- The paper introduces AQPIM, a novel framework that uses product quantization to aggressively compress KV activations, achieving up to 80% memory reduction with <2 point accuracy loss.
- It combines GPU prefill with HBM-PIM decoding to perform direct compressed attention, reducing GPU-CPU traffic by 90–98.5% and enabling up to 8.3× execution speedup.
- The framework boosts energy efficiency by up to 14.3× through hardware-conscious clustering and intra-row indirection, making scalable long-context LLM inference feasible.
AQPIM: Breaking the PIM Capacity Wall for LLMs with In-Memory Activation Quantization
Introduction and Motivation
The exponential growth in the deployment of LLMs has underscored severe bottlenecks in memory capacity and bandwidth, especially as context windows scale toward hundreds of thousands or millions of tokens. Processing-in-Memory (PIM) architectures are promising for alleviating bandwidth issues by bringing computation closer to data. However, the KV (key-value) activation cache—whose size increases linearly with context length—frequently exceeds the practical on-chip memory capacity of even state-of-the-art PIM systems. Traditional methods such as offloading, sparse attention, or coarse quantization approaches are fundamentally mismatched with PIM’s need for strict data locality and limited computational flexibility.
As illustrated, existing PIM architectures cannot linearly scale to meet KV cache requirements for long-context LLMs due to prohibitive area and cost per die (Figure 1).
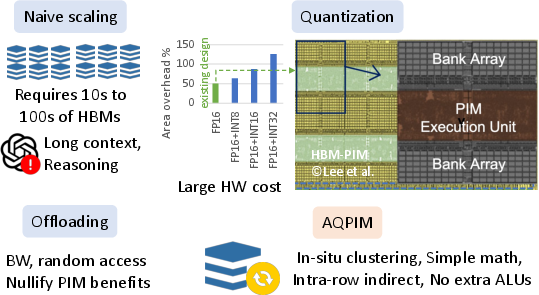
Figure 1: Scaling challenges of existing PIM designs for LLMs. The die photo is taken from the HBM-PIM paper.
