Towards a Foundation-Model Paradigm for Aerodynamic Prediction in Three-dimensional Design
Abstract: Accurate machine-learning models for aerodynamic prediction are essential for accelerating shape optimization, yet remain challenging to develop for complex three-dimensional configurations due to the high cost of generating training data. This work introduces a methodology for efficiently constructing accurate surrogate models for design purposes by first pre-training a large-scale model on diverse geometries and then fine-tuning it with a few more detailed task-specific samples. A Transformer-based architecture, AeroTransformer, is developed and tailored for large-scale training to learn aerodynamics. The methodology is evaluated on transonic wings, where the model is pre-trained on SuperWing, a dataset of nearly 30000 samples with broad geometric diversity, and subsequently fine-tuned to handle specific wing shapes perturbed from the Common Research Model. Results show that, with 450 task-specific samples, the proposed methodology achieves 0.36% error on surface-flow prediction, reducing 84.2% compared to training from scratch. The influence of model configurations and training strategies is also systematically studied to provide guidance on effectively training and deploying such models under limited data and computational budgets. To facilitate reuse, we release the datasets and the pre-trained models at https://github.com/tum-pbs/AeroTransformer. An interactive design tool is also built on the pre-trained model and is available online at https://webwing.pbs.cit.tum.de.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Towards a Foundation-Model Paradigm for Aerodynamic Prediction in Three-dimensional Design”
1. What is this paper about?
This paper is about making fast, accurate predictions of how air flows around 3D shapes, like airplane wings. Usually, engineers use heavy computer simulations (CFD) to do this, which take a lot of time and money. The authors introduce a smarter machine-learning approach that learns from many examples first (pre-training) and then gets polished for a specific task (fine-tuning). Their goal is to help designers get reliable aerodynamic answers much faster so they can try more ideas in less time.
2. What questions are the researchers trying to answer?
- How can we build one general model that understands aerodynamics well enough to be reused for many wing designs?
- Can we first teach a big model general “aero knowledge” (from many diverse but simpler shapes), then teach it the details of a specific design (richer, more detailed shapes) using only a small amount of extra data?
- Will this two-step process be accurate enough for real design work and still save time and computation?
3. How did they do it? (Methods in everyday language)
Think of teaching a student to read:
- First, you give them lots of different books so they learn general language skills (pre-training).
- Then, you give them a short guide on a specific topic so they become an expert in that area (fine-tuning).
That’s the same idea here, but for airflow around wings.
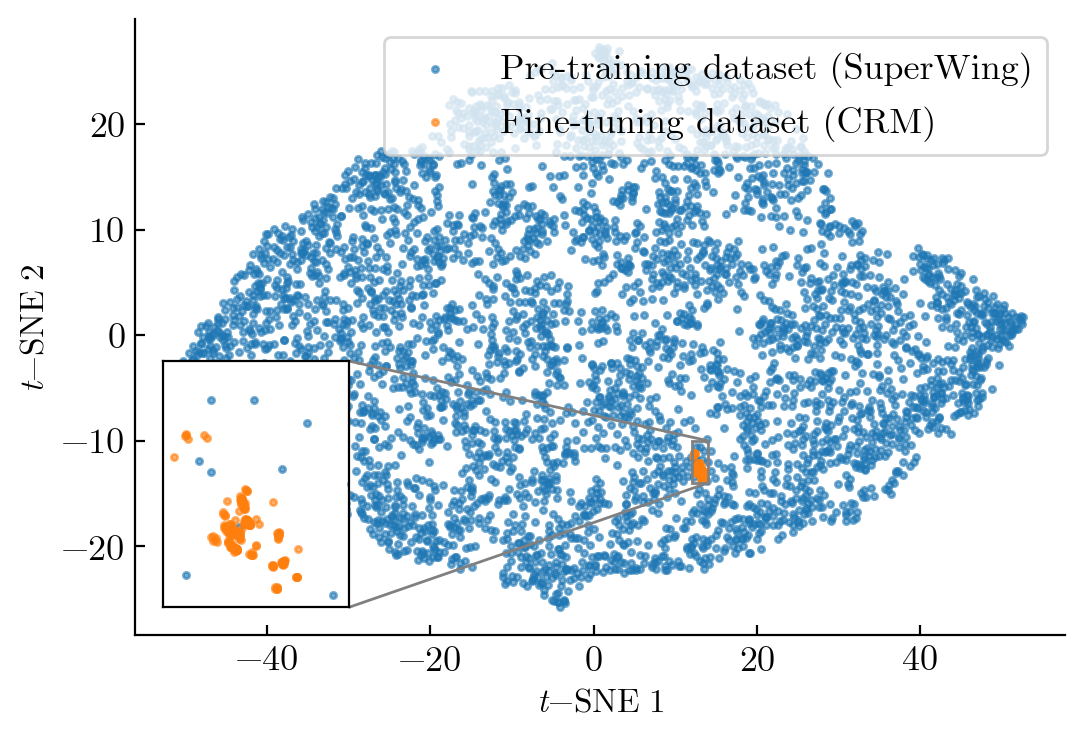
- Pre-training stage (broad and diverse, but simpler details):
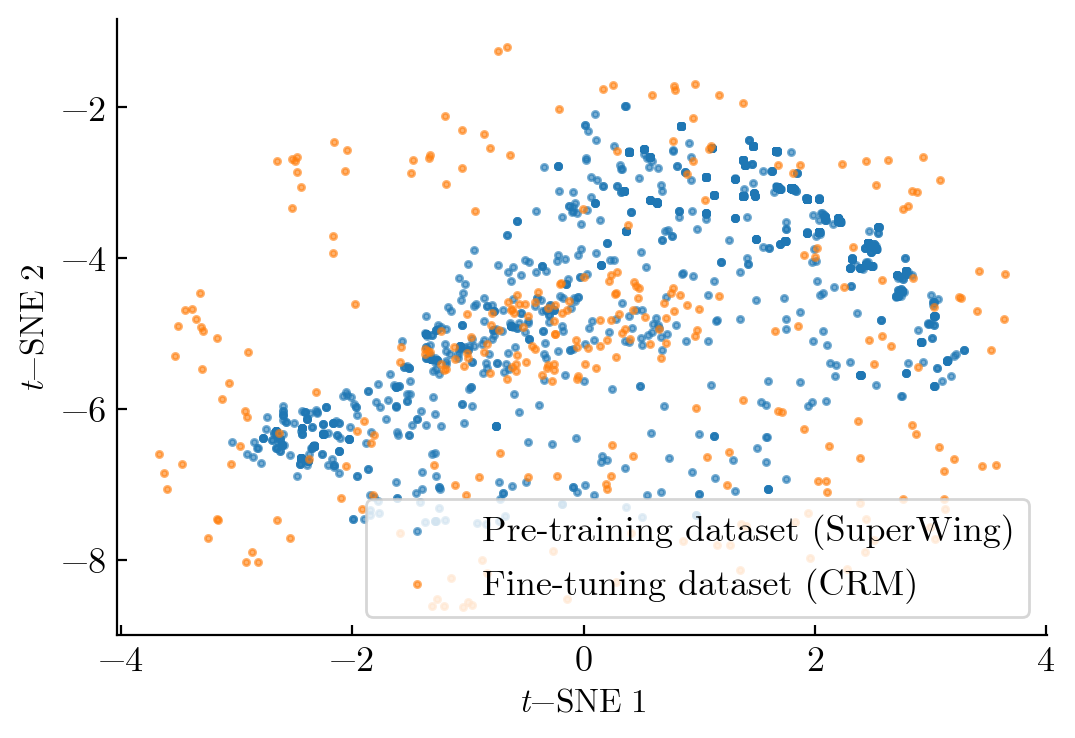
- They trained a large model called “AeroTransformer” on a big dataset (SuperWing) of nearly 30,000 examples. These include many different wing shapes and flight conditions (like speed and angle of attack).
