Parallel-SFT: Improving Zero-Shot Cross-Programming-Language Transfer for Code RL
Abstract: Modern LLMs demonstrate impressive coding capabilities in common programming languages (PLs), such as C++ and Python, but their performance in lower-resource PLs is often limited by training data availability. In principle, however, most programming skills are universal across PLs, so the capability acquired in one PL should transfer to others. In this work, we propose the task of zero-shot cross-programming-language transfer for code RL. We find that, for Llama-3.1, RL training for code generation in a source PL fails to improve, and sometimes even degrades, the performance on other target PLs. To address this, we hypothesize that effective RL transfer requires a generalizable SFT initialization before RL. We thus propose Parallel-SFT, an SFT strategy that incorporates "parallel programs" -- functionally equivalent code implemented in multiple PLs -- into the data mixture. We demonstrate that this improves transferability: when we subsequently perform RL on our Parallel-SFT model, we observe better generalization to unseen PLs. Analysis of the model internal representations reveals that Parallel-SFT leads to a more functionality-centric latent space, where equivalent programs across PLs are more tightly clustered, which we hypothesize to contribute to the improved transferability.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper looks at how AI coding models can learn in one programming language and still do well in another, without extra training. The authors find that today’s models often don’t transfer well across languages during reinforcement learning (RL), a training step where models “practice” by getting rewards for correct answers. They propose a simple idea called Parallel-SFT: before doing RL, give the model lots of side‑by‑side, functionally identical code examples in different languages (like the same recipe written in Python, C++, Java, etc.). This helps the model focus on the meaning and logic of code, not just the exact words and symbols of one language.
Key questions the paper asks
- Can a model that is trained (with RL) to solve coding tasks in one language (like Python) perform well in another language (like Go) without additional training?
- Why do current models struggle to transfer learning across programming languages?
- Does pretraining the model with “parallel” code examples (same solution, different languages) help it transfer what it learned to new languages?
- Will this approach still work on different kinds of coding tasks, like both writing code and judging if code is correct?
How they did it (methods in simple terms)
First, here are the main pieces in everyday language:
- Supervised fine-tuning (SFT): Think of this like a teacher showing many example problems and correct solutions. The model copies and learns patterns from these.
- Reinforcement learning (RL): This is “practice with feedback.” The model tries to solve a problem; if it passes tests, it gets a reward and learns to do better next time.
- Zero-shot transfer: The model is tested in a new language it didn’t see during training on that task, with no extra practice.
What they tried:
- Two tasks:
- Code generation: The model writes a program from a text description; it “passes” if the code passes all tests.
- Code validation: The model judges if a given piece of code correctly solves a problem (yes/no).
- Testing transfer across languages:
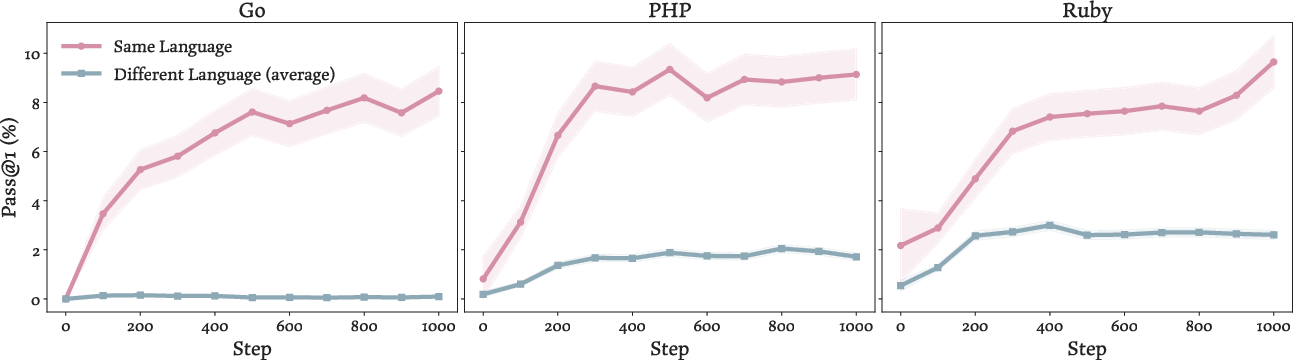
- They trained with RL in a “source” language (like Python or C++) and tested in “target” languages (Go, PHP, Ruby) without extra training.