This work introduces AQPIM, a PIM-specialized activation quantization and attention framework, building on product quantization (PQ) to aggressively compress the KV cache, enable computation directly on compressed data, and exploit PIM’s massive internal bandwidth without the need for costly new hardware units. This approach resolves the fundamental “capacity wall” of PIM-accelerated LLM inference.
Locality and Structure in LLM Activations
A critical observation is that, unlike statically trained weight matrices, KV activations generated by LLMs during inference exhibit substantial context-dependent structure, with pronounced locality and clustering. Dimensionality reduction (UMAP) shows that KV vectors for realistic input tasks form highly localized and non-uniform clusters, making them amenable to clustering-based quantization (Figure 2).
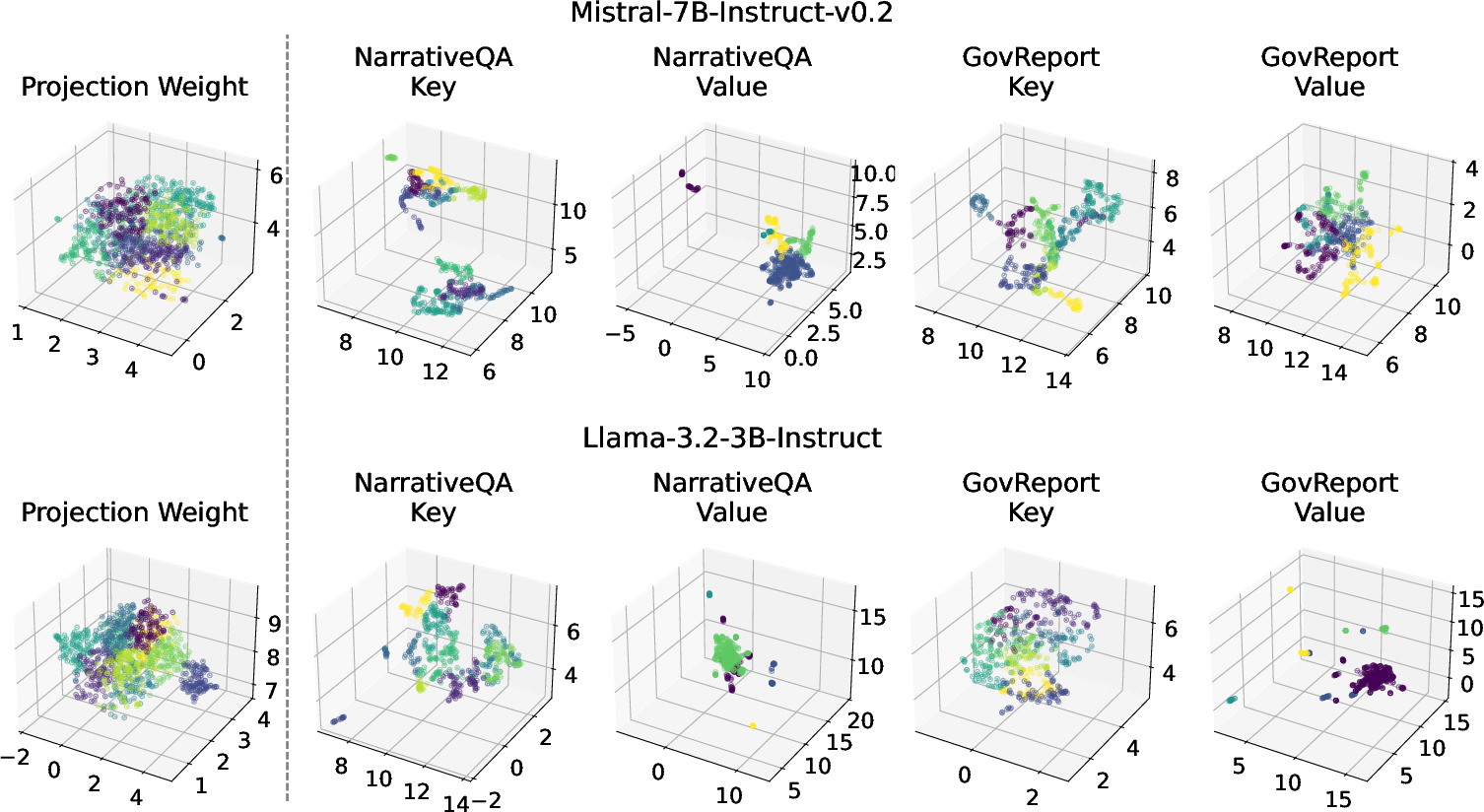
Figure 2: Locality within the projection weights and KV cache visualized by UMAP, demonstrating activation redundancy and cluster structure absent in weights.
This property underpins AQPIM’s choice of PQ over standard quantization approaches, as cluster-based representations closely fit the true activation distribution, permitting high compression ratios with limited accuracy sacrifice.
AQPIM Framework: Algorithm-Hardware Co-Design
Overview
AQPIM orchestrates a synergistic collaboration between GPU (for compute-intensive tasks) and HBM-PIM (for bandwidth-bound processes). During the “prefill” phase, the GPU generates QKV tensors, while the PIM system offloads and compresses KV activations using PQ in parallel (Figure 3):
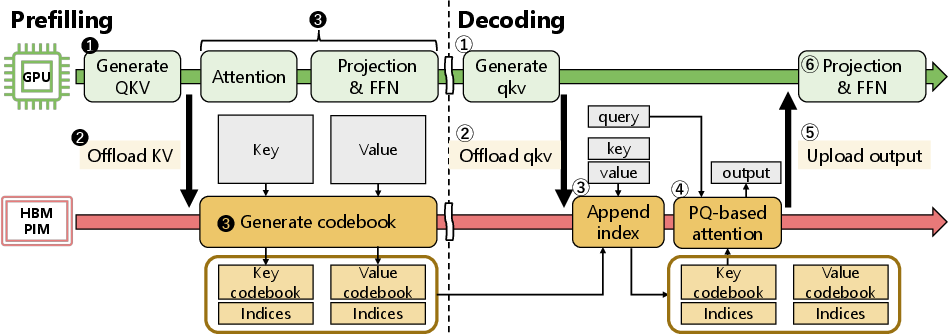
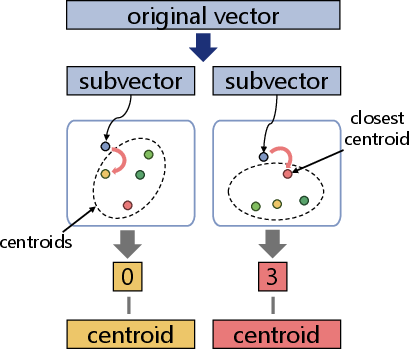
Figure 3: AQPIM execution flow during prefilling and decoding. GPU and HBM-PIM operate concurrently, hiding the codebook generation overhead.
