Neural Garbage Collection: Learning to Forget while Learning to Reason
Abstract: Chain-of-thought reasoning has driven striking advances in LLM capability, yet every reasoning step grows the KV cache, creating a bottleneck to scaling this paradigm further. Current approaches manage these constraints on the model's behalf using hand-designed criteria. A more scalable approach would let end-to-end learning subsume this design choice entirely, following a broader pattern in deep learning. After all, if a model can learn to reason, why can't it learn to forget? We introduce Neural Garbage Collection (NGC), in which a LLM learns to forget while learning to reason, trained end-to-end from outcome-based task reward alone. As the model reasons, it periodically pauses, decides which KV cache entries to evict, and continues to reason conditioned on the remaining cache. By treating tokens in a chain-of-thought and cache-eviction decisions as discrete actions sampled from the LLM, we can use reinforcement learning to jointly optimize how the model reasons and how it manages its own memory: what the model evicts shapes what it remembers, what it remembers shapes its reasoning, and the correctness of that reasoning determines its reward. Crucially, the model learns this behavior entirely from a single learning signal - the outcome-based task reward - without supervised fine-tuning or proxy objectives. On Countdown, AMC, and AIME tasks, NGC maintains strong accuracy relative to the full-cache upper bound at 2-3x peak KV cache size compression and substantially outperforms eviction baselines. Our results are a first step towards a broader vision where end-to-end optimization drives both capability and efficiency in LLMs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching a LLM (like ChatGPT) not only how to think step by step, but also how to clean up its own “scratchpad” as it thinks. The authors call this idea Neural Garbage Collection (NGC). It helps the model remember what’s important and forget what’s not, so it can keep reasoning well without running out of memory.
What questions were the researchers asking?
- Can a LLM learn, by itself, when to forget old information while it is reasoning—without humans writing special rules?
- If the model learns to manage its own memory, can it keep high accuracy while using much less memory?
- Is it possible to train both “how to think” and “what to forget” using just the final result (right or wrong) as the learning signal?
How did they do it? (Methods explained simply)
Think of the model’s short-term memory (called the KV cache) like a desk covered in sticky notes. Chain-of-thought reasoning means the model writes lots of notes. That helps it think, but the desk fills up fast. NGC teaches the model to pause and tidy the desk regularly, keeping only the notes it still needs.
Here’s the basic cycle, described with everyday analogies:
- The model “thinks” for a few steps.
- It takes a “clean-up break” (an eviction round): it looks over all the notes on its desk and scores how useful each one seems.
- It keeps some notes and throws away others, then continues thinking using only what remains.
To make this work, the researchers combined a few ideas:
- Scoring importance with attention: Models already have a built-in way to measure what’s relevant (attention scores). The model reuses these scores to judge which notes (memory entries) matter.
- Cleaning in chunks: Instead of deciding on each tiny note one-by-one, the model groups neighboring notes into blocks and keeps or removes whole blocks. This makes decisions simpler and more stable.
- Picking what to keep with “weighted randomness”: The model doesn’t always take the top-scoring blocks; it uses a method like “rolling weighted dice” (a trick called Gumbel top-k) so it can explore different choices and learn what works best.
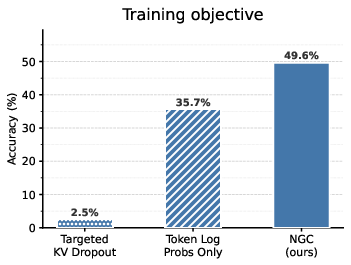
- Learning from outcomes only: The model treats both writing a token and choosing what to forget as actions. It tries a full solution, gets a simple reward (correct or incorrect), and then adjusts both its thinking and its clean-up strategy to do better next time. This is reinforcement learning: learning by trial, error, and reward.