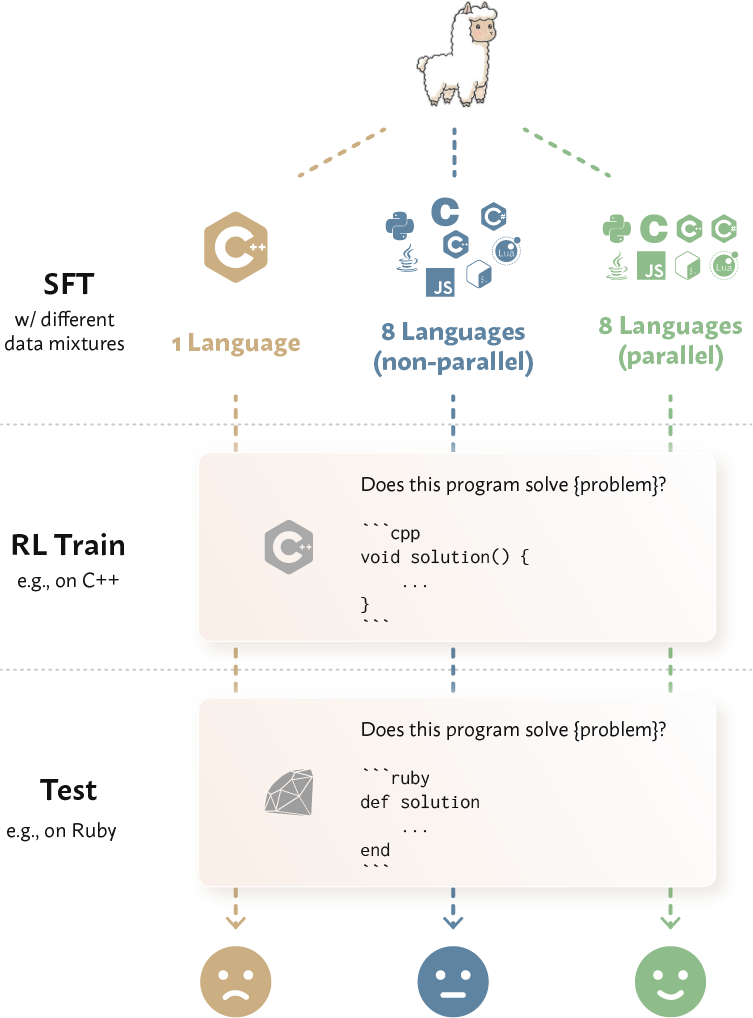
- Parallel-SFT (their idea):
- Before RL, they build an SFT dataset where the same problem and solution is provided in multiple languages (e.g., Python, C, C++, Java, C#, JavaScript, Bash, Lua).
- They created these “parallel programs” by translating verified Python solutions into other languages using a strong translator model, then kept only translations that still pass all tests. This ensures the versions really do the same thing.
- They tested three SFT setups (same total size):
- 1 Language (source): only code in the source language.
- 8 Languages (non-parallel): many languages, but each problem appears in just one language (no side-by-side pairs).
- 8 Languages (parallel): many languages, and each problem appears in all of them (side-by-side pairs).
- They also compared to an “oracle”: training directly in the target language with its own data (the usual best-case scenario).
- Measuring results:
- For code generation: pass@k (e.g., pass@1), meaning the fraction of problems solved when sampling k attempts.
- For code validation: accuracy (correct yes/no judgments).
- They also analyzed the model’s internal “representations” to see if code that means the same thing in different languages looks similar inside the model.
Main findings and why they matter
- Naive cross-language transfer during RL often fails:
- Training with RL in one language (like Python) typically helps in that language but doesn’t reliably help in another (like Go). Sometimes it even hurts performance.
