- The paper demonstrates that conventional ID estimators are biased by latent space expansion, leading to unreliable intrinsic dimension measures.
- It proves that intrinsic dimensions should be non-increasing in Lipschitz neural layers, contradicting the increasing trends observed empirically.
- Empirical results reveal that ID estimates correlate more with entropy and geometric expansion rather than true manifold dimensions.
Authoritative Essay on "Rethinking Intrinsic Dimension Estimation in Neural Representations"
Introduction and Motivation
The paper "Rethinking Intrinsic Dimension Estimation in Neural Representations" (2604.20276) conducts a thorough theoretical and empirical investigation into intrinsic dimension (ID) estimators commonly used to analyze deep neural network representations. The study is grounded in the manifold hypothesis, which posits that high-dimensional data—such as images or textual prompts—are effectively supported on low-dimensional manifolds within their ambient input spaces. This hypothesis motivates the deployment of ID estimators in both dataset analysis and internal representation probing across architectures, including CNNs and transformers.
However, prevailing empirical results show persistent patterns in layer-wise ID estimates—specifically, increasing ID estimates in early layers followed by decreasing estimates in later layers for many architectures (see Figure 1). These trends are often interpreted as reflecting abstraction or phase transitions. The paper challenges these interpretations by rigorously demonstrating a disconnect between the theoretical properties of IDs and their actual estimates via standard methods. The research identifies and resolves this contradiction, offering new perspectives on what these ID estimates actually capture in neural representations.
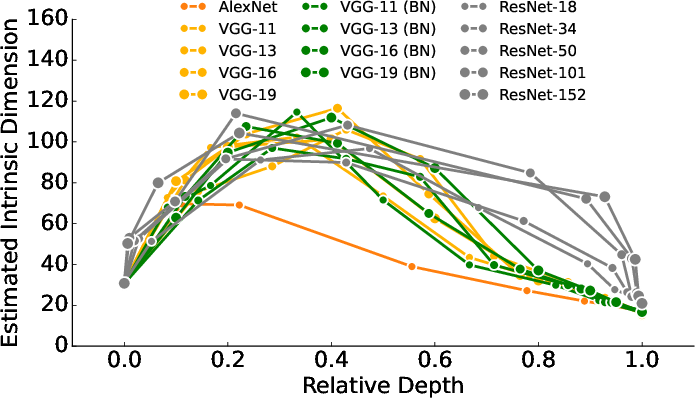
Figure 1: Layer-wise ID patterns for various architectures revealing increasing and then decreasing estimated IDs, commonly attributed to abstraction phases.
Theoretical Results: Failure of Conventional ID Estimators
IDs are typically formalized either as Hausdorff dimension or pointwise dimension, both of which attempt to describe the minimal number of degrees of freedom necessary to locally describe a data manifold. The most ubiquitous estimation methods—Maximum Likelihood Estimation (MLE), TwoNN, and Gride—operate on ratios of nearest neighbor distances in latent spaces, targeting the pointwise dimension.
Bias and Non-Monotonicity
Empirically, the authors show that TwoNN and MLE estimators suffer from substantial negative bias in high dimensions (Figure 2). This bias grows rapidly with increasing true ID, rendering these estimators unreliable for modern deep networks whose representations reside in very high dimensionalities. Crucially, the paper proves that—in theory—IDs cannot increase through layers of neural networks under the assumption that each layer is at least Lipschitz (almost always satisfied for standard architectures). The pointwise and Hausdorff dimensions are non-increasing under such mappings.
