- The paper introduces DSAINet, which decouples multi-scale temporal extraction from adaptive cross-scale integration using parallel convolution branches and attention mechanisms.
- It demonstrates consistent accuracy and F1 improvements across ten public datasets and five EEG paradigms, achieving superior performance with significantly reduced computational cost.
- The model ensures subject-independent decoding with interpretable neurophysiological saliency patterns, offering a scalable solution for real-time BCI applications.
DSAINet: Efficient Dual-Scale Attentive Interaction Network for General EEG Decoding
Motivation and Theoretical Contributions
Recent advances in EEG decoding have yielded high-performance models, but generalization across tasks and subjects within a unified architectural setting remains unresolved. Task-specific temporal structure in EEG requires models that can robustly capture heterogeneous dynamics without resorting to per-task architectural tuning. Existing CNN, attention-based, and hybrid architectures have improved modeling capacity, but they typically conflate the roles of temporal feature extraction and cross-scale information integration, resulting either in inefficient models or configurations biased to particular tasks. DSAINet addresses this limitation by designing a dual-scale architecture that explicitly decouples multi-scale temporal pattern extraction from adaptive, hierarchical attention-based integration mechanisms.
Architectural Design
DSAINet introduces several technical innovations in unified EEG decoding:
- Tokenization: Raw EEG is converted into compact spatiotemporal tokens using a lightweight CNN-based tokenizer that incorporates temporal convolutions and depthwise spatial processing, yielding embeddings with positional encoding.
- Dual-Scale Temporal Convolution: Tokens are input to two parallel convolution branches, tuned to capture fine and coarse temporal patterns via different kernel sizes and depths. Branches employ lightweight depthwise convolutions and group pointwise transformations, optimized via residual connections and learnable scaling, facilitating efficient long-range dependency modeling.
- Attentive Refinement and Interaction: Each branch undergoes intra-branch Transformer-style self-attention to emphasize scale-specific patterns, followed by a symmetric, bidirectional inter-branch cross-attention to explicitly integrate local and global features. This separation ensures effective refinement and fusion of task-relevant dynamics without overburdening individual attention modules.
- Adaptive Token Aggregation: Rather than averaging representations, aggregated features are formed using attention-weighted pooling based on learnable token importance, enhancing the discriminative capacity of the final representation.