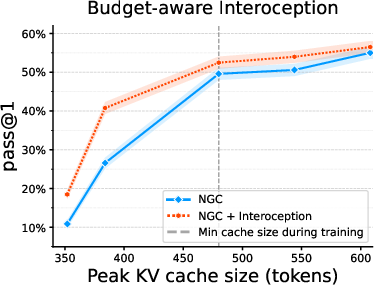
- Budget-aware interoception: During training, the model is told how strict the memory budget is (like being told “you can only keep half your notes”). This helps it plan ahead and generalize to different budgets.
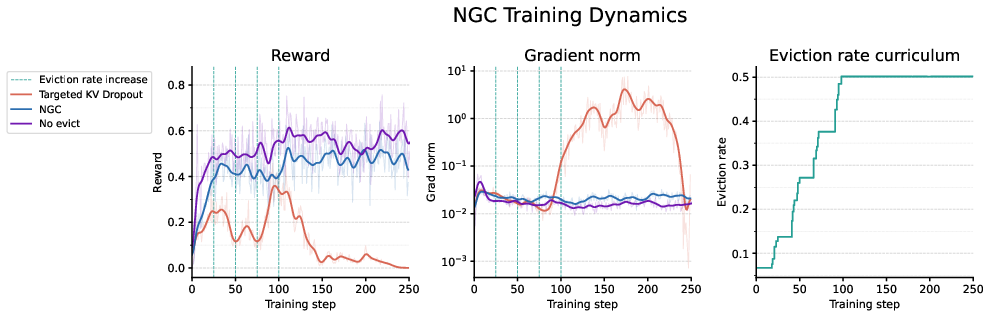
- A gentle start: At first, the model forgets only a little. Over time, it learns to forget more while staying accurate. This “eviction curriculum” keeps training stable.
Big picture: The memory no longer grows forever. With regular clean-ups (how often and how much to forget), the peak memory stays around a fixed size, set by the “budget” the model was trained to handle.
Key terms in plain language
- Chain-of-thought: The model writes out its reasoning steps before answering.
- KV cache: The model’s short-term memory of past tokens that helps it know what came before (like a desk full of sticky notes).
- Eviction: Deleting some memory entries (throwing away sticky notes) to save space.
- Attention scores: The model’s built-in “importance meter” for how relevant older notes are to what it’s thinking about now.
- Reinforcement learning (RL): Learning by trying, seeing if the result is good or bad, and adjusting actions to improve future results.
What did they find?
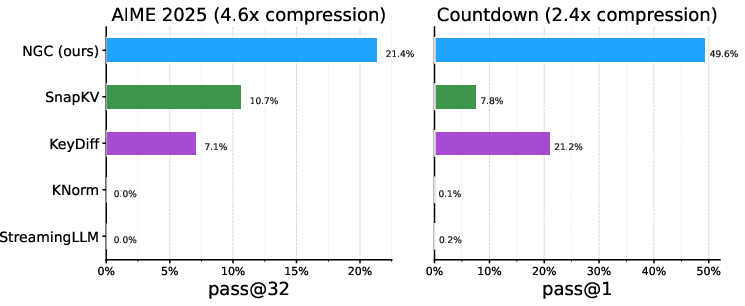
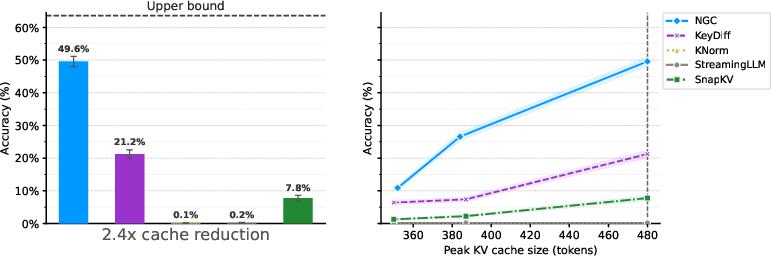
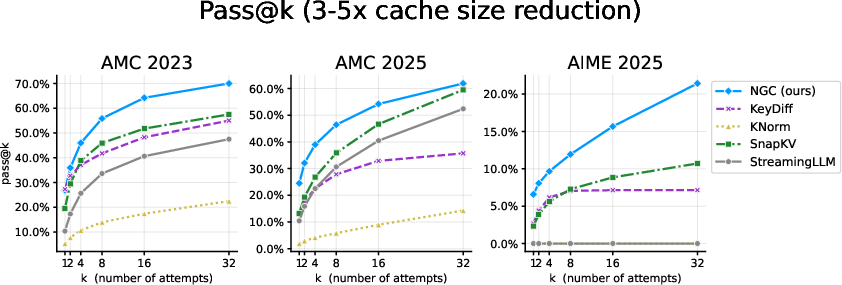
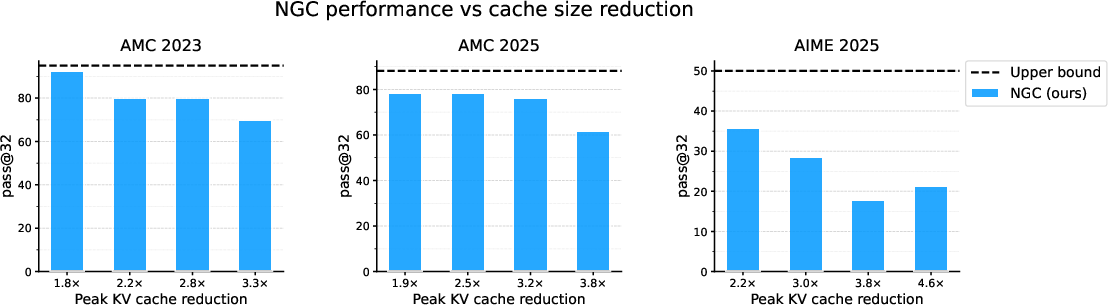
- Strong accuracy with much less memory: On math and reasoning tasks (Countdown, AMC, AIME), the model kept high accuracy while cutting peak memory use by about 2–3×.
- Big gains over hand-made rules: On the Countdown task, NGC more than doubled the accuracy of the next-best memory-management method at a similar memory budget (49.6% vs. 21.2%), while shrinking peak memory about 2.4×.
- Consistent wins on math benchmarks: On AMC and AIME, NGC outperformed several popular eviction strategies (like SnapKV and StreamingLLM) while keeping memory low.
