- The paper presents a novel two-stage reward model that optimizes candidate selection across formulation and solution stages for enhanced pipeline success.
- It employs automated data collection using execution feedback and direct preference optimization to eliminate the need for manual annotations.
- Experimental results across optimization tasks and GSM8K show significant improvements in execution rate and problem-solving accuracy.
Pipeline-Adapted Reward Models for Multi-Stage LLM Pipelines
Introduction
The work introduces PARM (Pipeline-Adapted Reward Model), a modular reward-modeling framework for multi-stage LLM-based pipelines. While reward models have been successfully leveraged in aligning LLMs with human preferences in single-step tasks via RLHF and decoding strategies, their adaptation to complex, multi-stage pipelines remains underexplored. The paper focuses on code generation pipelines for combinatorial optimization, using a two-stage paradigm: formulation generation (translating a language description into a formal mathematical specification) and solution generation (producing executable code from the formulation). The authors identify and address the key challenge that stage-wise reward models, trained solely on local outputs, may not align with overall pipeline-level success due to downstream dependencies.
Pipeline Framework and Reward Model Integration
PARM structures LLM-based problem-solving pipelines into modular stages with independent generators and reward models for each stage. The process, exemplified in Figure 1, begins with a Formulation Generator that creates candidate formalizations of the input, followed by a Solution Generator that converts the selected formulation into executable code. At both stages, best-of-N sampling is performed, with reward models scoring each candidate based on its utility for downstream pipeline success.
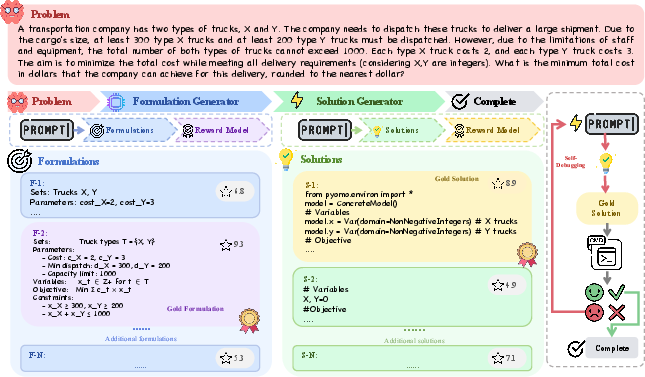
Figure 1: Workflow of PARM on an optimization problem: initial problem decomposition, multiple candidate generations per stage, and reward-guided selection at each step.
In contrast to single-stage approaches, pipeline-level reward assignment is achieved by aligning supervision with task-level verification outcomes—i.e., formulator or code outputs are labeled positive if they ultimately yield a correct solution post-execution. This coupling, illustrated in Figures 1 and 3, differs from conventional approaches where reward modeling does not consider cross-stage effects or the propagation of local errors.
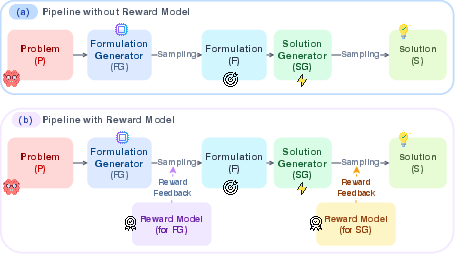
Figure 2: Without reward modeling, candidate selection is unguided. With reward models, outputs are scored, allowing preferential selection of higher-quality results.
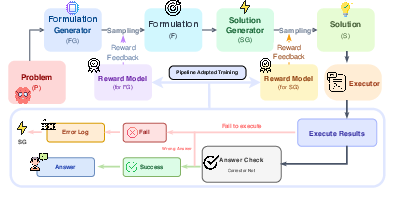
Figure 3: Reward models score both formulation and solution candidates; execution results feedback into reward model training, closing the adaptation loop.
Pipeline-Adapted Training and Automated Data Collection
The central methodological contribution is the pipeline-adapted reward model training (PAT). Instead of training reward models with manual annotation or human preferences, PARM automatically constructs supervision by tracing which candidates in each stage eventually contribute to correct final execution. For the formulation stage, a candidate is labeled positive if any of its downstream solutions is correct. For the solution stage, candidates are labeled by direct task-level correctness (e.g., execution and optimality). Figure 4 details the reward flow and fully-automated data collection mechanism.
