts with very little data: When given only a few real examples, the model fine-tuned well and generated more successful, task-complete videos than baselines.
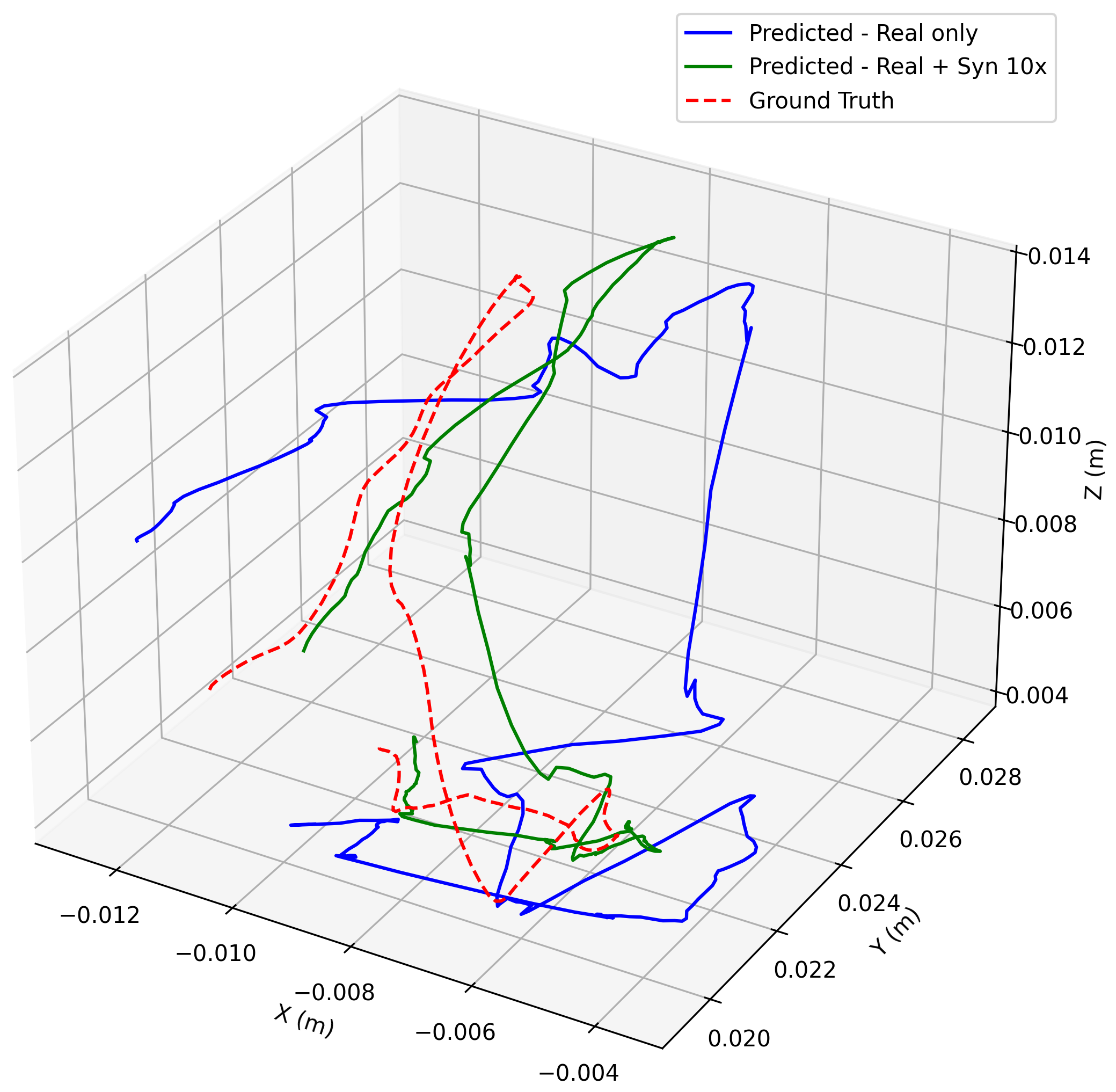
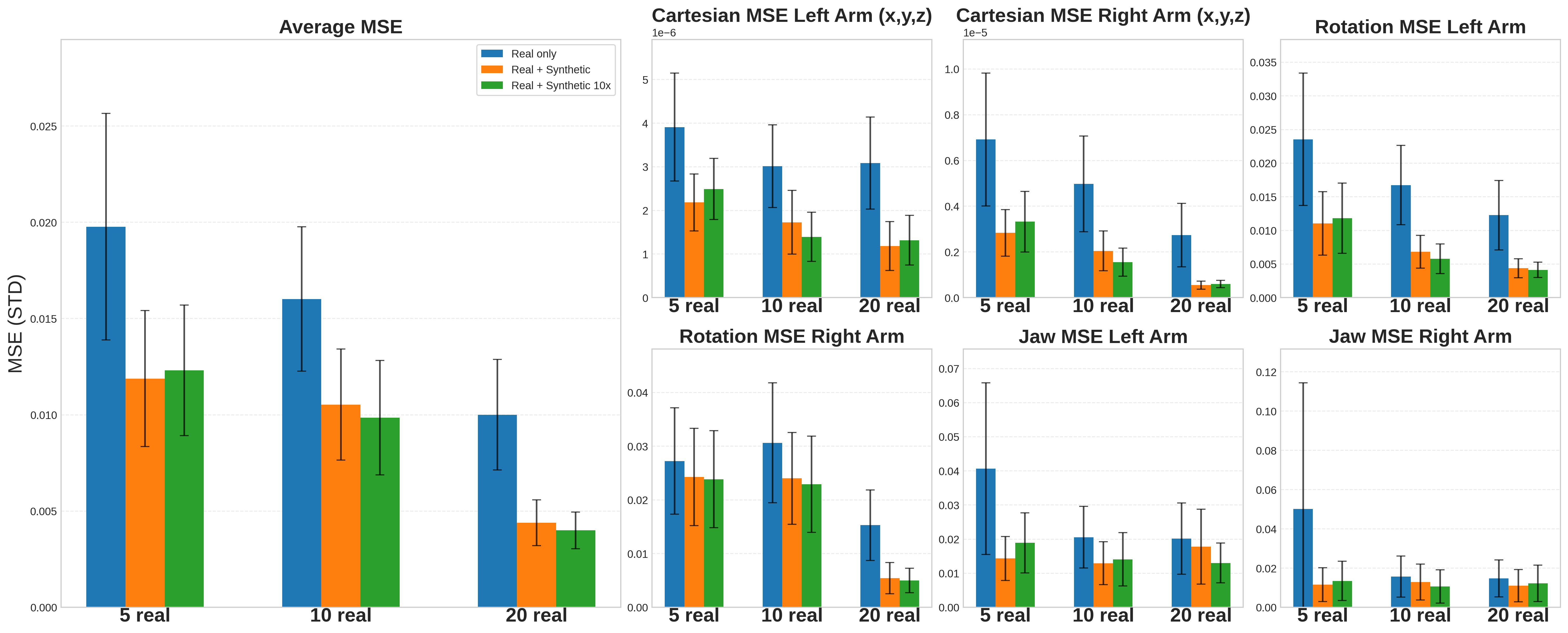
- Real robot improves with synthetic data: A surgical robot trained on both real demos and synthetic pairs made smaller mistakes and followed the correct motion more closely than one trained only on real demos. In simple terms: more practice examples (even synthetic ones) led to better performance on a real robot doing needle pickup and hand-over.
Why this is important:
- Surgical data is hard to collect because of privacy, safety, and cost. SurgWorld turns plentiful unlabeled videos into useful training material.
- Better training data means safer, more reliable robot skills with fewer hours in the operating room.
Implications and Impact
- Safer, scalable training: Hospitals and researchers can train surgical robots without needing tons of in-person procedures. This can speed up progress while protecting patients.
- Generalization: Because the model learns from many different scenes and detailed text, robots can adapt to new tools, views, or steps more easily.
- A path to autonomy: This approach brings us closer to robots that assist surgeons more intelligently—steady hands for precise, repetitive steps—reducing fatigue and improving consistency.
Limitations and what’s next:
- Each new robot type still needs some fine-tuning data to align the world model and the inverse-dynamics model.
- The “guessed” actions from video aren’t perfect and can add some noise.
- The dataset, while large and detailed, doesn’t cover every surgery type yet.
