- The paper demonstrates that BPE-based tokenization lowers token-level entropy of secrets, making them more prone to memorization and leakage.
- It employs distributional analysis and KL divergence to reveal a long-tail token shift between regular code and secret tokenizations.
- Results indicate that expanding tokenizer vocabularies amplifies gibberish bias, urging the development of alternative tokenization methodologies.
Tokenization-Induced Secret Leakage in Code LLMs: The Gibberish Bias Phenomenon
Introduction
Code LLMs (CLLMs) have been extensively deployed as code generation assistants, significantly impacting the software development lifecycle by providing real-time support in coding, documentation, and automated testing. With model families such as Deepseek Coder, StarCoder2, and Qwen2.5-Coder, adoption has reached large-scale industry and open-source usage. However, concerns over the security and privacy risks posed by CLLMs have intensified, especially regarding the potential for code secret leakage—API keys, tokens, and other credentials embedded in source code—often caused by model memorization of sensitive data from training corpora. This paper rigorously analyzes a previously underappreciated factor: the interaction between secrets and CLLM tokenization, focusing on how Byte-Pair Encoding (BPE) induces a "gibberish bias" that increases the risk of secret memorization and leakage (2604.17814).
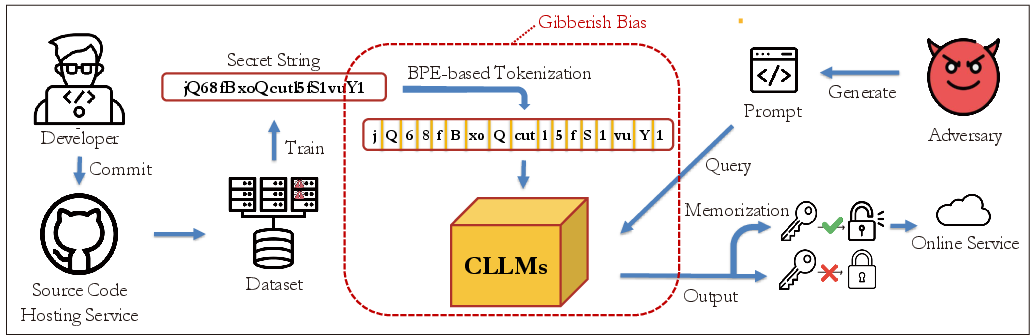
Figure 1: The risk map of secret leakage through CLLMs. The red box highlights the focus of this paper.
Tokenization and Its Role in Secret Memorization
Contemporary CLLMs universally employ subword tokenization, primarily BPE, for vocabulary construction and input text segmentation. BPE operates by iteratively merging the most frequent character pairs in pre-training corpora, thus creating a fixed corpus-adapted vocabulary. While such compression-oriented tokenization enhances model efficiency for code-like data, it overlooks the structural peculiarities of secrets, which are typically random, high-entropy strings crafted at the character level (e.g., "ghp_ABC123DEF...").
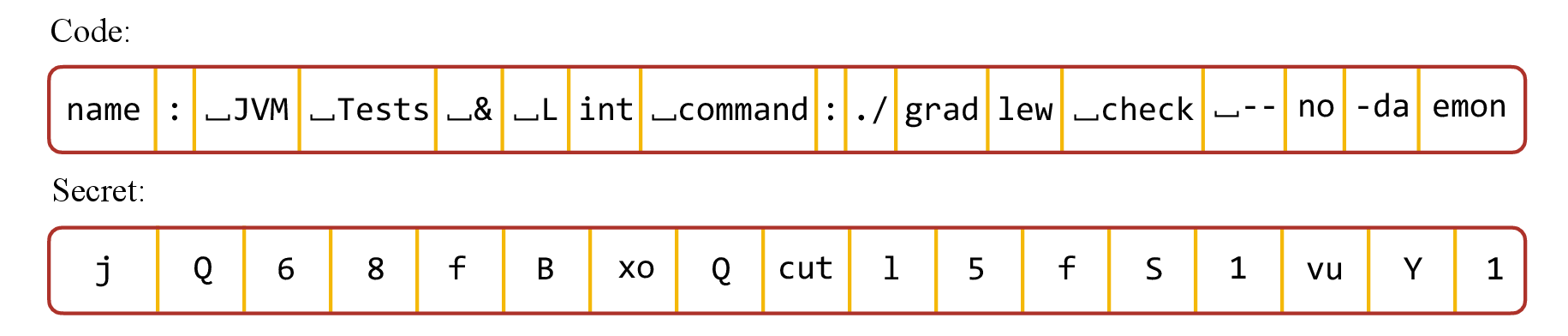
Figure 2: Use BPE to tokenize one line of normal code and secrets. Each token is a subword.