Figure 1: DSAINet encodes raw EEG into shared tokens, models fine/coarse-scale temporal patterns via dual branches, applies intra-/inter-branch attention, and uses adaptive token pooling for final classification.
This design paradigm is empirically shown to support robust, subject-independent decoding across highly variable datasets while maintaining strict parameter and architectural consistency.
Comparative Analysis with State-of-the-Art
A structured evaluation across ten public datasets, spanning five downstream EEG paradigms—including motor imagery (MI), mental disorders, neurodegenerative disease, mental workload, and cognitive attention—demonstrates the universal applicability and robustness of DSAINet. The model is benchmarked against 13 established baselines, including DeepConvNet, EEGNet, multiple attention-enhanced CNNs, and modern CNN-Transformer hybrids such as Conformer, DBConformer, and Deformer.
Tables of results indicate consistent performance leadership in both accuracy and weighted F1 across all settings, notably delivering:
- Up to 2.03% and 1.56% absolute improvements in ACC and F1 on BCIC-IV-2a and Zhou2016, respectively.
- Superior cross-dataset stability, including small-channel scenarios (BCIC-IV-2b), large-cohort MI (OpenBMI, PhysioNet-MI), and disorder/cognitive paradigms (Mumtaz2017, ADFTD, Shin2018), where DSAINet outperforms or ties the best competitor in every instance.
Notably, DSAINet applies identical hyperparameters on all datasets, contrasting with baselines that typically require task-specific parameterization or design (2604.18095).
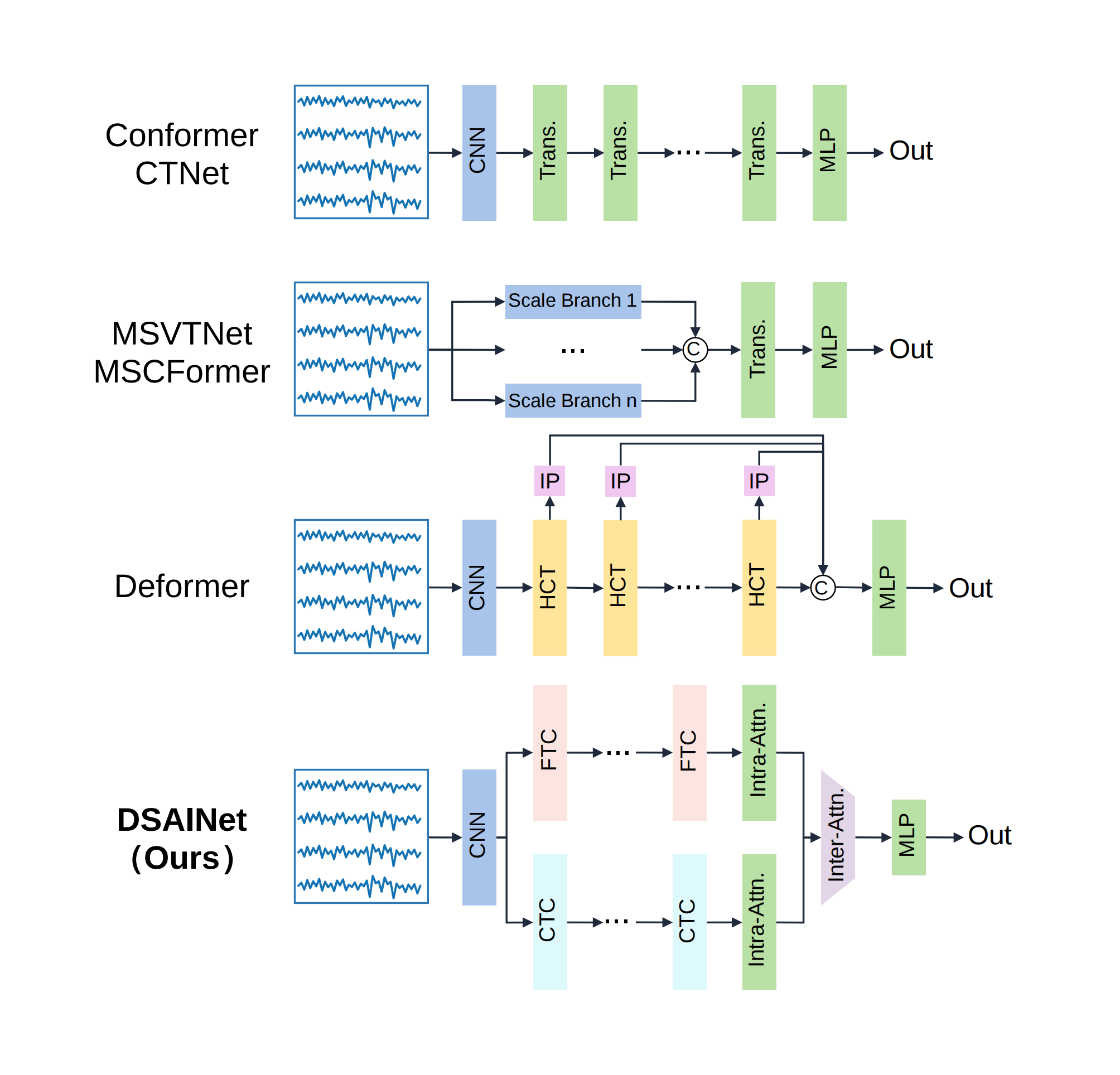
Figure 2: Side-by-side architectural summary of existing CNN-Transformer hybrid architectures versus DSAINet.
Ablation and Sensitivity Analyses
A set of ablation studies reveal that all major components—positional embeddings, both fine and coarse branches, intra-branch and inter-branch attention, and adaptive aggregation—contribute meaningfully to performance. Removing either attention operation or reducing depth in convolution blocks or attention layers uniformly degrades classification. Two convolutional blocks per temporal branch and a single attention layer per module are found optimal for broad generalization, underscoring the computational and sample efficiency of the design.
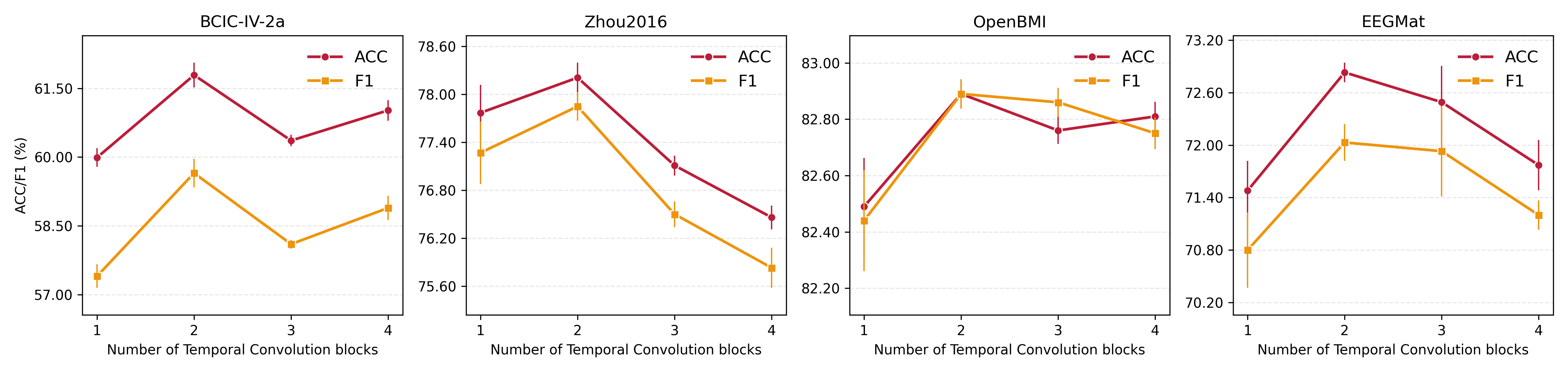
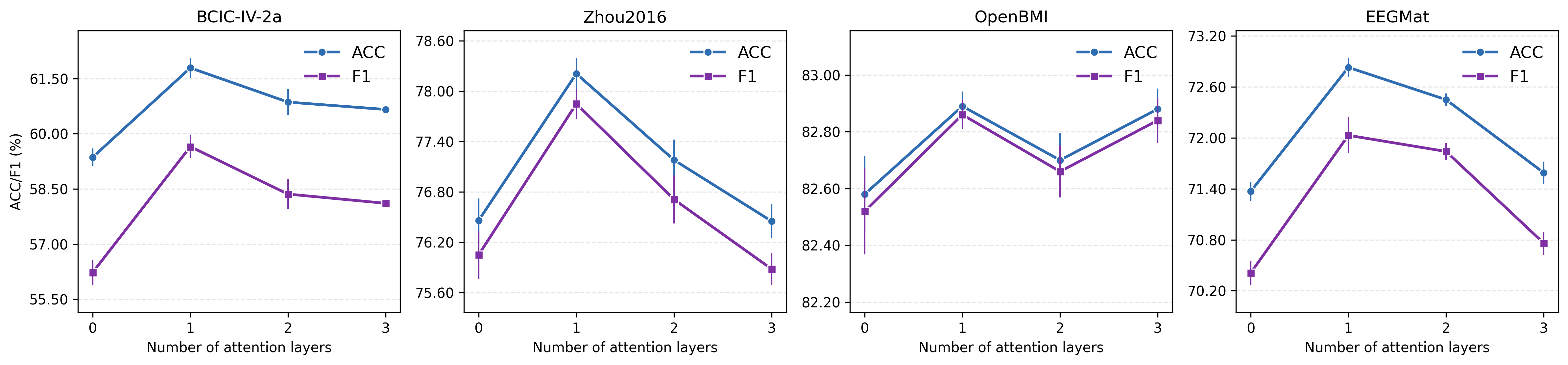
Figure 3: Model performance shifts as a function of convolutional block count (top row) and attention layer depth (bottom row), demonstrating stability and efficiency at moderate depth.
