- The paper introduces DPC, a distributed page cache architecture that uses CXL to maintain a single-copy invariant of pages across nodes.
- It employs a centralized directory and integrates with the Linux VFS to coordinate page ownership and remote mappings, enhancing scalability.
- Experimental results highlight significant latency and throughput improvements in read and write workloads compared to traditional systems.
DPC: A Distributed Page Cache over CXL
Motivation and Problem Statement
Modern distributed file systems typically employ independent, per-node page caches layered atop shared file systems like GPFS or Lustre. This design achieves low-latency access but leads to significant inefficiencies—namely (i) massive data redundancy, as hot data is replicated unnecessarily across nodes, and (ii) costly cache-coherence overheads due to heavyweight lock-based or token protocols. These inefficiencies waste DRAM resources and hamper scalability as clusters grow.
Despite decades of work in cooperative and shared caching, most systems maintain only disjoint, local caches without exposing a true, cluster-wide DRAM cache abstraction. While prior proposals leverage RDMA-enabled designs for remote cache access, these solutions fail to transparently integrate with the OS-level page cache and incur significant software overheads. The advent of Compute Express Link (CXL) 3.0 introduces hardware-managed, memory-centric cache coherence across hosts, providing a substrate for building coherent, distributed memory structures. However, to fully realize these benefits at the page-cache level and within the constraints of commodity OS interfaces, new designs are needed.
DPC Architecture
DPC (Distributed Page Cache) presents an OS-level distributed page cache, which aggregates cluster memory into a single, unified page cache accessible over a CXL memory fabric. DPC’s design revolves around a page-granularity single-copy invariant—each logical page exists in DRAM at exactly one node; all other nodes request access over CXL, avoiding unnecessary cacheline or page replication.
DPC Directory
The centralized DPC Directory manages page-level metadata for all cached file pages across the cluster, coordinating ownership, invalidations, and reclamations. Ownership is immutable per logical page; remote mappings are tracked explicitly, enabling DPC to deterministically coordinate memory reclamation or migration.
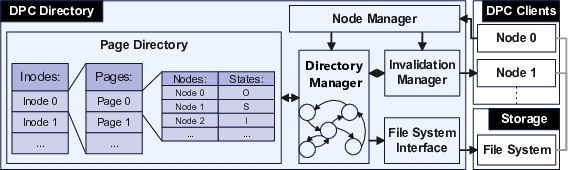
Figure 1: The DPC Directory integrates per-page state tracking, directory management logic, and interfaces for file system access, control-plane communication, and invalidation management.
The core data structure is a two-level hash table mapping (inode, page index) to an ownership vector encoding the current owner and all mappings. The directory maintains a compact state machine per page, with states including Invalid, Exclusive, Owner, Shared, and To-Be-Invalidated. State transitions are triggered on cache misses, writes, mapping requests, and evictions, preserving atomicity and supporting high concurrency.
DPC Client
Each compute node runs a DPC Client, transparently integrating with the Linux VFS and page cache layers. Upon page-cache miss, the client communicates with the DPC Directory, either obtaining exclusive ownership or establishing a remote mapping via CXL. Remote pages are mapped into local ZONE_DEVICE regions, appearing as ordinary DRAM-backed pages to the kernel and user processes.
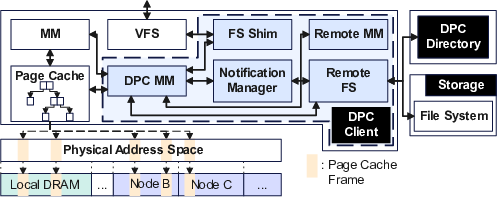
Figure 2: Key components of the DPC Client: file system shim, memory management, directory communication, notification handling, and CXL-backed remote memory mapping.
For memory reclamation, the client cannot unilaterally evict owned pages without orchestrating invalidations of all remote mappings. DPC implements scalable, batched invalidation protocols, separating regular I/O and coordination/control-plane traffic through dedicated virtio queues.
Challenges and Solutions
The design of a distributed page cache over CXL introduces several technical challenges:
- Semantic/Granularity Mismatch: CXL manages coherence at cache line granularity, unaware of high-level file/page abstractions or OS-level durability semantics. DPC bridges this by synthesizing page-level invariants atop the underlying coherence protocol without resorting to coarse locking.