During decoding, GPU-generated queries are sent to PIM, which performs attention on compressed, in-memory KVs, returning results without decompression.
Product Quantization for KV Compression and Attention
PQ partitions each vector (key or value) into multiple subvectors and clusters each subspace independently. Each token thus stores only a compact codebook index per subvector, not a full-precision value. During attention, the expensive GEMV operation is replaced by efficient table lookups and index-based additions, realized within the PIM architecture (Figure 4):
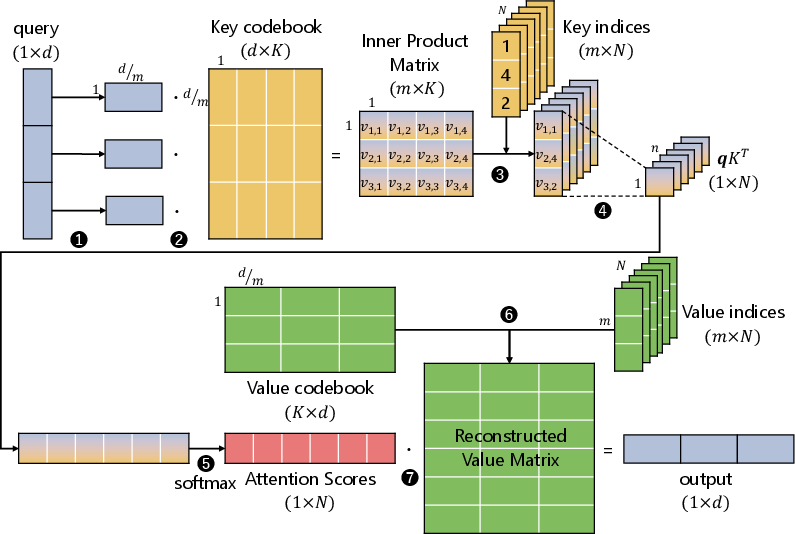
Figure 4: Computation flow of PQ-based attention—matrix multiplications are replaced by inner product lookups and summations using compressed representations.
Page-Aware Windowed Clustering and Intra-Row Indirection
To maintain high locality and avoid random DRAM row activations (a major PIM inefficiency), AQPIM employs page-aware windowed clustering, dynamically creating codebooks for context windows mapped to single memory rows. Hardware supports intra-row indirection for fast index-based retrieval, leveraging large row buffers and minimal additional logic (Figures 6, 8):
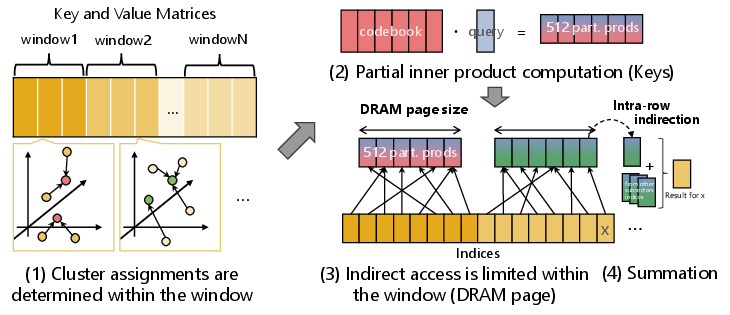
Figure 5: Page-aware windowed clustering splits the context into segments mapped to single DRAM pages for efficient lookup.