Why this matters: It shows a model can learn to be both smart and efficient—without extra labels, special losses, or hand-coded rules. The only training signal was whether the final answer was correct.
Why is this important?
- Longer, cheaper reasoning: If a model can clean its own scratchpad, it can think through longer problems without running out of memory, and it can do so using fewer resources. That saves time and money.
- Efficiency as a learned skill: This reframes efficiency as something a model can learn—just like reasoning or language. Future models might learn other resource skills too (like when to use heavy compute or how to route information).
- Practical impact: Better memory management means running strong models on smaller devices, handling bigger tasks on the same hardware, and reducing the environmental footprint of AI.
Bottom line
Neural Garbage Collection teaches a model to “forget on purpose” while it reasons. By treating both tokens and forgetting decisions as actions and learning from the final outcome, the model keeps what matters, drops what doesn’t, and solves problems accurately with much less memory. This is a step toward AI systems that improve not only in what they can do, but in how efficiently they do it.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following concrete gaps highlight what remains uncertain or unexplored and can guide follow‑up research:
- Scalability to larger models and broader tasks: Does NGC maintain stability, accuracy, and compression benefits on 7B–70B+ LMs and across domains beyond math/Countdown (e.g., long-form QA, code, multi-hop retrieval, tool-use, multi-turn dialogue)?
- Generalization to naturally long contexts: How does NGC perform on tasks with thousands to tens of thousands of tokens (e.g., book QA, legal/biomedical documents) where KV growth and long-range dependencies are more extreme?
- Inference-time determinism vs stochasticity: The method samples evictions during training; what eviction policy is best at inference (deterministic top‑k vs sampling)? How do choices affect accuracy variance, reproducibility, and latency?
