- The paper introduces a dual evaluation framework that benchmarks synthetic trajectory utility using point-level, trajectory-level, and task performance metrics.
- The paper demonstrates that blurring models, despite high utility, are highly vulnerable to membership inference attacks with accuracies up to 98.5%, highlighting critical privacy risks.
- The study emphasizes the need for robust privacy-preserving techniques, such as differential privacy, to mitigate data leakage in synthetic mobility data.
Dual Perspective Analysis of Synthetic Trajectory Generators: Comprehensive Utility Framework and Investigation of Privacy Vulnerabilities
Introduction
The paper "A Dual Perspective on Synthetic Trajectory Generators: Utility Framework and Privacy Vulnerabilities" (2604.19653) introduces a systematic utility evaluation framework for synthetic human mobility trajectory generators and critically examines their privacy properties, particularly focusing on "blurring models" that generate synthetic trajectories by transforming real samples at inference. This work addresses the critical privacy-utility trade-off inherent to synthetic data release and demonstrates that some models, despite producing high-utility synthetic data and showing apparent privacy resilience against user-linking, remain highly susceptible to privacy leakage through membership inference attacks.
Utility Evaluation: Taxonomy and Framework
The study initiates with an extensive analysis of the challenges in utility evaluation for synthetic mobility data. Given the inherent complexity of human mobility—marked by sparsity, heterogeneity, and non-stationarity—existing studies lack a standardized or comprehensive approach to utility benchmarking. Most prior work is fragmented, typically opting for a restricted set of metrics tailored to narrow use cases, rendering cross-model comparison infeasible.
The paper proposes a multidimensional taxonomy for utility evaluation, distinguishing between:
- Data granularity: Point-level (statistical properties of individual points) versus trajectory-level (distributional statistics across whole sequences).
- Utility notions:
- Statistics Preservation: Both marginal (e.g., individual speeds, densities) and relational statistics (e.g., pairwise distances like Hausdorff, Fréchet).
- Realism Assurance: Physical and semantic plausibility checks, including map reconciliation, reachability, and constraint violations.
- Task Performance: Efficacy on downstream analytical or predictive tasks (e.g., clustering, forecasting, flow prediction).
This taxonomy explicitly excludes inter-dataset relational metrics (e.g., closest real-synthetic pairs), showing that such metrics are not only misleading as utility measures, but also serve as privacy attack vectors (specifically in membership inference scenarios).
The framework advocates constructing an "utility-vector" per generator, with dedicated dimensions for each orthogonal utility criterion, and mandates practitioners choose at least one metric per cell to enable robust, context-sensitive benchmarking.
Empirical Benchmarking of Generative Models
The utility framework is empirically applied to three generative architectures:
- LSTM-TrajGAN: Recurrent neural model synthesizing trajectories with joint modeling over spatial, temporal, and semantic features
- exGAN: Attention-augmented generator with label-exclusion constraints for sensitive attributes
- TrajGDM: Diffusion probabilistic model with LSTM encoding and transformer-based noise reversal
Two use case studies are presented:
- Retail Mobility (Weekly FS-NYC): The primary goal is the accurate regeneration of semantic/categorical mobility attributes.
- Web Mobility (Daily Geolife): The objective shifts to spatial accuracy for localization prediction tasks.
Evaluation reveals that no model universally dominates; exGAN achieves the highest combined semantic utility in scenario A, while LSTM-TrajGAN is optimal for physical/trajectory realism in scenario B; diffusion models show higher variability across utility dimensions. Notably, performance is highly task-sensitive, and practitioners may consider hybrid approaches or model ensembles targeting domain-specific utility profiles.
On Privacy: Limitations of Existing Evaluation and Introduction of Membership Inference Attacks
A major contribution concerns privacy analysis. The paper identifies two fundamental generator classes:
- Synthetic models: Generate data from random noise via learned distributions (classic GANs, diffusion models), decoupled from the inference/test set.
- Blurring models: Generate synthetic samples by direct transformation (blur, perturb) of real records at inference, creating intrinsic one-to-one mapping (e.g., LSTM-TrajGAN, exGAN).