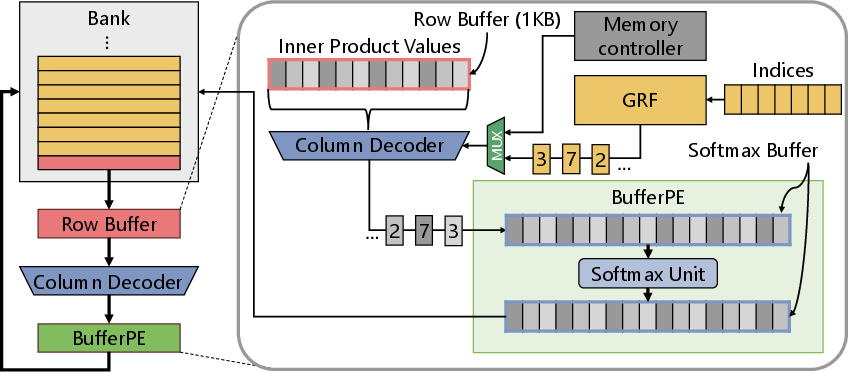
Figure 6: Intra-row indirection enables efficient, bank-local random access, leveraging the row buffer and column decoder.
Importance-Weighted Clustering and Channel Sorting
To further limit accuracy loss under strong compression, AQPIM incorporates importance-weighted k-means for codebook generation. Token importance is estimated from attention weights, biasing centroids toward high-impact activations. Additionally, a channel sorting preprocessing aligns subvectors by cosine similarity, reducing per-subvector quantization error.
Architecture and Data Mapping
AQPIM builds on multi-bank, multi-head HBM-PIM topologies. Each attention head is mapped to a distinct HBM die; each subvector group is mapped to a separate bank. Bank-proximate PEs handle lightweight computation (distance, reduction), while die-level BufferPEs tackle data-intensive steps (e.g., softmax). Data flow and allocation are strictly designed to minimize inter-bank/die traffic and leverage inherent parallelism (Figure 7, Figure 8):
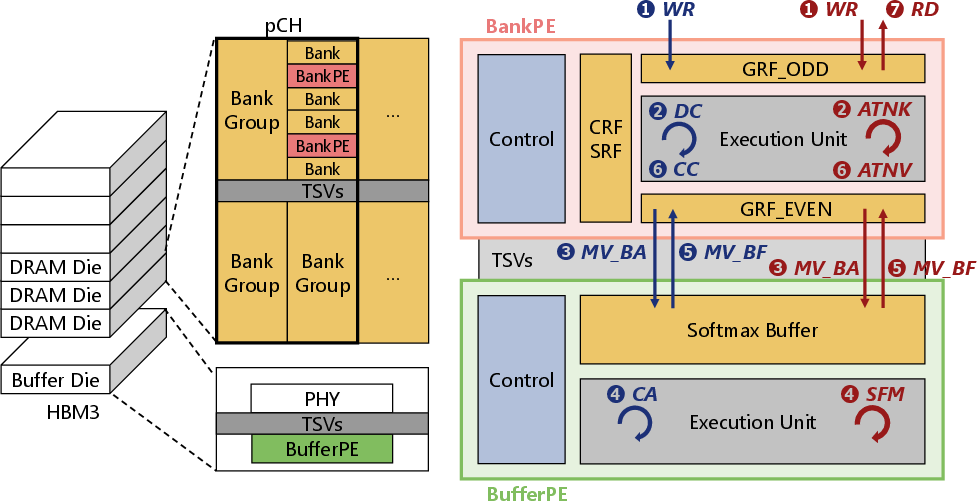
Figure 7: AQPIM architecture and dataflow. BankPEs and BufferPEs divide workload for codebook generation and attention computation.
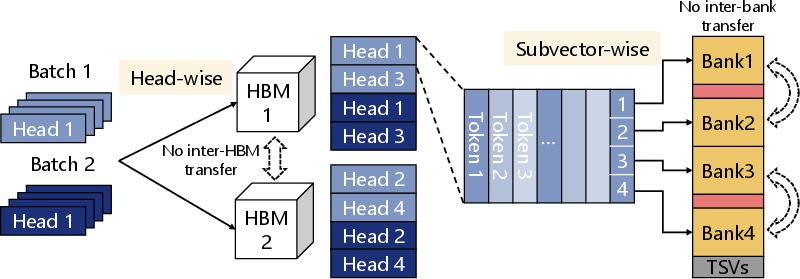
Figure 8: Data mapping assigns separate heads to HBMs and subvectors to banks, maximizing PE utilization and minimizing movement.
Experimental Results
Compression-Accuracy Tradeoff
On diverse LLM benchmarks (LongBench, Mistral-7B, Llama-3.2-3B), AQPIM consistently achieves substantially higher compression ratios at a given accuracy than baselines, maintaining <1–2 point accuracy loss with ∼80% memory reduction (Figure 9). This level of compression would be infeasible with prior uniform quantization or token eviction methods at comparable fidelity.
