- The paper introduces an end-to-end pipeline that converts sparse, noisy autonomous driving logs into high-quality 3D simulation assets.
- It leverages a two-stage approach with SparseViewDiT for multi-view novel synthesis and Object TokenGS for feedforward Gaussian lifting.
- Benchmarking results demonstrate significant improvements in PSNR, SSIM, and other metrics over existing image-to-3D baselines.
Asset Harvester: Image-to-3D Asset Generation for AV Simulation
System Design and Methodological Innovations
Asset Harvester introduces a domain-focused end-to-end pipeline that transforms sparse, noisy object-centric observations from multi-modal autonomous driving logs into simulation-grade 3D assets. The architecture begins with scalable ingestion and curation from NCore-based logs, proceeds through data rectification and cropping, followed by a two-stage generative process: SparseViewDiT, a linear-attention multiview diffusion transformer trained for robust, limited-angle novel view synthesis, and Object TokenGS, a feedforward neural module that lifts generated multiview images into explicit, compact 3D Gaussian representations.
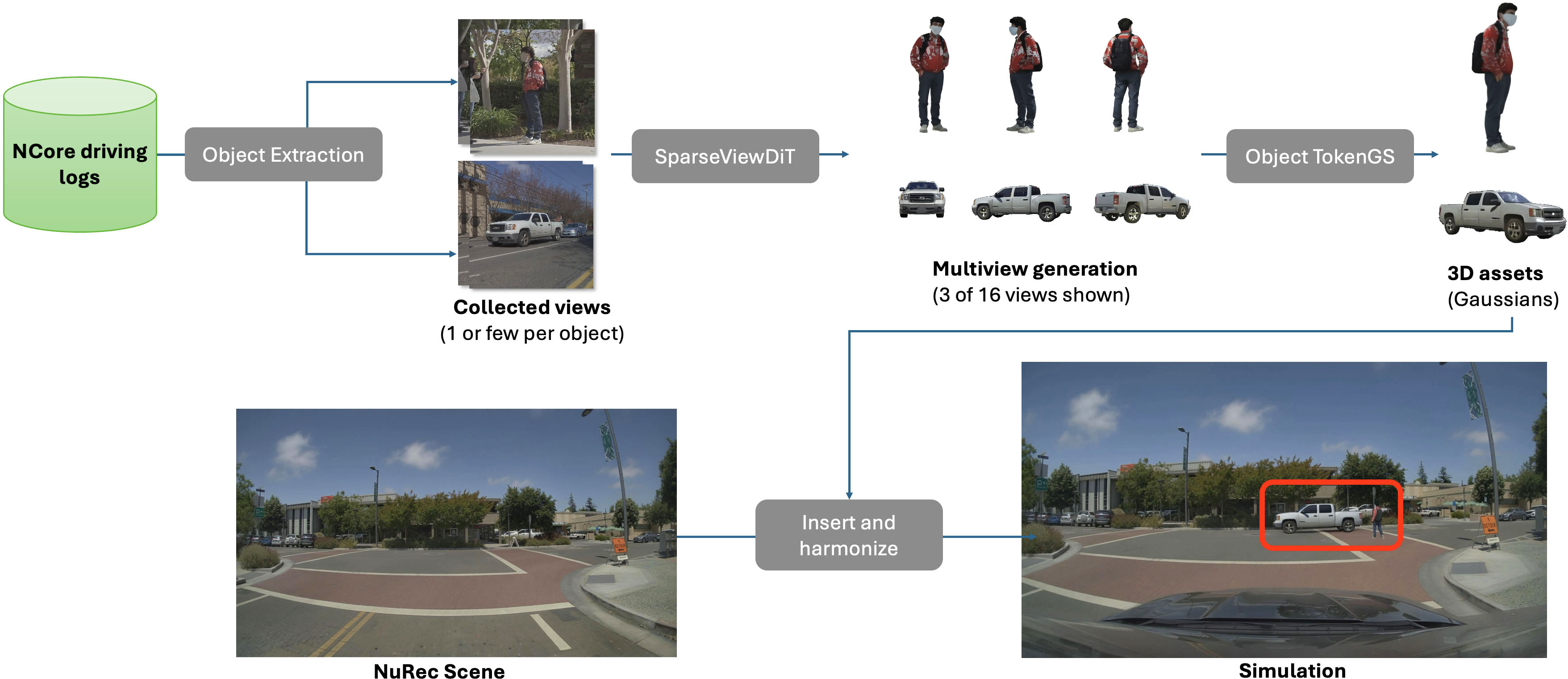
Figure 1: Asset Harvester pipeline: log ingestion, object-centric cropping, multiview generation, 3D lifting, asset reinsertion and harmonization for closed-loop simulation.
The pipeline incorporates geometry-aware preprocessing to consolidate inconsistent sensor modalities (multi-camera RGB, LiDAR, 3D tracks) and minimizes AV-log artifacts through robust farthest-point sampling and Mask2Former-based view screening. Occlusion and truncation are detected via ray--box intersection in 3D cuboid space, and crops undergo canonical projection for consistent conditioning. Crucially, near-duplicate frames are aggressively filtered to prevent adverse learning and maximize angular diversity.