Overall, SurgWorld shows a promising way to turn the ocean of unlabeled surgical videos into practical training power, helping surgical robots learn faster, safer, and better.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of gaps and open questions that remain unresolved and could guide future research:
- Dataset coverage and balance: SATA includes four suturing-related actions across 8 procedures, but excludes many clinically critical skills (e.g., dissection, vessel clipping, stapling, cauterization, suction, camera manipulation). It is also imbalanced (e.g., fewer knotting clips), potentially biasing learned dynamics; quantify and correct the imbalance and extend to broader surgical activities.
- Annotation granularity and validation: The paper does not report inter-annotator agreement, per-frame temporal alignment precision, or label consistency across sources; establish reliability metrics and adjudication protocols, and release annotation guidelines to support reproducibility.
- Open sourcing and licensing: It is unclear whether SATA, SurgWorld weights/adapters, IDM, and training scripts are publicly available and under what licenses; clarify release plans and address patient privacy/compliance (e.g., HIPAA, GDPR) for internet-derived surgical videos.
- Text grounding robustness: Text–video alignment is shown with curated prompts and limited behaviors (e.g., single/multi handovers); stress-test with complex, multi-step, conditional instructions, ambiguous phrasing, synonyms, multilingual prompts, and adversarial/incorrect prompts to quantify grounding failure modes.
- Domain diversity and realism: Internet videos differ from clinical OR conditions (smoke, bleeding, fogging, lens contamination, rapid camera motion, trocar repositioning); evaluate robustness and fine-tune to these phenomena and report failure rates under occlusions/specularities.
- Stereo and 3D perception assumptions: The robot uses a stereo endoscope, but training appears to use single 224×224 frames; quantify how monocular vs stereo inputs affect 3D action inference (especially depth, orientation), and assess sensitivity to camera calibration errors and moving-camera scenarios.
- Physical plausibility and constraints: Video generation lacks explicit modeling of contact physics, tool limits, tissue deformation, suture thread dynamics, and friction; integrate physics priors/constraints or differentiable soft-body simulation and measure gains in kinematic and contact realism.
- Temporal horizon and compounding error: The world model conditions on the first frame only; characterize rollout length limits, error accumulation over long sequences, and benefits of closed-loop video conditioning or latent state filtering.
- IDM accuracy and reliability: Pseudo-kinematics are inferred without ground truth for synthetic videos; measure IDM action error distributions, failure cases (e.g., during occlusions/fast motions), sensitivity to frame gap (T=16), and calibration mismatches between camera and action frames.
- Embodiment transferability: SurgWorld and IDM require finetuning for unseen robot embodiments; investigate embodiment-agnostic action spaces, cross-robot transfer, and scaling laws for the amount of embodiment-specific data needed.
- Synthetic-to-real ratio and curation: Although 1× and 10× synthetic sets help, the optimal synthetic/real ratio, prompt diversity, rollout length/seed strategies, and selection criteria for initial frames remain unexplored; systematically study these knobs to maximize policy gains.
- Evaluation metrics validity: FVD and VBench are not validated for surgical realism; design surgical domain metrics (e.g., tool–tissue contact accuracy, needle trajectory deviation, insertion angle/depth errors, thread tension consistency) and correlate them with policy success.
- Human evaluation rigor: Expert ratings are based on 50 samples with three evaluators; report inter-rater reliability (e.g., Cohen’s/Fleiss’ kappa) and expand the panel size and rubric to cover safety-critical criteria (e.g., tissue trauma risk, collision avoidance).
- Policy evaluation on hardware: Policy improvements are reported as offline action MSE; perform closed-loop, on-robot trials measuring task success, recovery from perturbations, safety violations, and cycle time, and compare to surgeon baselines and SRT/SRT-H benchmarks.
- Covariate shift and on-policy learning: Policies are trained via behavior cloning with limited real data; evaluate DAgger-like on-policy correction, curriculum learning, and model predictive control using the world model to mitigate covariate shift.
- Generalization across scenes and institutions: Test cross-site generalization (different hospitals, cameras, lighting, instrument manufacturers, patient anatomies) and quantify distribution shift impacts; develop domain adaptation strategies.
- Language-to-action latency and real-time constraints: Large VLA and world models may not meet surgical real-time constraints; profile inference latency, memory footprint, and propose optimizations (e.g., distillation, sparsity, caching, streaming).