- Local Reclamation vs. Global Coherence: Nodes must independently reclaim local DRAM while avoiding unsafe evictions of pages remotely mapped or dirtied by other nodes. DPC ensures safe reclamation through centralized directory coordination and deterministic invalidation handshakes.
- Control-plane Overhead: The latency budget for directory lookups, ownership negotiation, and invalidations must be amortized so as not to erode the latency advantages of remote memory access over local SSD/NVMe.
Implementation
DPC extends the upstream Linux 6.12.5 kernel’s Virtiofs implementation. The directory/server side extends virtiofsd, while client logic is implemented as a kernel module and integrates at the VFS and MMU levels. Remote memory regions exposed by CXL are modeled as ZONE_DEVICE and mapped via a custom dpc_dax driver. All DPC-specific coordination is carried over new dedicated FUSE opcodes and virtqueues.
Experimental Setup and Microbenchmark Results
A complete end-to-end implementation is evaluated on a QEMU-based emulated CXL 3.0 multi-host environment using a large ARM server. Storage is provisioned on a high-throughput SSD-based RAID-0 subsystem, and experiments use both standard system microbenchmarks (fio) and real applications.
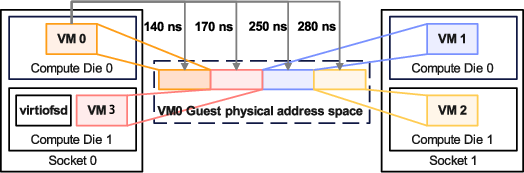
Figure 3: Evaluation setup for CXL emulation, showing memory hierarchy and latency modeling for local and remote DRAM access.
Benchmarks consider three scenarios: (1) cache miss with no remote resident, (2) cache miss with a remote resident (CM-R), and (3) repeated accesses hitting a previously established remote mapping (CH-R). Two I/O engines are used: libaio and mmap, exercising both syscall-based and page-fault-driven access paths.
In read microbenchmarks, DPC demonstrates minor overheads over Virtiofs on cold-cache misses (pure storage path). For cache hits where a remote node owns the page, DPC achieves up to 2.6× lower latency and 1.3× higher bandwidth compared to Virtiofs in CM-R, and up to 4.5× speedup in the CH-R scenario (libaio).
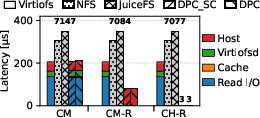
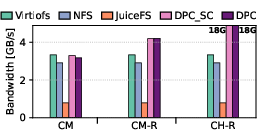
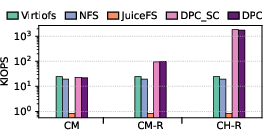
Figure 4: Read latency, bandwidth, and IOPS using fio with libaio demonstrating the efficacy of DPC in remote cache-hit scenarios.
In mmap-based evaluation, DPC achieves similar advantages, as page faults can be directly resolved from remote DRAM, substantially outperforming classic file systems and user-level distributed FSes.
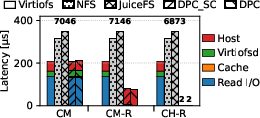
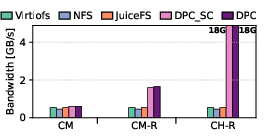
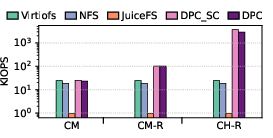
Figure 5: Read latency, bandwidth, and IOPS using fio with mmap, illustrating DPC’s gains for transparent, page-fault-based remote cache access.
Write throughput is compute-bound, as all baseline systems utilize buffered write-back. DPC introduces overhead only under strong coherence due to directory-mediated ownership negotiation, but this is offset by effective batching and remote mapping re-use. In mmap-based write benchmarks, DPC achieves 2.7× lower latency and 3× higher bandwidth in the CM-R scenario, with up to 23× lower latency and 18× higher IOPS for repeat remote-mapping hits.
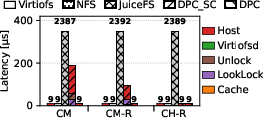
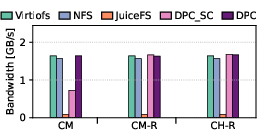
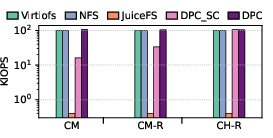
Figure 6: Write latency, bandwidth, and IOPS using fio with libaio, showing the impact of DPC’s write coordination.