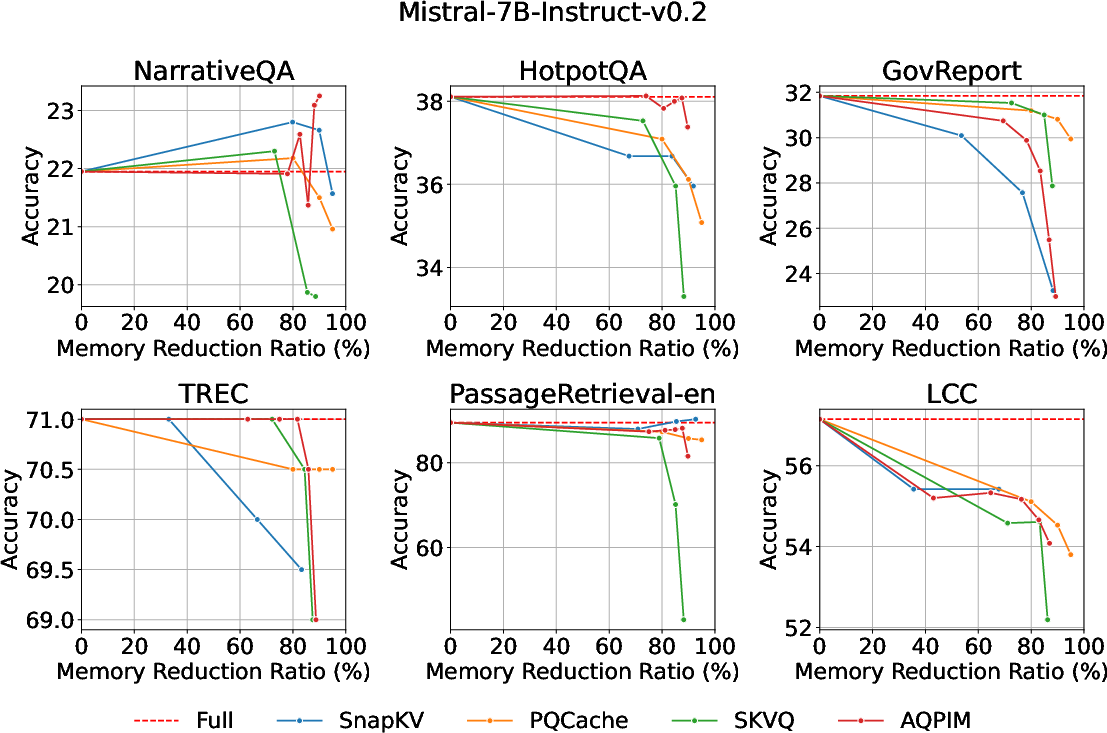
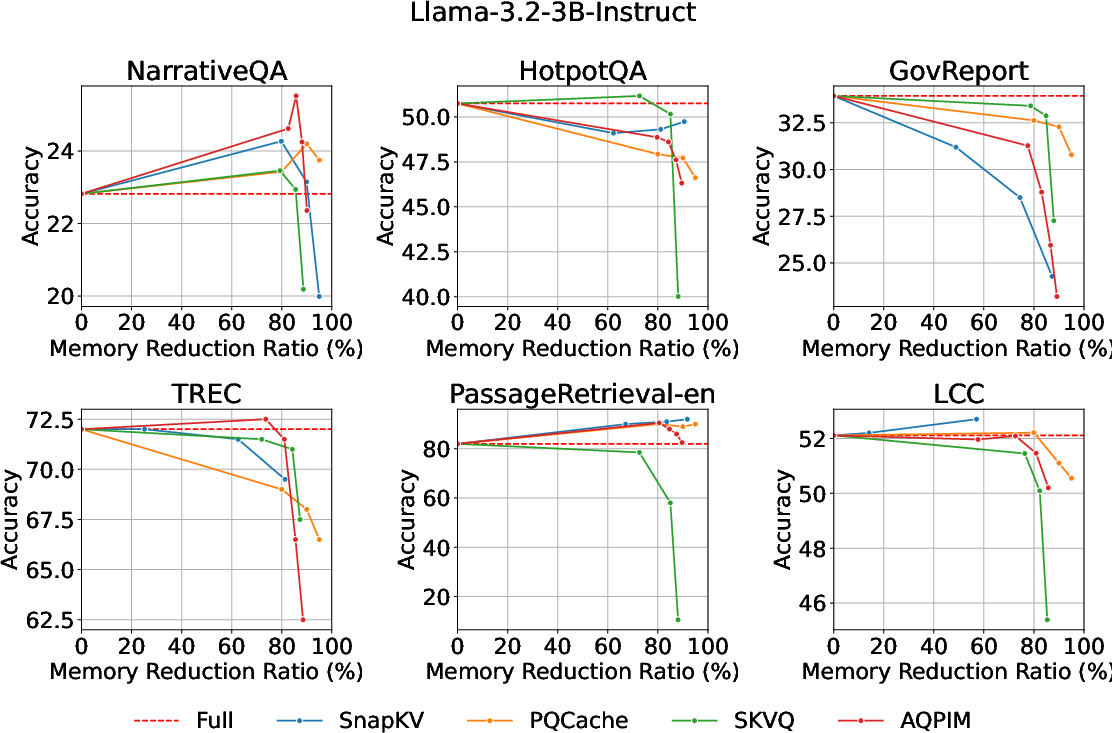
Figure 9: Memory reduction ratio vs. accuracy; AQPIM achieves superior fidelity-utility balance across tasks.
Ablation studies confirm that both importance-weighted clustering and subvector channel pre-sorting offer significant gains in high-compression regimes over standard PQ.
System-level simulation against GPU+HBM, AttAcc!, and offloading-based designs demonstrates that AQPIM’s PQ compression and direct compressed attention pipeline enable:
- Drastic reduction (90–98.5%) in GPU-CPU traffic, eliminating the dominant source of decoding latency.
- Overall 2.3× to 8.3× execution speedup over prior PIM approaches and 3.4× over SOTA PIM when operating at high context and batch size (Figures 11, 12, 13).
- Up to 14.3× improvement in energy efficiency during decoding, due to reduced matmul operations and microarchitectural locality (Figure 10).
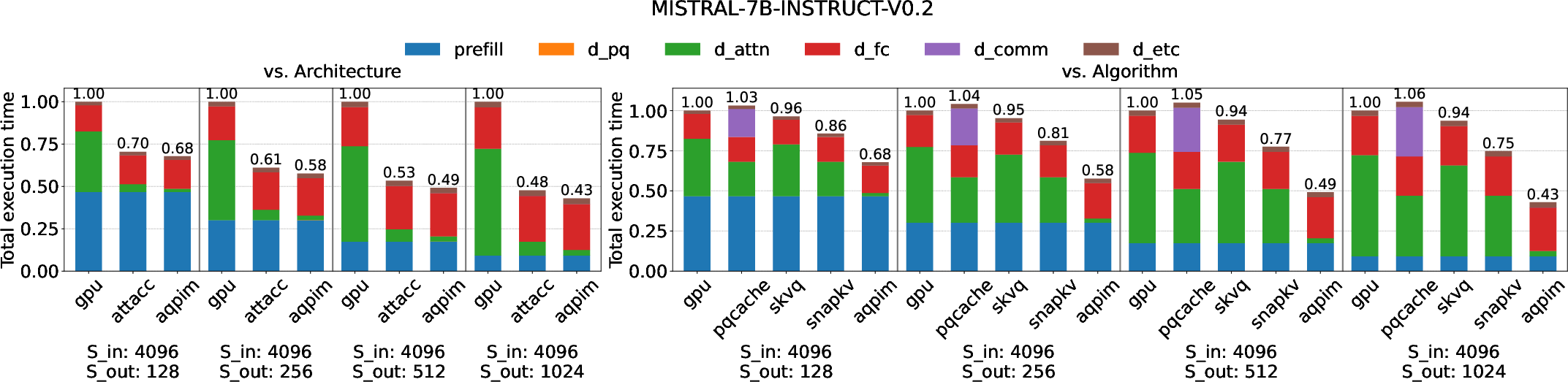
Figure 11: Normalized total execution time—AQPIM significantly lowers end-to-end latency, particularly for lengthy outputs.