- Safety assurance and guardrails: Synthetic training may encode undesirable behaviors; introduce safety constraints (e.g., tool speed/force limits, proximity thresholds), formal verification, or risk-aware training, and define failure detection/abort mechanisms.
- Multi-arm coordination and role assignment: While actions are 20D for two arms, explicit coordination strategies (e.g., leader–follower, role switching during handovers) are not analyzed; develop multi-agent control metrics and policies for dexterous bimanual tasks.
- Orientation error metrics: Rotation MSE in 6D representation is not physically interpretable; report orientation errors in degrees (e.g., geodesic distance on SO(3)) and analyze their effect on needle alignment and puncture success.
- Thread and topology handling: Suture thread dynamics and topology (loop formation, knot stability) are central to suturing but not modeled or evaluated; incorporate thread tracking/topology constraints and assess knot integrity.
- Camera-relative control assumptions: Actions are expressed in the endoscope frame; evaluate robustness to camera motion/zoom, endoscope repositioning, and changes in intrinsic/extrinsic calibration, and explore world-frame or patient-frame representations.
- Comparative baselines: Missing comparisons to physics-based simulators, domain randomization, video-only pretraining methods (e.g., AMPLIFY), or alternative world models; include ablations against these to isolate gains attributable to the proposed pipeline.
- Data augmentation and prompt engineering: The impact of visual augmentations, prompt templates, negative prompts, and instruction diversity on both video generation and policy performance is not quantified; perform targeted ablations.
- Scaling laws: The relationship between SATA size/quality, LoRA rank, pretraining duration, and downstream policy gains is unknown; derive scaling laws to guide resource allocation.
- Failure taxonomy: Provide a systematic taxonomy and quantitative breakdown of failure modes (e.g., tool hallucination, wrong action sequencing, drift, poor text grounding), tied to root causes (data scarcity, annotation errors, model biases).
- Clinical integration pathway: Outline the steps for clinical translation (bench-to-OR), including regulatory validation, human factors studies, surgeon-in-the-loop supervision, and risk management; propose standardized evaluation protocols for autonomous surgical assistance.
Practical Applications
Immediate Applications
Below are concrete, near-term use cases that can be deployed with the methods, datasets, and workflows introduced in the paper.
- Synthetic data augmentation for policy training
- Sectors: Healthcare robotics, Software
- Use case: Boost performance of surgical manipulation policies (e.g., needle pickup and handover) by training with SurgWorld-generated video rollouts labeled via an inverse dynamics model (IDM) alongside small numbers of real demonstrations.
- Tools/products/workflows: SurgWorld LoRA adapters finetuned on task; IDM trained on out-of-domain + few task demos; VLA policy finetuning (e.g., GR00T N1.5) with mixed real + pseudo-labeled synthetic video–action pairs.
- Assumptions/dependencies: Access to a small set of real demos (5–20 shown), compute to run video generation and IDM, embodiment-specific IDM tuning, integration with robot control stack. Quality depends on IDM accuracy and the realism of generated video; regulatory use limited to benchtop/offline testing at this stage.
- Evidence from paper: Synthetic rollouts reduced action MSE across translation/rotation/gripper and improved trajectory fidelity; with few-shot data, synthetic 10× augmentation further improved performance.
- Few-shot onboarding of new robots, instruments, and tasks
- Sectors: Healthcare robotics
- Use case: Rapidly adapt policies to new surgical tools/tasks via LoRA finetuning of the world model and per-embodiment IDM with only a handful of real trajectories.
- Tools/products/workflows: LoRA finetuning pipeline; per-embodiment IDM; minimal data collection workflow; continuous integration for new task variants.
- Assumptions/dependencies: Small but representative task data, camera pose stability, per-robot calibration. The paper’s few-shot experiments show robust adaptation from just 5 trajectories when pretrained on SATA.
- Semi-automatic kinematic labeling of legacy surgical videos
- Sectors: Academia, Hospitals, Medical device OEMs
- Use case: Apply IDM to infer pseudo-kinematics for existing endoscopic videos, accelerating dataset creation for imitation learning and analytics.
- Tools/products/workflows: Batch IDM inference; human-in-the-loop QA UI for spot-checking/correcting labels; curation scripts to align videos with estimated action streams.