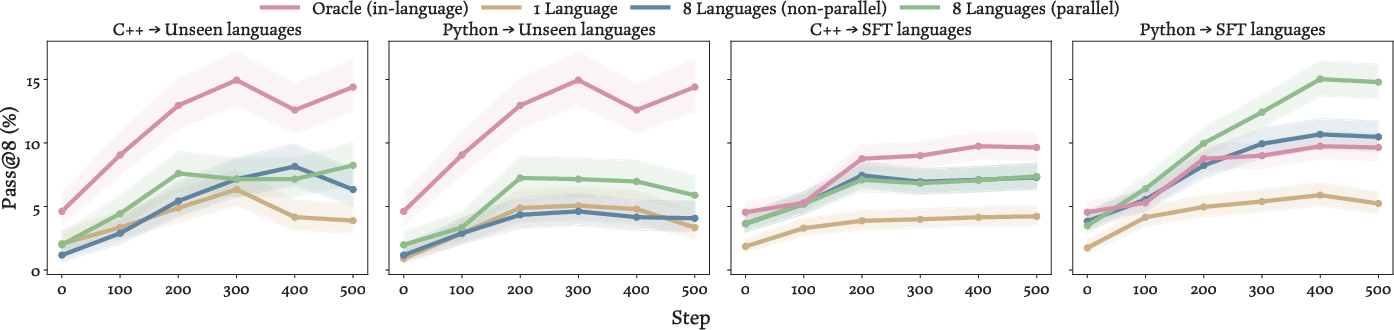
- Parallel-SFT makes RL improvements transfer better:
- Training the model first with parallel code examples across multiple languages makes later RL gains in the source language carry over to new languages.
- Even just seeing multiple languages (non-parallel) helps some, but parallel examples help more.
- In some cases, Parallel-SFT plus RL in a high-resource language (like Python) beats training directly in the target language—better than the “oracle.” That suggests learning on clearer, richer data in one language can transfer to others if the model is properly aligned.
- It works across tasks:
- The benefits show up in both code generation and code validation.
- Code validation is especially important in practice because the input code is language-specific, so transfer really matters.
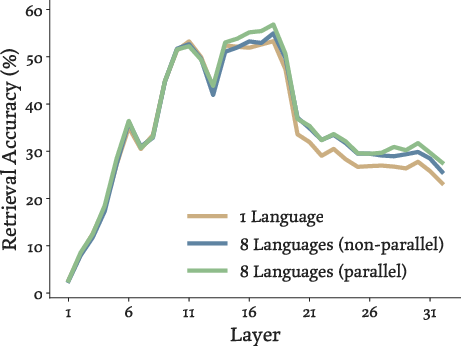
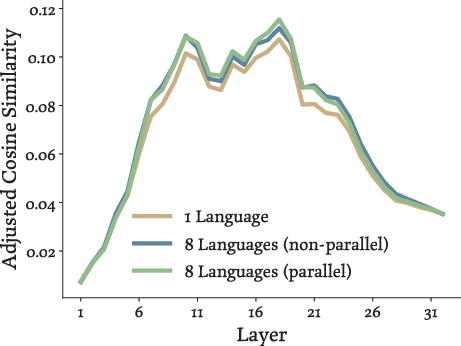
- Better “semantic” understanding inside the model:
- When they looked at the model’s internal representations, code that solved the same problem in different languages became more similar after Parallel-SFT.
- This alignment was strongest in the “middle” layers of the model, which is where models usually capture meaning and logic (rather than surface details like punctuation or language-specific keywords).
Why this matters:
- Many programming languages have less training data (they’re “low-resource”). With Parallel-SFT, a model can learn a lot in a popular language and still perform well in less popular ones.
- It could make coding assistants more reliable across different ecosystems without needing huge amounts of per-language data.
- The idea mirrors what works in multilingual natural language processing (using translations to align meanings), but adapts it to code with “functionally equivalent” programs.
What this could lead to (implications)
- More universal code models: Models that understand the logic of programs, not just the syntax of one language, can help developers switch stacks more easily.
- Better training efficiency: Teams could focus RL training on a high-quality, well-supported language and still get strong performance in others, saving time and resources.
- Stronger tools for code agents and search: More “meaning-aware” code representations can improve code retrieval, bug detection, and automated code review across languages.
- Future directions: The same idea—aligning “meanings” across different forms—could help models generalize across other domains too (like natural languages, different tasks, or even different problem settings).