- Stability and variance of RL signal for evictions: Eviction actions use outcome-only, binary rewards across long horizons; what variance-reduction or credit-assignment schemes (e.g., per-round baselines, TD/value critics) are needed to stabilize learning at larger scales?
- Reward sparsity and credit assignment: Is outcome-only reward sufficient when horizons are long and evictions occur many times? Would carefully designed but minimal shaping (e.g., partial-credit or stepwise verifiable checks) improve sample efficiency without undermining the “tabula rasa” goal?
- Sensitivity to hyperparameters: Impact of block size b, scoring window w, eviction cadence δ, and eviction rate ε on accuracy/compression/variance is not systematically characterized; guidelines for tuning and task‑dependent defaults are missing.
- Adaptive eviction cadence and rate: NGC uses fixed eviction rounds and rates with a curriculum; can the model learn when and how aggressively to evict based on internal state or difficulty signals, potentially improving budget use under dynamic constraints?
- Budget-aware prompting (“interoception”): Including the budget in prompts improves cross-budget generalization, but how robust is this to mismatched or noisy budget signals? What is the best format and timing for budget conditioning?
- Parameterization limits of attention-based scoring: Reusing attention scores to value keys assumes they are reliable retention signals. Are learned, dedicated scoring heads, cross-layer features, or learned mixture policies superior, especially under distribution shift?
- Per-layer independent evictions: Evictions are chosen separately per layer. Does coordinating evictions across layers (or sharing decisions) improve consistency, reduce redundancy, or better preserve multi-layer computations?
- Cross-layer credit assignment: How to attribute reward to evictions in particular layers when downstream errors arise from complex inter-layer interactions? Can per-layer advantages or layer-specific critics improve learning?
- Block-level granularity: Coarsening to fixed-size blocks simplifies credit assignment but may evict useful subspans. Can variable-sized, content-aware, or learned segmentation improve retention–compression trade-offs?
- Prefill (prompt) evictions: Both prefill and generation tokens are eligible for eviction. What are the safety and instruction-following risks of forgetting system or policy tokens, and should policy guardrails be exempt?
- Interaction with standard KV optimizations: How does NGC integrate with FlashAttention, paged KV (e.g., vLLM), quantized caches, speculative decoding, and batching across many sequences? Do eviction rounds or replay masks introduce throughput/fragmentation regressions?
- Training/inference compute and latency costs: What is the total overhead of scoring (across layers, with window w), Gumbel top‑k sampling, and replay-mask computation? Are end-to-end throughput and energy improved after accounting for these costs?
- Off-policy biases and replay masks: Replay masks correct token log-probabilities, but do they fully eliminate subtle off-policyness when recomputing eviction log-probs across layers and rounds, especially under parallelism and kernel fusions?
- Numerical stability of Gumbel-top‑k log-probabilities: The proposed prefix-sum trick avoids repeated logsumexp; how stable is this for large N, and does it introduce approximation or gradient bias in practice?
- Safety under extreme compression: How does performance degrade as budgets become very tight (e.g., 5–10x compression)? Does the policy learn brittle shortcuts or hallucinations when forced to forget aggressively?
- Catastrophic interference with general LM ability: Does post-training with NGC degrade full-cache or zero-eviction performance, general perplexity, or non-reasoning tasks? Are there methods to preserve base capabilities (e.g., alternating objectives or LORA adapters)?
- Comparison to learned compression baselines: The paper compares to hand-designed eviction heuristics; direct empirical comparisons to training-based methods (e.g., Breadcrumbs, Memento, distillation/compression models) under matched budgets are missing.
- Complementarity with sparse attention and MoE: Can NGC be combined with sparse attention (read-time sparsity) or MoE routing (compute sparsity) to jointly optimize memory and compute? How to train unified policies under a single outcome reward?
- Handling multi-turn dialogues and session memory: How does NGC extend to conversational settings where retaining earlier turns can be crucial? Should budgets be allocated across turns with policy-learned prioritization?
