Convergent Evolution: How Different Language Models Learn Similar Number Representations
Abstract: LLMs trained on natural text learn to represent numbers using periodic features with dominant periods at $T=2, 5, 10$. In this paper, we identify a two-tiered hierarchy of these features: while Transformers, Linear RNNs, LSTMs, and classical word embeddings trained in different ways all learn features that have period-$T$ spikes in the Fourier domain, only some learn geometrically separable features that can be used to linearly classify a number mod-$T$. To explain this incongruity, we prove that Fourier domain sparsity is necessary but not sufficient for mod-$T$ geometric separability. Empirically, we investigate when model training yields geometrically separable features, finding that the data, architecture, optimizer, and tokenizer all play key roles. In particular, we identify two different routes through which models can acquire geometrically separable features: they can learn them from complementary co-occurrence signals in general language data, including text-number co-occurrence and cross-number interaction, or from multi-token (but not single-token) addition problems. Overall, our results highlight the phenomenon of convergent evolution in feature learning: A diverse range of models learn similar features from different training signals.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple question: when computers learn language, how do they learn about numbers? The authors find that many different kinds of LLMs, trained in different ways, end up representing numbers with repeating patterns tied to our base‑10 number system. Even more interesting, they show there are two levels of this “convergent evolution”:
- Spectral convergence: models show clear repeating (periodic) patterns for numbers (like rhythms in music), especially with periods 2, 5, and 10.
- Geometric convergence: models organize number meanings so cleanly that a simple tool can tell, just from a number’s internal representation, what its remainder is when divided by 2, 5, or 10 (that’s “mod T”).
They prove that the first level (seeing the patterns) doesn’t guarantee the second (organizing them so they’re easy to use). Then they test what data, model designs, training choices, and tokenization make the second level happen.
What questions did the authors want to answer?
In plain terms:
- Do different kinds of LLMs learn the same repeating patterns for numbers?
- Do those patterns mean the model actually understands useful number properties, like whether a number is even or what it is mod 10?
- What makes this happen: the data, the model type, the training method, or how we split numbers into tokens (tokenization)?
- If we train only on arithmetic (like addition), do the same patterns and usable structures appear?
How did they study this?
To keep things simple, here’s what their tools and tests mean:
What is a “number embedding”?
Think of each number (like “37”) getting turned into a small vector—a list of numbers—that the model uses internally, like a compact “ID card” for that token. That ID card is called an embedding.
What is a “Fourier spike” and “period T”?
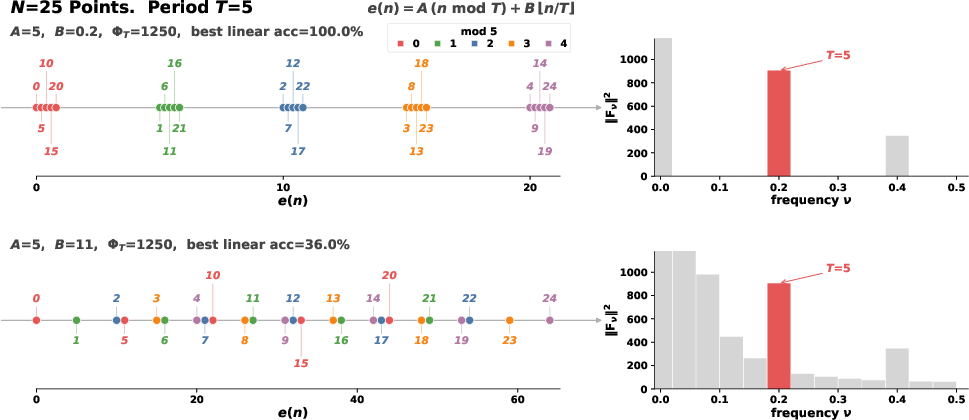
- Imagine lining up number embeddings from 0 to 999 and “listening” for rhythms in how those vectors change (like using a music analyzer). The “Fourier transform” is that analyzer: it finds repeating patterns.
- A “spike at period T” means a strong, repeated pattern every T numbers. For example:
- T = 2: the model picks up the even/odd rhythm.
- T = 5 or T = 10: patterns tied to base‑10 digits and how we write and talk about numbers.
What does “mod T” mean?
“Mod T” means the remainder after dividing by T. For T = 10, the remainder is the last digit. For T = 2, it’s whether the number is even or odd.
What is a “linear probe”?
A very simple classifier (like drawing straight lines to separate groups) that tries to read a property (like “what’s this number mod 10?”) from the embeddings. If a linear probe succeeds, it means the concept is cleanly and simply organized inside the model.
What experiments did they run?