In short, Parallel-SFT is like teaching an AI the same lesson in multiple languages, side by side, so it learns the core idea instead of just the words. This simple step makes its later practice (RL) much more portable across programming languages.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions the paper leaves unresolved. These items are intended to guide actionable follow-up research.
- Limited PL coverage and typological diversity: results use two source PLs (Python, C++) and three unseen target PLs (Go, PHP, Ruby). It remains unclear whether Parallel-SFT holds for languages with very different paradigms (e.g., Haskell, OCaml, Lisp, Prolog), memory models (Rust), or platform-specific ecosystems (Swift, Kotlin).
- Sensitivity to language selection and typological distance: the paper does not quantify how transfer varies with PL “distance” (e.g., static vs. dynamic typing, OOP vs. functional, tooling model). An explicit typology-aware study and ablation is missing.
- Scaling to larger or different model families: all experiments use Llama-3.1-8B. It is unknown whether gains persist or change for larger/smaller models, other architectures (e.g., Qwen, CodeLlama variants), or MoE models.
- Effect of pretraining vs. post-training: Parallel-SFT is inserted at SFT, not pretraining. It is unknown whether parallel signals at pretraining (or joint pretrain+SFT) yield larger or different gains.
- Amount of parallel data required: no scaling law or data-efficiency curve is given for parallel pairs (e.g., number of PLs, number of parallel solutions per problem). The minimal effective budget and diminishing returns are unknown.
- Mixing ratios and curriculum: the method uses a fixed 142k coding instances and uniform per-language sampling. Optimal mixing ratios, curricula (e.g., start with fewer PLs, then expand), or scheduling strategies remain unexplored.
- Parallel vs. non-parallel ablation granularity: the paper contrasts fully parallel and fully disjoint multi-PL mixtures, but does not probe partial parallelism (e.g., only a subset of questions parallelized) or the relative importance of “identical instructions” vs. “functional equivalence.”
- Role of stylistic alignment: prompts ask translations to follow stylistic aspects. It is unclear whether functional equivalence alone suffices, or whether stylistic similarities (naming conventions, comment density) materially drive representation alignment.
- Test coverage limitations in synthetic translation: functional equivalence is validated by test suites that may be incomplete. The rate of false positives (programs that pass provided tests but are semantically non-equivalent) and its effect on learned alignment is unknown.
- Translation bias and domain skew: parallel programs are sourced via Llama-4 translations filtered by test pass. This likely biases the SFT set toward “simpler/easier-to-translate” instances; how this affects generalization is unquantified.
- Reuse and duplication effects: the dataset averages 181 solutions per question per language. The impact of heavy duplication per question on overfitting, memorization, and the learned alignment signal is not analyzed.
- Transfer to tasks beyond two settings: only code generation and code validation are tested. Generalization to bug fixing, code repair, refactoring, code search, doc generation, type inference, or repository-level tasks remains unverified.
- Practicality for code generation: authors note zero-shot cross-PL RL for generation is mainly scientific because tests are PL-agnostic. Empirical gains in genuinely PL-bound generation scenarios (e.g., language-specific libraries, frameworks, IO models) are untested.
- RL algorithms and reward design: only GRPO with binary verifier rewards is used. It is unknown if results hold under alternative RL methods (e.g., PPO, RLOO, VPG), reward shaping, or learned reward models for unverifiable tasks.
- Source-only RL vs. multi-PL RL: the study trains RL only in a single source PL. Whether performing RL across multiple PLs (including parallel RL data) further improves transfer—and how it compares to Parallel-SFT alone—is not explored.
- Post-RL representation alignment: the analysis measures representation similarity after SFT, not after RL. How RL updates reshape cross-PL alignment—and whether Parallel-SFT preserves/improves alignment through RL—is open.
- Causes of “surpassing oracle” effect: Parallel-SFT occasionally beats target-language oracle training. The conjecture (source high-resource advantages) is untested; controlled ablations (e.g., quality/quantity of target PL data, RL stability, regularization) are needed.
- Impact on in-language performance across PLs: only a single in-language check (Python, pass@1) is reported. Whether Parallel-SFT consistently avoids in-language regressions across PLs and tasks is unresolved.
