- The paper introduces a two-dimensional framework that rigorously assesses both convergent (constraint satisfaction) and divergent (novelty and uniqueness) creativity in molecule generation.
- It reveals a strong anti-correlation between achieving chemical validity and maintaining structural novelty across physicochemical, ADMET, and activity-driven tasks.
- Results indicate that smaller models excel in producing 'Fully Creative' molecules for hypothesis generation, while temperature tuning and in-context learning help balance exploration and exploitation.
Systematic Analysis of Creativity in LLM–Driven Molecule Generation
Introduction
This paper presents a rigorous empirical study of the notion of "creativity" in molecular generation by LLMs, positing that creativity is not merely an aesthetic attribute but a functional necessity for molecular discovery. The authors propose a two-dimensional operationalization of creativity—convergent creativity (constraint satisfaction) and divergent creativity (chemical space exploration)—and perform an extensive evaluation of state-of-the-art LLMs across physicochemical, ADMET, and biological activity-driven molecule generation scenarios. The interplay between model scale, constraint complexity, in-context learning, and inference-time sampling is dissected, yielding nuanced insights into the effective deployment of LLMs in de novo drug design pipelines.
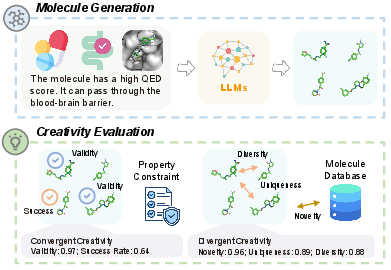
Figure 1: Overview of the creativity evaluation framework, separating convergent (constraint satisfaction) and divergent (chemical space exploration) molecular generation.
Operationalizing Creativity in Molecular Generation
The study reframes molecule generation as a task demanding balanced creativity: models must go beyond mere validity to find chemically plausible, novel, and functionally relevant structures under various constraints. The evaluation framework extends standard generative metrics, consolidating them via the geometric mean to produce system-level creativity scores. These aggregate metrics penalize models that perform highly on only one dimension (e.g., constraint satisfaction without novelty) and recognize those that achieve simultaneous novelty, uniqueness, diversity, and success—a class termed "Fully Creative."
Experimental Protocol
Eight core tasks were designed spanning three axis:
- Physicochemical (QED, synthetic accessibility, LogP control)
- ADMET (BBB permeability, intestinal absorption)
- Activity (target binding to DRD2, JNK3, GSK3β)
Property evaluation leverages established computational chemistry toolkits and predictive oracles. The study benchmarks multiple LLMs, including LLaMA3, GPT-3.5, GPT-4o-mini, and DeepSeek-V3, to comprehensively trace creativity trends under zero-shot and in-context learning (ICL) prompting regimes.
Empirical Results
Convergent vs. Divergent Creativity: Trade-Offs and Correlations
A fundamental empirical outcome is the strong anti-correlation (r≈−0.8) between convergent (validity, success) and divergent (novelty, uniqueness, diversity) creativity metrics. Fine-tuning for constraint satisfaction frequently narrows chemical space exploration, while maximizing novelty often leads to lower rates of functional molecules.
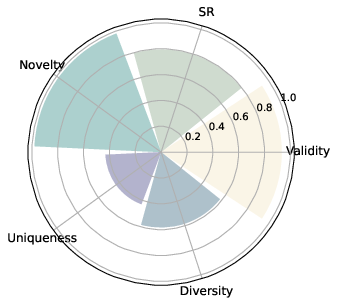
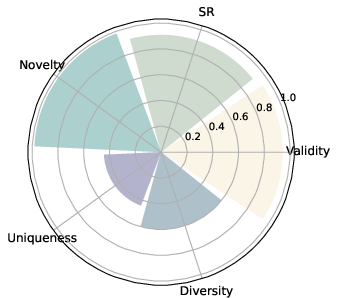
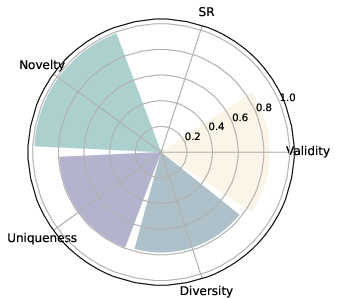
Figure 2: Convergent (constraint satisfaction, validity) and divergent (structural variety, novelty) creativity on physicochemical tasks.