- The shapes in this stage are described with simpler, lower-detail settings so generating the training data isn’t too expensive.
- Fine-tuning stage (narrow and specific, with richer detail):
- They then fine-tuned this model on a smaller set of wings that are all small variations of the NASA Common Research Model (CRM) wing.
- These shapes use more detailed controls (more parameters) to reflect real design adjustments.
- This teaches the model the “local details” needed for a particular design problem, using far less new data.
What is AeroTransformer?
- It’s a Transformer-based neural network (Transformers are the same family of models used in language AI).
- It looks at the wing surface laid out on a grid (like draping a net over the wing), along with flight conditions (Mach number = speed relative to sound; angle of attack = how much the wing is tilted).
- It predicts:
- Surface flow maps: pressure and friction on each tiny patch of the wing.
- Overall numbers (coefficients) like lift (CL), drag (CD), and pitching moment (how much the wing tends to rotate).
Key ideas explained simply:
- Structured mesh: Imagine covering the wing with a checkerboard net. The model sees both the positions of the net’s squares and the flight condition to understand what the airflow should look like.
- Attention in windows: The model “looks” at the surface in small tiles, then shifts the tiles to also capture what’s happening across boundaries—like scanning a large picture tile-by-tile.
- From flow to forces: If you know the pressure and friction on every tiny tile, you can add up all those pushes and pulls to get lift and drag (like summing all small forces to get the total force).
Training details in plain terms:
- Pre-training uses the big, diverse SuperWing dataset to learn general rules of flow around wings.
- Fine-tuning uses a much smaller, detailed dataset around the CRM wing to specialize the model.
- They also tried efficient fine-tuning tricks (like updating only specific parts of the model or using LoRA, a way to change fewer parameters) to save time and memory.
4. What did they find, and why does it matter?
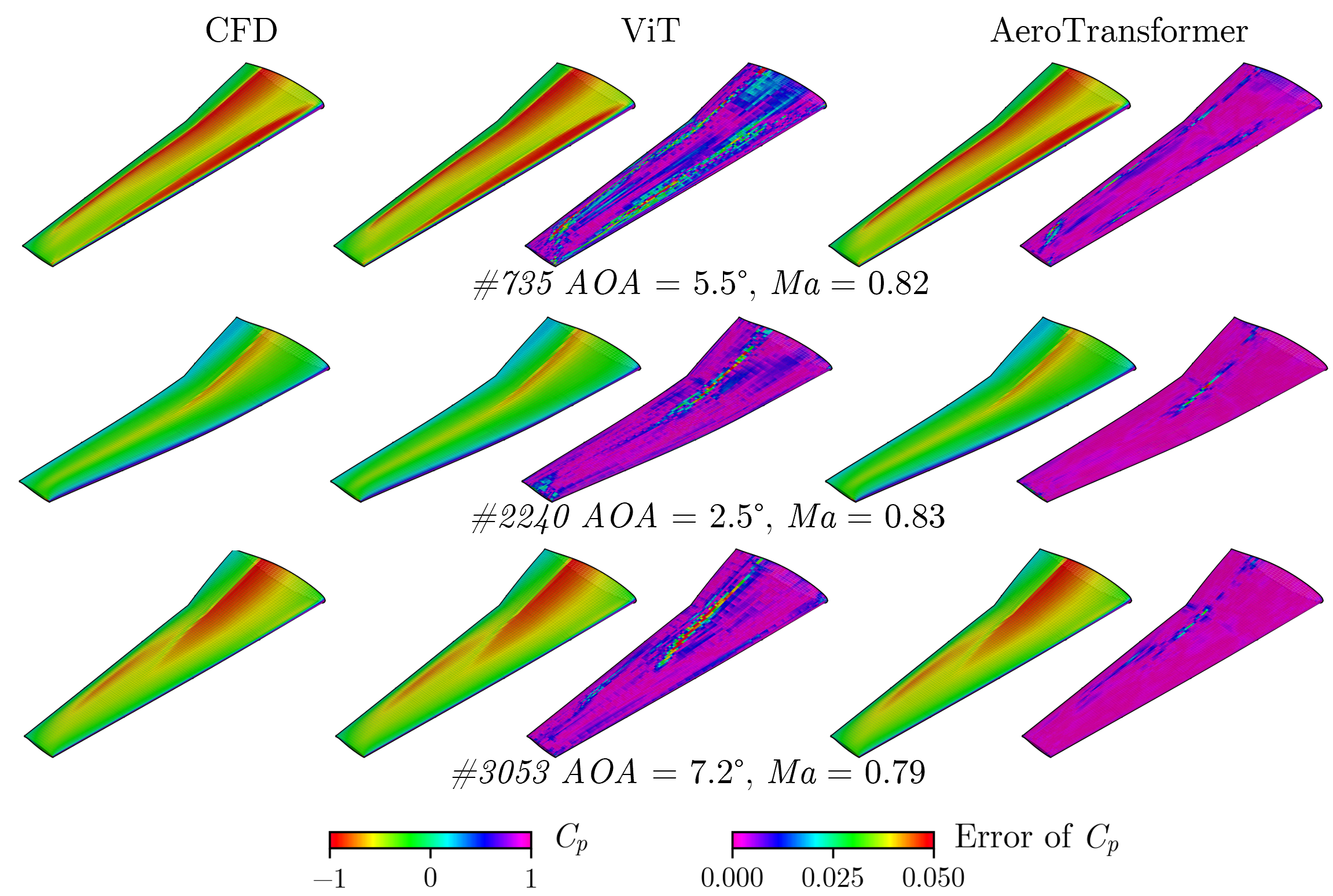
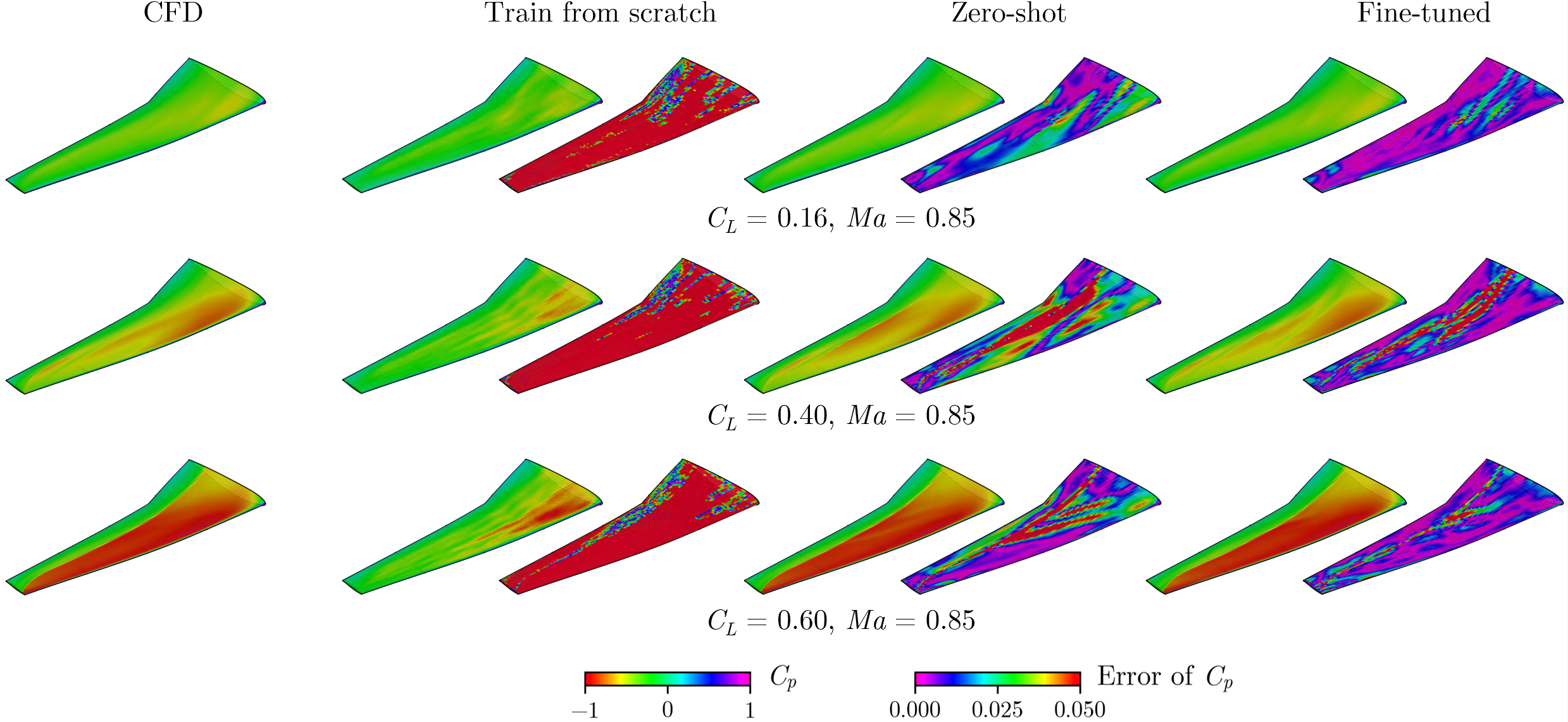
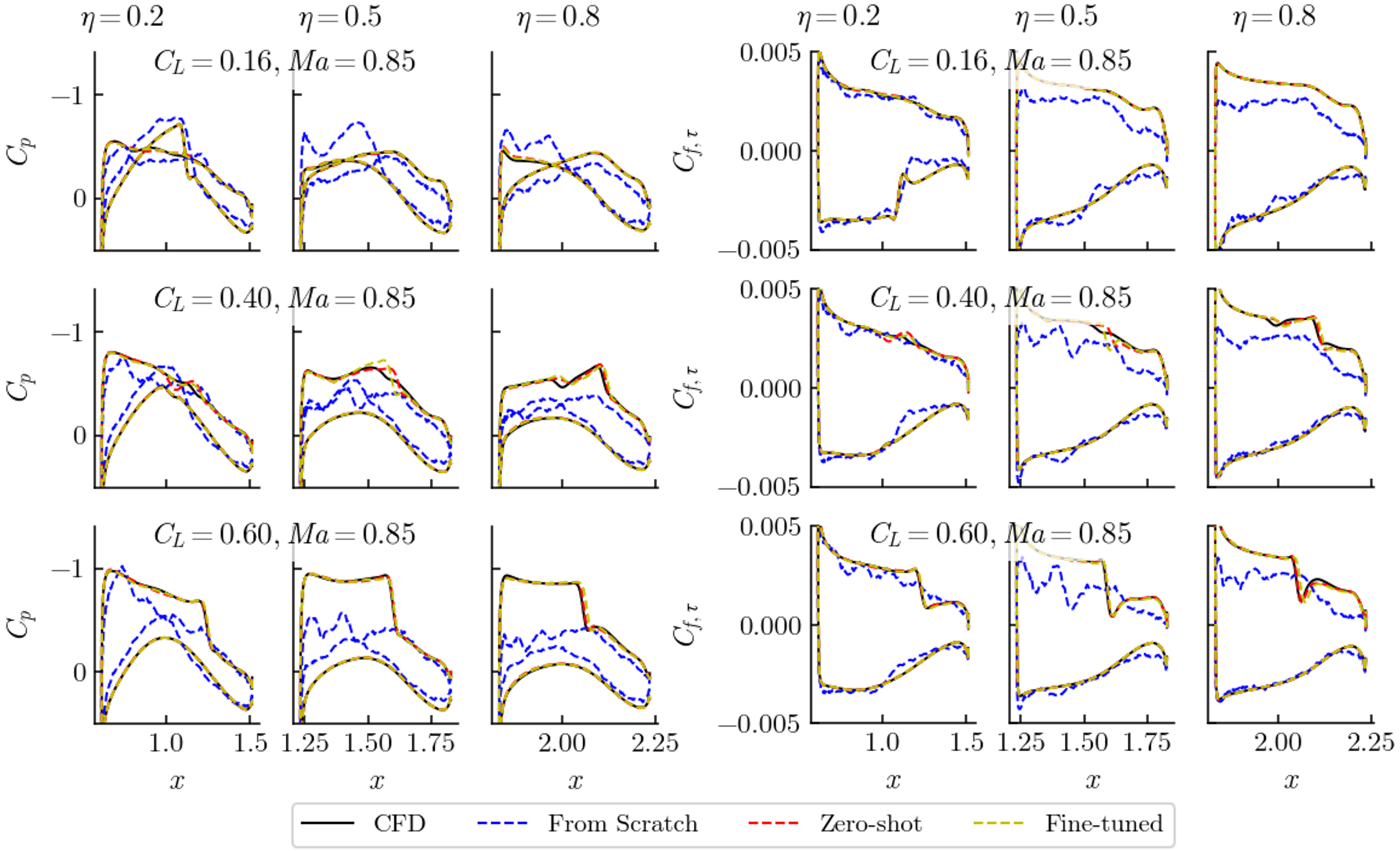
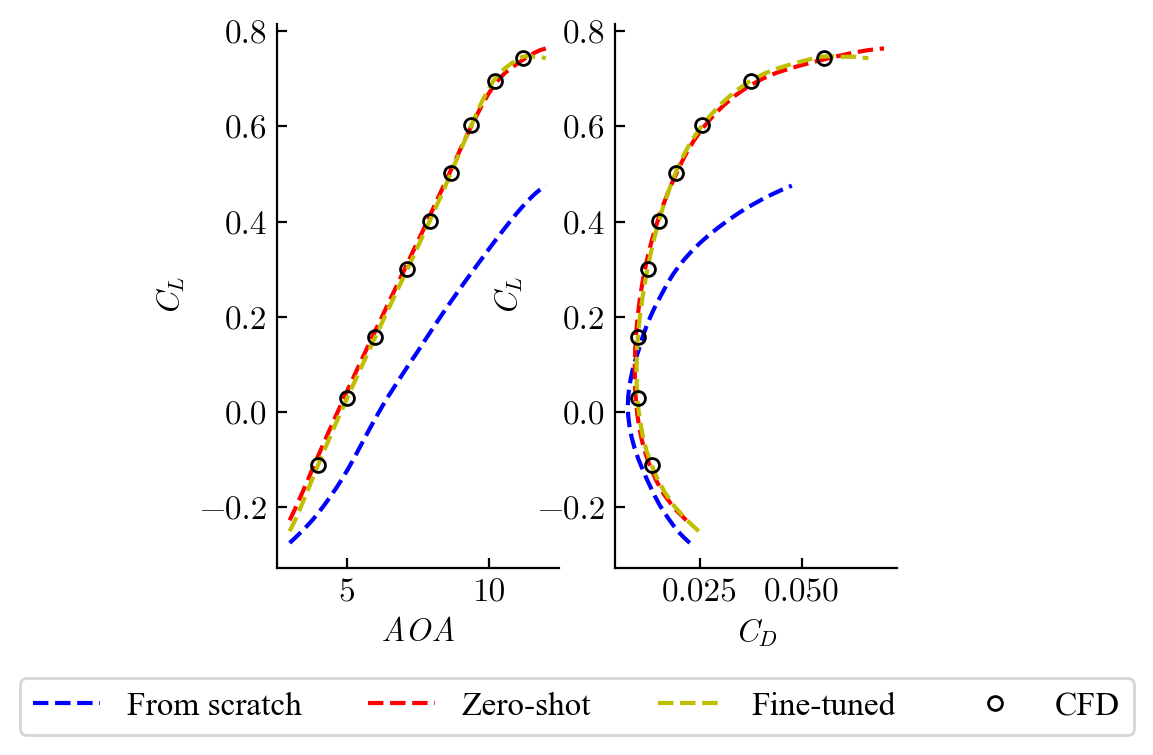
- With only 450 task-specific samples for fine-tuning, the model reached about 0.36% error on predicting surface flow. That’s very accurate.