- Evaluation beyond accuracy: Does NGC affect faithfulness, reasoning trace quality, calibration, or error types? Metrics that probe which information is retained vs forgotten would illuminate learned forgetting strategies.
- Theoretical guarantees and analysis: Beyond the steady-state cache bound , are there bounds on regret, convergence, or optimality of eviction policies under assumptions on token utility? Formalizing the trade-off between eviction and downstream task reward remains open.
- Security and adversarial robustness: Can adversarial prompts induce the model to evict critical context (e.g., instructions or safety constraints)? Are there mechanisms to robustly protect certain spans while keeping learning end-to-end?
- Resource-aware multi-objective training: The current setup enforces resource use via fixed eviction fractions; can budget constraints be optimized jointly with task reward (e.g., via Lagrangian relaxation) to learn task/resource Pareto frontiers automatically?
Practical Applications
Practical applications of “Neural Garbage Collection: Learning to Forget while Learning to Reason”
NGC trains LLMs to manage their own KV-cache memory while reasoning, using a single outcome-based reward and no proxy losses. It achieves 2–3x peak KV cache compression at comparable accuracy on reasoning tasks by:
- Treating cache eviction as a discrete action sampled from the LM (via Gumbel top-k) and optimized with policy gradients alongside tokens.
- Using block-level evictions parameterized by native attention scores (no new modules), and replay attention masks to compute exact rollout log-probabilities.
- Maintaining constant-memory decoding under a grow-then-evict cycle and exposing budgets via “budget-aware interoception.”
Below are concrete, sector-linked applications, grouped by deployment horizon. Each item notes key assumptions/dependencies that affect feasibility.
Immediate Applications
These are deployable with RLVR-capable training pipelines and modern inference stacks (e.g., vLLM with paged KV caches), especially for chain-of-thought style models.
- Cost- and memory-efficient chain-of-thought serving for LLM APIs (software/AI infrastructure)
- Use case: Reduce per-request VRAM and increase throughput (2–3x peak KV reduction) for reasoning-heavy endpoints without changing base architecture.
- Tools/products: “NGC-Serving” plugin for vLLM/Hugging Face; server knobs for eviction cadence and rate; budget-aware prompt controls (“fast/cost-saver” modes).
- Assumptions/dependencies: Requires NGC-style RL finetuning with verifiable rewards; inference engine must support pause-and-evict rounds and block-level eviction.
- Multi-tenant GPU utilization and SLA-based budgeting (cloud platforms/DevOps)
- Use case: Serve more concurrent reasoning sessions per GPU with predictable steady-state memory (L·δ/ε), smoothing latency spikes and preventing OOM on long CoT.
- Tools/products: Autoscalers that set per-session memory budgets via interoception; dashboards showing per-layer eviction stats.
- Assumptions/dependencies: KV pagination compatible runtime (e.g., vLLM paging); policies to bound aggressive eviction that harms accuracy.
- On-device/offline assistants with longer reasoning under tight RAM (mobile/edge/IoT)
- Use case: Smartphones, wearables, smart speakers that need step-by-step reasoning without cloud, improving battery and responsiveness.
- Tools/workflows: “Edge Reasoning SDK” integrating NGC scheduler; budget sliders tied to battery/thermal status.
- Assumptions/dependencies: Small/medium LMs trained with NGC; task rewards available during training (e.g., math/verifiable Q&A).
- Privacy-preserving point-of-care or bedside decision support (healthcare)
- Use case: On-cart or handheld devices that must reason locally (e.g., triage protocols) with constrained memory and no data egress.
- Tools/workflows: Constant-memory inference paths; budget-aware prompts encoding device capability.
- Assumptions/dependencies: Clinical validation for target tasks; carefully chosen rewards and guardrails; acceptance that NGC was validated on math/reasoning—not clinical tasks.