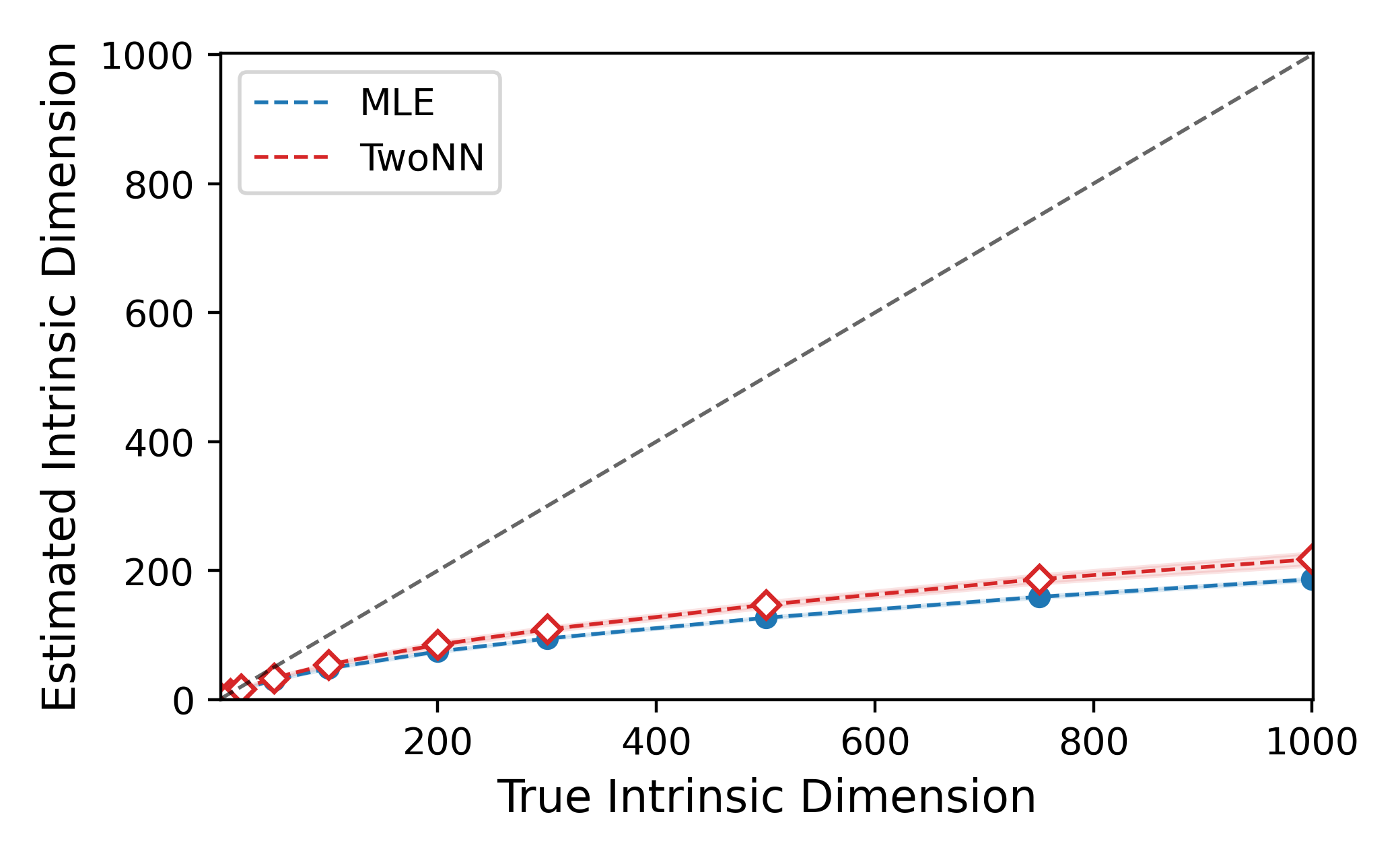
Figure 2: Estimated IDs using TwoNN and MLE vs. true ID, showing severe negative bias for high-dimensional manifolds.
The contradiction is manifest: empirical layer-wise ID estimates often increase in early layers, contravening the theoretical constraint that IDs should be monotonically non-increasing. Therefore, these empirical ID patterns are neither lower bounds nor consistent with theoretical IDs; layer-wise comparisons based on these estimates are fundamentally unsound.
Extensions: Union-of-Manifolds Hypothesis and Class-Specific IDs
The union-of-manifolds hypothesis extends the classic manifold hypothesis, positing that data from distinct classes or categories may reside on disconnected, possibly heterogeneous manifolds. The theoretical results proved for single manifolds also apply to unions of manifolds—pointwise and Hausdorff IDs remain non-increasing under Lipschitz mappings, even when each class-specific support can have distinct dimensions (Figure 3).