- Compared to training a model from scratch on the same task, the error was reduced by 84.2%. In other words, pre-training made the model much better and more data-efficient.
- The model can predict both detailed surface maps and overall performance numbers (like lift and drag), which are vital for optimization and for engineers to understand why a design performs the way it does.
- The approach scales: a large pre-trained model can be adapted to new but related tasks using relatively little data and compute.
- They share their data and pre-trained models, plus an interactive web tool (WebWing), so others can try and build on this work.
Why this matters:
- Designers can explore more wing shapes quickly and with confidence.
- Companies can save a lot of time and computational cost during the design and optimization cycles.
- The method balances generality (reusability) and accuracy (trustworthiness), which is often hard to achieve in 3D aerodynamics.
5. What’s the impact going forward?
- Faster, cheaper design: This could speed up how aircraft wings—and potentially other 3D aerodynamic shapes like car bodies—are designed and optimized.
- Reusable “foundation” models for engineering: Just like LLMs are reused across many tasks, this shows how a single aerodynamic foundation model can be adapted to many design problems.
- Better optimization: More accurate and stable predictions help optimization algorithms avoid getting “lost,” leading to better designs.
- Practical tools and benchmarks: With open data, open models, and an online demo, the community can improve and extend this approach, possibly toward more complex shapes and broader operating conditions.
In short: The paper shows that pre-training a big, general aerodynamic model and then fine-tuning it on a specific design task can deliver very accurate results with much less extra data. This could make future aerodynamic design smarter, faster, and more affordable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored in the paper and should be addressed in future work.
Scope and physics coverage
- Generalization beyond transonic swept wings is untested (e.g., high-lift configurations with flaps/slats, winglets, wing–fuselage–nacelle interactions, control surfaces, cars/automotive shapes, rotorcraft/propellers).
- Operating-condition coverage is narrow: , limited AoA ranges, fixed Reynolds number and temperature, no sideslip/yaw, no gusts or control deflections, and no subsonic/supersonic regimes.
- Only steady RANS ground truth is used; performance on unsteady phenomena (buffet, shock-induced separation, stall onset, aeroelastic effects) and URANS/LES/DES/DNS targets remains unknown.
- Turbulence-model dependence is not quantified; it is unclear how the surrogate transfers across turbulence models or solver implementations.
Data, parameterization, and representation
- Pre-training shapes simplify airfoil variability (single baseline airfoil with spanwise trends), potentially biasing learned representations; the impact of this simplification on downstream fidelity for realistic airfoil diversity is unmeasured.
- The approach depends on mapping wing surfaces to a single-block structured parameterization and removes a small tip region; robustness to parameterization distortions, variable topology, and arbitrary complex surfaces (multi-block or non-developable surfaces) is untested.
- No evaluation on unstructured inputs (point clouds/meshes) or cross-resolution generalization; the model’s ability to handle different grid densities or mesh types is unknown.
- Dataset composition strategies for fine-tuning (e.g., optimal design of experiments, active learning, coverage vs. locality trade-offs) are not explored; only random sampling is used.
Architecture, training, and scaling
- No scaling laws are provided that relate model size, pre-training corpus size/diversity, and downstream performance; compute–data–performance trade-offs are not quantified.
- The sensitivity of performance to window size, patch size, tokenization, and hierarchical depth is not systematically studied for aerodynamic features (e.g., shock capture fidelity).
- Parameter-efficient fine-tuning is only lightly evaluated (attention-only, LoRA); rank selection, which layers to adapt, and adapter composition strategies for multi-task reuse are not systematically explored.
- Catastrophic forgetting during fine-tuning is not measured; retention of pre-trained capabilities and continual/multi-task adaptation strategies remain open.
- No analysis of negative transfer: when pre-training on simplified shapes might harm adaptation to detailed geometries.
Losses, physics constraints, and metrics
- Loss design is limited to MSE on surface fields plus coefficient losses; shock-aware losses, conservation-/equilibrium-inspired penalties, monotonicity constraints (e.g., vs AoA), and symmetry/rigid-motion equivariance are not incorporated or evaluated.
- Coefficient accuracy obtained via surface-flow integration may be sensitive to error compensation; the balance between surface and coefficient losses (choice of λ) is not tied to task-level objectives (e.g., optimizer sensitivity).
- Error metrics normalize by spatial range per quantity; the impact of this choice on design-relevant quantities (e.g., sensitivity to small variations or shock location errors) is not analyzed.
- No uncertainty quantification (epistemic/aleatoric) or calibration is provided; the model cannot express confidence or detect out-of-distribution (OOD) samples.
Optimization-readiness and deployment
- Surrogate gradient quality for optimization is not validated against adjoint or finite-difference gradients; the accuracy, smoothness, and stability of surrogate-derived gradients in closed-loop optimization are unknown.
- The effect of prediction errors on optimization convergence and solution quality (e.g., suboptimal designs, constraint violations) is not demonstrated in realistic optimization loops.
- Inference speed, memory footprint, and deployment constraints (CPU/GPU latency, batching, quantization) are not reported; practical throughput for large-scale design studies is unclear.
- Robustness to solver/data noise, failed CFD runs, and inconsistent meshing is not assessed; outlier handling and data-cleaning strategies are unspecified.
Domain shift and transferability
- Transfer across solvers, meshes, and turbulence models (domain shift) is untested; domain adaptation strategies (e.g., feature alignment, adversarial adaptation) remain unexplored.
- Bridging from CFD-trained surrogates to experimental data (wind tunnel/flight) for real-world validation is not addressed; systematic biases from RANS ground truth remain unquantified.
- Multi-fidelity strategies (e.g., pre-train on panel/Euler or coarse-RANS, correct with high-fidelity RANS/LES) are not investigated.
Outputs and physical completeness
- Only surface quantities are predicted; no volumetric fields are produced, limiting applications that require volume features (e.g., separation extent, wake structure, buffet precursors).
- Prediction of additional performance metrics (e.g., stability derivatives, control effectiveness, roll/yaw moments) is not evaluated; only , , are considered.
- Handling of geometric tolerances/manufacturing variability and robustness of predictions under small geometric noise is unstudied.
Interpretability, reliability, and governance
- Model interpretability is not examined (e.g., attention maps aligning with shocks/BL features, saliency vs physical features); no diagnostics on learned physics.
- No safeguards for reliability (e.g., conservative predictions, safety margins) are proposed for high-stakes design use.
- Environmental/compute cost and carbon footprint of pre-training are not quantified; guidance on cost-effective pre-training vs fine-tuning mix is not given.
Reproducibility and resources
- While datasets and pre-trained models are released, a complete recipe for reproducing training (compute budget, data curation decisions, failure rates, hyperparameter sweeps) and ablation breadth appears limited; reproducibility across independent environments is unverified.
Practical Applications
Immediate Applications
Below are specific use cases that can be deployed now using the released datasets, pre-trained models, and the AeroTransformer methodology.
- Real-time aerodynamic feedback during 3D design (Aerospace, Automotive, UAVs; Software/CAx)
- What: Integrate the pre-trained AeroTransformer to provide instant estimates of surface pressure, skin friction, and integrated coefficients (CL, CD, CMz) as designers modify wing-like surfaces.
- Tools/workflows/products:
- CAD/CAE plugins for CATIA, Siemens NX, or Rhino/Grasshopper.
- “Digital wind tunnel” web app (e.g., extending https://webwing.pbs.cit.tum.de) for internal design reviews.
- Microservice/API deployment of the pre-trained model (e.g., containerized PyTorch service).