- Long-dialog and meeting assistants with constant-memory reasoning (enterprise software/collaboration)
- Use case: Maintain high-quality reasoning over lengthy conversations without cache blow-up; prune scratch tokens dynamically.
- Tools/products: Chat systems exposing per-thread memory budgets; retention analytics for quality audits.
- Assumptions/dependencies: Robustness to open-domain dialogue vs math-focused training; trade-offs when evicting early history.
- Memory-aware RAG and tool-augmented pipelines (developer tools)
- Use case: In complex pipelines (retrieval, code execution), let the model learn to drop transient scratch computations while retaining key results, reducing cache bloat.
- Tools/workflows: Integrate NGC with RAG controllers; per-tool budgets via interoception prompts.
- Assumptions/dependencies: Reward must reflect end-task quality, not intermediate proxy metrics; engineering for eviction rounds between tool calls.
- Real-time robotics and embedded planning under tight budgets (robotics)
- Use case: Onboard planning that reasons longer with fixed memory footprints (e.g., drones, home robots).
- Tools/workflows: Eviction cadence synced to control cycles; “reasoning budget” tied to CPU/GPU load.
- Assumptions/dependencies: Reward-providing tasks (simulation or self-play) for stable RLVR; real-time constraints on pause-and-evict acceptable.
- Education and tutoring on low-cost devices (education)
- Use case: Step-by-step problem solving and explanations on tablets/classroom devices without cloud dependency.
- Tools/products: LMS-integrated NGC models with budget-aware profiles for lab vs home environments.
- Assumptions/dependencies: Curriculum-aligned rewards; evaluation beyond math tasks required for broad subjects.
- Energy/cost-aware deployment policies and reporting (IT governance/sustainability)
- Use case: Track and enforce energy-per-query reductions by using NGC models in cost-sensitive deployments.
- Tools/workflows: Internal procurement guidance favoring “learned-efficiency” models; dashboards for memory/energy KPIs.
- Assumptions/dependencies: Instrumentation for energy attribution; acceptance of RLVR training overhead to realize inference savings.
Long-Term Applications
These require additional research, scaling, or ecosystem support (e.g., broader rewardable tasks, hardware co-design, generalized benchmarks).
- Unified learned resource management across memory, compute, and routing (software/hardware co-design)
- Vision: Extend NGC to learn conditional compute (e.g., MoE routing), layer skipping, and scheduling under a single task reward.
- Potential products: “Self-budgeted LMs” that jointly optimize accuracy and cost in real time.
- Dependencies: Stable RL with multi-objective rewards; integration with kernels supporting dynamic sparsity.
- Constant-memory long-horizon agents and planners (autonomy/agents)
- Vision: Agents that carry out lengthy plans (code synthesis, scientific workflows) while keeping memory bounded by learned evictions and summaries.
- Workflows: Agent frameworks exposing per-phase budgets; learned keep/drop policies for tool outputs and retrieved docs.
- Dependencies: Reward signals for complex tasks; mechanisms to avoid catastrophic forgetting of critical context.
- Safety and privacy by design: learned forgetting of sensitive context (policy/compliance)
- Vision: Models that proactively evict or summarize sensitive intermediate data, aligning with data minimization and “right to be forgotten.”
- Tools: Policy-driven budget/retention profiles; audit logs of eviction decisions.
- Dependencies: Formal guarantees/audits for privacy; detection of sensitive content; avoiding performance degradation.
- Training-time memory/compute reduction (ML systems)
- Vision: Apply learned evictions to reduce activation/KV memory during training or finetuning, enabling larger batches or models on fixed hardware.
- Tools: Replay-mask analogs for backprop over pruned states; schedules integrated with optimizer steps.
- Dependencies: New theory/algorithms for coupling forward evictions with backward passes; stability of gradients.
- Multimodal memory management (vision/audio/video)
- Vision: Learned eviction of image patches, audio frames, or video tokens to keep multimodal context constant-size while preserving task-critical information.
- Products: Streaming captioners and copilots for AR with fixed memory budgets.
