Whisper Leak: a side-channel attack on Large Language Models
Abstract: LLMs are increasingly deployed in sensitive domains including healthcare, legal services, and confidential communications, where privacy is paramount. This paper introduces Whisper Leak, a side-channel attack that infers user prompt topics from encrypted LLM traffic by analyzing packet size and timing patterns in streaming responses. Despite TLS encryption protecting content, these metadata patterns leak sufficient information to enable topic classification. We demonstrate the attack across 28 popular LLMs from major providers, achieving near-perfect classification (often >98% AUPRC) and high precision even at extreme class imbalance (10,000:1 noise-to-target ratio). For many models, we achieve 100% precision in identifying sensitive topics like "money laundering" while recovering 5-20% of target conversations. This industry-wide vulnerability poses significant risks for users under network surveillance by ISPs, governments, or local adversaries. We evaluate three mitigation strategies - random padding, token batching, and packet injection - finding that while each reduces attack effectiveness, none provides complete protection. Through responsible disclosure, we have collaborated with providers to implement initial countermeasures. Our findings underscore the need for LLM providers to address metadata leakage as AI systems handle increasingly sensitive information.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
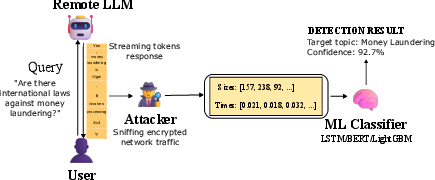
This paper looks at a privacy problem with AI chat systems called LLMs. Even when your messages to an AI are encrypted (so no one can read them), a watcher on the network can still see the size of the data pieces being sent and the timing between them. The authors show that by studying those sizes and timings during a live, streaming AI response, an attacker can guess what topic you asked about—especially sensitive topics—without ever seeing the actual words. They call this attack “Whisper Leak.”
What questions did the researchers want to answer?
The paper explores three simple but important questions:
- Can a network observer, like an internet provider or someone on public Wi‑Fi, figure out the topic you asked an AI about just from encrypted traffic patterns (packet sizes and timing)?
- How well does this attack work across many popular AI models from different companies?
- Which defenses (like adding random noise or bundling tokens together) can reduce this risk, and how much do they help?
How did they do the research?
Think of each AI response as a stream of tiny “envelopes” (network packets) going back to you. The envelopes are sealed (encrypted), so you can’t see inside, but you can see:
- How big each envelope is.
- How quickly the envelopes arrive, one after the other.
LLMs often “stream” their answers token-by-token (a token is a piece of a word), which creates a pattern of envelope sizes and arrival times. Even with strong encryption (TLS), the size and timing of these envelopes aren’t hidden. That’s the “side channel.”
Here’s their approach in everyday terms:
- They picked one sensitive topic to test: questions about the legality of money laundering. They wrote 100 different versions of this question.
- They mixed those with over 11,000 random, everyday questions (from a public dataset) to simulate normal traffic.
- For 28 popular LLMs, they collected the encrypted network streams (just sizes and timings, no content) as the models answered the questions.
- They trained simple classifiers (think of them as guessers that learn patterns) to tell whether a stream likely came from the sensitive topic or from a random question. They tried three kinds of models:
- LightGBM: a fast, tree-based classifier.
- LSTM: a neural network good at sequences (like time series).
- BERT-based: a transformer model adapted to read sequences of discretized size/timing “tokens.”
A quick guide to terms:
- Packet: a chunk of data sent over the internet (our “envelope”).
- TLS encryption: locks the content so it’s unreadable, but the envelope’s size and timing are still visible.
- Streaming: sending response pieces as they’re produced, so text appears live.
- Classifier: a program that learns to tell “sensitive topic” vs. “not sensitive” from patterns.
- Precision and recall:
- Precision = “Of the times we flagged a message as sensitive, how often were we right?” (Avoids false alarms.)
- Recall = “Of all the sensitive messages that existed, how many did we correctly catch?” (Avoids missing true cases.)
- AUPRC (Area Under the Precision-Recall Curve): a score that summarizes how well the classifier balances precision and recall, especially when sensitive cases are rare.
What did they find, and why does it matter?
The main results:
- The attack works very well across many models. For most of the 28 LLMs, the classifiers scored above 98% AUPRC. In plain words: the patterns in the encrypted traffic were strong enough to reliably tell when the sensitive topic was being discussed.
- Even when sensitive questions are rare (like 1 in 10,000), many models still let the attacker be extremely confident. For 17 out of 28 models, the attack reached 100% precision at 5–20% recall. That means an attacker could pick out a portion of true sensitive conversations with basically no false alarms.