- Dependencies/assumptions:
- Geometry must be mappable to a structured surface mesh similar to the paper’s setup.
- Valid within operating ranges used for training (transonic, specific Mach/AoA ranges; steady RANS regime).
- Accuracy highest after light task-specific fine-tuning for the target geometry family.
- Surrogate-assisted multipoint and robust optimization (Aerospace; MDO/Optimization Software)
- What: Use the pre-trained + fine-tuned model to replace most CFD calls in design loops, especially for multipoint studies and robust design under varying Mach/AoA.
- Tools/workflows/products:
- Integrate into OpenMDAO/pyOptSparse pipelines as a fast evaluator.
- Two-stage workflow: pre-train on broad shapes, fine-tune locally with ~100–500 CFD samples to reach high accuracy (paper reports 0.36% surface-flow error with 450 samples and 84.2% error reduction vs. training from scratch).
- Periodic CFD “checkpointing” to validate and correct surrogate drift.
- Dependencies/assumptions:
- Surrogate is reliable within the local design neighborhood used for fine-tuning.
- Requires a small but representative set of high-fidelity CFD cases for adaptation.
- Use coefficient-aware loss when deriving coefficients from surface flow to improve robustness.
- CFD triage and screening (Aerospace, Automotive, UAVs; CAE/Simulation)
- What: Rapidly pre-screen large design pools, discarding weak candidates and prioritizing high-value CFD runs.
- Tools/workflows/products:
- Batch inference on candidate libraries to rank designs by estimated CD/CL.
- Thresholding rules to decide which cases go to high-fidelity CFD.
- Dependencies/assumptions:
- Surrogate performance must be monitored for domain shift; spot-checks with CFD recommended.
- Parameter-efficient adaptation for small teams (Aerospace, UAVs; Software/ML Ops)
- What: Use LoRA or attention-only fine-tuning to adapt the base model to new wing variants with limited data/compute.
- Tools/workflows/products:
- Pre-trained checkpoint + LoRA adapters for different product lines.
- Dependencies/assumptions:
- Good performance requires some overlap between pre-training manifold and the target shape family.
- Minimal compute still needed for collecting ~100–500 high-fidelity samples.
- Rapid feasibility studies and design reviews (Aerospace, Automotive; Product Development)
- What: Provide near-instant aerodynamic assessments in early concept phases to inform down-selection and budget planning.
- Tools/workflows/products:
- Internal “digital wind tunnel” dashboards linked to PLM systems for program gate reviews.
- Dependencies/assumptions:
- Use cases limited to performance regimes and shape classes within or close to the training distribution.
- Educational and research enablement (Academia; Education/Research Software)
- What: Use open datasets and models to teach ML for PDEs, aerodynamics, and surrogate modeling; benchmark new methods (e.g., PEFT, training strategies).
- Tools/workflows/products:
- Course labs with the SuperWing dataset and AeroTransformer code (https://github.com/tum-pbs/AeroTransformer).
- Reproducible benchmarks for generalization and fine-tuning efficacy.
- Dependencies/assumptions:
- Requires basic ML/CFD tooling familiarity; focus is currently on transonic wing surfaces.
- Accelerated design-of-experiments (DoE) planning (Aerospace; Optimization/DoE)
- What: Use the surrogate to shape DoE grids, focusing expensive CFD points on high-sensitivity regions.
- Tools/workflows/products:
- Surrogate-driven adaptive sampling policies; active learning loops.
- Dependencies/assumptions:
- Requires uncertainty proxies (e.g., ensemble surrogates) or periodic CFD-based validation.
- QA and regression testing for CAD changes (Aerospace, Automotive; QA/PLM)
- What: Quickly assess the aerodynamic impact of small CAD modifications in continuous integration pipelines.
- Tools/workflows/products:
- CI hooks trigger surrogate evaluation on latest design commits; flag significant performance deviations.
- Dependencies/assumptions:
- Effective for small local changes near the fine-tuning domain; periodic CFD auditing recommended.
- Coupled workflow with adjoint CFD (Aerospace; MDO)
- What: Use the surrogate for coarse design-space exploration and warm-start adjoint-based shape optimization to reduce total wall time.
- Tools/workflows/products:
- Hybrid loop: surrogate-guided candidate generation + adjoint refinement.
- Dependencies/assumptions:
- Adjoint methods remain the authority for final gradient accuracy; surrogate helps reduce the search horizon.
- Public-facing “digital wind tunnel” demos and training (Academia, Industry; Outreach/Training)
- What: Leverage the existing interactive tool for demos, internal training, and non-expert engagement.
- Tools/workflows/products:
- Workshops or internal portals that mirror https://webwing.pbs.cit.tum.de.
- Dependencies/assumptions:
- Communicate model limits clearly (operating ranges, geometry assumptions).
Long-Term Applications
These opportunities require additional research, broader datasets, scaling, integrations, or regulatory acceptance before widespread deployment.
- Cross-geometry aerodynamic foundation models (Aerospace, Automotive, Energy/Wind; Software/CAE)
- What: Extend the paradigm from transonic wings to cars, UAV fuselages, wind-turbine blades, and multi-element high-lift configurations.
- Tools/workflows/products:
- Multi-domain pre-training hubs; CAE model marketplaces.
- Dependencies/assumptions:
- Requires large-scale, diverse, high-quality datasets with unified geometry representations (including unstructured meshes and complex topologies).
- Domain-specific physics (e.g., rotating machinery, separation) must be represented.
- Surrogate-in-the-loop certification and regulatory workflows (Aerospace; Policy/Standards)
- What: Use rigorously validated surrogates to replace portions of CFD in certification processes (e.g., preliminary analyses for compliance).
- Tools/workflows/products:
- Model cards and validation protocols for CAE surrogates; standardized metrics and acceptance criteria.
- Dependencies/assumptions:
- Requires uncertainty quantification, robustness guarantees, and third-party validation.
- Adoption depends on regulators’ guidance and evidence across diverse conditions.
- Real-time onboard aerodynamic state estimation and control (Aerospace, Robotics/UAVs; Embedded/Controls)
- What: Deploy lightweight surrogate inference for flight envelope protection, gust load alleviation, or model predictive control.
- Tools/workflows/products:
- Edge-deployable variants of AeroTransformer with latency guarantees.
- Dependencies/assumptions:
- Extensive validation across off-nominal conditions; robust UQ and failure modes; integration with sensor fusion.
- Autonomous, closed-loop generative design (Aerospace, Automotive; Software/AI Design)
- What: Combine foundation surrogates with generative models and optimizers to automatically propose and test designs at scale.
- Tools/workflows/products:
- “Design co-pilots” that suggest geometry edits with immediate aero feedback; reinforcement learning or Bayesian optimization loops.
- Dependencies/assumptions:
- High-fidelity physics coupling (structures, manufacturability) and guardrails to prevent mode collapse or infeasible designs.
- Multiphysics foundation models for MDO (Aerospace, Energy; CAE/MDO)
- What: Joint surrogates for aerodynamics, structures, aeroelasticity, and acoustics to enable end-to-end multidisciplinary optimization.
- Tools/workflows/products:
- Federated training pipelines across physics; co-simulation adapters.
- Dependencies/assumptions:
- Harmonized datasets and consistent geometry parameterizations across disciplines; larger model capacity and training budgets.
- Sustainability and cost reductions in CAE compute (Cross-industry; Corporate Sustainability/IT)
- What: Systematically replace large fractions of exploratory CFD with surrogates to cut energy, cost, and queue time.
- Tools/workflows/products:
- Enterprise policies for surrogate-first exploration; metering and reporting of compute/CO2 savings.
- Dependencies/assumptions:
- Cultural and process changes; tracking frameworks; buy-in from CAE teams.
- Edge deployment for wind farms and aero assets (Energy; Operations)
- What: Use fast surrogates for blade pitch optimization, wake management, or predictive maintenance.