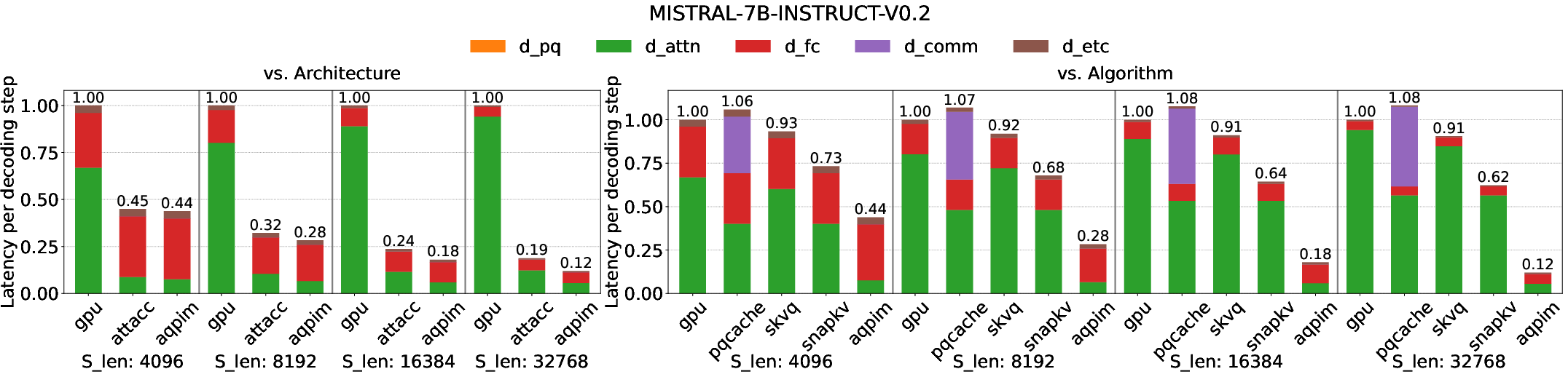
Figure 12: Normalized decoding time—AQPIM’s speedup over both PIM and non-PIM baselines rises as context length increases.
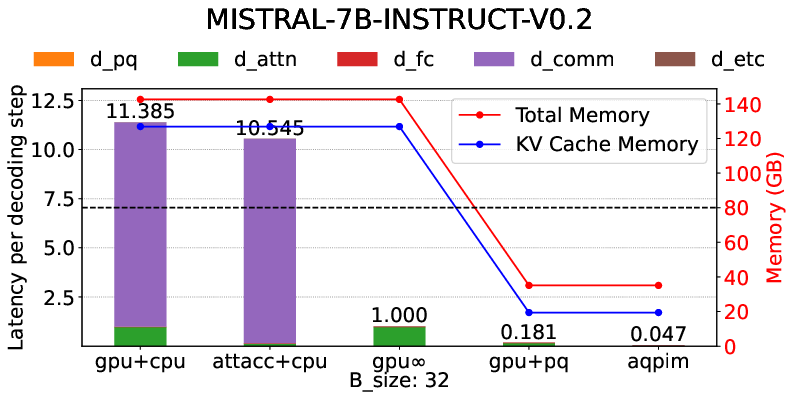
Figure 13: Decomposition analysis of decoding speedups—shows contributions from compression, communication reduction, and architectural optimization.