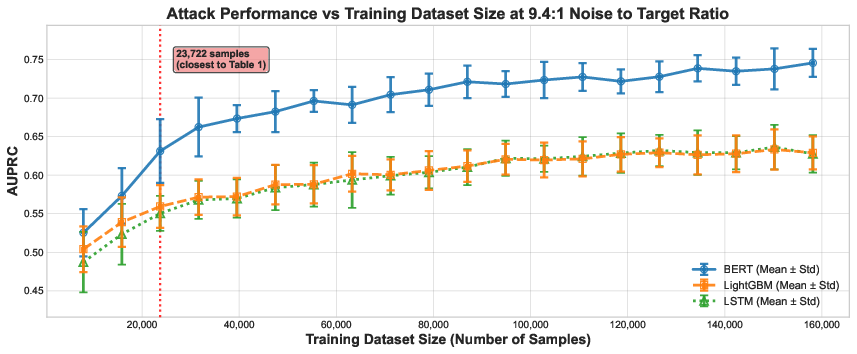
- More training data makes the attack stronger. When the researchers collected more examples, the classifiers improved. Real attackers with lots of data could do even better.
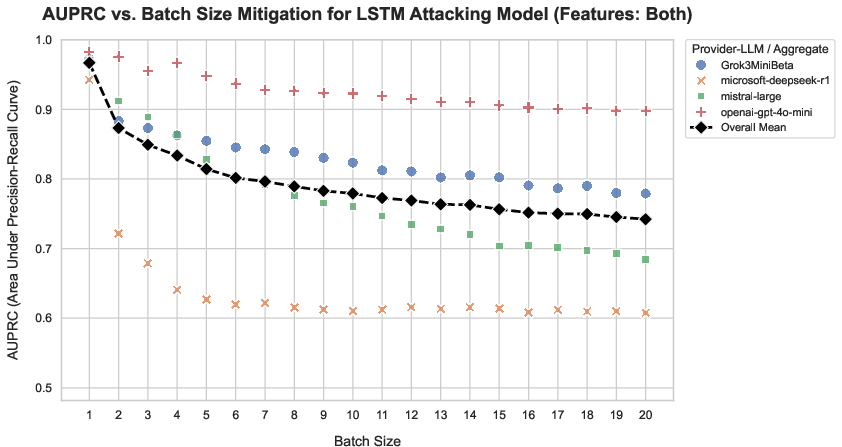
- Some defenses help, but none fix it fully:
- Random padding (adding random extra text to change packet sizes): reduces success noticeably, but patterns remain in timing and overall flow.
- Token batching (sending multiple tokens together instead of one by one): often helps, but not always enough.
- Packet injection (sending fake packets to add noise): also reduces success, yet doesn’t eliminate the leak.
Why it matters:
- This is an industry-wide privacy risk. It doesn’t break encryption, but it uses the “metadata” (sizes and timings) to guess sensitive topics. That’s dangerous for people in places where discussing certain topics can put them at risk.
- The problem comes from how LLMs stream responses and how encryption preserves data size relationships. It’s not a bug in TLS; it’s a design challenge in how AI responses are delivered.
What does this mean for the future?
In simple terms:
- AI chat systems should treat traffic patterns (sizes and timings) as sensitive information, not just the words themselves.
- Providers need stronger, practical defenses that hide or blur those patterns without making the chat feel slow or expensive. Today’s fixes (padding, batching, injection) improve privacy but don’t guarantee safety.
- The researchers responsibly told AI providers about the risk. Some, like OpenAI and Microsoft, have started adding padding to help. That’s a good step, but more robust protections and standards are needed.
Big picture takeaway:
- Even encrypted AI conversations can whisper clues through their “heartbeat” of data sizes and timing. As AI gets used for sensitive advice—health, legal, or personal topics—defending against these leaks will be key to keeping users safe.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to be actionable for future research.
- Topic coverage and generalization
- The evaluation uses a single sensitive topic (“legality of money laundering”). It is unknown whether results generalize across diverse sensitive topics (e.g., political dissent, LGBTQ+ issues in hostile jurisdictions, reproductive health, whistleblowing) or across multi-class topic classification.
- The attack’s robustness to non-English languages, code-generation tasks, and mixed-modality outputs (images, audio) is untested.
- Confounding factors and causal attribution
- It is unclear whether classifiers are primarily detecting provider-specific safety/disclaimer templates (i.e., stereotyped responses to illegal topics) rather than the topic itself. Controlled tests where models produce similar-length, similar-structure responses for non-sensitive topics, or where disclaimers are suppressed/neutralized, are needed.
- Output length and structure confounds are not controlled. The attack may rely on differences in total tokens or typical formatting patterns (e.g., lists, citations) induced by the topic. Experiments with fixed-length, fixed-format outputs (e.g., “respond in exactly N tokens”) would clarify causality.