- Tokenization and vocabulary effects: no analysis of whether tokenization differences across PLs (e.g., subword splits on symbols, identifiers) influence alignment and transfer under Parallel-SFT.
- Prompt/template sensitivity: transfer could depend on prompting conventions and execution harness templates (e.g., language tags, boilerplate). Sensitivity analyses for prompts and evaluation harnesses are missing.
- Execution/toolchain variability: RL relies on compiling/executing across PLs with different toolchains. The effect of environment variance (compiler versions, runtime flags) on measured transfer is not examined.
- Domain shift beyond APPS/CodeContests and CodeForces: SFT and RL operate on specific academic-style datasets. Transfer to real-world repositories, industry codebases, or code with heavy library dependencies remains untested.
- Error and failure-mode analysis: the paper does not categorize where transfer fails or succeeds (e.g., recursion, pointer/struct handling, floating point, concurrency, I/O differences). Fine-grained diagnostics are absent.
- Generalization to extremely low-resource PLs: two of the training PLs (Bash, Lua) are excluded from certain evaluations due to RL data scarcity. The viability of Parallel-SFT in truly low-data, unseen PLs remains unclear.
- Comparison to structure-centric baselines: the work discusses AST/IR methods but does not present empirical head-to-head comparisons with models that explicitly leverage ASTs or IRs for alignment.
- Cross-lingual instruction variability: Parallel-SFT uses near-identical natural language instructions across PLs. Whether alignment persists when instructions are paraphrased or independently authored per PL is unknown.
- Security and quality beyond pass rates: no assessment of runtime performance, resource usage, or security properties (e.g., unsafe patterns) of generated/validated code across PLs.
- Data and artifact release: reproducibility would benefit from releasing the synthetic parallel dataset and training scripts; the paper does not specify availability.
- Cost-benefit analysis: the compute and engineering cost to build multi-PL parallel SFT at scale (toolchains, translation, verification) versus the realized gains is not quantified.
- Long-term stability and catastrophic forgetting: multiple post-training stages (SFT, RL) can interact. Whether Parallel-SFT makes models more/less robust to later training stages (e.g., instruction tuning, preference optimization) is unstudied.
- Interaction with multilingual natural language data: the effect of adding parallel code on broader NL tasks (e.g., instruction following in non-English) or cross-L transfer in NL remains unmeasured.
- Robustness to identifier obfuscation: whether alignment holds when variable/function names are obfuscated (to remove lexical cues) is not tested, leaving open whether models rely on superficial token overlaps.
Practical Applications
Below is an overview of practical, real-world applications implied by the paper’s findings and methods. Each item notes target sectors, plausible tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Cross-programming-language code validation (reward models) for RL and CI
- Sectors: software, finance, healthcare, robotics/embedded
- Tool/workflow: Drop-in, language-agnostic correctness evaluators trained via Parallel-SFT that score candidate solutions without language-specific test harnesses; usable as RL rewards and as CI pre-merge checks
- Assumptions/dependencies: Availability of verified parallel SFT data; reliable extraction of boolean correctness; compilers/runtimes for supported languages; tasks resemble algorithmic problems with executable tests
- Enterprise training recipe to boost support for low-/mid-resource PLs
- Sectors: software platforms, cloud/AI providers, enterprise ML teams
- Tool/workflow: Augment existing SFT mixtures with Parallel-SFT (synthetic, test-verified parallel programs) and conduct RL in a high-resource PL while deploying to others
- Assumptions/dependencies: Sufficient compute; access to high-quality translation models or services; licensing for source problem sets; evaluation infrastructure across target PLs
- Polyglot IDE assistants with stronger Go/PHP/Ruby support
- Sectors: software development, education
- Tool/workflow: VS Code/JetBrains extensions backed by Parallel-SFT-initialized models for code completion, refactoring, and “rewrite in X” that generalizes from Python/C++ to less-common PLs
- Assumptions/dependencies: Model deployment within IDE; robust per-language runtimes for verification; alignment holds beyond algorithmic tasks into framework-heavy code
- Code porting/migration with verification
- Sectors: IT modernization, enterprise software
- Tool/workflow: “Translate-and-verify” pipelines that generate target-language implementations and validate functional equivalence via tests or LLM-based validators
- Assumptions/dependencies: Existence or synthesis of test suites; library/API mapping fidelity; access to both language toolchains; translations filtered by execution tests