- Tools/workflows/products:
- Lightweight inference engines on turbines; fleet-level optimization.
- Dependencies/assumptions:
- Models must capture operating variability (Reynolds, turbulence, yaw misalignment); online adaptation and monitoring.
- Expanded operating envelopes and physics (Aerospace; Research/CAE)
- What: Incorporate variable Reynolds numbers, transitional/turbulent regimes beyond steady RANS, and unsteady phenomena.
- Tools/workflows/products:
- New datasets (LES/DNS/RANS mixes), temporal models, and uncertainty-aware training.
- Dependencies/assumptions:
- Significant data generation costs and workflow changes; careful curation to avoid negative transfer.
- Differentiable CAD-to-surrogate pipelines (Software/CAE; Optimization)
- What: End-to-end differentiable workflows linking geometry parameters to aero metrics via the surrogate for fast gradient-based design.
- Tools/workflows/products:
- Differentiable geometry kernels; adjoint-like gradients through the network.
- Dependencies/assumptions:
- Stable, well-behaved gradients and verified correspondence with high-fidelity sensitivities.
- Policy and open-science infrastructure (Policy, Academia, Industry Consortia)
- What: Establish standards for scientific foundation models in CAE (dataset documentation, reproducibility, benchmarking).
- Tools/workflows/products:
- Shared data/model repositories; governance frameworks for IP, safety, and bias.
- Dependencies/assumptions:
- Community coordination and funding; alignment on licenses and privacy/IP constraints.
Notes on Assumptions and Dependencies (common across applications)
- Domain coverage and generalization: Current models are validated on transonic wings within specific Mach/AoA ranges using steady RANS. Significant domain shifts (e.g., multi-element high-lift, bluff bodies, strong separation, or very different Reynolds numbers) require additional pre-training and fine-tuning.
- Geometry representation: The pipeline assumes mapping the surface to a structured mesh. Broader adoption needs robust handling of complex topologies and unstructured meshes.
- Data quality and cost: High-fidelity CFD data are expensive; the proposed two-stage strategy reduces but does not eliminate this need. Model performance depends on the representativeness and quality of fine-tuning samples.
- Reliability in optimization: Even small errors can mislead optimizers; best practice is surrogate-in-the-loop validation with periodic CFD and coefficient-aware loss when integrating surface flow to global metrics.
- Compute and integration: Training/fine-tuning requires ML infrastructure; inference is lightweight but still benefits from GPU acceleration for real-time feedback.
- Governance and trust: For high-stakes use, uncertainty quantification, traceability (model cards), and compliance with emerging standards are prerequisites.
Glossary
- AdamW optimizer: A variant of the Adam optimizer that decouples weight decay from the gradient update to improve generalization. "the AdamW optimizer and a learning rate schedule based on the one-cycle policy are employed"
- adaptive layer normalization-zero (adaLN-Zero): A conditioning mechanism that modulates Transformer activations via learned scale and shift parameters derived from conditioning inputs. "inspired by the adaptive layer normalization-zero (adaLN-Zero) conditioning mechanism from Diffusion Transformer"
- adjoint techniques: Methods that compute gradients efficiently for high-dimensional systems by solving adjoint equations, commonly used in PDE-constrained optimization. "particularly those utilizing adjoint techniques for gradient evaluation"
- aerodynamic coefficients: Dimensionless measures (e.g., lift, drag, moments) describing forces and moments on a body in a flow. "The aerodynamic coefficients include the lift coefficient , the drag coefficient , and the pitching momentum coefficient ."
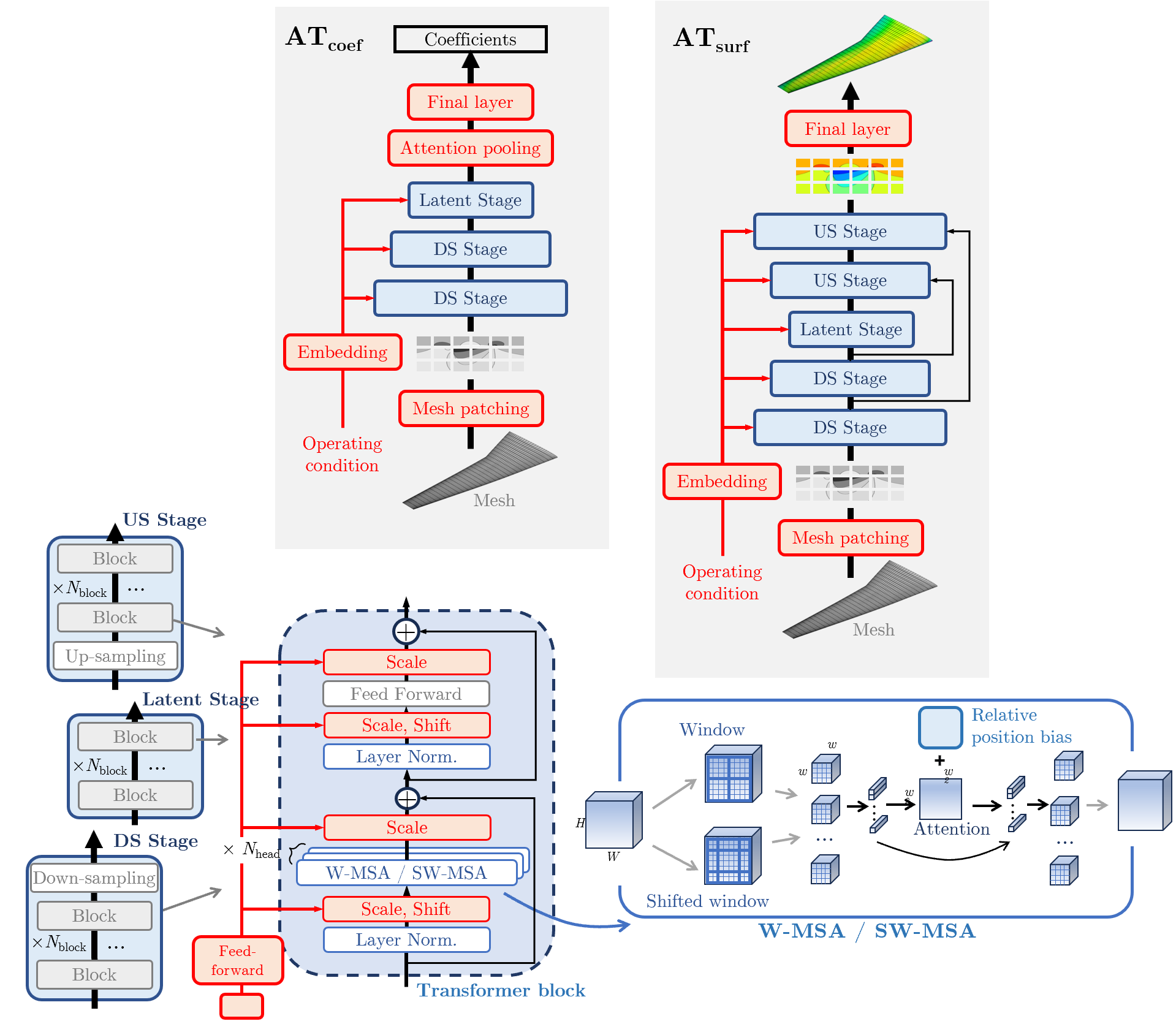
- AeroTransformer: A Transformer-based architecture tailored for aerodynamic prediction tasks such as surface flow and coefficient inference. "A Transformer-based architecture, AeroTransformer, is developed and tailored for large-scale training to learn aerodynamics."