- Assumptions/dependencies: Reasonable domain match to IDM training; consistent endoscope framing; acceptance that pseudo-labels introduce some residual noise.
- Research benchmarking and rapid prototyping with SATA + SurgWorld
- Sectors: Academia
- Use case: Use the curated, fine-grained Surgical Action–Text Alignment (SATA) dataset and the pretraining/finetuning recipes to benchmark surgical video generation, text grounding, and policy learning.
- Tools/products/workflows: SATA prompts for action granularity; FVD/VBench metrics; expert review rubric for anatomical/tool realism; baselines like zero-shot vs. action-category vs. SurgWorld.
- Assumptions/dependencies: Dataset availability/licensing; adequate compute; adherence to the paper’s evaluation protocols.
- Curriculum video generation for surgical education
- Sectors: Healthcare education
- Use case: Generate photorealistic, text-aligned endoscopic videos demonstrating core actions (grasping, puncture, pulling, knotting), with controlled complexity (e.g., one-, two-, three-time handovers) for resident training and assessment.
- Tools/products/workflows: Prompt library; scenario packs by action type; LMS integration for annotation, quizzes, and self-assessment.
- Assumptions/dependencies: Faculty validation of realism and pedagogical value; disclosure of synthetic content; adherence to institutional training policies.
- Simulator enrichment and domain randomization
- Sectors: Software/simulation, Healthcare robotics
- Use case: Augment surgical simulators with realistic video sequences for perception modules, domain randomization for visual variation (lighting, occlusions), and rare-case exposure.
- Tools/products/workflows: API to generate synthetic rollouts from initial frames; dataset packing for sim training; pipelines to mix sim-rendered and SurgWorld-generated content.
- Assumptions/dependencies: Synchronization between sim states and generated visuals; proper coverage of visual edge cases; simulator–video alignment for perception.
- Offline stress-testing and QA of autonomy
- Sectors: Healthcare robotics, QA/Validation
- Use case: Generate diverse synthetic scenarios to test policy robustness (occlusions, imperfect initial poses), measure trajectory errors, and perform failure analysis before benchtop runs.
- Tools/products/workflows: Scenario libraries; batch evaluation harness; trajectory-MSE dashboards; regression testing across policy versions.
- Assumptions/dependencies: Scenario diversity and realism correlate with real-world failure modes; acceptance of synthetic stress tests by internal QA.
- Communication and marketing visuals for medical devices
- Sectors: Medical device companies
- Use case: Produce high-quality, text-consistent videos to illustrate instrument capabilities or training pathways without exposing patient data.
- Tools/products/workflows: Controlled prompts; brand-specific scenarios; review/approval workflows for external communications.
- Assumptions/dependencies: Clear disclosure as synthetic; compliance with medical advertising guidelines.
- Methodology export to other vision-action-scarce domains
- Sectors: Robotics (manufacturing micro-assembly, lab automation), Endoscopy (non-robotic)
- Use case: Apply world modeling + IDM for domains that have abundant videos but few action labels to bootstrap VLA policies or perception pretraining.
- Tools/products/workflows: Domain-specific LoRA finetuning; per-embodiment IDM; mixed real + synthetic policy training.
- Assumptions/dependencies: Availability of curated video corpora; embodiment-specific adaptation; domain shift management.
Long-Term Applications
These opportunities require additional research, validation, scaling, and/or regulatory progress to be feasible in clinical or production environments.
- Step-level surgical autonomy (suturing, knot-tying, tissue handling)
- Sectors: Healthcare robotics
- Use case: Execute complex multi-step maneuvers under surgeon supervision, expanding from fundamental actions to procedure steps.
- Tools/products/workflows: Text-conditioned VLA policies; safety monitors; recovery behaviors; closed-loop perception.
- Assumptions/dependencies: Regulatory approval (FDA/CE), extensive real-world evaluation, reliable perception under blood, smoke, and occlusion, robust fail-safes.
- Generalist surgical VLA foundation model
- Sectors: Healthcare robotics, Academia
- Use case: A single model that generalizes across procedures, tools, and anatomies, controllable via natural language (“handover twice”, “puncture at X”).