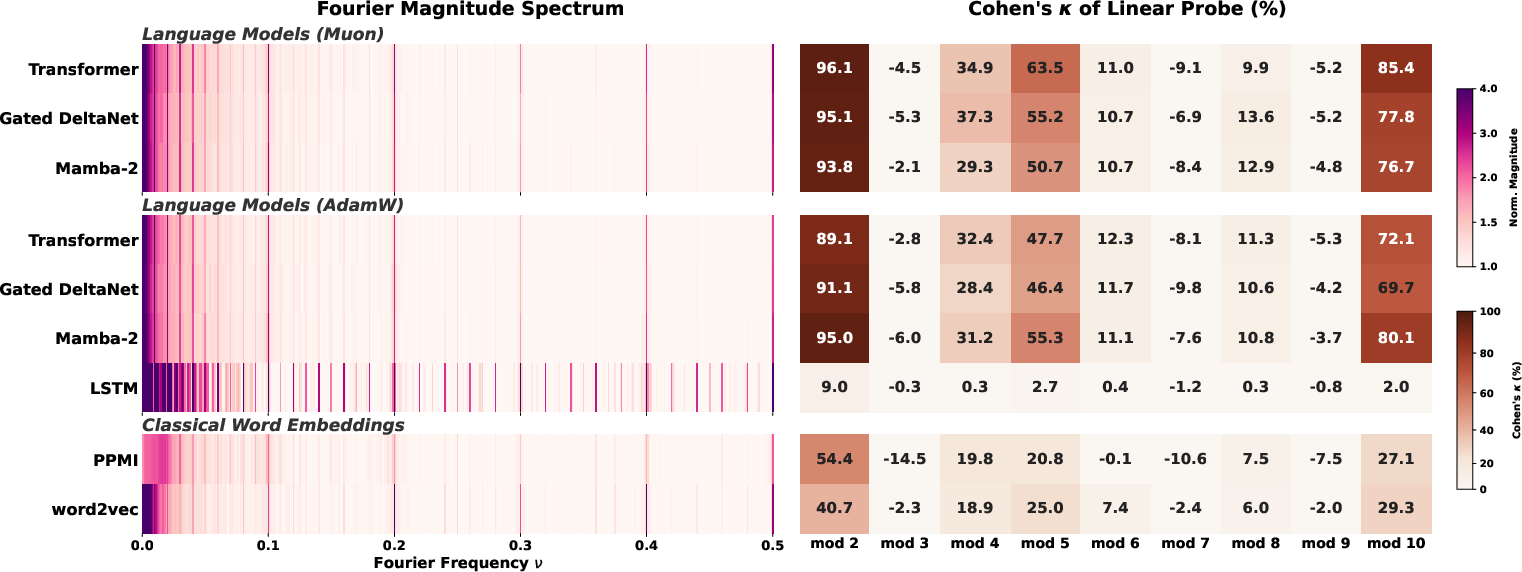
- They checked many model types: Transformers, modern RNNs (like Mamba, Gated DeltaNet), classic LSTMs, and even older methods like word2vec and GloVe.
- They changed the training data in controlled ways to remove specific signals (for example, keeping number frequencies but shuffling which numbers appear with which words).
- They switched optimizers (ways of updating a model during training) like AdamW and Muon.
- They compared normal language pretraining with training only on addition.
- They tested different tokenizations: numbers as single tokens (like “472”) vs. multi-token numbers (splitting long numbers into chunks), which affects what subproblems the model must solve.
What did they find, and why is it important?
Here are the main results, explained simply:
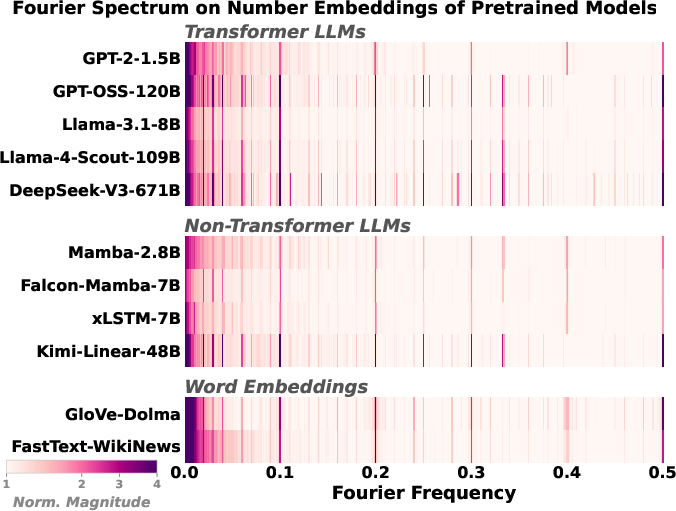
- Many systems show the same repeating patterns (spectral convergence).
- Transformers, newer RNNs, old word embeddings—and even just the raw frequency of numbers in text—all have strong “music-like” spikes at periods 2, 5, and 10.
- This happens because of how numbers appear in natural language and because we use base 10. It’s like different species independently evolving eyes because they all live in places where seeing is useful.
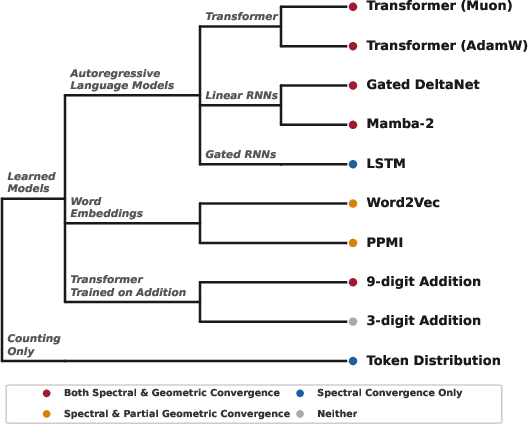
- But seeing patterns isn’t the same as organizing them for use (geometric convergence).