- Real-world traffic realism and imbalance
- Precision at a 10,000:1 noise-to-target ratio is projected from test sets rather than empirically validated on truly imbalanced, in-the-wild traffic. Validation on live or realistically synthesized traffic distributions with calibrated thresholds is missing.
- Negative controls are limited to Quora Questions Pairs. It is unclear whether results hold for realistic LLM usage (code assistants, RAG systems, enterprise workflows, education tools) or for mixed app-layer traffic multiplexed with other services.
- The paper does not quantify early detection performance (e.g., classification using only the first K packets/tokens). Practical surveillances often require rapid decisions; early classification accuracy is unknown.
- Network and protocol heterogeneity
- Robustness across protocols (HTTP/1.1 vs HTTP/2 multiplexing vs HTTP/3/QUIC UDP), cipher suites, TLS versions, and record fragmentation is not studied. QUIC’s pacing, packet coalescing, and multiplexing could alter side-channel characteristics.
- Effects of HTTP-level compression (e.g., gzip/br compression of SSE/WebSocket payloads) on ciphertext size patterns are not evaluated.
- Vantage-point variability (ISP core vs last-mile Wi-Fi vs mobile networks) and network jitter/noise sensitivity are not quantified. Time-of-day load, CDN edge routing, path asymmetries, and ACK/directionality effects remain unexplored.
- Flow delimitation challenges under HTTP/2/HTTP/3 multiplexing (separating LLM streams from concurrent application streams on a shared connection) are not addressed.
- Client-side diversity and application framing
- Dependence on client transport (SSE vs WebSockets vs gRPC), SDKs, and browsers is unknown. Differences in framing (JSON chunking, event formatting) may create provider- and client-specific fingerprints.
- Impact of connection reuse, keep-alive settings, and transport flow control (e.g., HTTP/2 stream windows) on timing/size features is unexamined.
- Cross-provider and temporal transferability
- The attack is trained per provider-model. Transfer learning across models/providers (train on A, test on B) and across versions/releases (model updates, inference engine changes) is not evaluated.
- Stability over time (model updates, infrastructure changes, deployment configuration drift) and the adversary’s re-training maintenance costs are unknown.
- Multi-turn and user-level effects
- The paper does not test multi-turn conversations or aggregation across multiple interactions from the same user/IP, which could amplify signal.
- Session-level linking and cross-turn temporal patterns (including think modes, tool calls, and function-calling APIs) are not explored.
- Feature space and modeling choices
- Only packet sizes and inter-arrival times are used. The impact of directionality, burstiness features, cumulative size slopes, spectral/periodic features, and richer sequence encodings is not analyzed.
- Discretization choices (50 bins for sizes/times) and truncation lengths (255/511 tokens) are ad hoc; sensitivity analyses and continuous-feature transformer baselines are absent.
- Metrics, statistical rigor, and reporting
- AUPRC baselines are mischaracterized in places (e.g., “above random classification (50%)” is not generally the correct baseline for PR curves; the baseline is the positive class prevalence). Proper baselines, threshold calibration methods, and confidence intervals are needed.
- Results rely on medians across five trials without comprehensive confidence intervals, bootstrapping, or multiple-comparison corrections. More trials and formal uncertainty quantification would strengthen claims.
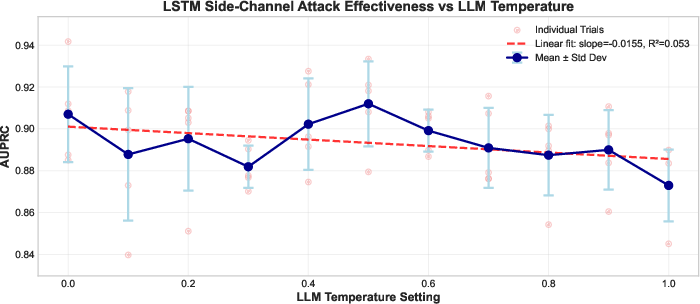
- The temperature ablation (single model, p=0.0986) is underpowered; broader, multi-model temperature sweeps with more trials are needed.
- Caching and provider-side variability
- Although space perturbations are used, the residual influence of provider-side caching (prefix/semantic) on timing/size remains unquantified. Controlled cache-hit/miss experiments are missing.
- Safety filter interventions and refusal behaviors reduce some noise samples; effects on class balance, model behavior, and attack accuracy are not analyzed.
- Mitigation realism and comprehensive evaluation
- Random padding is evaluated on one provider-model; token batching and packet injection are simulated offline rather than measured in real deployments. End-to-end impacts on latency, bandwidth, cost, and user experience are unquantified.
- Parameter sweeps and combinations of mitigations (e.g., padding + batching + injection) are not systematically studied, nor are adaptive attackers retrained against deployed defenses.