Notably, when processing secrets, BPE tokenizers generate token sequences that are anomalously non-uniform: many tokens map to single characters, a few to longer substrings, and, peculiarly, even English words sometimes appear in "gibberish" secrets. This non-uniform, long-tailed distribution strongly deviates from the maximal-entropy assumption held for secrets at the character level, resulting in reduced entropy at the token level.
Characterizing Gibberish Bias
The paper formalizes "gibberish bias" as follows: BPE-based tokenization transforms many high character-level entropy secrets into low token-level entropy tokenizations. As established experimentally, the normalized token-level entropy for secrets is markedly lower than for non-secrets, even as their character-level entropy remains high. This counterintuitive behavior occurs because the fixed BPE vocabulary, built on natural code data distributions, is ill-suited to segment highly-randomized secret strings.
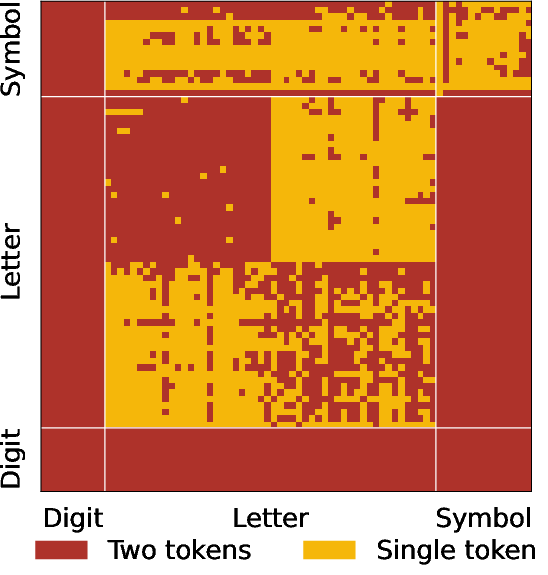
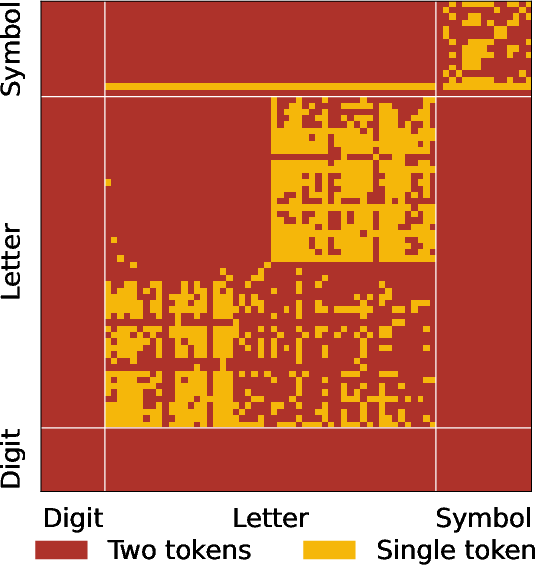
Figure 3: Visualizing how Qwen2.5-Coder and Deepseek Coder encode all 2-char substrings of secrets, revealing non-uniform and complex token splits.