- Multi-PL auto-graders and online judges
- Sectors: education (MOOCs, universities, bootcamps)
- Tool/workflow: Graders that accept submissions in many PLs using Parallel-SFT-trained validators; reduce per-language rubric engineering
- Assumptions/dependencies: Curated problem sets and tests; fairness controls across PLs; anti-plagiarism safeguards
- Cross-PL code search and retrieval
- Sectors: software, open-source ecosystem
- Tool/workflow: Embedding indices (e.g., echo embeddings from the paper) aligned across languages to find functionally similar snippets in other PLs
- Assumptions/dependencies: Scalable indexing and deduping; license-aware retrieval; embedding alignment remains robust for larger, real-world codebases
- CI/CD checks for polyglot repos
- Sectors: DevOps, platform engineering
- Tool/workflow: Pre-merge validation that mirrored implementations (e.g., Python + Go) remain semantically consistent using cross-PL validators; gates for refactors/ports
- Assumptions/dependencies: Availability of mirrored modules/specs; integration with existing CI; stable pass@k thresholds for acceptance
- Security pattern transfer across PLs
- Sectors: application security, compliance
- Tool/workflow: Train detectors or validators in a high-resource PL and apply to others for vulnerability pattern recognition (e.g., input sanitization, auth flows)
- Assumptions/dependencies: Quality ground-truth vulnerabilities; managing false positives across different idioms; domain shift beyond algorithmic code
Long-Term Applications
- Cross-PL autonomous coding agents
- Sectors: software, DevOps, multi-agent systems
- Tool/workflow: Agents that plan, implement, port, and maintain modules across languages, leveraging Parallel-SFT initialization for language-agnostic reasoning
- Assumptions/dependencies: More capable planning/reasoning models; stronger evaluation benchmarks; safety and governance frameworks for autonomous changes
- Automated legacy modernization at scale
- Sectors: government, finance, telecom, industrial systems
- Tool/workflow: End-to-end COBOL/Fortran→modern language migration with semantic verification and staged RL improvements
- Assumptions/dependencies: Reliable test synthesis for legacy systems; accurate API/data-model mappings; acceptance criteria and auditing
- DSL and domain-language generalization (e.g., smart contracts, medical DSLs, SQL dialects)
- Sectors: healthcare, finance, Web3, data engineering
- Tool/workflow: Parallel-SFT built from functionally equivalent programs across DSLs, enabling cross-language generation/validation for safety-critical code
- Assumptions/dependencies: Executors/compilers and tests for DSLs; robust alignment of domain semantics; curated parallel datasets
- Cross-PL governance and certification standards
- Sectors: policy/regulation, enterprise risk, procurement
- Tool/workflow: Standardized benchmarks and certification that AI coding tools demonstrate cross-language correctness and fairness for low-resource PLs
- Assumptions/dependencies: Community-agreed datasets of parallel programs; independent auditors; reproducibility and contamination controls
- Compiler/IR–aware learning stacks
- Sectors: programming languages, tooling vendors
- Tool/workflow: Combine Parallel-SFT with AST/IR signals to further align semantics and support more diverse paradigms (functional, reactive, async)
- Assumptions/dependencies: Integration with parsers/compilers; scalable data pipelines; empirical validation that IR signals compound gains
- Cost- and energy-efficient training for vendors
- Sectors: foundation model providers, cloud AI
- Tool/workflow: Train on a few high-resource PLs plus Parallel-SFT to cover many PLs, reducing separate per-language finetunes and energy use
- Assumptions/dependencies: Demonstrated scaling to larger models and broader tasks; MLOps to maintain mixed-language SFT datasets
- Multi-language microservices orchestration and conformance
- Sectors: SaaS, enterprise platforms
- Tool/workflow: Agents or linters that ensure interface and behavioral consistency across services implemented in different languages
- Assumptions/dependencies: High-quality API specs; contract/integration tests; production observability hooks for validation
- Sector-specific safety and compliance tooling
- Sectors: healthcare (EHR/data pipelines), finance (risk/ops), robotics/embedded
- Tool/workflow: Cross-PL validators for safety-critical logic (e.g., dosage calculations, pricing engines, control loops), trained in a reliable PL and applied to deployment PLs
- Assumptions/dependencies: Formalized requirements and gold tests; regulatory acceptance of AI-assisted verification; strict logging and audit trails
Cross-Cutting Assumptions and Constraints
- Data and verification: The method hinges on high-quality, test-verified parallel programs; practical coverage of real-world libraries/frameworks may require richer tests and domain-specific scaffolding.