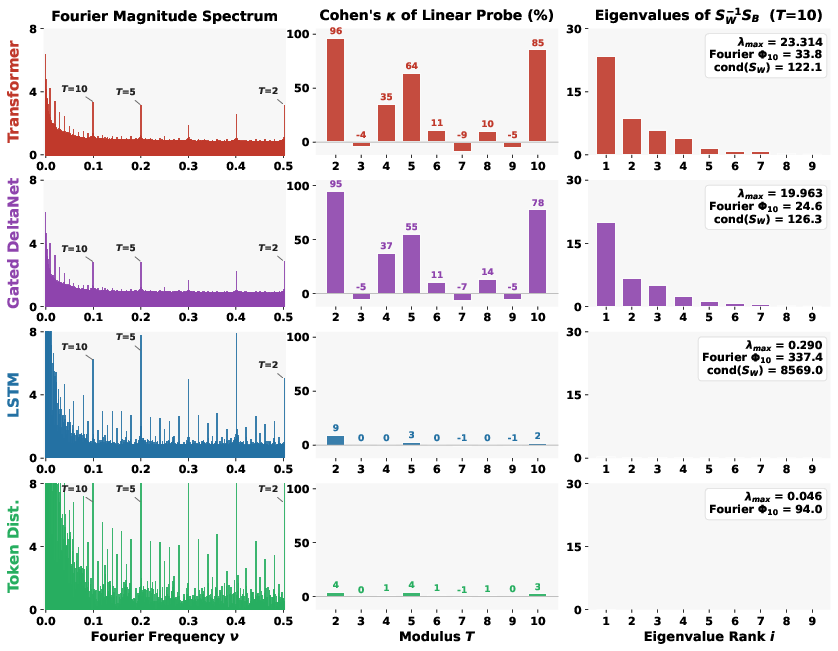
- Some models (Transformers, linear-style RNNs) organize number embeddings so well that a simple linear probe can read mod‑2, mod‑5, or mod‑10.
- Other models (notably LSTMs) can have even bigger Fourier spikes but still fail at simple mod‑T classification. In other words: the rhythm is there, but it’s buried under messy noise that makes it unusable by simple tools.
- They proved why spikes don’t guarantee usable structure.
- In math terms: having big periodic power (the spikes) is necessary but not sufficient for clean, linearly separable classes. If the “within-class noise” is large in the wrong directions, the classes overlap and simple classifiers can’t separate them.
- Intuition: Imagine you sort marbles into 10 bins (for mod‑10), but then you shake the table so much that marbles from different bins spill into each other. A noise-sensitive setup can hide the structure even if it exists on average.
- What determines whether usable structure emerges?
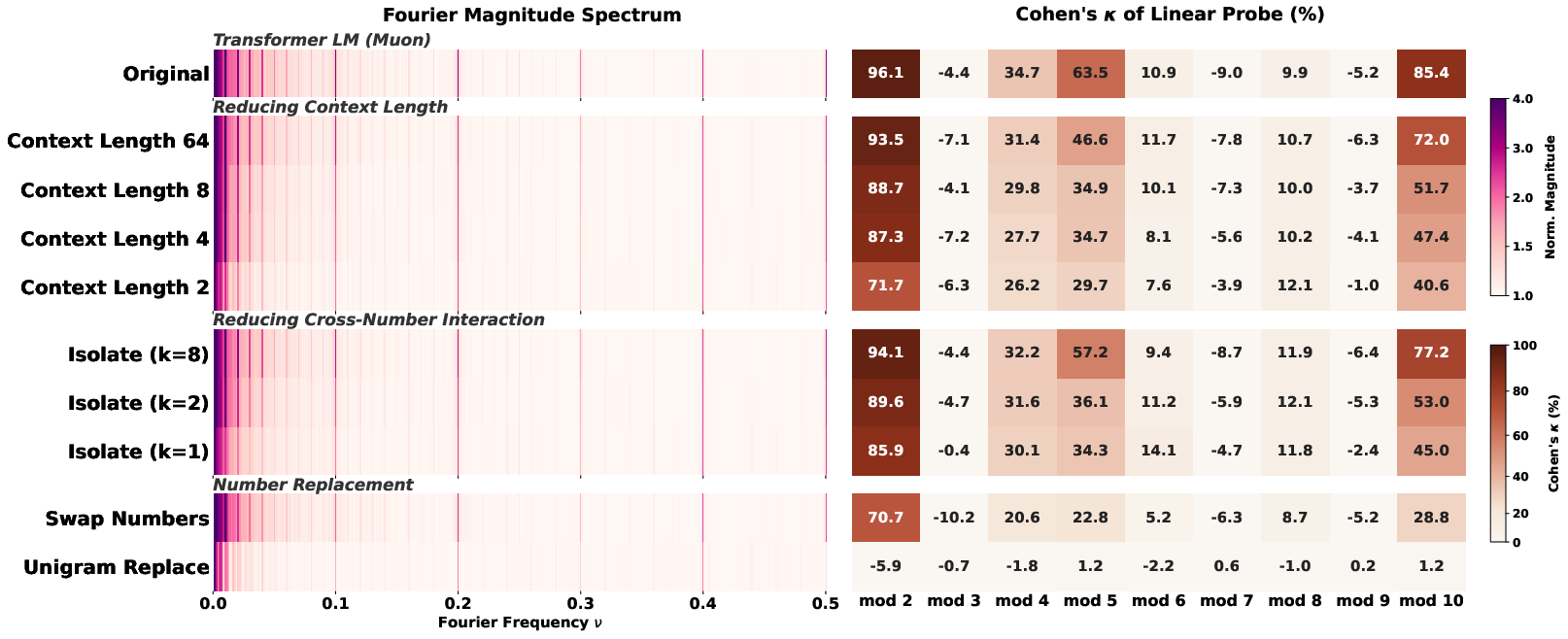
- Data signals:
- Just keeping number frequencies (and destroying co-occurrences) still gives Fourier spikes—but mod‑T decoding collapses to chance.