Extensive experiments including manual labeling show that among highly memorized outputs ("zero-distance" cases), secrets are overrepresented by sequences with lower token entropy than matched non-secret sequences. The experimental finding is both strong and contrary to prevailing heuristic expectations derived from information theory, where higher entropy is conventionally perceived as offering better privacy protection.
Distributional Analysis: Token Shift Between Training Data and Secrets
A central empirical contribution is the characterization of the train-test distributional shift between standard CLLM code corpora and secrets. The analysis of token length and frequency reveals a pronounced long-tail distribution for secret tokenizations: while character-level secret entropy nearly maximizes the theoretical upper bound, token-level entropy is sharply decreased due to the tokenizer's limited vocabulary coverage on gibberish substrings.
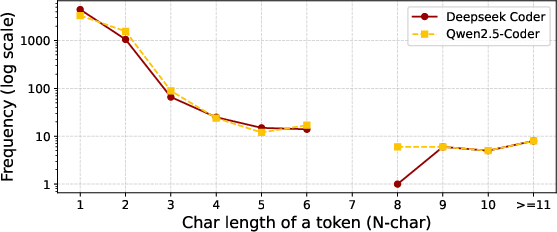
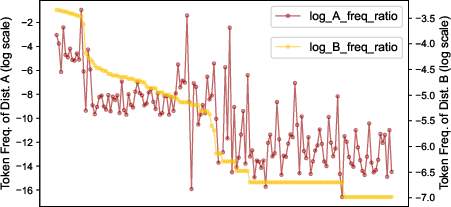
Figure 4: The distribution of n-char tokens for secrets; shows exponential decay with token length, indicating non-uniform token distributions.
KL divergence analysis quantifies this shift, confirming the substantial mismatch between code and secret token statistics under BPE tokenization.
Impact of Larger Tokenizer Vocabularies
Current trends advocate scaling vocabulary sizes in tandem with model size, aiming for improved code representation with optimal compression [tao2024scaling; huang2025overtokenized]. The paper demonstrates that larger BPE vocabularies do not alleviate, but actually accentuate, gibberish bias: the entropy gap between secrets and standard code widens as vocabulary increases, further reducing the effective entropy of secrets at inference time. Thus, the underlying security risk is amplified by the community's move to large-vocabulary models.
Mitigation Strategies and Future Tokenizer Design
The authors propose several mitigation strategies, including reverting to character-wise tokenization for recognized secret formats and direct removal of gibberish tokens (tokens predominantly found in secret, not code, datasets) from the vocabulary. Two approaches for token elimination are outlined: tokenizer mapping deletion and vocabulary reduction via cross-tokenizer distillation, enabling the exclusion of problematic tokens at tokenization or through model re-distillation.
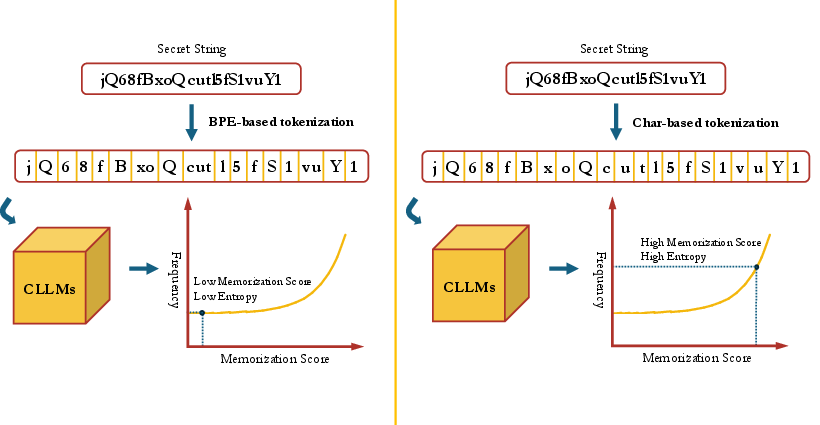
Figure 5: Mitigation Strategy Visualized—depicts the pipeline for identifying and eliminating gibberish tokens to mitigate leakage risk.