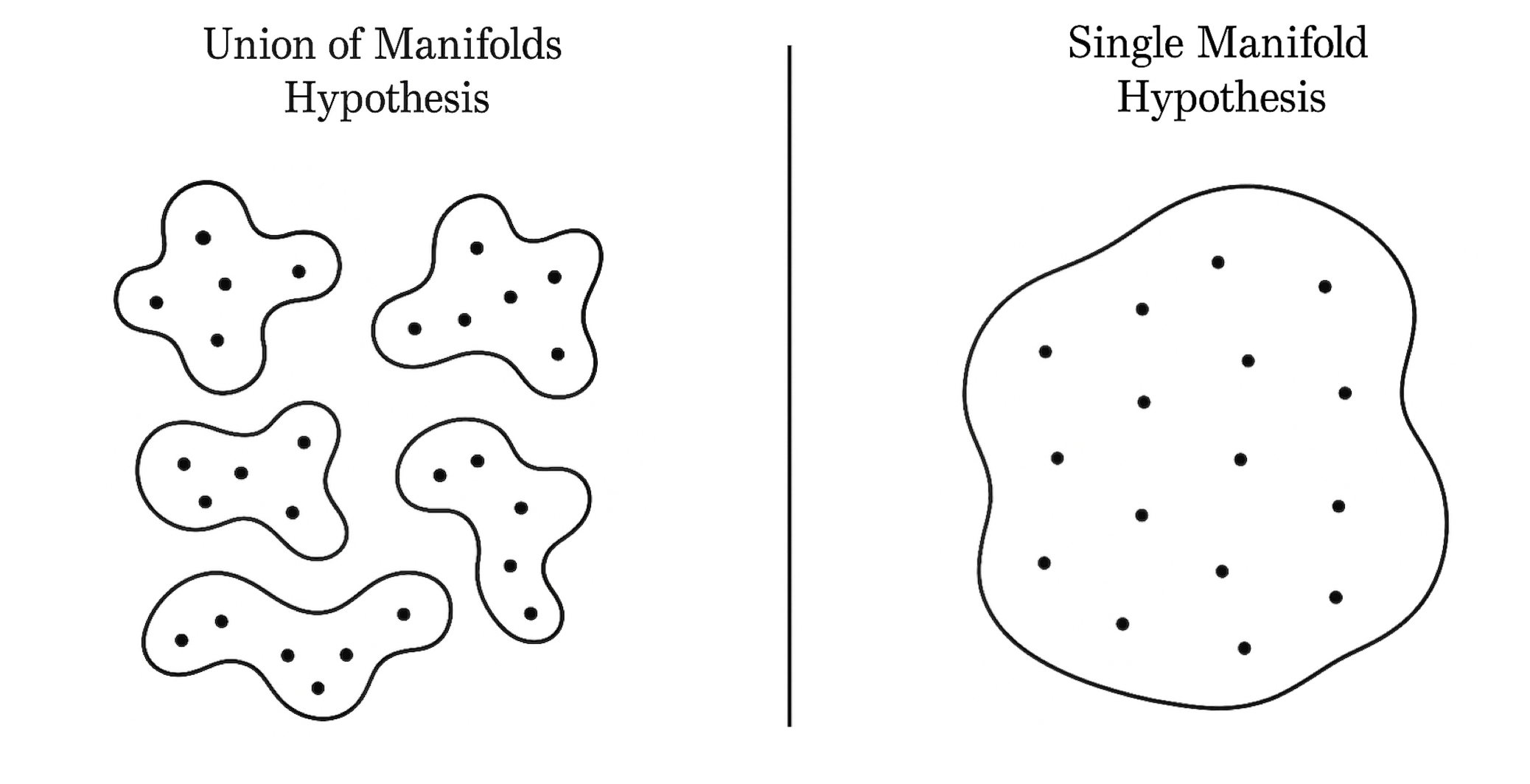
Figure 3: Illustration contrasting the union-of-manifolds (multiple disconnected) versus single manifold hypotheses.
Empirical tests reveal that even class-specific layer-wise ID estimates exhibit increasing patterns, reinforcing the mismatch between estimated and actual IDs (Figure 4).