Segment length sensitivity experiments, crucial given varying temporal context across EEG tasks, show DSAINet maintains strong performance over a wide window range, further supporting the utility of its multi-scale abstraction.
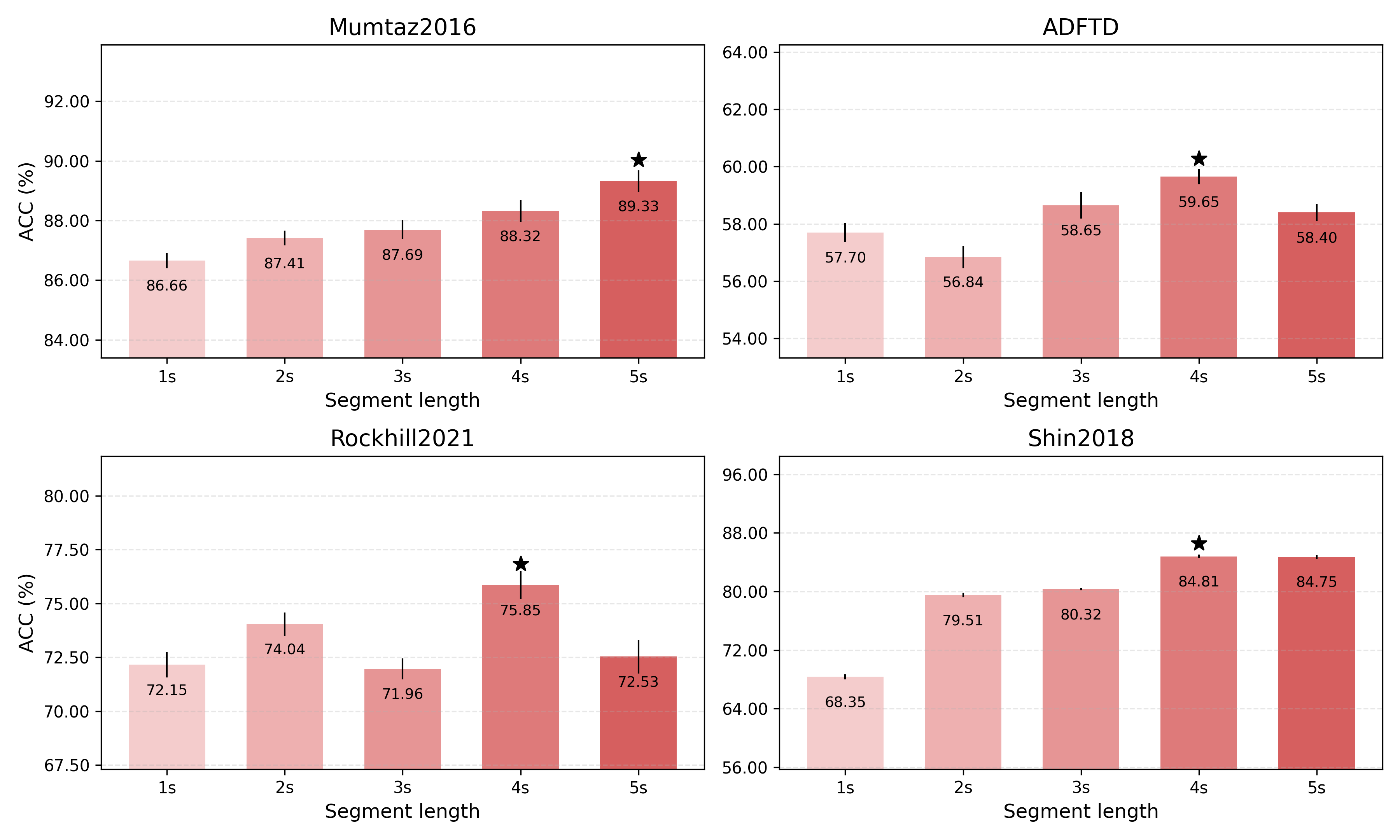
Figure 4: Classification accuracy vs. input segment length for four non-MI datasets, showing robustness to segment duration.
Accuracy-Efficiency Trade-off
Resource efficiency is critical for scalable or real-time BCI systems. DSAINet demonstrates significant computational advantages, requiring orders-of-magnitude fewer parameters (~77K) and achieve lower multiply-accumulate (MAC) cost than baseline hybrids, often at substantially higher accuracy. For instance, on PhysioNet-MI, DSAINet exceeds Deformer by 0.5% ACC while reducing parameters by ~34× and MACs by ~8×.