- Keeping associations between numbers and their surrounding words helps.
- Letting multiple numbers appear together in a context also helps (numbers interacting in the same sentence).
- Longer context windows (seeing more surrounding tokens) helps more.
- Architecture:
- Transformers and some linear RNNs achieve strong geometric convergence.
- LSTMs do not, even with clear Fourier spikes.
- Optimizer:
- The choice (Muon vs. AdamW) matters in nuanced ways: it shifts how well geometric convergence happens, and the best choice depends on the architecture. Spectral convergence shows up either way.
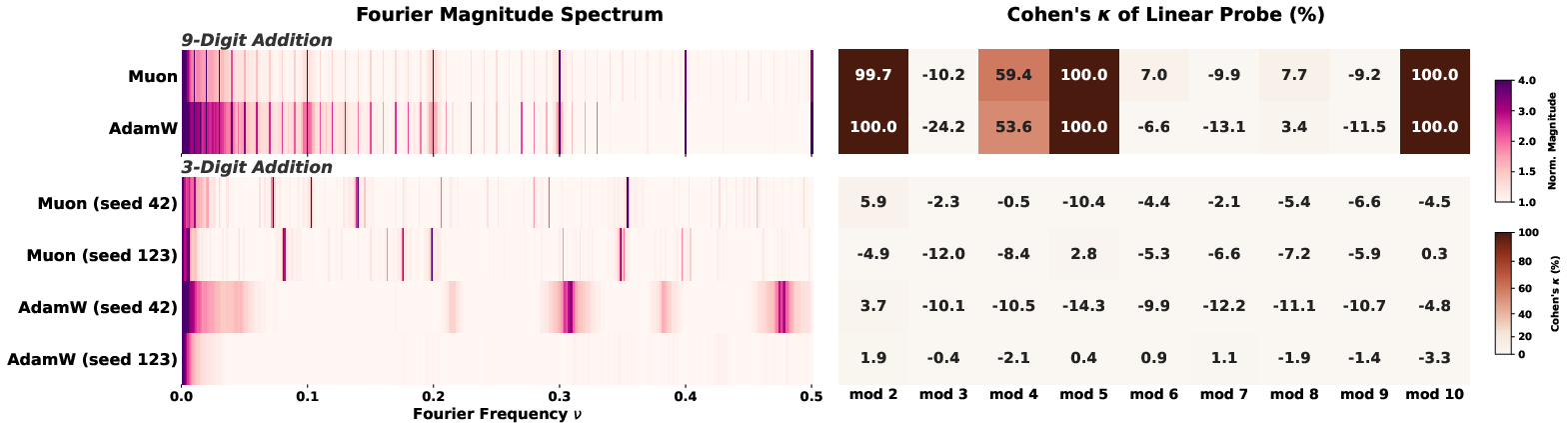
- Training on arithmetic shows a second route to convergence—and tokenization is the key.
- Multi-token addition (long numbers split into chunks) forces the model to solve “carry” subproblems digit by digit. That naturally creates mod‑1000 and related mod‑T structures, so spikes appear and mod‑T is easy to decode—no matter the optimizer.
- Single-token addition (each number is one token) doesn’t force any modular substructure. There’s no pressure to build those circular/repeating features, so sometimes the model learns them, sometimes not. Results vary by optimizer and random seed.
- Bottom line: if the task demands modular thinking (because of how numbers are split), the model converges on usable, shared representations. If not, it may not.
Why does this matter?
- It warns us: seeing a pattern in model embeddings doesn’t mean the model can use it simply. Pretty pictures of structure can be misleading.
- It gives a checklist for building better number understanding:
- Use data that connects numbers with text and with other numbers, and give the model enough context.
- Choose architectures (like Transformers or linear-style RNNs) that tend to produce clean, usable organization.
- Use tokenization and tasks that force modular subproblems (like multi-token numbers in arithmetic), which naturally shape the right internal structures.
- It suggests a general lesson beyond numbers: for any concept (like days of the week, months, or other cycles), we should distinguish “spectral” signs of a pattern from “geometric” organization that makes it functionally usable. That helps us tell superficial learning from real, actionable understanding.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of unresolved issues that limit the paper’s claims or open directions for follow-up work:
- Missing sufficient conditions: While the paper proves Fourier-domain power at period T is necessary but not sufficient for mod-T linear separability, it does not provide constructive or verifiable sufficient conditions (in terms of data distribution, architecture, or training dynamics) that guarantee geometric separability.
- Theory-to-training link: No theoretical bridge predicts when specific data/optimizer/architecture choices will yield favorable within-class scatter (low cond(S_W)) so that spectral signals translate into strong λ_max(S_W{-1} S_B) and high probing accuracy.
- Origin of T ∈ {2, 5, 10} spikes: The paper documents universality of these spectral peaks but does not causally explain why natural corpora (and tokenization) produce this periodic structure; a corpus-level, cross-domain, and cross-lingual analysis is missing.
- Tokenizer generality: Results hinge on the Llama-3 tokenizer (single tokens for 0–999). It remains unknown how conclusions change for byte-level tokenizers, different BPE/unigram vocabularies, digit-level tokenizations, or languages with distinct numeral morphology (e.g., Chinese, Arabic-Indic), and for spelled-out numbers.
- Ordering assumption in Fourier analysis: The DFT is computed over numbers ordered by numeric value. Robustness to token ID permutations, missing numbers, or non-contiguous numeric vocabularies is not evaluated.