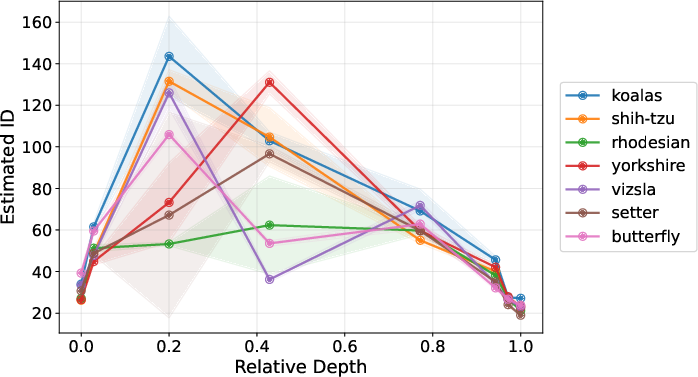
Figure 4: Estimated IDs for different ImageNet categories over the layers of a ResNet-34; estimates increase despite theoretical monotonicity constraints.
ID Estimation in LLMs
For LLMs, the manifold hypothesis is less straightforward. Token embeddings are discrete and finite, and thus strictly, their ID should be zero in the sense of Hausdorff or pointwise dimension. The paper rigorously demonstrates this, showing that any finite set (e.g., token embeddings or representations of finite sequences) has zero ID—even after transformations by the neural network (Figure 5). Nonetheless, empirical ID estimates for LLM layers show familiar non-monotonic increasing/decreasing trends when estimated using Gride or analogous methods (Figure 6).
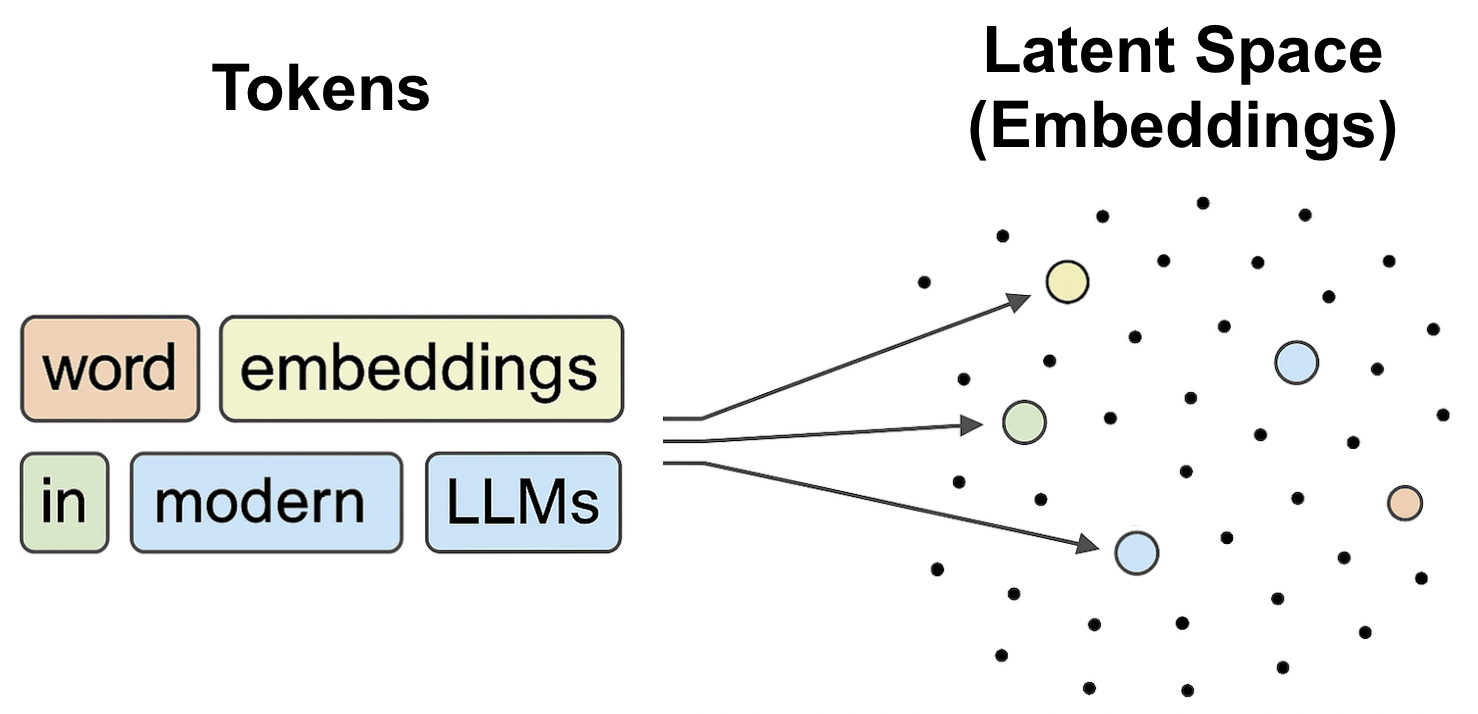
Figure 5: LLM word embeddings—tokens mapped to discrete points in latent space, with strictly zero intrinsic dimension.