Task-Dependent Creative Behavior
LLMs consistently achieve high convergent creativity on physicochemical and ADMET tasks but virtually no success on protein-binding activity objectives in the absence of in-context support, while exploration (diversity, novelty) remains high in both. This dichotomy underscores a strong dependence on the prevalence of task-aligned patterns in pretraining data, with LLMs failing to generalize to bioactivity constraints not well reflected in training corpora.
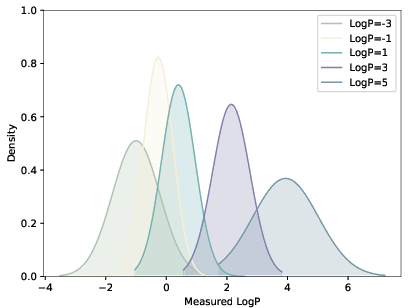
Figure 3: Generated LogP distributions shift in the direction of the specified numerical constraint, but precise control is limited to the distributional level.
Model Scaling and Its Consequences
Larger models (70B+ parameters) exhibit robust improvements in chemical validity and constraint success but suffer notable drops in both diversity and uniqueness. Small models (8B) produce a greater proportion of "Fully Creative" molecules, i.e., candidates that are simultaneously valid, novel, unique, and satisfiers of constraints, highlighting their utility in hypothesis generation and chemical exploration.
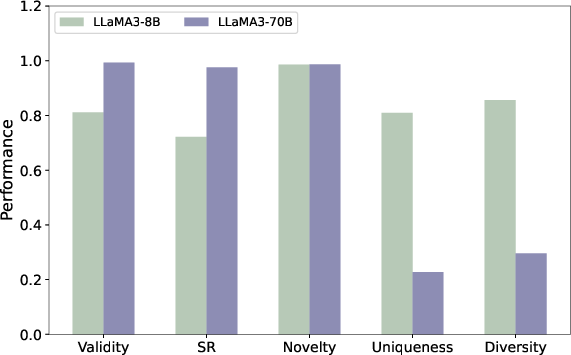
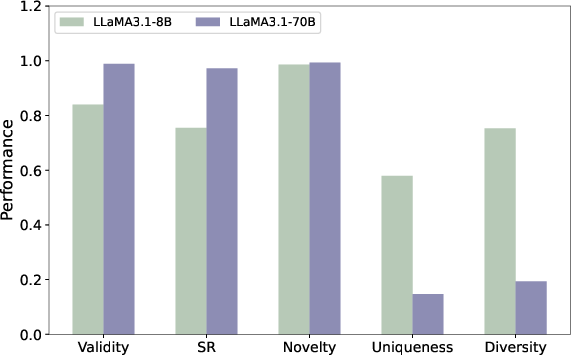
Figure 4: LLaMA3 series model size comparison—scaling up increases constraint satisfaction at the expense of exploration.
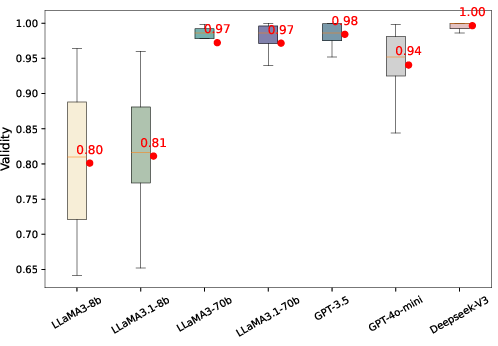
Figure 5: High validity is stably maintained by larger models, in contrast to increased variance in smaller models.
Combinatorial Constraints and Numerical Control
Contradicting intuition from unconstrained language generation, imposing additional, chemically compatible constraints (e.g., QED+SA) can increase the rate of constraint satisfaction, attributable to underlying correlations in chemical property space. Numerical constraint understanding is present only at the distributional, not exact, level (e.g., LogP modes shift, but broad output variance remains).