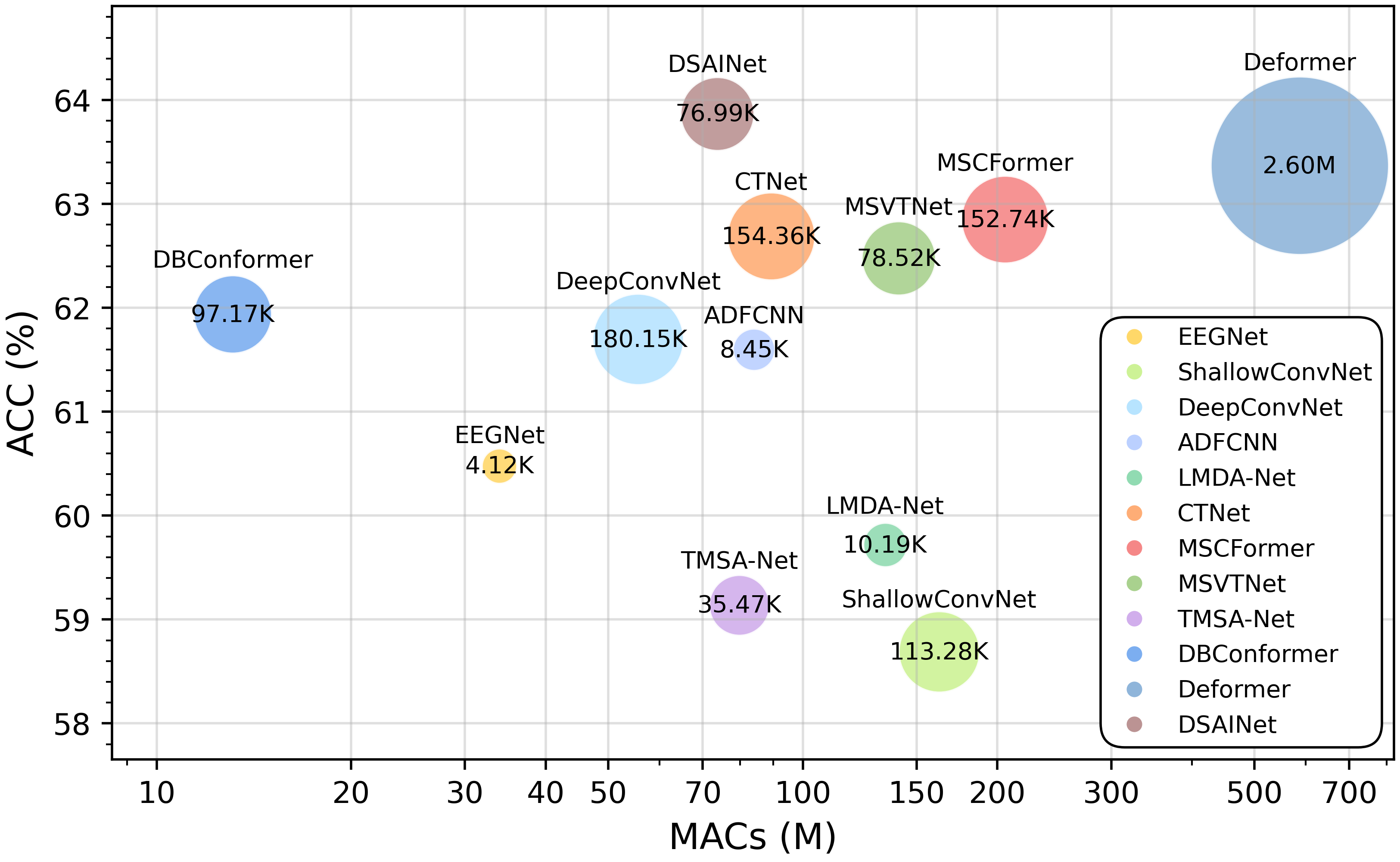
Figure 5: DSAINet achieves superior accuracy with a substantially reduced parameter and computational budget compared to baselines on the PhysioNet-MI dataset.
Interpretability: Saliency and Attention Patterns
A key practical objective is physiological interpretability of network