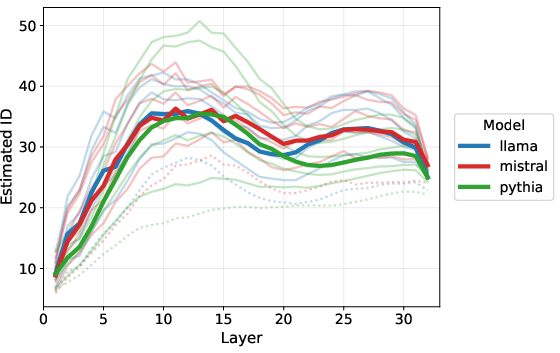
Figure 6: Estimated IDs via Gride for multiple LLMs, showing non-monotonic patterns analogous to vision models.
Analysis of Driving Factors Behind Empirical ID Patterns
Given the proven disconnect, the paper probes what the ID estimators are actually measuring:
- Nearest Neighbor Distances: ID estimators are sensitive to layer-wise expansion in latent space as measured by growing NN distances between representations (Figure 7).
- Cosine Similarity: Layer-wise cosine similarity fails to correlate with ID patterns; empirical trends are inconsistent or null (Figure 8).
- Representation Length: Layer-wise L2 norms of representations show expansion in latent space for LLMs, closely tracking increases in ID estimates (Figure 9).
- Entropy-Based Metrics: Layer-wise von Neumann entropy of representation distributions correlates strongly with ID estimates (Figure 10). Entropy increases when variance is more widely distributed across eigendirections.
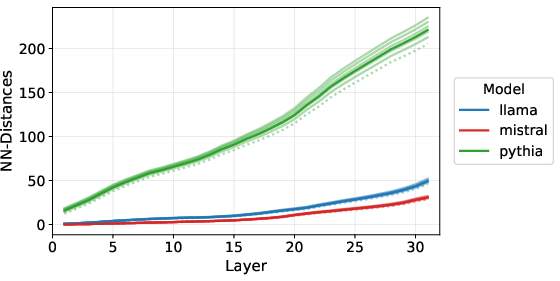
Figure 7: Layer-wise NN distances for LLMs showing a systematic increase—key driver for inflated ID estimates.
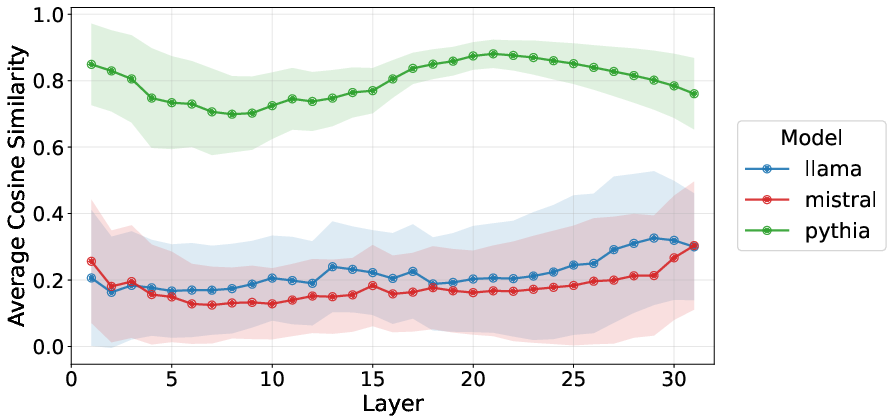
Figure 8: Average cosine similarity for layer-wise LLM representations; patterns are inconsistent with ID trends.