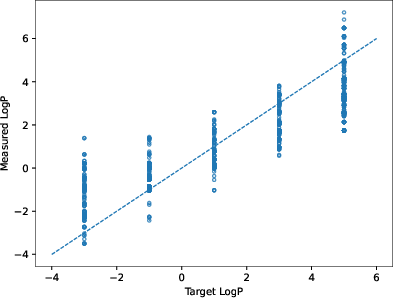
Figure 6: Conditional LogP distributions demonstrating strong, but not precise, alignment with numerical constraint targets.
In-Context Learning
ICL (10-shot) substantially augments convergent creativity for structure–activity prediction (SR increases from near-zero to as high as 0.70 in GSK3β tasks), but at the expense of novelty and uniqueness. Most successful molecules under ICL are structurally redundant, indicating a strong template bias inherited from provided examples, which limits the discovery of truly novel scaffolds.
Sampling Temperature as an Exploration-Exploitation Dial
Increasing decoding temperature enhances divergent creativity up to a critical threshold, beyond which validity and constraint fidelity collapse. Moderate temperature boosts diversity and uniqueness with minimal loss of success, making it a practical inference-time parameter for tailoring output profiles conditional on application goals.
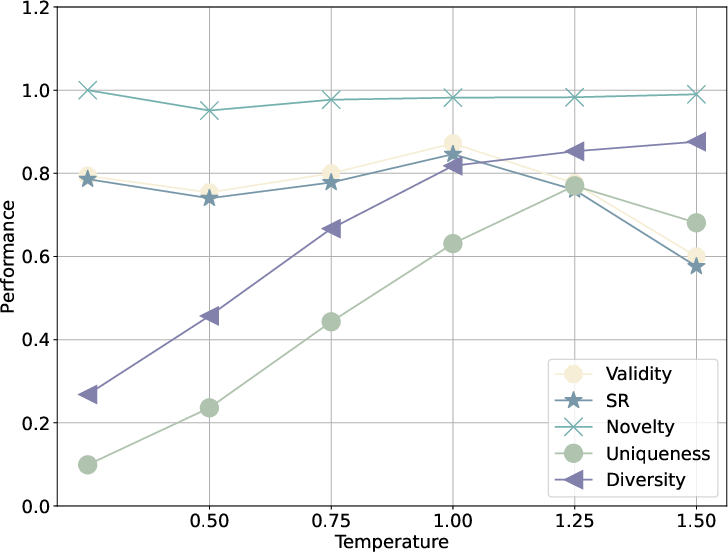
Figure 7: Sampling temperature mediates the trade-off between constraint satisfaction and diversity, facilitating controllable exploration.
Practical and Theoretical Implications
The empirical dissection provides rigorous evidence supporting several practical recommendations:
- LLMs are best deployed for molecular generation tasks defined by global physicochemical or ADMET properties learned from large-scale data, not for target-specific activity optimization unless fine-grained data and in-context examples are available.
- Smaller LLMs may be more appropriate than larger LLMs for hypothesis generation and scaffold diversification in early-stage discovery.
- Combinatorial constraint specification, when properties are compatible, may fortify overall design efficacy rather than induce detrimental specialization.
- Temperature tuning should be standard practice in LLM-aided discovery to balance exploration and reliability; in-context learning should be used judiciously with awareness of its tendency to induce structural mode collapse.
For future research, these findings anticipate the need for improved pretraining strategies incorporating richer structure–activity data, novel training curricula that balance creativity dimensions, and hybrid generator–predictor pipelines that synergistically optimize both constraint satisfaction and chemical exploration.
Conclusion
This work provides the first systematic, quantitative framework for assessing and comparing the creative behavior of LLMs in molecular generation. By rigorously separating and measuring convergent and divergent creativity, it is possible to both elucidate the practical limits of current LLMs and derive actionable guidelines for their optimization in molecular discovery pipelines. The geometric mean–based aggregation scheme enforces a mathematically grounded, application-relevant notion of creativity that penalizes unbalanced or degenerate solutions. As LLMs become increasingly central in generative chemistry, frameworks such as this will be crucial for unbiased performance analysis and principled method development.