- angle of attack (AoA): The angle between the oncoming flow and a reference line on the body (often the chord line of an airfoil). "the Mach number and the angle of attack "
- aspect ratio (AR): A wing planform metric, typically span squared divided by reference area, influencing aerodynamic performance. "aspect ratio "
- attention-based pooling: A pooling operation that aggregates features by learned attention weights rather than simple averaging or max operations. "compressed with an attention-based pooling layer"
- autoregressive approach: A prediction strategy where future states are predicted from a sequence of past states. "PDE-Transformer also adopts an autoregressive approach for prediction"
- B-spline: A piecewise polynomial curve representation used for smooth parametric shapes and distributions. "represented using B-spline curves defined by five control points."
- CAD: Computer-Aided Design; software and methods for creating precise engineering geometry models. "The surface mesh generation is with in-house CAD code"
- camber: The curvature of an airfoil’s mean line, affecting lift and other aerodynamic characteristics. "maximum thickness and camber along the spanwise direction"
- ClassâShape Transformation (CST): A parametric method for representing aerodynamic shapes using basis functions. "including ClassâShape Transformation (CST)"
- Common Research Model (CRM): A widely used benchmark aircraft wing-body configuration for aerodynamic studies. "the NASA Common Research Model (CRM) wing"
- computational fluid dynamics (CFD): Numerical simulation of fluid flows using discretized equations of motion. "computational fluid dynamics (CFD)-based optimization methods"
- ConFIG method: A hyperparameter-free technique to combine potentially conflicting gradient directions from multiple loss terms. "we also tested the hyperparameter-free ConFIG method"
- convolutional embedding layer: A convolutional module that converts grid/patch inputs into token embeddings for Transformer processing. "using a convolutional embedding layer"
- dihedral: The upward or downward angle of a wing relative to the horizontal plane, affecting stability; here parameterized along the span. "the dihedrals $y_{\mathrm{LE}$ and the twist angles $\alpha_{\mathrm{tw}$"
- Diffusion Transformer: A Transformer architecture used in diffusion models, informing conditioning mechanisms like adaLN-Zero. "from Diffusion Transformer \cite{peebles_scalable_2023}"
- drag coefficient (C_D): A dimensionless coefficient quantifying the drag force relative to dynamic pressure and reference area. "the drag coefficient "
- exponential moving average (EMA): A smoothing technique that maintains a running average of parameters or gradients with exponential decay. "We also attempted the exponential moving average (EMA) method for gradient clipping"
- Free Form Deformation (FFD): A geometric deformation technique using control lattices to flexibly perturb shapes. "deformation techniques such as Free Form Deformation (FFD)"
- friction coefficient (C_f): A dimensionless measure of skin-friction shear on a surface due to viscous effects. "the friction coefficient "
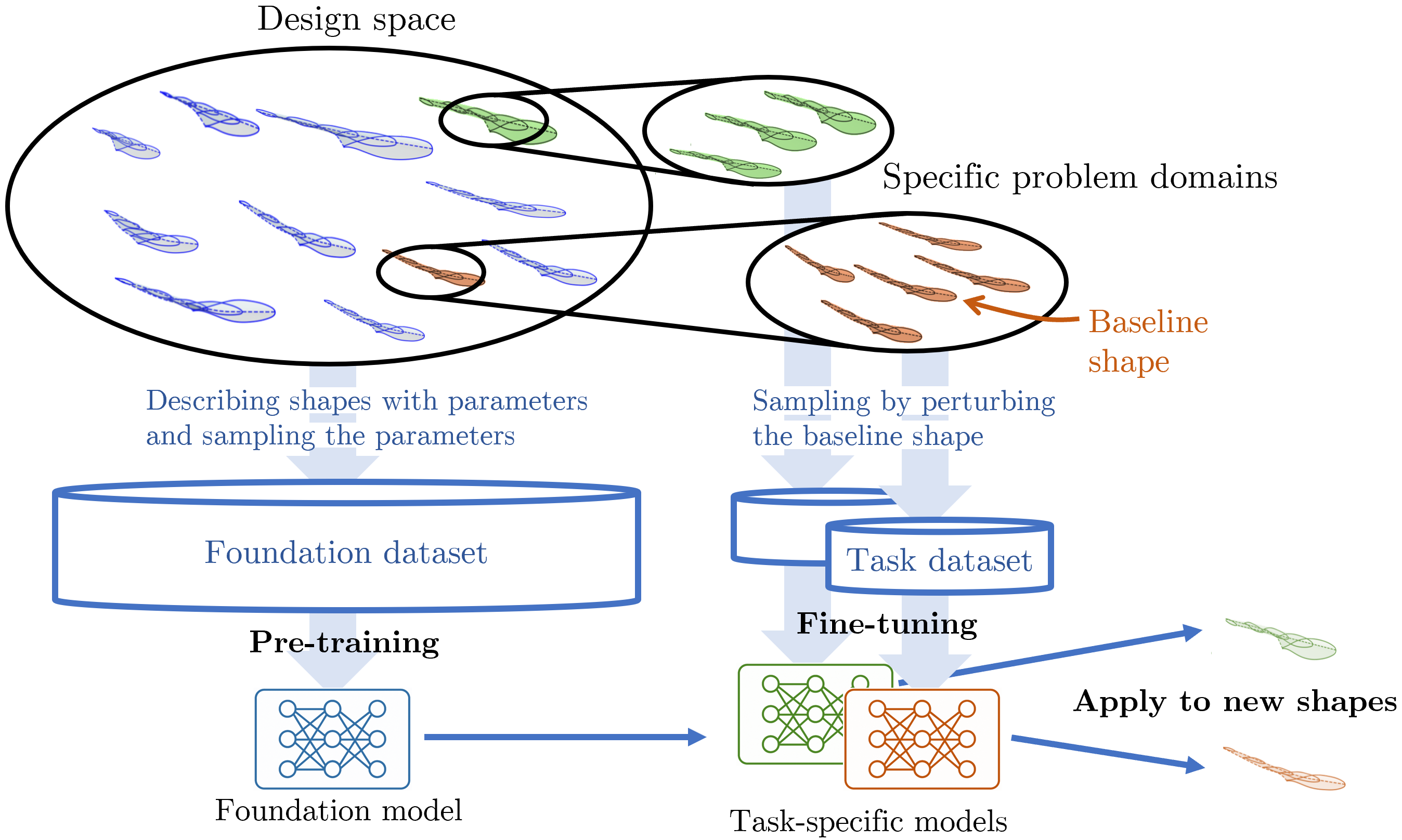
- foundation-model paradigm: A training strategy where large models are pre-trained on broad, diverse data and later adapted to specific tasks. "The foundation-model paradigm relies on large, diverse datasets to learn broadly transferable relationships"
- gradient clipping: A stabilization technique that limits gradient norms to prevent exploding gradients during training. "We also add gradient clipping \cite{pascanu_difficulty_2013} to avoid spikes in the learning curve."
- hierarchical U-shaped architecture: A multi-scale encoder–decoder design with downsampling and upsampling paths plus skip connections. "a hierarchical U-shaped architecture is adopted"
- kink: The break in a wing’s trailing edge planform typically separating inboard and outboard segments. "also known as the \"kink\"."