- Dependencies: Verifiable rewards in multimodal tasks; block definitions over non-text tokens.
- Hardware and runtime co-design (accelerators/runtime)
- Vision: Accelerators and runtimes optimized for block-level eviction, replay masks, and stochastic subset selection.
- Products: KV-cache “paging” hardware; compiler support for learn-to-evict primitives.
- Dependencies: Vendor adoption; standardization of block/page sizes; kernel support for mask replay.
- Sector-specific deployments with guaranteed budgets (healthcare/finance/legal/public sector)
- Vision: Certifiable “budget-aware” endpoints with predictable memory/cost envelopes for regulated environments.
- Products: Procurement standards that require efficiency-as-capability; benchmarks that score task quality at fixed memory budgets.
- Dependencies: Domain task rewards; third-party certifications; longitudinal validation beyond math/logic tasks.
- Dynamic budget negotiation and marketplace pricing (cloud economics)
- Vision: APIs where clients specify target accuracy/cost, and models negotiate memory budgets during inference.
- Products: Pricing tiers linked to eviction profiles and expected accuracy; on-the-fly budget adjustments.
- Dependencies: Robust generalization of budget-aware interoception; reliable accuracy-cost Pareto curves.
- Generalized selection beyond memory: learned retrieval/pruning (information systems)
- Vision: Reuse Gumbel top-k subset selection and replay-mask training for learned document/retrieval selection and pipeline pruning under task reward.
- Products: End-to-end optimized RAG with reward-driven retriever keep/drop decisions.
- Dependencies: Efficient logging of selection decisions and exact log-prob reconstruction; verifiable task rewards for end-to-end tuning.
- Standardized efficiency benchmarks and policies (academia/policy)
- Vision: Benchmarks that measure accuracy at fixed memory budgets and steady-state cache limits; policy guidance incentivizing learned efficiency.
- Products: Leaderboards reporting “accuracy @ memory budget”; funding criteria emphasizing efficiency-as-capability.
- Dependencies: Community adoption; transparent reporting of training vs inference costs.
Notes on feasibility and transferability:
- Current evidence is strongest on verifiable reasoning tasks (Countdown, AMC, AIME) with clear binary rewards; generalization to open-ended tasks needs study.
- Stable training relies on RLVR (e.g., Dr. GRPO), eviction curricula, replay masks, and block-level decisions; these add engineering complexity.
- While NGC introduces no architectural changes, inference engines must support pause-and-evict rounds and paged KV caches for best results.
- Aggressive budgets can harm accuracy; production deployments need monitoring and fallback policies.
Glossary
- AlphaZero: A reinforcement learning system that learns policies end-to-end from self-play without handcrafted heuristics. Example: "This follows the tabula rasa spirit of AlphaZero"
- autograd graph: The computational graph used by automatic differentiation to propagate gradients through operations. Example: "see Figure~\ref{fig:autograd} for a schematic of the desired autograd graph."
- block-level evictions: Removing or keeping contiguous groups of tokens (blocks) in the KV cache rather than individual tokens to simplify decisions and align with hardware. Example: "Coarsening the action space via block-level evictions"
- budget-aware interoception: Prompting the model with its resource budget so it can plan reasoning under constraints. Example: "â a technique we call budget-aware interoception."
- causal attention mask: An attention mask that only allows attending to past tokens, enforcing autoregressive generation. Example: "naively computing log-probabilities under a standard causal attention mask would be incorrect"
- chain-of-thought: A step-by-step reasoning trace generated before producing a final answer. Example: "As the LLM (LM) generates its chain-of-thought, it periodically enters an {eviction round}"
- conditional computation: Dynamically routing parts of the input to subsets of model parameters to save compute. Example: "A related line of work uses conditional computation to improve efficiency"
- Dr. GRPO: A specific RL training recipe (a variant used in RLVR-style training of LMs) for optimizing policies from grouped rollouts. Example: "We optimize using Dr. GRPO"
- eviction cadence: How often eviction rounds occur during generation, measured in tokens between rounds. Example: "we will refer to as the eviction cadence."