- Scale dependence: Controlled experiments use ~300M-parameter models; the scaling behavior (parameters, data size) of spectral vs geometric convergence, including thresholds and scaling laws for κ vs tokens/params, is not characterized.
- Architecture-specific mechanism: LSTMs show strong spectral spikes but fail probing; the paper does not mechanistically explain why (e.g., gate dynamics, representational anisotropy sources, depth/width effects) or whether architecture tweaks (LN-LSTMs, attention-augmented LSTMs) could remedy this.
- Optimizer implicit bias: The optimizer dependence (Muon vs AdamW) is documented but not explained; a systematic study over hyperparameters (learning rate schedules, weight decay, norm constraints, clipping, batch size) and their interaction with architecture is missing.
- Layer-wise representations: Analyses focus on token embeddings; it is unknown how mod-T features evolve across layers, whether geometric separability emerges early or late, and whether deeper activations exhibit stronger/nonlinear decodability than embeddings.
- Nonlinear structure: While linear probes are primary, the extent to which moduli (e.g., 3, 7, 9) are nonlinearly decodable (kernel/MLP/circular probes) is not comprehensively mapped, nor are the representational geometries for these harder moduli analyzed.
- Distinguishing frequency artifacts from learned structure: Beyond showing that unigram frequencies can induce spikes, the paper does not provide a general diagnostic pipeline (e.g., reweighting/whitening, control spectra) to disentangle frequency-driven artifacts from functional features in practice.
- Comprehensive modulus sweep: The study emphasizes T ∈ {2, 5, 10} (and 4). A systematic chart of κ over a wide range of T (including divisors of 1000 like 8, 20, 25, 40, 50, 100, 125 and non-divisors) in pretraining is missing, making it hard to separate tokenizer vs data effects.
- Cross-number interaction granularity: The Isolate-k and context-length perturbations are coarse. More granular, synthetic controls over inter-number distance, order, and co-occurrence topology could isolate which interaction patterns most contribute to geometric convergence.
- Cross-lingual/multidomain robustness: Universality is claimed across some pretrained models but not systematically tested across languages, numeric conventions (thousand separators, date formats), domains (code, math corpora), or multimodal settings.
- Downstream relevance: It remains untested whether higher κ (geometric convergence) correlates with better numeric reasoning or arithmetic performance on downstream benchmarks; functional significance beyond probe accuracy is unclear.
- Addition with untied embeddings: The claim that tied embeddings induce modular pressure in multi-token addition is plausible but unverified; whether modular features still emerge with untied input/output embeddings or alternative output heads remains open.
- Task/objective dependence: Only autoregressive next-token prediction is studied; whether masked LMs, sequence-to-sequence training, or other objectives alter spectral/geometric convergence is unknown.
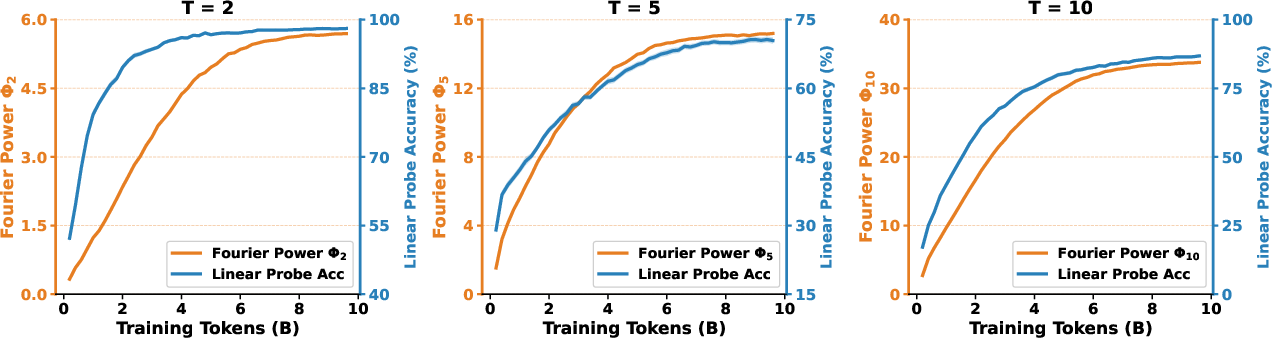
- Dynamics of S_W: Training dynamics show smooth co-emergence, but the evolution of the within-class scatter spectrum (eigenvalues, condition number) and its alignment with periodic signal directions over training is not measured.
- Reconciling digit-based and Fourier-based views: Prior work finds digit-level/base-10 representations. The relationship between digit-structured features and circular/Fourier features (coexistence, transformations between them) is not established.
- Mechanistic circuits: The paper does not connect embedding-level geometry to internal computational circuits (e.g., attention heads/MLPs implementing rotations) in the controlled pretraining runs; a causal link between geometry and mechanisms is missing.
- Arithmetic without modular pressure: In single-token addition, optimizer/seed-sensitive spectra appear, but the paper does not explore interventions (e.g., synthetic mod constraints, curriculum, regularizers) to induce convergence or explain why some seeds grok and others do not.
- Robustness of spectral metrics: Median-normalized Fourier power may be sensitive to analysis choices; robustness to alternative normalizations, windowing, detrending, and frequency-domain statistical tests is not reported.
- Post-processing to recover geometry: It is unknown whether simple post-processing (e.g., whitening by S_W{-1/2}, PCA within harmonic subspaces, metric learning) can convert “spectral-only” embeddings (e.g., LSTM) into geometrically separable ones, clarifying what training must achieve.