- Model and compute: Demonstrated on an 8B LLM and algorithmic tasks; generalization to larger codebases and complex frameworks needs further validation and likely more compute.
- Translation quality and licenses: Synthetic translations must be filtered by execution tests; ensure dataset licensing and IP compliance.
- Task scope: Results are strongest on problems with clear functional specifications and stdin/stdout tests; extension to UI-driven, event-driven, or framework-heavy tasks requires additional instrumentation.
- Toolchain availability: Feasibility depends on compilers/runtimes across target PLs and stable execution environments in training and evaluation.
Glossary
- Abstract Syntax Trees (AST): A tree-structured, language-agnostic representation of program syntax used to analyze or transform code. "language-agnostic intermediate forms such as Abstract Syntax Trees~\citepia{guo-etal-2022-unixcoder,chen-etal-2023-pass,gong2024astt}"
- Adjusted cosine similarity: A similarity metric corrected for representation-space bias by subtracting non-parallel pair similarity. "Adjusted cosine similarity. Following \citet{wu2025the}, we correct for baseline anisotropy by subtracting the cosine similarities between non-parallel pairs."
- Anisotropy: The tendency of high-dimensional embeddings to occupy a narrow cone, making naive cosine comparisons misleading. "It, however, can be misleading due to the anisotropy of the representation space~\citep{ethayarajh-2019-contextual}."
- Code RL: Reinforcement learning applied to code tasks (e.g., generation, validation) with execution-based rewards. "We propose zero-shot cross-PL transfer for code RL, where we perform RL training and testing on different PLs."
- Code validation: A task where a model judges if a given program solves a specified problem. "In code validation, the model takes as input a tuple containing a question and a candidate code solution, and it outputs whether is correct, i.e., whether solves ."
- Competition-level code generation: Generating solutions to difficult, Olympiad-style programming problems. "We consider the task of competition-level code generation and use the CodeForces dataset for training and evaluation~\citep{penedo2025codeforces}."
- Cross-PL transfer: Transferring learning or performance across programming languages. "cross-PL transfer from a different source language leads to limited improvements or even performance degradation."
- Direct Preference Optimization (DPO): A preference-based post-training method that optimizes models using pairwise human or synthetic preferences. "It is not an SFT model, which typically precedes the RL stage, but it has also gone through preference tuning with DPO."
- Echo embedding: An embedding technique that repeats input to let autoregressive models attend to future tokens for better sequence representations. "We compute the program representations via echo embedding~\citep{springer2025repetition} that repeats the program twice in a lightweight template which empirically produces strong sequence representations."
- Execution equivalence: The property that two programs produce identical behavior across all inputs. "Parallel-SFT semantically grounds programs with execution equivalence."
- GRPO: A reinforcement learning algorithm variant used to update policy models from verifier feedback. "This binary signal is used to update the policy using RL algorithms such as GRPO~\citep{shao2024deepseekmathpushinglimitsmathematical}."
- In-context learning: Performing tasks by conditioning on prompts/examples at inference, without updating model weights. "investigated cross-PL code generation in modern LLMs via in-context learning, but found that cross-PL transfer often underperforms zero-shot prompting."
- Incidental bilingualism: Naturally occurring parallel text segments within documents that aid cross-lingual alignment. "First, natural language corpora benefit from “incidental bilingualism,” where a single document contains parallel text."
- Intermediate Representations (IR): Compiler-like, language-agnostic forms that normalize program semantics for analysis or generation. "and Intermediate Representations~\citep{10123512,szafraniec2023code,paul-etal-2024-ircoder}."