predictions. Saliency mapping across tasks reveals that DSAINet redistributes attention in a neuroanatomically and task-consistent manner: for MI, sensorimotor regions dominate; for affective and neurodegenerative disorder, frontal and posterior differences emerge; for workload and attention paradigms, relevant frontal-parietal patterns are observed. This convergence on physiologically plausible features underscores the biological validity of the learned representations.
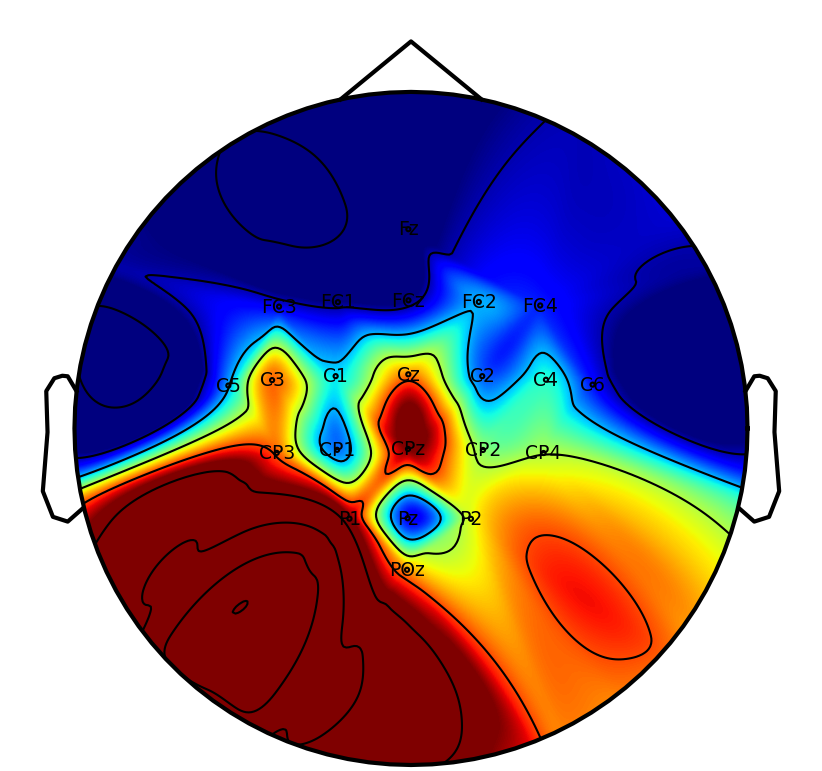
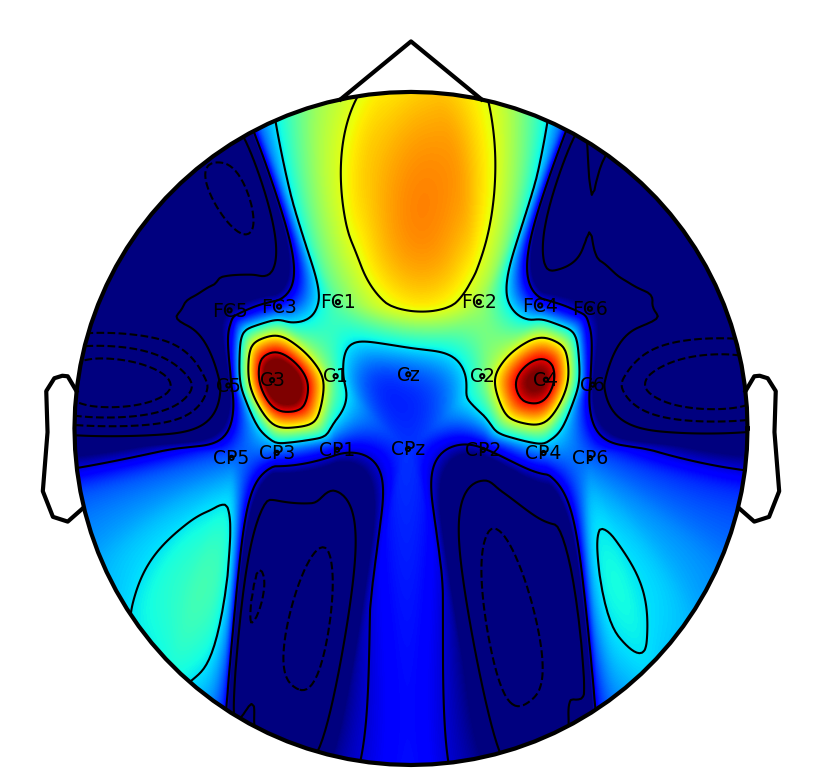
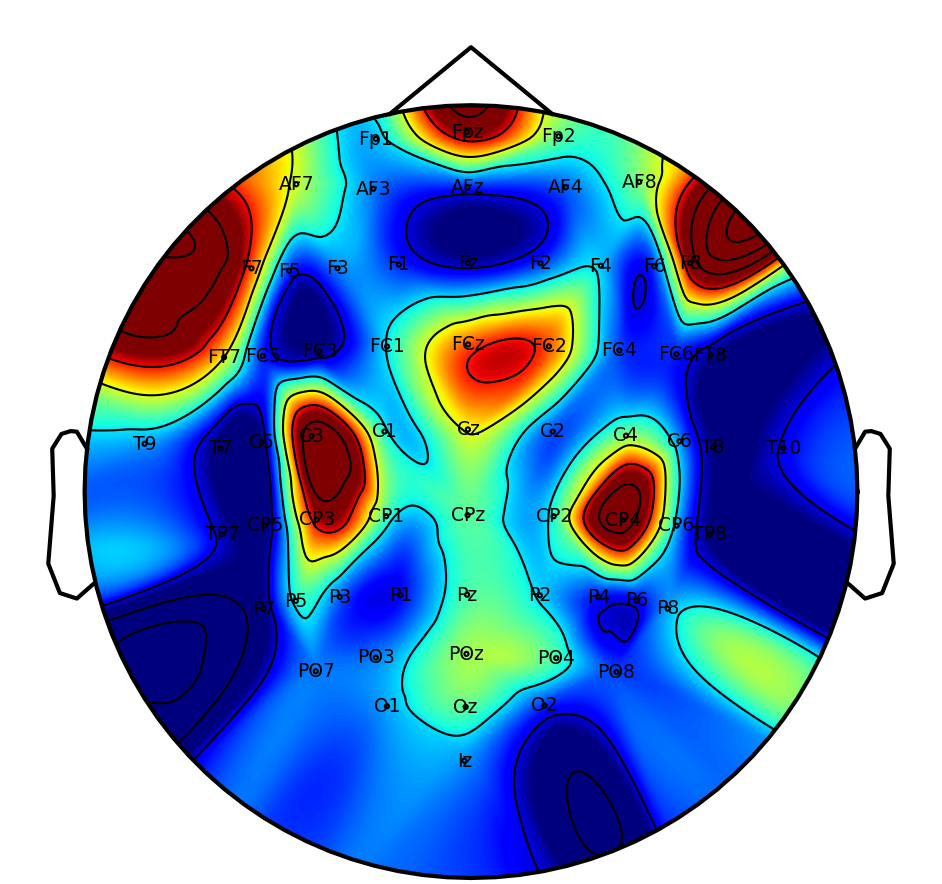
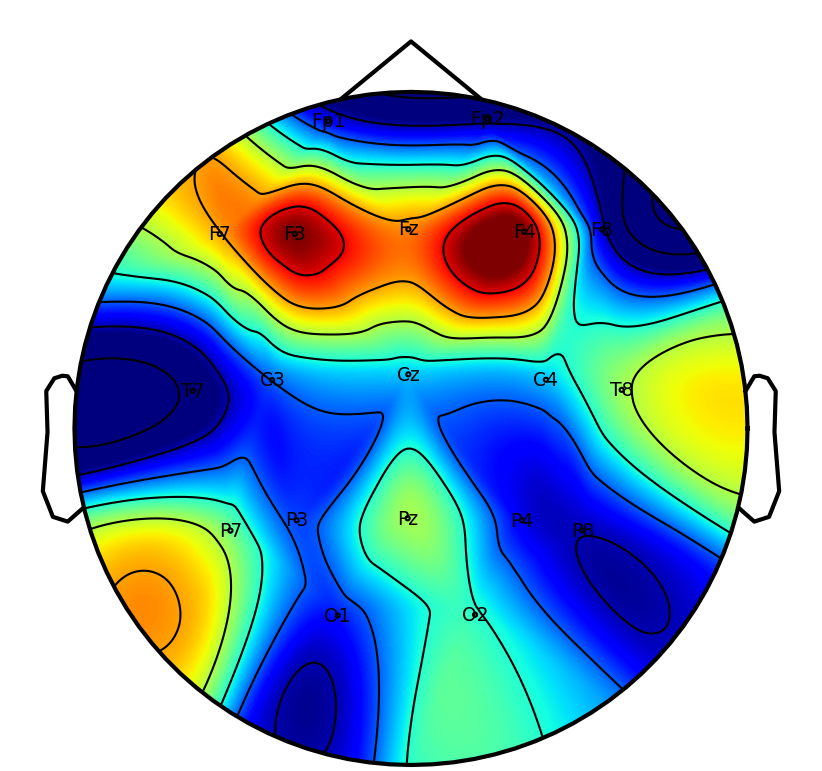