- Regularization effects: The influence of explicit regularizers (orthogonality, spectral penalties, embedding norm constraints, dropout on embeddings) on cond(S_W) and geometric convergence is not explored.
- Reproducibility and variance: While multiple seeds are used in places, comprehensive confidence intervals and variance analyses for κ and Φ_T across seeds/runs and compute settings are limited; exact scripts for data perturbations and training are not detailed in the main text.
Practical Applications
Immediate Applications
The paper’s findings support several concrete actions that can be adopted now to improve model reliability with numbers, audit training data, and design better training/evaluation workflows.
- Numeracy diagnostics for model development (Sector: software/AI) — Package Fourier-spectrum + mod-T linear-probe checks (Cohen’s κ, Fisher LDA eigenvalues) as a “Numeracy Eval Pack” integrated into training dashboards and eval harnesses; use thresholds on κ for T∈{2,5,10} as release gates; add a “Numeracy Annex” to model cards. — Assumptions/dependencies: access to number-token embeddings (or tied input/output embeddings), single-token coverage for 0–999 (or equivalent), and sufficient number-token counts.
- Tokenization-aware prompt/data formatting to improve arithmetic reliability (Sectors: software, finance, education) — Prefer multi-token formats that segment numbers into digit groups (e.g., triads) in tasks requiring addition/carry; ensure numbers are adjacent in context to induce cross-number interaction; keep consistent base-10 formatting. — Assumptions/dependencies: control over tokenization or input formatting; tied embeddings amplify benefits; applicable with common LLM tokenizers.
- Architecture selection guidelines for numeric tasks (Sectors: software, robotics, finance) — Choose Transformers or linear RNNs (e.g., Mamba-2, Gated DeltaNet) over LSTMs when reliable modular arithmetic features are required; use longer context windows where possible. — Assumptions/dependencies: similar parameter budgets; training on text with natural number co-occurrence; availability of long-context training/inference.
- Optimizer choice as a lever (Sector: software/AI) — Prefer Muon for Transformers and (often) Gated DeltaNet when targeting strong mod-10 separability; validate empirically for state-space models (e.g., Mamba-2 sometimes favors AdamW). — Assumptions/dependencies: optimizer availability, stability with current infra; effect is architecture-dependent and should be validated on the target data.
- Data pipeline “knobs” to preserve/use co-occurrence signals (Sectors: software/AI, education) — Avoid unigram replacements or aggressive de-identification that randomizes numbers; maintain text–number co-occurrence and cross-number interaction via packing strategies; ensure sufficient context length during pretraining/fine-tuning. — Assumptions/dependencies: control over corpus curation and packing; privacy constraints may conflict.
- Arithmetic hardening via lightweight synthetic curricula (Sectors: software, finance, education) — Interleave multi-token addition exercises during fine-tuning to induce geometric convergence (linearly separable mod classes) without degrading general language ability; focus on least significant digit tasks first. — Assumptions/dependencies: tied embeddings and multi-token numbers produce strongest effects; small curricula blended with domain data are often sufficient.
- Output guardrails using modular checks (Sectors: finance, operations, logistics) — Add parity (mod 2), last-digit (mod 10), Luhn-like (mod 10/11) checks as fast validators on generated calculations, invoice numbers, SKU checksums, and ledger summaries; prompt or tool-correct when violations are detected. — Assumptions/dependencies: the paper shows mod-2/5/10 are easiest; these guards detect a large fraction of arithmetic slips with minimal latency.
- Corpus auditing and anomaly detection via number-spectrum fingerprints (Sectors: policy, risk/compliance, software) — Track the Fourier spectrum of number-token frequencies to detect distribution drift, synthetic content mixtures, or data pipeline bugs; compare spectrum against historical baselines. — Assumptions/dependencies: requires enough numeric tokens; spikes at T=2,5,10 are typical in natural web-scale corpora—deviations can indicate issues but are not proof of malfeasance.
- Evaluation of cyclical concepts beyond numbers (Sectors: scheduling/logistics, calendaring, education) — Reuse the spectral vs. geometric probing workflow to verify that models not only “see” day-of-week/month periodicities but also encode functionally separable classes; adjust prompts/formatting to explicitly include multi-token date components (DD-MM-YYYY). — Assumptions/dependencies: availability of date-time tokens and consistent formatting; generalization beyond numbers is plausible but should be validated per domain.
- Structural attribution as an interpretability workflow (Sectors: academia, software/AI) — Adopt controlled data perturbations (e.g., Swap Numbers, Isolate-k, ContextLength-ℓ) to attribute learned numeric structure to data properties; use it alongside instance-level influence methods to guide dataset design. — Assumptions/dependencies: access to retraining or continued pretraining; impacts must be measured on held-out embeds/probes.
Long-Term Applications
These require further research, scaling studies, or engineering to productize but are directly motivated by the paper’s discoveries and theory.
- Numeracy certification standards for AI systems (Sectors: policy/regulation, finance, healthcare) — Define standardized tests that require geometric (not just spectral) convergence for mod-T classes; mandate reporting κ and LDA-based metrics in procurement/compliance; include “Numeracy Annex” in AI assurance frameworks. — Dependencies: consensus on thresholds; sector-specific moduli (e.g., mod 10/11 for checksums) and domain-tailored tasks.
- Tokenizer redesign for robust numerical reasoning (Sectors: software/AI) — Develop numeric-aware tokenizers that (a) guarantee multi-token segmentation for longer numbers, (b) preserve base-10 triads, and (c) coordinate with tied embeddings to encourage modular subproblems; ship as “Numeracy-First” tokenizers. — Dependencies: retraining or substantial continued pretraining; compatibility with multilingual/format-rich corpora.