- Tools/products/workflows: Massive mixed real + synthetic training; broader SATA-like datasets; multi-institution data partnerships; deployment SDKs.
- Assumptions/dependencies: Scale of data and compute, standardized prompts and taxonomies, governance for data sharing and synthetic augmentation reporting.
- Patient-specific preoperative rehearsal and intraoperative planning
- Sectors: Healthcare IT, Surgical planning
- Use case: Generate plausible tool–tissue interaction sequences for a specific patient’s anatomy to plan suturing paths or port placement; rehearse difficult steps.
- Tools/products/workflows: Integration with imaging (CT/MRI), digital-twin OR tools, prompt templates linked to anatomy maps.
- Assumptions/dependencies: Accurate anatomy conditioning, validation of biomechanical plausibility, data integration pipelines, clinician acceptance.
- Teleoperation assistance via predictive displays
- Sectors: Tele-surgery, Human–robot interaction
- Use case: Predict surgeon intent and provide latency compensation or suggested trajectories overlaid on video; automated “ghost” motion previews.
- Tools/products/workflows: Real-time world model rollouts; HUD overlays; shared-control interfaces.
- Assumptions/dependencies: Low-latency inference, reliable intent inference, human factors validation, safety interlocks.
- Hospital-scale surgical process mining and analytics
- Sectors: Healthcare IT, Hospital operations
- Use case: Use IDM and vision models to structure OR video into action timelines, quantify efficiency and skill, and identify training needs across departments.
- Tools/products/workflows: Secure ingestion; de-identification; action/timeline extraction; dashboards and alerts.
- Assumptions/dependencies: Legal/ethical approvals and consent frameworks; robust de-identification; compute and storage; change management.
- Regulatory safety validation using synthetic scenarios
- Sectors: Policy/regulation, QA/Compliance
- Use case: Build standardized scenario libraries (occlusions, instrument collisions, rare failure modes) to validate autonomy and document coverage evidence.
- Tools/products/workflows: Reference scenario packs with metrics; conformance tests; reporting templates for regulators.
- Assumptions/dependencies: Acceptance of synthetic tests as part of evidence; calibration against real incident data; traceability and reproducibility.
- Adaptive, competency-based simulators and credentialing
- Sectors: Healthcare education
- Use case: Closed-loop simulators that generate scenarios based on trainee performance, evaluate micro-skills (e.g., approach angles), and support credentialing decisions.
- Tools/products/workflows: Skill assessment models; adaptive difficulty engines; integration with residency programs and CME platforms.
- Assumptions/dependencies: Validity studies proving skill transfer; governance for assessment use.
- Real-time world-model-informed control (predictive planning/MPC)
- Sectors: Robotics
- Use case: Use short-horizon predictions to avoid occlusions, plan smooth instrument trajectories, and recover from errors in tight anatomy.
- Tools/products/workflows: Latent-space MPC; uncertainty-aware planning; safety constraints.
- Assumptions/dependencies: Real-time throughput on OR hardware; calibrated uncertainty; robust state estimation.
- Multi-agent coordination in the OR
- Sectors: Robotics, OR operations
- Use case: Coordinate two robotic arms (and potentially an assistive robot) for handovers, retraction, and tool exchanges with text-informed intent.
- Tools/products/workflows: Multi-arm VLA policies; constraint-aware scheduling; shared world models.
- Assumptions/dependencies: Multi-robot safety and synchronization; shared calibration; human-in-the-loop oversight.
- Instrument and camera design optimization
- Sectors: Medical device R&D
- Use case: Use synthetic rollouts to explore camera placements, instrument articulation ranges, and jaw designs for better manipulability and visibility.
- Tools/products/workflows: Design-of-experiments with synthetic data; CAD–AI co-simulation; objective metrics for coverage and reachability.
- Assumptions/dependencies: Fidelity of world model to tool–tissue physics; linkage to mechanical constraints.
- Cross-specialty extensions (IR, GI endoscopy, dentistry, micro-assembly)
- Sectors: Healthcare, Industrial robotics
- Use case: Replicate the video-to-action pipeline in other minimally invasive or fine-manipulation domains with abundant unlabeled video.
- Tools/products/workflows: Domain-specific LoRA finetuning; bespoke IDM; mixed-data training.
- Assumptions/dependencies: Domain-specific datasets; embodiment differences; safety and regulatory pathways.