- Language-general representations: Shared latent features that capture semantics across different natural or programming languages. "successful LM generalizability between natural languages is often attributed to language-general representations, where multilingual models develop representations that capture the underlying semantics of texts"
- Meta-learning: A training paradigm where learning across tasks improves the ability to rapidly adapt to new tasks. "posited multi-task training as a form of meta-learning that facilitates better downstream adaptation~\citep{wang2021bridging}."
- Mixture-of-expert model: An architecture that routes inputs to specialized expert subnetworks to improve scalability and capacity. "by prompting Llama-4-Maverick, a 400B-parameter mixture-of-expert model~\citep{meta2025llama4}."
- Negative transfer: When transfer across domains/languages hurts performance instead of helping. "transferring from another source language leads to limited, or sometimes degraded effects (negative transfer)."
- Oracle (in-language oracle): A baseline that assumes abundant target-language data and training, representing an upper-bound scenario. "Remarkably, when Python is the source PL, Parallel-SFT not only outperforms the baselines but even the in-language oracle."
- pass@k: A code-generation metric measuring whether any of k sampled solutions passes all tests. "Performance is typically measured using the pass@ metric: for each question, the model samples solutions, and the instance is considered solved if at least one sample passes all tests."
- Parallel programs: Functionally equivalent implementations of the same solution across different programming languages. "which incorporates synthetically generated “parallel programs”—functionally-equivalent programs across PLs—into the SFT data mixture"
- Parallel texts: Aligned sentences/documents in different languages (e.g., translations) used to align multilingual models. "Past work on multilingual NLP has attributed multilingual capabilities to organic parallel texts (i.e., translations) in pretraining corpora."
- Parallel-SFT: An SFT approach that trains on aligned multi-language code solutions to align representations across languages. "We propose Parallel-SFT, which incorporates synthetically generated “parallel programs”—functionally-equivalent programs across PLs—into the SFT data mixture (Figure~\ref{fig:overview})."
- Policy (policy model): The model that maps inputs to actions/outputs and is optimized during RL. "During training, the policy model samples a response, which is scored by the verifier."
- Policy optimization: Algorithms and stages that improve the policy (e.g., RL, preference-based tuning). "it is common for current LMs to undergo multiple stages of policy optimization~\citepia{qwen3,bercovich2025llamanemotronefficientreasoningmodels}."
- Preference tuning: Post-training that optimizes models to preferred outputs via human or synthetic comparisons. "but it has also gone through preference tuning with DPO."
- Representation space alignment: Making embeddings of semantically equivalent items (across languages) close in the shared representation space. "we hypothesize that Parallel-SFT aligns the PL representation space, leading to more semantic code representations."
- Retrieval accuracy: A metric that checks whether true parallel pairs are closest in embedding space compared to non-parallel pairs. "Retrieval accuracy measures whether a program and its translation have closer representations than all other non-corresponding programs~\citepia{artetxe-schwenk-2019-massively,feng-etal-2022-language,shen-etal-2025-unaligned}."
- Reward model: A learned model that scores outputs when direct verification is unavailable. "Or a reward model for non-verifiable tasks, which we do not consider."
- Structural isomorphism: The structural similarity across languages’ distributions that can enable unsupervised alignment. "This success is typically driven by two factors: structural isomorphism and explicit alignment signals."
- Supervised finetuning (SFT): Post-pretraining stage where models learn from input–output pairs to follow instructions or solve tasks. "the model undergoes SFT on a dataset of instruction and ground-truth response pairs"
- Translate-train: Training on target-language data obtained by translating source-language examples. "a practice termed “translate-train” in the multilingual NLP nomenclature~\citep{conneau-etal-2018-xnli}."
- Verifier: An automatic checker that evaluates outputs (e.g., via execution or extraction) to provide reward signals. "and the verifier extracts the boolean prediction from the code solution and compares it against the ground truth."
- Zero-shot cross-lingual transfer: Finetuning on one language and evaluating on another without target-language task data. "Zero-shot cross-lingual transfer is a core paradigm in multilingual NLP."
- Zero-shot cross-programming-language transfer: Training on one programming language and evaluating on another without target-language task data. "We define the task of zero-shot cross-programming-language transfer, optimizing a task policy via RL in a source PL and zero-shot evaluating its performance on another target PL."
Collections
Sign up for free to add this paper to one or more collections.