- Training objectives that explicitly shape within-class scatter (Sectors: software/AI, academia) — Add losses/regularizers that maximize Fisher discriminants (or control cond(S_W)) for target moduli, ensuring that Fourier power translates into geometric separability; extend to cyclical concepts (calendars, clocks). — Dependencies: careful optimization to avoid interfering with general capabilities; requires scalable implementation.
- Plug-in “Fourier number embeddings” modules (Sectors: software/AI, finance, education) — Integrate explicit circular features (e.g., FONE-like Fourier number embeddings) into model inputs/heads to guarantee usable modular structure; expose a numeracy API for downstream apps. — Dependencies: interface and compatibility with existing architectures; evidence for broad transfer without regressions.
- Certified arithmetic heads for LLM tool-use (Sectors: finance, logistics, enterprise software) — Couple LLMs with small arithmetic modules that operate on multi-token numbers using modular representations; provide formal guarantees for addition/multiplication correctness and carry handling. — Dependencies: robust routing/tool-use; verification frameworks; UX integration.
- Forensic provenance and synthetic-text detection using numeric spectra (Sectors: policy, security) — Use characteristic mod-spectrum signatures of corpora/models as part of content provenance and detection pipelines; combine with other stylometry to identify training sources or generation artifacts. — Dependencies: large-scale benchmarks to validate sensitivity/specificity; defenses against adversarial obfuscation.
- Curriculum design for math tutoring systems (Sectors: education) — Build tutoring workflows that present numbers in multi-token, carry-rich contexts to induce modular representations in student-facing LLMs; progressively expand context length and cross-number interactions to enhance generalization. — Dependencies: longitudinal validation of learning gains; age-appropriate formatting; alignment with educational standards.
- Numeracy-aware data governance (Sectors: policy, enterprise data management) — Establish guidelines that preserve meaningful text–number co-occurrence and cross-number interaction in curated corpora; annotate datasets with numeric-spectrum metadata for reuse/disclosure. — Dependencies: processes to balance privacy with representational needs; tooling for automatic metadata extraction.
- Cross-modal periodic-representation engineering (Sectors: robotics, IoT, energy) — Extend spectral–geometric design to periodic sensor/time series (e.g., diurnal cycles, maintenance intervals), ensuring models both detect periodicity and encode functionally separable phases for control/planning. — Dependencies: domain-specific tokenization/segmentation of signals; evaluation of safety-critical performance.
- Theory-guided numeracy benchmarks and leaderboards (Sectors: academia, software/AI) — Publish open benchmarks that score models on both spectra and geometry (κ, λ_max(W{-1}B)) across moduli, tokenizers, and architectures; track progress on moving from spectral spikes to functional separability. — Dependencies: community adoption; reproducible pipelines and public model embeddings.
Each application builds on the paper’s core insights: (1) Fourier spikes (spectral convergence) are widespread but insufficient indicators of functional numeracy, (2) geometric convergence depends jointly on data, architecture, optimizer, and tokenization, and (3) multi-token arithmetic induces modular structure reliably. The feasibility of each item varies with control over tokenization, access to training loops, and sector-specific requirements for auditability and safety.
Glossary
- AdamW: An adaptive optimizer with decoupled weight decay commonly used to train deep networks. "We vary two different optimizers for training LLMs: AdamW and Muon."
- Anisotropic: Having direction-dependent variability; here, unequal spread of within-class variance across embedding dimensions. "the LSTM's within-class scatter is highly anisotropic"
- Attention window: The span of tokens a model’s attention mechanism can directly attend to within a context. "no two number tokens can interact within the same attention window."
- Autoregressive language modeling: Training objective where the model predicts the next token given previous tokens. "suggesting that autoregressive language modeling with text-number co-occurrence alone extracts richer modular structure than classical embedding methods."
- Between-class scatter matrix: Matrix capturing variance among class means, used in discriminant analysis. "the class means μ_r, grand mean μ, between-class scatter matrix S_B, and within-class scatter matrix S_W be"
- Carry propagation: The process by which carries from lower-order digit additions affect higher-order digits in multi-token addition. "multi-token tokenization creates modular subproblems that produce both spectral and geometric convergence through carry propagation"
- Circular probes: Probes that project embeddings onto the unit circle to analyze circular structure. "We additionally train circular probes that project embeddings onto the unit circle"
- Cohen's κ: A chance-corrected agreement measure used here to evaluate probe accuracy across T-way classes. "measured by Cohen's of a classifier trained to predict "
- Condition number: Ratio of largest to smallest eigenvalues of a matrix; indicates numerical stability and anisotropy. "A large condition number, , drastically lowers the minimum bound."
- Convergent evolution: Independent emergence of similar representations across different models due to shared training constraints. "We view this universality as a case of convergent evolution"
- Cross-number interaction: Statistical dependencies arising from multiple numbers co-occurring within the same context sequence. "including text-number co-occurrence and cross-number interaction"
- Discrete Fourier transform: A transform that decomposes a sequence into frequency components; applied along token index to detect periodicity. "we compute the discrete Fourier transform along the token index:"
- Eigenspectrum: The set of eigenvalues of a matrix; here determines separability via . "probe accuracy depends on the eigenspectrum of $_W^{-1}_B$"
- Fisher discriminant: The maximal achievable class separation along a single linear direction in LDA. "its Fisher discriminant $\lambda_{\max}(_W^{-1}_B)$ is two orders of magnitude smaller."