The field's standard privacy evaluation—Trajectory User Linking (TUL)—is critiqued as insufficient. TUL, typically a clustering or matching task between synthetic and real sequences, is reducible to a nearest-neighbor distance problem, and under realistic threat models, fails to reveal true privacy leakage (as theoretical and empirical evidence increasingly shows [yao2025dcr, najjar2022trajectory]).
The work proposes a refined privacy evaluation methodology, advocating adversarial protocols in line with regulatory best practice (EU GDPR, etc). Most crucially, it presents and implements the first membership inference attack (MIA) for blurring models in the mobility context.
The MIA leverages the observation that, in blurring models, synthetic records are close (by design) in high-dimensional trajectory space to their source, and thus the minimum distance to the synthetic set is a powerful, robust feature for inference.
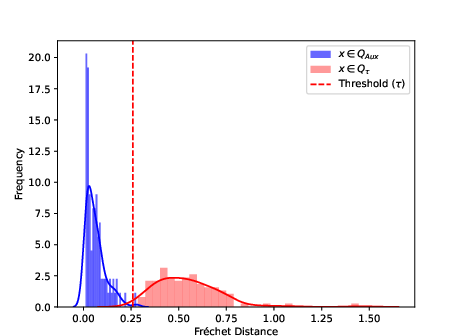
Figure 1: Example of threshold computation for MIA, based on the Fréchet distance between candidate and generated trajectories.
Numerical Results and Attack Implications
The MIA is demonstrated on LSTM-TrajGAN and exGAN, both on retail and web mobility datasets, with the following results:
- Accuracy up to 98.5% is achieved in determining trajectory membership, even with weak background knowledge (e.g., attacker only has access to released synthetic data).
- Effectiveness with limited information: With only partial (25%) trajectory information, accuracy remains above 80%.
This demonstrates that the privacy vulnerability is inherent to the generator's inference protocol, and not mitigated by standard dataset partitioning or metric selection.
Model Convergence Analysis
The paper also empirically investigates the convergence of the LSTM-TrajGAN generator, revealing the evolution of generator loss during training and its relation to memorization.
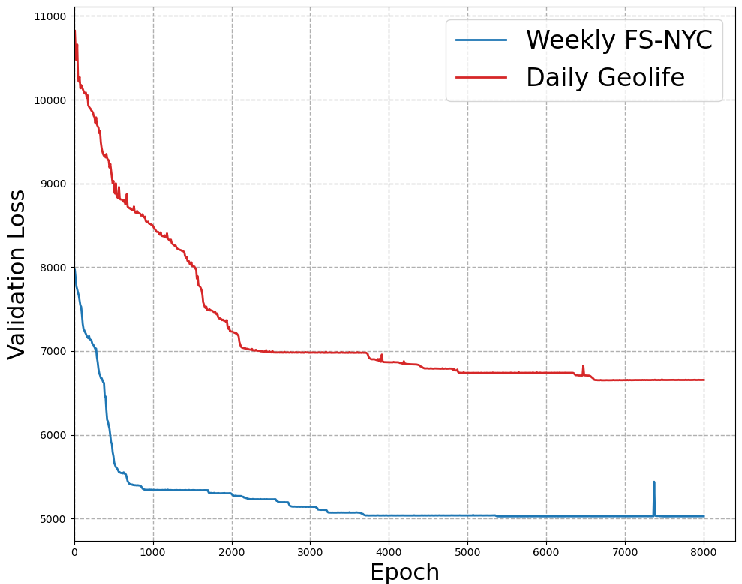
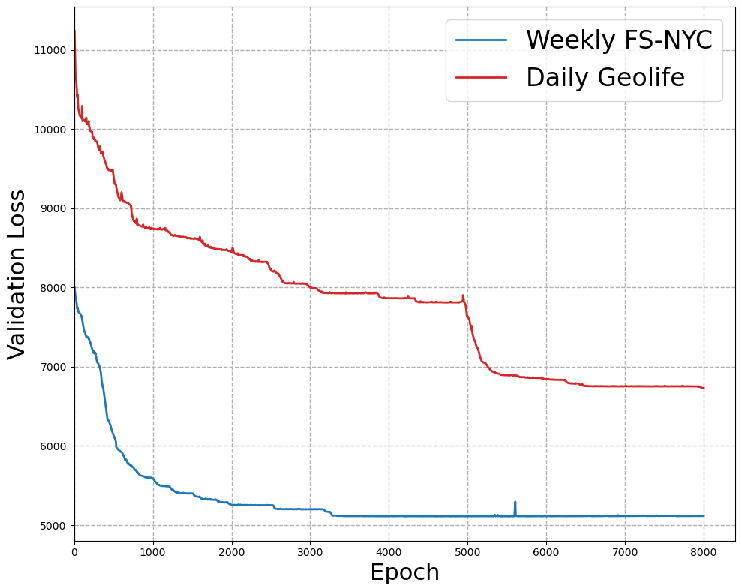
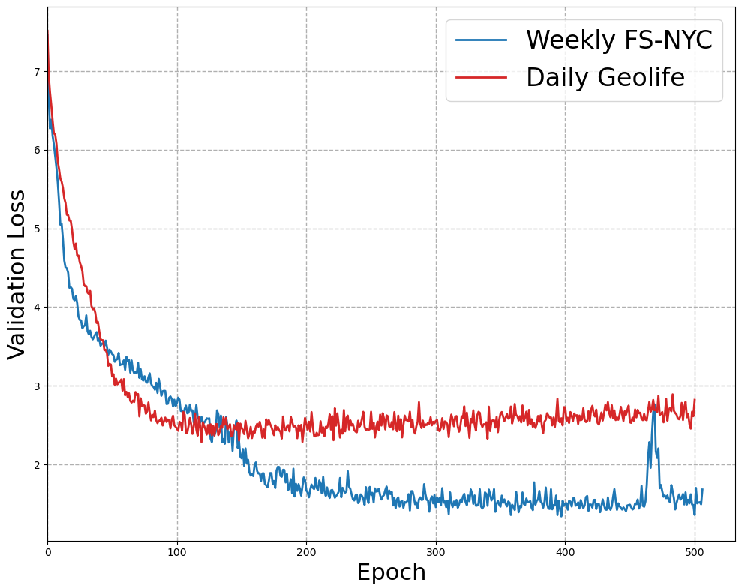