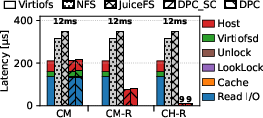
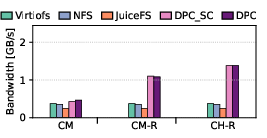
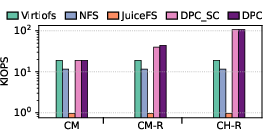
Figure 7: Write latency, bandwidth, and IOPS using fio with mmap, confirming superior remote-page write handling.
Page Reclamation and Scalability
DPC’s directory protocol for safe remote mapping invalidation introduces order-of-magnitude slower single-page invalidation compared to uncoordinated reclamation (Virtiofs: 11 µs vs. DPC: 99.7 µs), but in practice, amortizes this cost via asynchronous batching and does not degrade sequential read or write bandwidth under memory pressure.
Application Benchmarks and Speedup
Application-level benchmarks (RocksDB, DeepSeek, DiskANN, Webserver, Fileserver) examine end-to-end impact under realistic working sets exceeding per-node DRAM capacity. With cluster-wide cache pooling across multiple nodes, DPC yields dramatic per-node speedups compared to Virtiofs—up to 12.4× for DeepSeek, 16.2× for Webserver, and comparable improvements on other workloads. These gains are attributed to eliminating redundant replication and enabling transparent low-latency reuse of hot pages cached by any node.
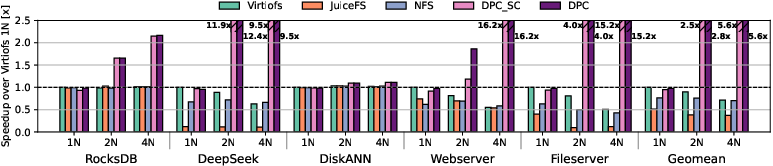
Figure 8: Relative speedup of application benchmarks over single-node Virtiofs baseline, for 1, 2, and 4-node configurations.
Additionally, DPC maintains per-node bandwidth as clients scale, validating its protocol and directory design for real cluster environments.
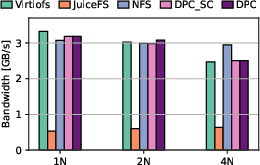
Figure 9: Measured per-node bandwidth across increasing numbers of cluster nodes, demonstrating DPC's scalability and resource pooling effectiveness.
Security, Liveness, and Consistency Considerations
DPC restricts CXL-exposed memory by exporting only page-cache frames enrolled in DPC, backed by hardware-granular access control. Directory liveness and client-failure handling are built-in by monitoring timeouts and removing failed nodes from all directory states. Both strong and relaxed coherence models are supported: strong coherence guarantees single-copy semantics with write coordination, while relaxed coherence offers weak consistency akin to NFS for workloads with predominantly read sharing.
DPC differs from prior CXL pooling solutions (DirectCXL, Pond, TPP) by supporting multi-host, page-level sharing rather than export-only or host-exclusive access. Other works utilizing CXL for database buffer pools or file systems (FamFS, CXL-SHM) do not target transparent, OS-integrated page caching across standard file system workloads. DPC's contributions are orthogonal to page cache scalability and policy optimizations achieved via user-space or eBPF-based approaches.
Implications and Future Directions
The DPC architecture positions CXL as a foundational substrate for new cluster-wide memory and caching abstractions, decoupling file-systemwide DRAM allocation from static per-node budgets. Practically, DPC can substantially reduce total DRAM provisioning and provide uniform, low-latency access to hot working sets in data-intensive distributed workloads. Theoretically, the decoupling of ownership, mapping, and coherence at the page granularity suggests new classes of protocols for OS-managed, heterogeneous memory fabrics that can accommodate both strong and eventual consistency models.
Potential avenues for future work include extending directory placement and management to decentralized or hierarchical topologies; mitigating coordination cost at exascale cluster sizes; and exploring differentiated consistency, durability, or caching policies in a broader range of distributed system software stacks.
Conclusion
DPC delivers a scalable, transparent, and efficient distributed page-cache mechanism for clusters interconnected by CXL. Leveraging a centralized directory, page-granularity single-copy invariant, and CXL-enabled low-latency remote memory mapping, DPC eliminates the DRAM waste and coherence complexity endemic to current per-node cache architectures. Experimental results highlight major end-to-end performance benefits across multiple real-world application domains, indicating that OS-level, CXL-backed distributed caching is a practical and impactful step toward future memory-centric cluster architectures (2604.19494).