SparseViewDiT leverages a DiT backbone adapted for variable input/output sequences, explicit camera geometry encoding (Plücker rays, extrinsics), and C-Radio image embeddings. Linear attention without absolute position encoding circumvents quadratic memory complexity, facilitating scalable high-resolution synthesis. Multiview outputs are processed via a ViT-L encoder and cross-attention decoder in Object TokenGS, decoupling Gaussian count from image resolution and enabling instance-level asset control.
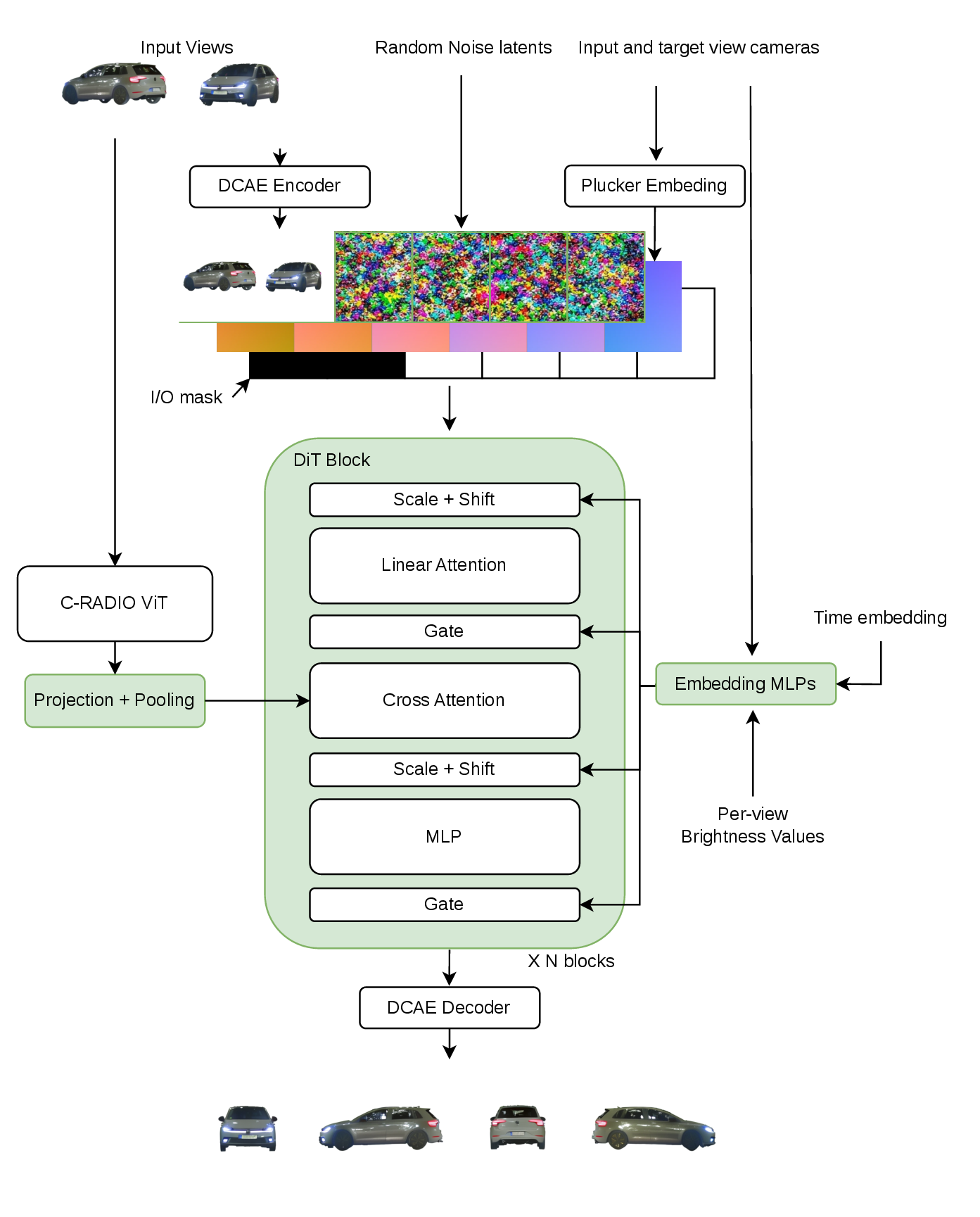
Figure 2: SparseViewDiT schematic for sparse-view-conditioned multi-view generation.
Training, Data Curation, and Self-Distillation
The training regime exploits a hybrid mixture: curated object crops from in-the-wild NCore AV logs, synthetic domain-specific 3D renders (vehicles, pedestrians), and Objaverse assets rendered with real-world camera distributions. Strong augmentations (occlusions, camera perturbations, brightness shifts) and Mask2Former+VLM filtering ensure real/synthetic mixture integrity and robust learning. The multi-stage pipeline comprises general-domain pretraining, in-domain post-training, and fine-tuning on self-distillation sets where high-quality predictions are synthesized from their degraded counterparts.
Synthetic data lifting is trained exclusively on pixel-precise synthetic renders, with random camera/fov selection, grid distortion, and background randomization reducing sim-to-real domain gap.
Benchmarking and Quantitative Results
Asset Harvester is evaluated on the NuRec AV Object Benchmark, designed for both ground-truth held-out and realistic, harder-in-the-wild splits across VRU pedestrians, riders, commercial and consumer vehicles, and miscellaneous objects. Metrics include classical PSNR, SSIM, LPIPS, as well as semantic ED-R and part-aware ED-P distances derived from DINOv3 patch embeddings. In settings lacking explicit ground truth, preference rates are measured via GPT5.2-based pairwise image evaluations.
The model outperforms leading baselines (SAM3D, TRELLIS, Hunyuan3D) with single-view input across all classes, achieving higher PSNR (up to 22.69dB consumer vehicles), SSIM (0.869), lower LPIPS (0.137), and strongest embedding distances (ED-R: 0.083, ED-P: 0.231 for pedestrians). GPT5.2 preference rates exceed 75% against all peer methods in hard splits.