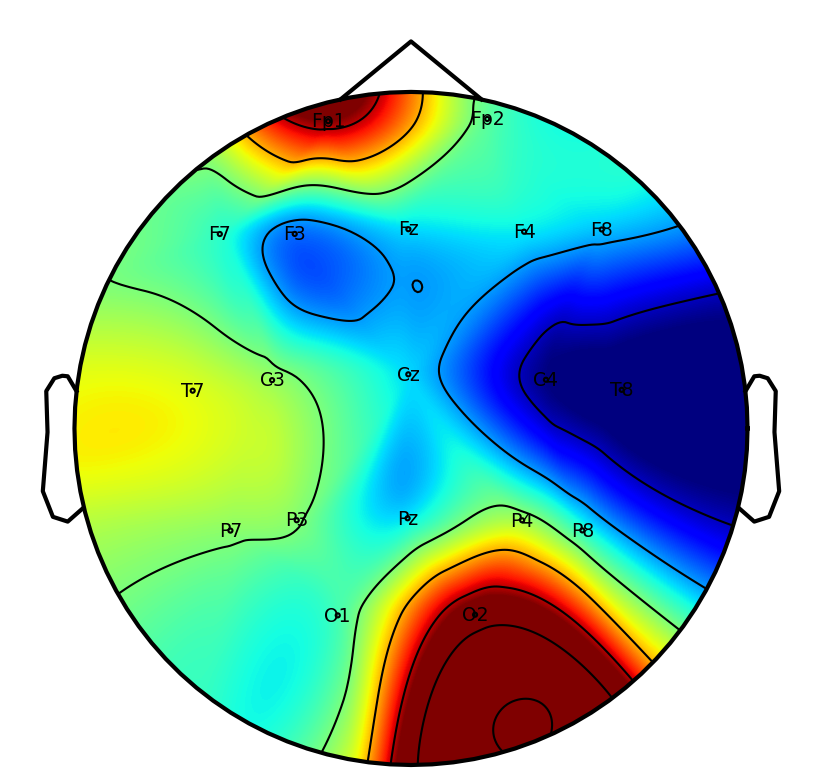
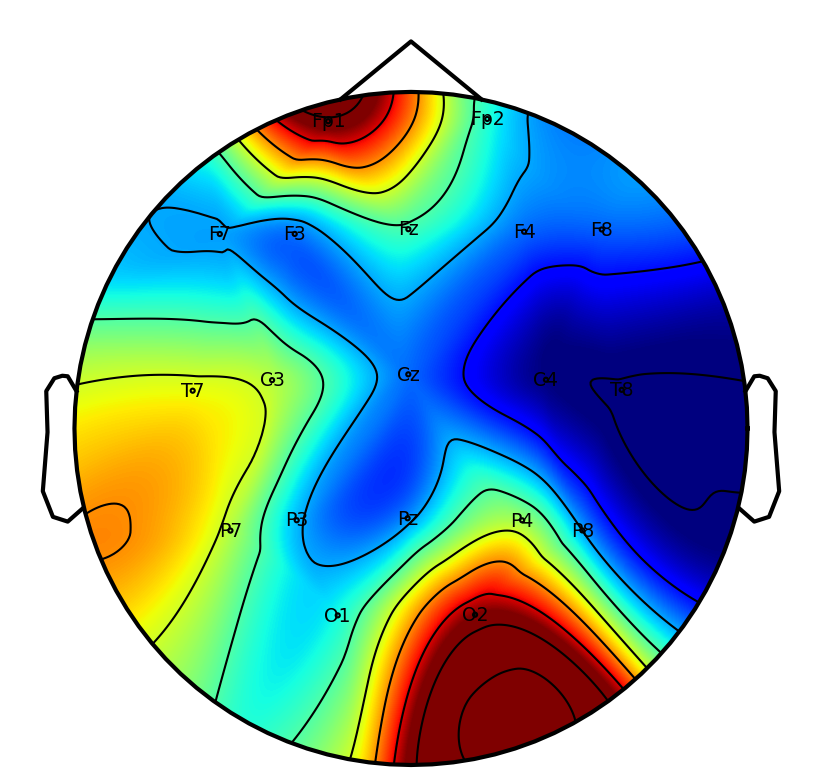
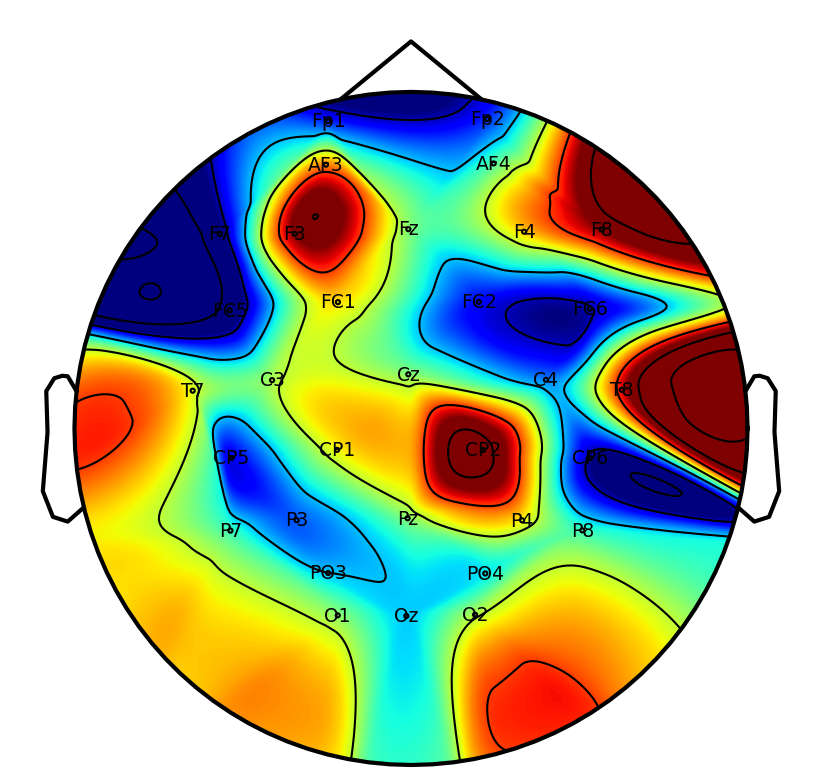
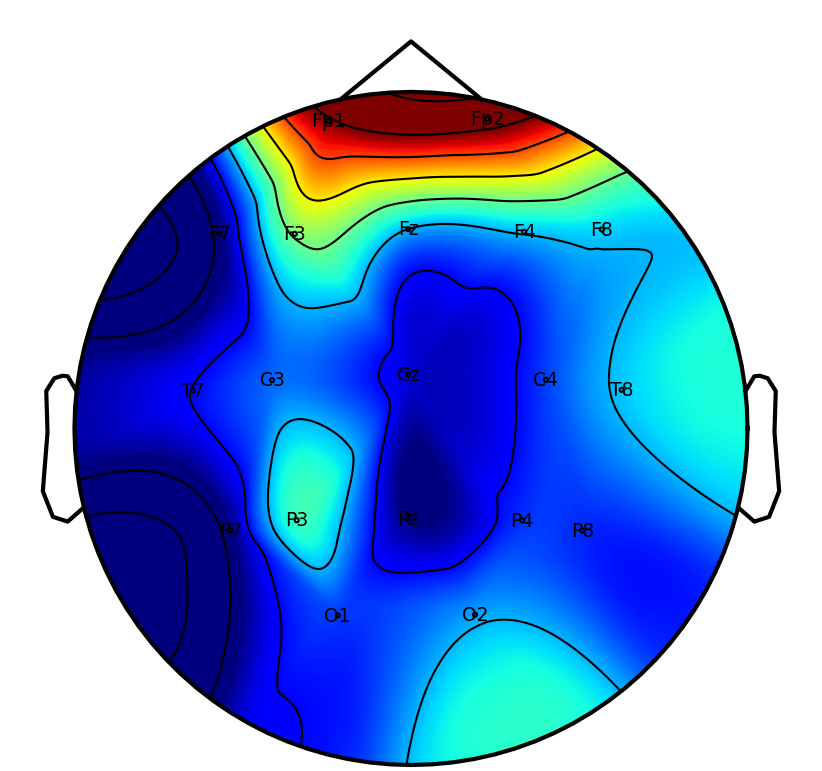
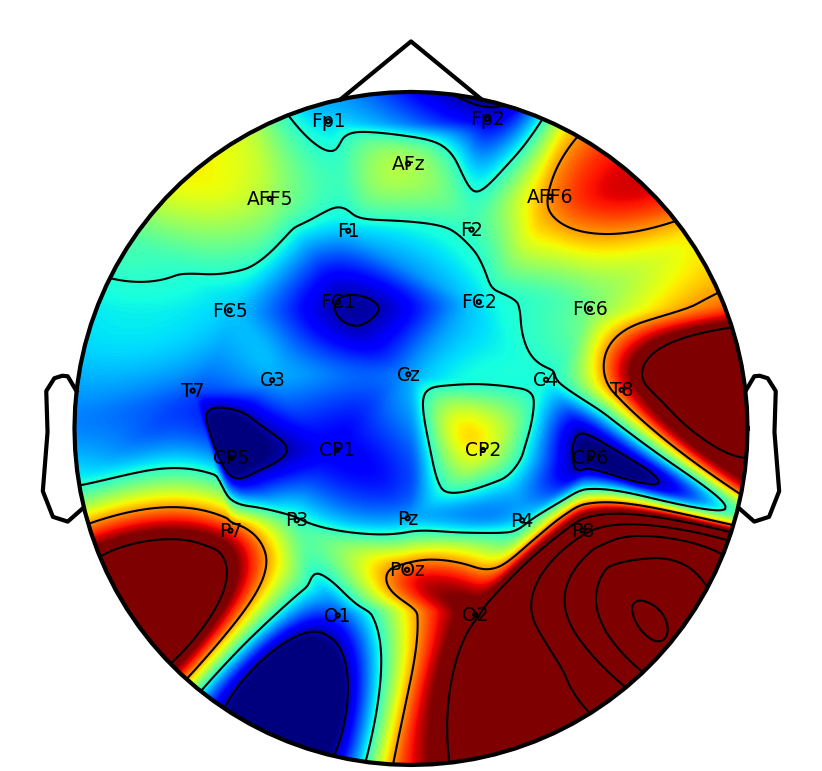
Figure 6: Saliency maps illustrate dataset/task-specific spatial-temporal focus, supporting interpretability and neurophysiological alignment.