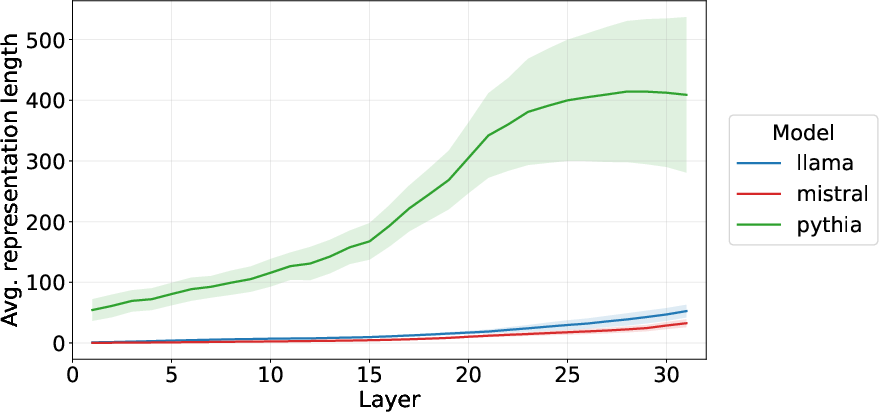
Figure 9: Layer-wise L2 norms for llama, mistral, and pythia; expansion in latent space mirrors ID growth.
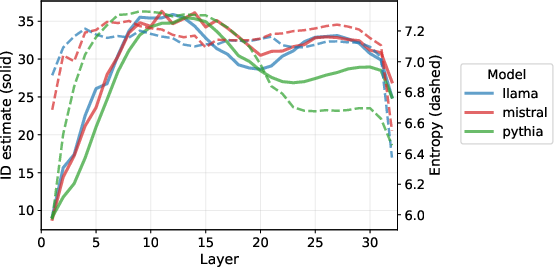
Figure 10: Paralleled increases between layer-wise ID estimates and von Neumann entropy for LLM representations.
This evidence supports the claim that estimated IDs are tracking geometric properties tied to expansion/spread in latent space, not the intrinsic manifold dimension. This is reinforced across modalities, including vision models, where complexity in representation does not track ambient dimension but entropy patterns instead.
Practical and Theoretical Implications
Revision of Common Interpretations
The research compels a broad reconsideration of empirical studies using ID estimates for neural representations in both language and vision domains. Empirical ID patterns—previously posited as evidence of abstraction formation or phase transitions—are not reliable indicators of actual intrinsic dimensions and should not be used as such. Instead, these estimates are more reflective of layer-wise geometric expansion and entropy.
Impact on Network Analysis and Future Estimators
As layer-wise entropy and expansion are the true drivers behind ID estimation patterns, the adoption of entropy-based metrics may provide more robust and theoretically sound geometric summaries. Furthermore, the paper sets a minimal requirement for future ID estimators: layer-wise IDs should not increase across layers in neural networks comprised of Lipschitz mappings. Any estimator failing this theoretical constraint cannot be consistent.
The findings suggest that theoretical formalization and benchmarking of ID estimators against monotonicity constraints will be crucial for principled analysis. Moreover, the recognized connection to entropy and variance spread indicates future avenues for integrating information-theoretic metrics in the analysis of latent geometry.
Conclusion
The paper provides a rigorous review of intrinsic dimension estimation in neural representations, unambiguously demonstrating that prevailing empirical techniques are neither unbiased nor consistent with theoretical IDs, especially in deep models. The persistent empirical ID patterns are explained by latent space expansion and entropy, not intrinsic manifold dimension. This implies that previous interpretations need to be revised and that future work should combine geometric and information-theoretic approaches. Critically, estimators must respect monotonicity under Lipschitz mappings, and entropy-based metrics should take precedence in neural representation analysis. These insights lay the groundwork for a more accurate and meaningful characterization of neural network internal geometry.