Figure 3: Qualitative results—single-view input, mask extraction, reconstructed 3D asset (front/back)—across diverse AV classes (sedan, bus, trailer, trash bin, truck, rider, pedestrian).

Figure 4: Visual comparison against contemporary image-to-3D baselines, evaluated with both estimated and parsed camera parameters.
Inference is efficient, with end-to-end pipeline runtimes of 10.95 s (A100) and 5.78 s (H100) per asset, and Gaussian lifting performed in seconds via feedforward prediction. Ablation studies demonstrate that while single-view conditioning yields plausible assets, the inclusion of more views further sharpens geometry and texture.

Figure 5: Ablation: comparison of single-view versus four-view input—additional views yield improved sharpness and detail.
Practical Extensions and Qualitative Analysis
Asset Harvester generalizes robustly to out-of-distribution edited images and supports asset-driven animation pipelines for pedestrians. Object insertion and harmonization into NuRec-reconstructed scenes is achieved using DiffusionHarmonizer, eliminating artifacts and improving photometric consistency for simulation.

Figure 6: Out-of-distribution image editing and 3D asset generation from Nano Banana-edited AV images.

Figure 7: Pedestrian animation: A-pose conversion, Gaussian asset rigging, and motion generation through SOMA/GEM/Kimodo.

Figure 8: Scene insertion and harmonization: asset reintegration into NuRec with DiffusionHarmonizer for shadow and lighting coherence.
Implications and Future Prospects
Asset Harvester bridges the operational chasm between neural scene reconstruction and agent-driven closed-loop AV simulation. By solving the sparse-observation completion problem, the pipeline enables upstream scenario manipulation, SDG, and long-tail asset generation directly from logged data. The explicit separation of multiview generative synthesis and feedforward Gaussian lifting ensures scalability and domain robustness. The approach enables practical simulation deployment, asset library expansion, and facilitates downstream tasks such as novel-view synthesis, relightable asset creation, and interactive editing.
Asset Harvester implies that future log-to-asset pipelines may be further integrated with route prediction, scene graph construction, and semantic annotation for fully automated AV testing environments. The methodology also motivates research in robust multi-modal sensor fusion, geometry-conditioned generative modeling, and efficient asset optimization for domain transfer.
Conclusion
Asset Harvester constitutes a rigorous, scalable pipeline for extracting simulation-ready 3D assets from real-world AV logs in sparse, noisy, and limited-angle conditions. Through system-level design integrating robust data curation, geometry-consistent diffusion synthesis, and efficient feedforward Gaussian lifting, the model surpasses prior image-to-3D baselines across all metrics and object classes. Its practical performance, adaptability to in-the-wild conditions, and close integration with AV simulation systems suggest broad utility for scalable asset generation and automated simulation scenario creation.