- Standards and governance for synthetic medical data
- Sectors: Policy, Standards bodies, Ethics
- Use case: Define consent, disclosure, and reporting standards for synthetic augmentation; establish benchmarks and leaderboards for surgical world models.
- Tools/products/workflows: Documentation checklists (e.g., proportion of synthetic data, generation settings); public benchmarks; review guidelines.
- Assumptions/dependencies: Multi-stakeholder consensus; alignment with privacy laws and medical ethics.
Notes on global dependencies and risks across applications:
- Embodiment specificity: Both the world model and IDM require finetuning for each robot and camera configuration.
- Pseudo-kinematics noise: IDM labels are approximate; human QA and robust training methods (e.g., noise-aware loss) mitigate risks.
- Compute and model licensing: Access to large video models (e.g., Cosmos-Predict2.5) and VLA checkpoints (e.g., GR00T N1.5) and sufficient GPU resources are required.
- Data governance: Use of public surgical videos and synthetic data reduces privacy risk but still requires governance, disclosure, and clinical validation for downstream use.
- Clinical safety and regulation: Any autonomy or clinical decision support must pass rigorous validation and regulatory review before patient use.
Glossary
- 6D rotation formulation: A continuous orientation representation using six parameters to avoid discontinuities and enable smooth interpolation for 3D rotations. "The 6D rotation formulation~\cite{zhou2019continuity} is used to avoid discontinuities and ensure smooth interpolation in by dropping the last column of the rotation matrix."
- Behavior cloning (BC): An imitation learning method that trains policies by supervised learning to directly map observations to actions based on demonstrations. "imitation learning (IL) remains the most direct and scalable approach, typically via behavior cloning (BC)~\cite{pomerleau1989alvinn}"
- Cosmos-Predict2.5: A large-scale video world model that uses diffusion-based latent prediction with transformers to simulate high-fidelity dynamics, adapted here for surgical scenes. "Cosmos-Predict2.5~\cite{nvidia2025worldsimulationvideofoundation} leverages diffusion-based latent video prediction with transformer backbones to simulate high-fidelity spatiotemporal dynamics."
- Covariate shift: A distribution mismatch between training and deployment data (states or observations) that degrades performance of learned policies. "However, BC suffers from covariate shift, producing rapidly worsening performance when the dataset is limited~\cite{ross2011dagger}."
- DIT: A Diffusion Transformer architecture used to predict actions in diffusion-based models. "These two models predict robotic actions with DIT~\cite{peebles2023scalable} and flow matching heads~\cite{lipman2022flow}."
- Diffusion-based latent video prediction: Generating or forecasting future video frames within a compact latent space using diffusion models. "Cosmos-Predict2.5~\cite{nvidia2025worldsimulationvideofoundation} leverages diffusion-based latent video prediction with transformer backbones to simulate high-fidelity spatiotemporal dynamics."
- Domain shift: The discrepancy between simulated or training domains and real-world deployment domains that hinders policy transfer. "Synthetic physics-based simulators~\cite{schmidgall2024surgical,xu2021surrol} attempt to fill the gap, but often suffer from a large visual and dynamic domain shift to real surgical systems and lacking soft body simulation, limiting policy transfer."
- Dynamic Degree (DD): A VBench metric assessing the degree of motion dynamics present in generated videos. "We report FVD and VBench metrics: dynamic degree (DD), imaging quality (IQ), and overall consistency (OC)."
- Endoscopic occlusion: Visual obstruction in minimally invasive surgical video due to instruments or tissue blocking the camera’s view. "these domains lack the unique visual and physical complexity of surgery, where specular tissue surfaces, endoscopic occlusion, and constrained tool motion present distinct modeling challenges."
- Flow Matching (FM): A generative training formulation that matches probability flow fields, used here to train video world models. "We adopt the Flow Matching (FM) formulation~\cite{lipman2022flow} to train the surgical video world model due to its conceptual simplicity and practical effectiveness."
- Fréchet Video Distance (FVD): A quantitative metric that measures the distributional distance between real and generated videos to assess quality. "We report Fréchet Video Distance (FVD)~\cite{unterthiner2019fvd} and follow~\cite{nvidia2025worldsimulationvideofoundation} to report the three representative VBench~\cite{huang2024vbench} metrics."