- layer normalization: A normalization method that stabilizes and accelerates training by normalizing across features within a layer. "residual connections and layer normalization"
- leading edge sweep angle: The angle between the wing’s leading edge and a perpendicular to the body’s centerline. "leading edge sweep angle $\Lambda_{\mathrm{LE}$"
- lift coefficient (C_L): A dimensionless coefficient quantifying lift relative to dynamic pressure and reference area. "the lift coefficient "
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that injects low-rank updates into weight matrices. "Low rank adaptation (LoRA)"
- Mach number (Ma): The ratio of flow speed to the speed of sound, indicating compressibility effects. "Mach number "
- mean square error (MSE): A loss function measuring the average squared difference between predictions and targets. "we use the mean square error (MSE) for the loss function"
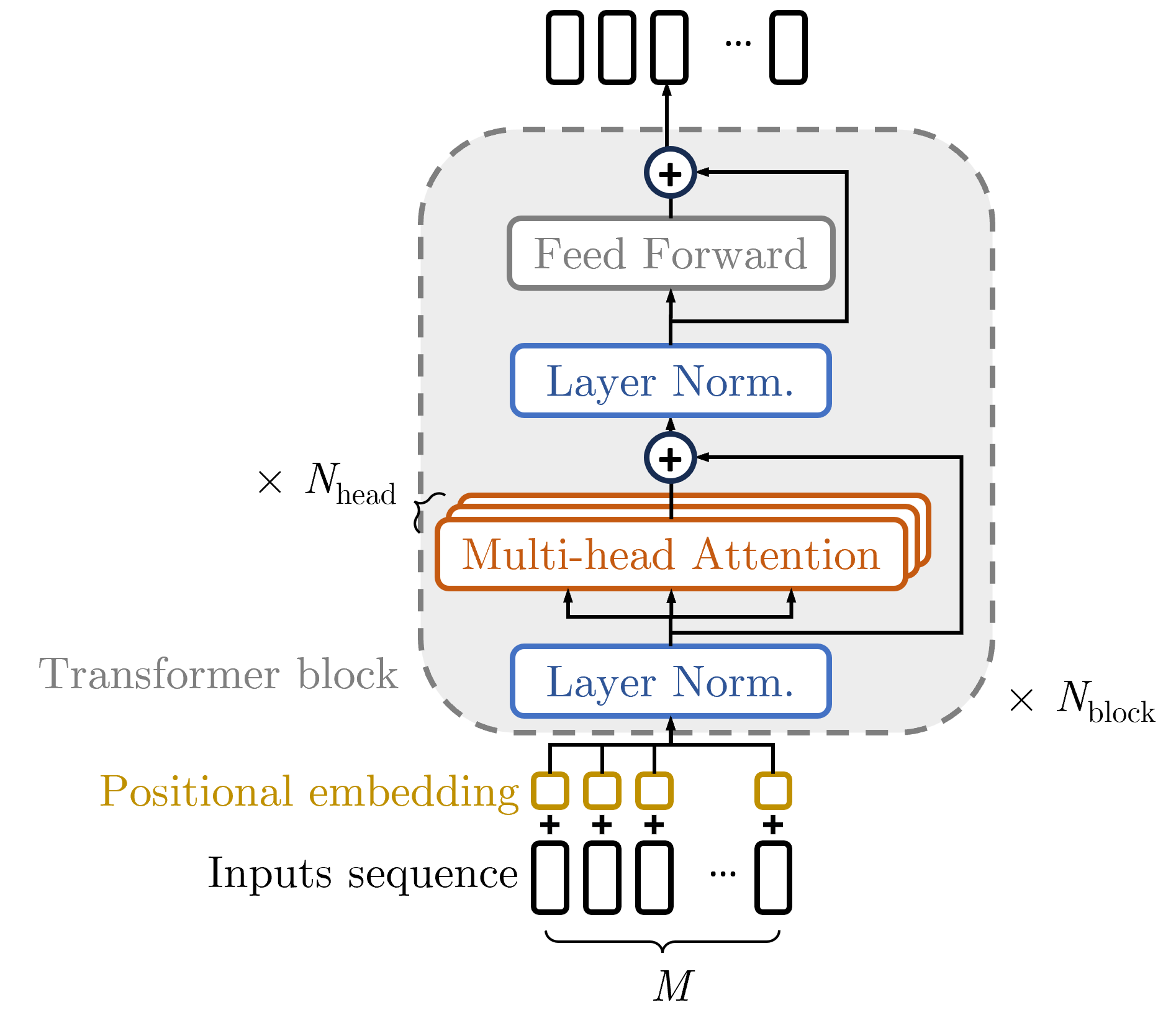
- multi-head self-attention: An attention mechanism that projects queries, keys, and values into multiple subspaces to capture diverse relationships. "featuring a multi-head self-attention mechanism layer"
- multigrid: A numerical acceleration technique solving on multiple grid resolutions to speed up convergence. "A “3w” multigrid strategy is adopted to accelerate convergence"
- one-cycle policy: A learning-rate schedule that increases then decreases the learning rate within a single training cycle. "a learning rate schedule based on the one-cycle policy"
- PDE-Transformer: A Transformer variant designed for spatiotemporal PDE inference on structured grids. "the PDE-Transformer \cite{holzschuh_pde-transformer_2025}"
- PixelShuffle: An upsampling operation that rearranges channels into spatial resolution, used in decoder paths. "Down- and up-sampling is performed using convolutional layers with PixelUnshuffle and PixelShuffle operations."
- PixelUnshuffle: A downsampling operation that rearranges spatial resolution into channels for efficient multi-scale processing. "Down- and up-sampling is performed using convolutional layers with PixelUnshuffle and PixelShuffle operations."
- planform: The top-down outline of a wing, defined by parameters like sweep, taper, and kink location. "a typical transonic wing follows a two-segment planform shape"
- positional embeddings: Encodings added to input tokens to provide the model with spatial or sequential position information. "positional embeddings are added to each input token"
- pressure coefficient (C_p): A nondimensional surface pressure metric normalized by dynamic pressure. "the surface pressure coefficients "
- pre-training: An initial training stage on broad, diverse data to learn general representations before task-specific fine-tuning. "by first pre-training a large-scale model on diverse geometries"
- Reynolds number: A dimensionless quantity expressing the ratio of inertial to viscous forces in a flow. "The Reynolds number and freestream temperature are fixed at 20 million"
- Reynolds-Averaged Navier-Stokes (RANS): A turbulence modeling approach that averages the Navier–Stokes equations to model mean flow. "Reynolds-Averaged Navier-Stokes (RANS) simulations are performed"
- scaled dot-product: The core similarity computation in attention, scaling the dot product of queries and keys by the embedding dimension. "described most commonly by the scaled dot-product"
- sectional airfoil: The two-dimensional airfoil shape at a given spanwise station of a three-dimensional wing. "sectional airfoils are allowed to vary independently"
- self-attention mechanism: A mechanism allowing each token to attend to all others to model global dependencies. "The self-attention mechanism represents the core of the architecture."
- shifted window multi-head self-attention (SW-MSA): A local attention scheme with shifted windows to enable cross-window interactions efficiently. "shifted \modified{window} multi-head self-attention (SW-MSA)"
- spline-based representations: Geometry parameterizations using spline curves to compactly encode smooth shape variations. "spline-based representations \cite{hasan_wing_bspline_spanwise_crm_2025}"
- structured mesh: A grid with a regular topology (e.g., logically rectangular) used for discretizing geometry or fields. "a single-block structured mesh"
- SuperWing: A large-scale wing dataset with broad geometric diversity used for pre-training. "the model is pre-trained on SuperWing, a dataset of nearly 30000 samples with broad geometric diversity"
- surrogate model: A learned model that approximates expensive simulations, enabling fast predictions in design loops. "constructing accurate surrogate models for design purposes"
- taper ratio: The ratio of tip chord to root chord, characterizing wing planform narrowing. "taper ratio "
- Transonic: A flight regime with flow speeds around the speed of sound, exhibiting mixed subsonic and supersonic regions. "transonic swept wings"
- Transformer: A neural network architecture based on self-attention and feedforward layers with residual connections and normalization. "The typical Transformer~\cite{vaswani_attention_2017} is an encoder-only architecture"
- twist angle: The rotation of a wing’s sectional airfoil about its spanwise axis, varying along the span. "the twist angles $\alpha_{\mathrm{tw}$"
- Vision Transformer (ViT): A Transformer model adapted to images by tokenizing patches instead of words. "The ViT \cite{dosovitskiy_vit_2022} extends the Transformer from natural language processing to computer vision tasks."
- windowed multi-head self-attention (W-MSA): Self-attention computed within local windows to reduce computational cost. "windowed multi-head self-attention (W-MSA)"
Collections
Sign up for free to add this paper to one or more collections.