- Fisher's Linear Discriminant Analysis: A technique for finding linear combinations of features that best separate classes. "through the lens of Fisher's Linear Discriminant Analysis"
- Fourier domain: Frequency space obtained by Fourier transforming embeddings across token indices. "period- spikes in the Fourier domain"
- Fourier domain sparsity: Concentration of power at a few Fourier frequencies; indicates strong periodic components. "we prove that Fourier domain sparsity is necessary but not sufficient for mod- geometric separability."
- Fourier magnitude spectrum: The power of Fourier coefficients across frequencies, often normalized to compare peaks. "the Fourier magnitude spectrum, computed as the power normalized by the median across frequencies "
- Fourier power: Total energy at certain frequencies (e.g., harmonics of a period), used as a measure of periodic signal strength. "The LSTM has larger Fourier power than the Transformer"
- Fourier spike: A pronounced peak in the Fourier magnitude at a specific periodic frequency, indicating periodic structure. "A Fourier spike at period refers to a visible peak in "
- Generalized eigenvalue: Eigenvalue of a matrix pair (A, B) in problems like ; measures discriminative signal relative to noise. "exactly the largest generalized eigenvalue of the scatter matrices, $\lambda_{\max}(_W^{-1} _B)$."
- Geometric convergence: Emergence of linearly separable mod- classes in embeddings, enabling linear decoding. "We call the emergence of Fourier spikes spectral convergence and the emergence of linearly separable mod- classes geometric convergence."
- Geometric separability: The property that classes can be separated by linear boundaries in embedding space. "we prove that Fourier domain sparsity is necessary but not sufficient for mod- geometric separability."
- Grokking: A delayed generalization phenomenon where training accuracy precedes test accuracy by a long margin before a phase transition. "unlike the grokking observed in modular arithmetic"
- Harmonic frequencies: Integer multiples of a base frequency corresponding to a given period in the Fourier domain. "Let be the total power at harmonics of period , and be the set of harmonic frequencies."
- Linear probe: A linear classifier trained on frozen embeddings to test whether a property is linearly decodable. "we train a linear probe (-class logistic regression) to predict from ."
- Linear representation hypothesis: The conjecture that high-level concepts, if learned, are linearly decodable from representations. "The linear representation hypothesis \citep{park2023lrh} conjectures that such structure should be accessible via linear probes."
- Logistic regression: A linear classification model used here as a probe for mod- decoding. "we train a linear probe (-class logistic regression) to predict "
- Mechanistic interpretability: Research that aims to reverse-engineer learned circuits and representations in models. "Mechanistic interpretability aims to reverse-engineer the representations and algorithms learned by LLMs."
- Median-normalized magnitude: A normalization of spectral power by the median across frequencies to highlight peaks. "Each row shows the median-normalized magnitude at each Fourier frequency."
- Mod-: Equivalence classes of integers under modulus T arithmetic; here, classes to be decoded from embeddings. "the residue class is linearly decodable from the embedding ."
- Modular arithmetic: Arithmetic system where numbers wrap around after reaching a certain modulus. "Linear probes reveal only the Transformer and Gated DeltaNet learned functional modular arithmetic with high Cohen's "
- Moduli: Plural of modulus; different mod- tasks considered (e.g., 2, 5, 10). "remains near chance across all moduli."
- PPMI: Positive Pointwise Mutual Information; a classical word embedding method based on co-occurrence statistics. "PPMI and word2vec fall in between."
- RFM kernel: A kernel based on random feature mappings used as a non-linear probe alternative. "We use three probe types: linear (logistic regression), MLP, and RFM kernel \citep{radhakrishnan2024rfm}"
- Rayleigh quotient: Ratio measuring separation along a direction, used in LDA to quantify discriminability. "the single direction that maximizes the ratio of between-class to within-class variance, given by the Rayleigh quotient ."
- Residue class: Set of integers congruent modulo T. "define the mod- residue classes "
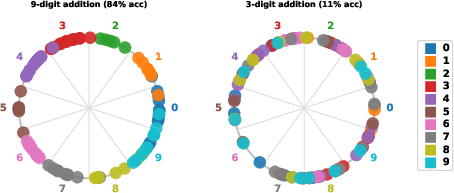
- Stratified digit-count sampling: Sampling scheme ensuring balanced coverage over operand digit lengths in addition tasks. "In 9-digit addition, operands have 1-9 digits with stratified digit-count sampling."
- Text-number co-occurrence: Joint appearance of numbers with surrounding text, providing a learning signal beyond frequency. "including text-number co-occurrence and cross-number interaction"
- Tied embeddings: Using the same embedding matrix for both input and output token representations. "Since all our models use tied embeddings"
- Token frequency distribution: Empirical counts of tokens; here, number tokens’ marginal distribution exhibiting periodic spectra. "Even the raw token frequency distribution of numbers in the training corpus, with no model at all, exhibits the same periodic spectrum"
- Tokenizer: The component that maps text to tokens; its design shapes numerical representation learning. "the tokenizer determines whether Fourier structure emerges"
- Unigram Replace: A perturbation that resamples each number token independently from its marginal (unigram) distribution, destroying co-occurrences. "including Unigram Replace, which destroys all co-occurrence structure by independently resampling every number token from its marginal distribution."
- Within-class scatter matrix: Matrix capturing variance within each class around its class mean. "between-class scatter matrix S_B, and within-class scatter matrix S_W be"
Collections
Sign up for free to add this paper to one or more collections.