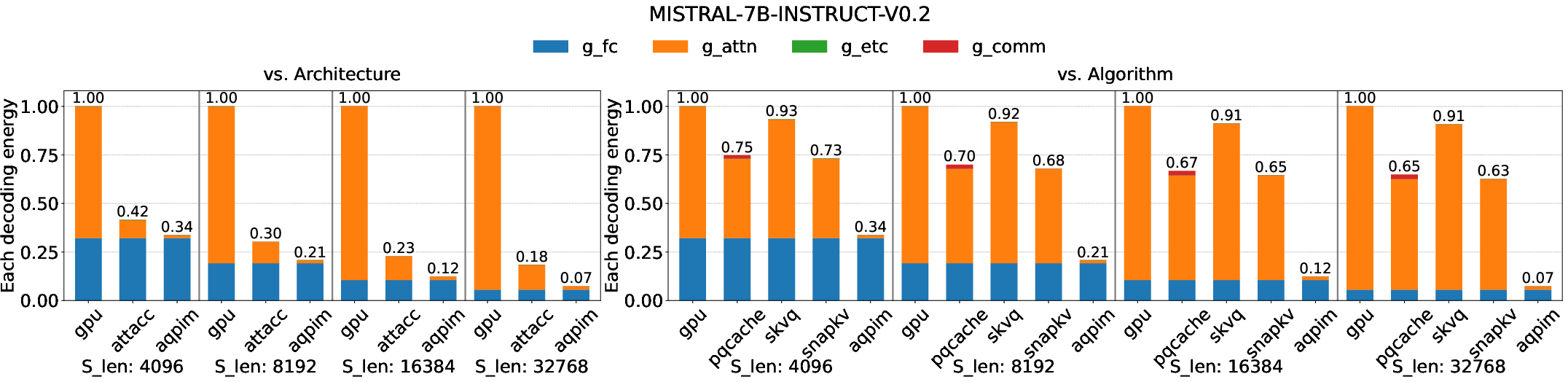
Figure 10: Energy per decoding step—AQPIM notably reduces “attention” component energy across baselines, especially for attention-heavy workloads.
Compression ratio can be flexibly tuned (Figure 14), offering a practical trade-off between speed, memory use, and accuracy, without hardware changes.
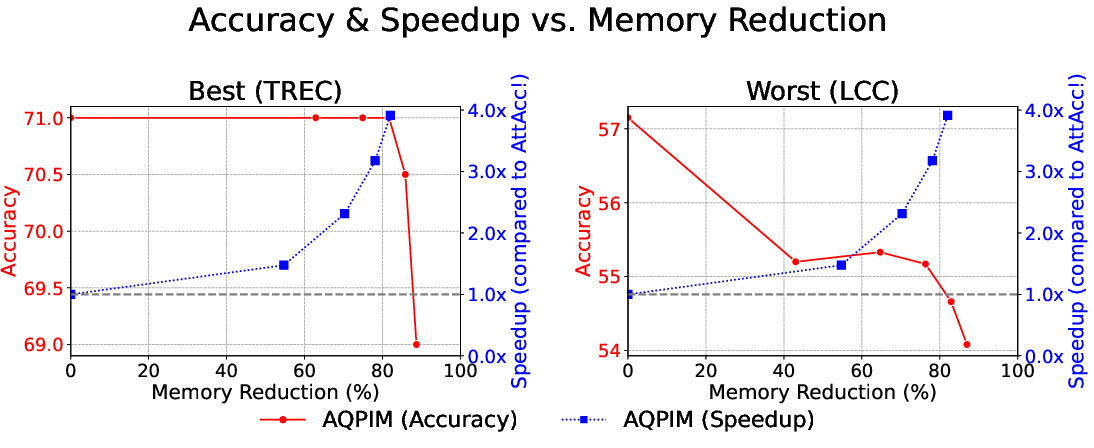
Figure 14: Speedup and accuracy as a function of memory reduction, showing graceful scaling across extreme compression levels.
Implications and Future Directions
This study demonstrates that activation-aware, PQ-based compression is uniquely suited to the constraints and strengths of PIM architectures for LLM inference. By leveraging structural activation locality, hardware-aware clustering, and minimal-area lookup datapaths, AQPIM breaks the scaling limit imposed by raw memory capacity. The co-design paradigm enables aggressive in-memory quantization while retaining the ability to execute end-to-end attention calculations on compressed KVs, eliminating the need for dequantization.
Practical implications include enabling economically viable, high-throughput LLM deployment for long-context tasks with much smaller PIM device counts per node. The methods generalize naturally to future hardware with even wider HBMs and deeper context requirements.
On the theoretical front, the results underline the value of dynamic, activation-aware quantization strategies—which adapt to input context and attention patterns—over generic, weight-based or calibration-only schemes. Integration with online PQ updates and more complex PIM control logic could further enhance adaptivity and efficiency.
Conclusion
AQPIM establishes a new foundation for scalable LLM inference in memory-centric architectures. Its activation quantization pipeline, rooted in PQ, importance-adaptive clustering, and intra-row indirection, enables practical execution of attention on highly compressed, latency-local KV caches. The resulting reductions in capacity, bandwidth, and energy requirements—validated across realistic hardware and challenging benchmarks—showcase a viable solution to the long-standing PIM “capacity wall” phenomenon.