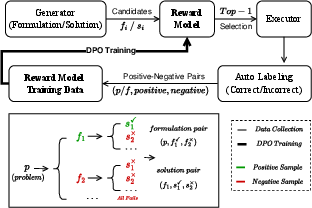
Figure 4: Automated assembly of reward model training data using task-level execution feedback.
Reward models are updated with direct preference optimization (DPO) objectives, where positive/negative preference pairs are constructed from pipeline execution logs. This eliminates the need for domain-specific annotation and allows for scalable reward model adaptation as pipeline domains or stages change.
Experimental Results
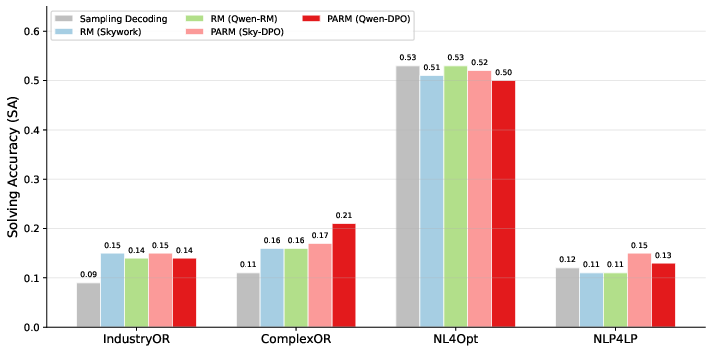
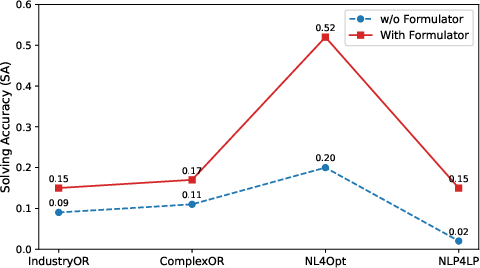
Comprehensive experiments are conducted across four public combinatorial optimization datasets (IndustryOR, ComplexOR, NL4Opt, NLP4LP) and with strong open-source LLMs (Qwen, DeepSeek series) as both formulator and coder. Performance is assessed by execution rate (ER) and solving accuracy (SA).
Key findings:
Theoretical and Practical Implications
PARM demonstrates that pipeline-adapted reward models—trained solely on automated, execution-based feedback—can robustly guide modular LLM-based multi-stage systems. This regime scales with available compute, not human annotation, and is directly compatible with plug-and-play LLM agents or reward models specialized for other domains. The greedy best-of-N scheme makes inference tractable (linear in the number of stages), but candidate diversity and data imbalance due to cross-stage credit assignment remain open scaling challenges for deeper (k>2) pipelines.
The framework is not inherently tied to code generation or mathematical optimization: its design principles apply wherever (i) tasks decompose naturally, and (ii) task-level correctness is objectively verifiable (e.g., automated programming with test pass rates, structured Q&A, simulation-based evaluation).
Limitations and Future Work
- The current empirical scope is confined to two-stage pipelines with objective correctness verification. As the number of stages grows, data sparsity for early-stage positive labels increases combinatorially, likely necessitating intermediate reward shaping or hybrid supervision.
- Open-domain tasks or those lacking executable correctness criteria may require partial manual annotation or the development of proxy verifiers.
- Integrating advanced search strategies (MCTS, curriculum search), investigating online or few-shot reward model adaptation, and pushing towards interpretable or human-in-the-loop reward signals are active future directions.
Conclusion
PARM provides a principled, empirical and practical framework for multi-stage reward model adaptation, leveraging the modularity and interpretability of LLM pipelines. Automated reward signal collection and direct preference learning yield robust, scalable performance improvements across optimization and reasoning tasks. The methodology positions pipeline-guided reward adaptation as a foundational building block for more general, reliable, and extensible multi-component LLM systems.