Figure 2: Generator's loss dynamics during training of LSTM-TrajGAN.
Practical and Theoretical Implications
The findings have several implications:
- Practitioners must not assess privacy solely via TUL or other distance-based utility-proxied approaches. Doing so creates a false sense of privacy, especially for blurring models, as low TUL accuracy does not preclude high MIA attack efficacy.
- High-utility synthetic mobility generation is currently orthogonal to robust privacy guarantees unless generators are strictly decoupled from their source records at inference, or additional privacy-preserving mechanisms (e.g., differential privacy) are explicitly incorporated.
- MIAs tailored to the trajectory setting must become the de-facto evaluation benchmark, and their development for each generator category (especially novel architectures) is mandatory for any privacy claim regarding data-sharing or release.
Conclusion
The study presents a principled, actionable framework for utility evaluation of synthetic trajectory generators and rigorously establishes the need for adversarial privacy assessment. It delineates the boundary between synthetic and blurring models, showing that state-of-the-art blurring approaches, though previously assumed "private," are acutely vulnerable to membership inference. The implications are direct: mere blurring or sample-to-sample transformations are not privacy-preserving. Differential privacy, or similar rigorous noise mechanisms, are necessary for strong privacy guarantees. Future research should focus on systematic frameworks for privacy evaluation, robust metric design, and the intersection of privacy and utility under realistic threat modeling.
References:
- [yao2025dcr] Z. Yao et al., "The DCR Delusion: Measuring the Privacy Risk of Synthetic Data", (Yao et al., 2 May 2025).
- [najjar2022trajectory] A. Najjar et al., "Trajectory-user linking is easier than you think", 2022 IEEE Big Data.
- (2604.19653) A. Cherigui et al., "A Dual Perspective on Synthetic Trajectory Generators: Utility Framework and Privacy Vulnerabilities".