Furthermore, analysis of learned attention weights demonstrates dataset-adaptive yet structured intra- and inter-branch interactions, confirming the distinct but complementary roles of both attention mechanisms: intra-branch attention sharpens scale-specific information, while inter-branch attention promotes cross-scale fusion based on task demands.
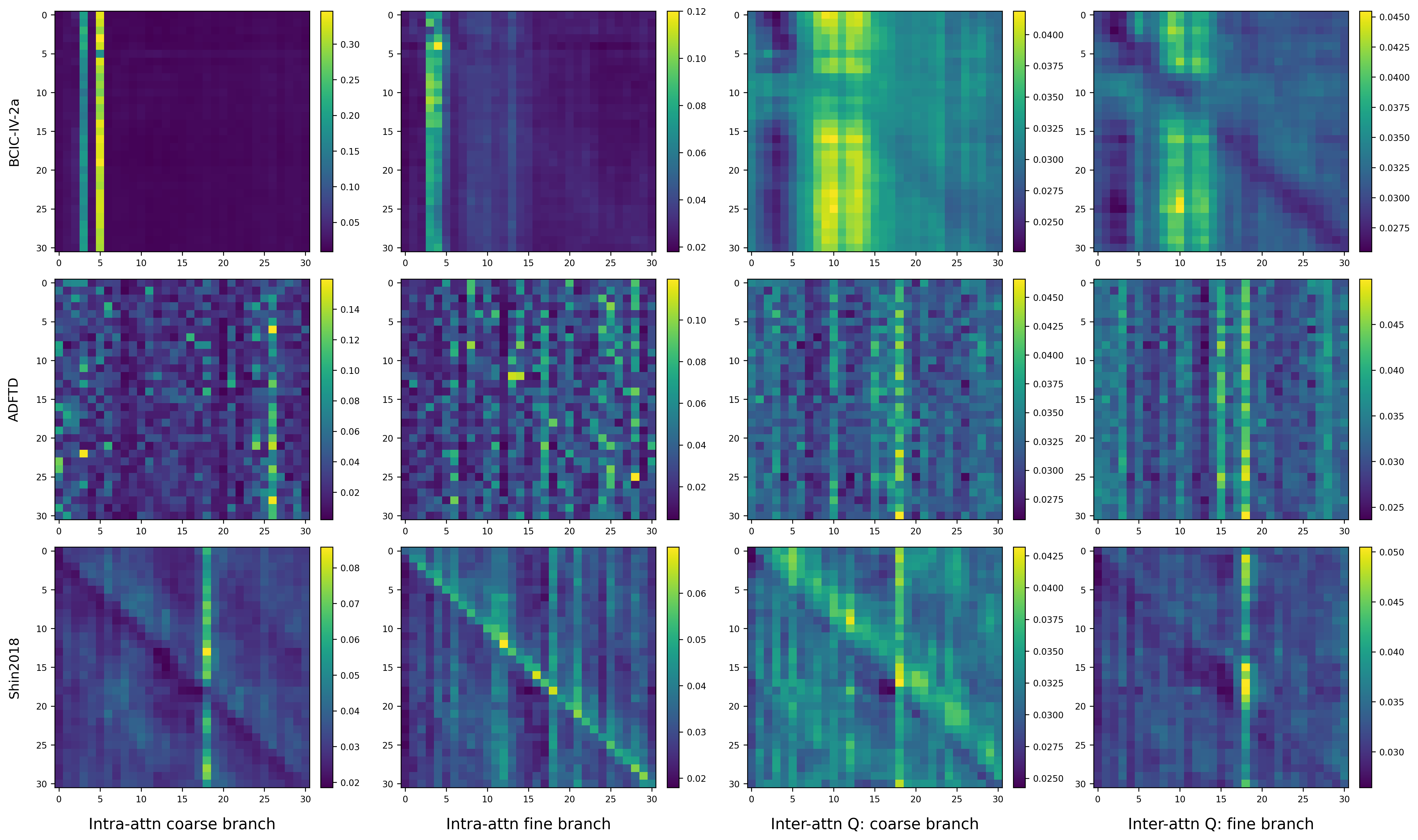
Figure 7: Visualization of intra- and inter-branch attention matrices reveals tightly-structured, dataset-dependent interaction patterns within and between branches.
Limitations and Future Directions
DSAINet, while providing universality across a suite of standard datasets, is inherently task-agnostic and does not integrate EEG-specific priors such as electrode topology, anatomical localization, or explicit frequency decomposition. Its efficiency analyses are primarily offline; real-time deployment remains an open optimization problem. Finally, while covering a broad operational envelope, the framework’s upper generalization bound across all possible EEG tasks and acquisition protocols remains to be established.
Future directions should focus on integrating structural priors and frequency-awareness into DSAINet’s unified design, exploring deployment-optimized model versions through quantization or distillation, and extending the paradigm to larger, more diverse multi-center EEG benchmarks.
Conclusion
DSAINet achieves robust, interpretable, and computationally efficient general EEG decoding under strict subject-independent evaluation. Empirical analyses across ten datasets and five paradigms validate its dual-scale, decoupled attentive interaction architecture as an effective inductive bias for universal EEG feature extraction and classification. The model’s superior performance and efficiency, matched with interpretable neurophysiological focus, make it a compelling candidate baseline for future research in unified, generalizable EEG decoding architectures (2604.18095).