- GR00T N1.5: A vision–language–action foundation model used as the policy network for robotic control. "We use both real surgical demonstrations with kinematic supervision and synthetic videos labeled with pseudo-actions to train the GR00T N1.5 VLA model~\cite{bjorck2025gr00t}."
- Imaging Quality (IQ): A VBench metric evaluating perceptual image fidelity in generated video frames. "We report FVD and VBench metrics: dynamic degree (DD), imaging quality (IQ), and overall consistency (OC)."
- Imitation learning (IL): A learning paradigm where a policy is trained to mimic expert demonstrations rather than optimizing a reward function. "To train those VLAs, imitation learning (IL) remains the most direct and scalable approach, typically via behavior cloning (BC)~\cite{pomerleau1989alvinn}."
- Inverse dynamics model (IDM): A model that infers the actions (controls) that cause observed state transitions, used here to label synthetic videos with pseudo-actions. "We then employ an inverse dynamics model (IDM) to infer pseudo-kinematics, producing synthetic paired videoâaction data that can be directly used for surgical VLA policy learning."
- Kinematics: The description of motion (positions, orientations, and joint states) without considering forces, used for robot action representation. "surgical robotics suffers from the paucity of datasets that include both visual observations and accurate robot kinematics."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning technique inserting low-rank adapters into transformer layers to specialize large models. "We adopt Low-Rank Adaptation (LoRA)~\cite{hu2022lora} to efficiently specialize Cosmos-Predict2.5~\cite{nvidia2025worldsimulationvideofoundation} for the surgical domain while preserving its general video modeling capabilities."
- Overall Consistency (OC): A VBench metric assessing temporal and semantic consistency across generated video sequences. "We report FVD and VBench metrics: dynamic degree (DD), imaging quality (IQ), and overall consistency (OC)."
- Pseudo-kinematics: Approximate or inferred robot motion parameters derived from video, not directly measured from sensors. "We then employ an inverse dynamics model (IDM) to infer pseudo-kinematics, producing synthetic paired videoâaction data that can be directly used for surgical VLA policy learning."
- SATA (Surgical ActionâText Alignment) dataset: A curated dataset of expert-annotated surgical video clips with detailed action descriptions for training physical AI models. "We introduce SATA, a large-scale surgical actionâtext alignment dataset comprising 2,447 expert-annotated video clips (over 300k frames) collected across 8 different surgery types."
- SO(3): The mathematical group of 3D rotations; ensuring continuity in rotation representations avoids artifacts in orientation interpolation. "The 6D rotation formulation~\cite{zhou2019continuity} is used to avoid discontinuities and ensure smooth interpolation in by dropping the last column of the rotation matrix."
- Spatiotemporal encoder: A network module that jointly encodes spatial and temporal information from video frames for downstream prediction. "A spatiotemporal encoder extracts features from , a transformer-based latent dynamics module models temporal evolution, and a decoder reconstructs the predicted frames."
- Spatiotemporal transformer: A transformer architecture modeling dependencies across space and time, tailored here for surgical video synthesis. "Endora~\cite{li2024endora} integrates a spatiotemporal transformer with a latent diffusion backbone for endoscopic video synthesis."
- Teleoperation: Human-controlled operation of a robot from a distance, often via specialized interfaces. "Its large-scale pretraining on heterogeneous robotic and human teleoperation videos provides strong priors for object interactions, tool motion, and scene dynamics"
- VBench: A benchmark suite providing standardized metrics for assessing video generation quality and dynamics. "We report Fréchet Video Distance (FVD)~\cite{unterthiner2019fvd} and follow~\cite{nvidia2025worldsimulationvideofoundation} to report the three representative VBench~\cite{huang2024vbench} metrics."
- VisionâLanguageâAction (VLA) model: A multimodal model that conditions robot actions on visual inputs and language instructions. "Large-scale visionâlanguageâaction (VLA) models have recently emerged as a powerful paradigm for general-purpose robotic policy learning."
- World model: A learned generative model of environment dynamics that predicts future states or video rollouts from current observations. "we aim to alleviate this problem by learning policy models from SurgWorld, a world model designed for surgical physical AI."
Collections
Sign up for free to add this paper to one or more collections.