Additionally, ablation on alternative tokenization paradigms (e.g., unigram-based as in XLNet/T5) demonstrates persistence of gibberish bias, confirming its roots in data-driven subword vocabulary selection rather than BPE mechanics alone.
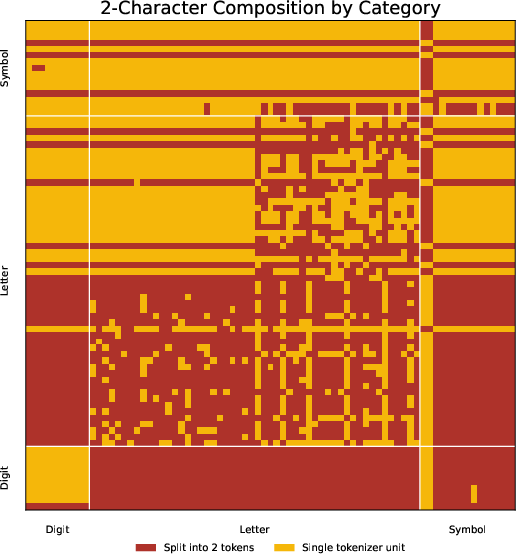
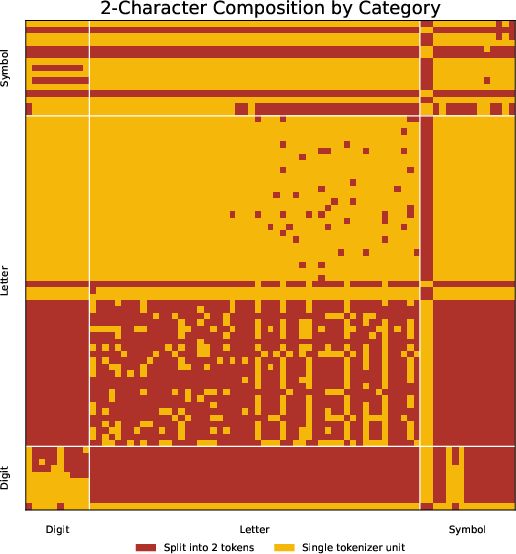
Figure 6: 2-char sub-string tokenization on unigram-based tokenizers: XLNet (left) and T5 (right); shows similar non-uniformities as BPE.
The analysis highlights the fundamental limitations of static, compression-driven tokenizers: lack of flexibility for post hoc adaptation and vulnerability under train-test distribution shift. This motivates research into adaptive or task-specific tokenizer construction, and potentially end-to-end differentiable or character-level tokenization models for improved privacy robustness.
Theoretical and Practical Implications
The study reveals that the tokenizer layer, often under-examined in AI safety, can introduce systematic memorization bias with severe practical implications: adversaries may exploit CLLMs to recover secrets with token distributions that are easier to memorize. This mandates coordinated action by code LLM designers, service providers, and the security research community. Furthermore, the paper calls for theoretical investigations into BPE and other subword tokenization algorithms, beyond empirical evaluation, to understand their generalization and memorization properties under distribution shift.
Conclusion
This work advances the understanding of CLLM secret leakage by uncovering and formally characterizing "gibberish bias," a systematic vulnerability introduced by BPE and related tokenization schemes. It demonstrates, both empirically and theoretically, that secrets—designed to be secure due to high character entropy—can be rendered easily memorizable and leakable through the low-entropy, long-tailed token representations forced by CLLM tokenization. These findings demand new mitigation mechanisms, as well as principled rethinking of tokenizer design for security- and privacy-critical applications in AI.
Reference: "Understanding Secret Leakage Risks in Code LLMs: A Tokenization Perspective" (2604.17814).