- eviction round: A step during generation where the model selects which KV cache entries to remove. Example: "it periodically enters an {eviction round}"
- Gumbel top-k: A stochastic sampling method that selects k items without replacement using Gumbel noise, enabling exact log-probabilities. Example: "samples cache evictions using those scores via Gumbel top-"
- group-normalized advantages: Centering rewards within a group of rollouts to compute advantages for policy gradient updates. Example: "Following GRPO~\citep{guo2025deepseekr1}, we compute group-normalized advantages:"
- indexer: A learned module that selects which tokens are attended to or retained, distinct from the main model. Example: "the indexer, which selects which tokens the model attends to, and the main model are not trained under a unified objective."
- KL-divergence: A measure of difference between probability distributions, often used as a training loss. Example: "a KL-divergence loss against the attention scores"
- KV cache: The store of key and value tensors that represent past context for transformer attention during decoding. Example: "every reasoning step grows the KV cache, creating a bottleneck to scaling this paradigm further."
- load-balancing: Regularization or constraints that encourage even routing of tokens/expert usage in conditional computation. Example: "load-balancing schemes rather than from downstream task reward"
- logsumexp: A numerically stable computation of the logarithm of a sum of exponentials, used in partition functions. Example: "i.e., computing a logsumexp times."
- mixture-of-experts (MoE): An architecture that routes tokens to one of several expert sub-networks to reduce per-token compute. Example: "as in mixture-of-experts (MoE) architectures"
- off-policyness: A mismatch between the data-generating policy and the policy used to compute log-probabilities, which can destabilize training. Example: "introducing a systematic off-policyness that causes training collapse."
- outcome-based task reward: A scalar reward based solely on the final task outcome (e.g., correctness), without intermediate supervision. Example: "trained end-to-end from outcome-based task reward alone."
- policy gradient: A family of RL algorithms that optimize expected reward by ascending the gradient of action log-probabilities weighted by advantage. Example: "We can perform the policy gradient update efficiently and correctly using replay attention masks."
- prefill: The initial tokens (e.g., prompt or input context) loaded into the KV cache before generation begins. Example: "Both prefill and generation tokens are eligible for eviction"
- prefix sum trick: A technique that uses cumulative sums to avoid recomputing expensive quantities repeatedly. Example: "We avoid this via a prefix sum trick that tracks the cumulative fraction of removed probability mass."
- reinforcement learning from verifiable rewards (RLVR): Training LMs with rewards that can be programmatically verified (e.g., correctness), enabling scalable self-improvement. Example: "The reinforcement learning from verifiable rewards (RLVR) paradigm"
- replay attention masks: Custom attention masks that reproduce exactly what was visible during rollouts to compute correct log-probabilities in parallel. Example: "We use {replay attention masks} to correctly and efficiently compute Equation~\ref{eq:token}"
- resource rationality: A framework that views cognition as optimizing performance under resource constraints. Example: "Resource rationality \citep{lieder2020resource} formalizes this perspective"
- softmax: A normalization function converting logits into probabilities by exponentiation and normalization. Example: "the LM scores KV cache entries via softmax"
- sparse attention: Attention mechanisms that limit which keys a query attends to, reducing computational cost. Example: "Sparse attention methods reduce the cost of attending over long contexts"
- state-space models: Sequence models (e.g., Mamba) that use state transitions rather than full self-attention to achieve efficiency. Example: "State-space models~\citep{gu2023mamba, dao2024mamba2} achieve efficiency through different computational primitives"
- tabula rasa: Training from scratch without prior handcrafted biases or supervision beyond the end objective. Example: "This follows the tabula rasa spirit of AlphaZero"
- vLLM: A system that manages KV cache with paged memory for efficient inference of large LMs. Example: "paged KV cache systems such as vLLM~\citep{kwon2023vllm}"
Collections
Sign up for free to add this paper to one or more collections.