- Formal privacy guarantees for provider-side mitigations (e.g., differential privacy shaping) are not derived or empirically validated against strong adversaries.
- Practical deployment guidance (default parameters, overhead budgets, monitoring, rollback strategies) is absent, as are measurements on HTTP/3/QUIC stacks.
- Adversary identification and feasibility
- The paper assumes an adversary can reliably isolate LLM flows and identify provider endpoints. The effect of Encrypted ClientHello (ECH), SNI obfuscation, domain fronting, or shared CDNs on attacker feasibility is unaddressed.
- Attack performance with partial or lossy visibility (packet drops, sampling, NAT aggregation), and in environments with VPNs/Tor, remains unknown.
- Topic set scaling and data needs
- Scaling beyond 100 variants of one target topic to families of related topics (and overlapping semantics) is not tested. Data requirements per topic and cross-topic interference are open questions.
- The large-data ablation uses one provider-model; generalization of data scaling benefits across providers and under realistic class imbalance is unverified.
- Early-stage and online classification
- How quickly an adversary can reach target-level precision during a streaming response (online inference) is not measured. Stopping rules and decision latencies require evaluation.
- Reproducibility and artifacts
- Code, datasets, and capture tooling configurations (SSE vs WebSocket, HTTP version, cipher suites, TLS record handling) are not provided. Without artifacts, independent replication across environments is challenging.
Practical Applications
Immediate Applications
The following items translate the paper’s findings and methods into concrete, deployable actions for different stakeholders. Each bullet lists sector(s), use case, potential tools/products/workflows, and key assumptions/dependencies.
- LLM provider-side privacy hardening playbook
- Sectors: Software, Cloud AI platforms, CDNs
- Use case: Reduce side-channel leakage from streaming APIs using mitigations evaluated in the paper (random padding, token batching, packet injection).
- Tools/products/workflows:
- SDK flags to enable random-length padding in streamed fields (server-controlled or negotiated via API).
- Configurable batching (e.g., N-tokens per event, adaptive to latency SLOs).
- Traffic-shaping modules for packet injection at API gateways (e.g., Envoy/NGINX filters or service mesh extensions).
- Assumptions/dependencies: Access to server-side networking stack; willingness to trade some bandwidth/latency for privacy; compatibility with HTTP/2/HTTP/3 streaming; telemetry to tune parameters without leaking new identifiers.
- Leakage auditing and certification for AI APIs
- Sectors: Software, Security, Compliance
- Use case: Offer third‑party “metadata leakage” audits of streaming endpoints using the paper’s classifiers/metrics (AUPRC under imbalance, precision-at-recall).
- Tools/products/workflows:
- Automated harness that replays target/noise prompts and captures TLS metadata to produce a “leakage scorecard.”
- CI/CD gate that fails releases when leakage exceeds policy thresholds.
- Vendor badges (e.g., “Side-Channel Resistant: Level X”).
- Assumptions/dependencies: Provider buy-in for controlled testing; stable test corpora; reproducible network conditions or normalization methods.
- Enterprise risk assessment and procurement due diligence
- Sectors: Healthcare, Legal, Finance, Government, Enterprise IT
- Use case: Select LLM vendors/tiers with lower topic-leakage risk for sensitive workflows (PHI, PII, regulated topics).
- Tools/products/workflows:
- RFP/RFI requirements around streaming-leakage metrics; “non-streaming privacy mode” option.
- Internal red-team tests mirroring the paper’s methodology on shortlisted vendors.
- Assumptions/dependencies: Access to trial endpoints; legal authority to test; alignment with data-protection policies (HIPAA, GDPR).
- SOC and red-team methodology updates
- Sectors: Security Operations, MSSPs
- Use case: Integrate “LLM metadata privacy” into threat models, tabletop exercises, and adversary emulations.
- Tools/products/workflows:
- Playbooks covering exposure scenarios on hostile Wi‑Fi, ISP surveillance, or corporate egress monitoring.
- Canary prompts/workflows to detect unusual monitoring outcomes (e.g., targeted throttling/blocks when sensitive topics are discussed).
- Assumptions/dependencies: Legal/ethical boundaries; safe, non-harmful emulation (no targeting of real users).
- Privacy-preserving UX configurations for end users and app builders
- Sectors: Consumer Apps, Education, Journalism, Civil Society
- Use case: Offer app-level toggles to reduce leakage risk (e.g., disable streaming; coarse-grained chunking; “privacy mode” with padding/batching).
- Tools/products/workflows:
- Client SDKs exposing a “privacy-first” preset, with warnings about latency and bandwidth trade-offs.
- App copy that explains metadata exposure, aligned to the paper’s threat model.
- Assumptions/dependencies: Provider support for non-streaming or padded streaming; acceptance of UX trade-offs.
- Network-edge privacy gateways for regulated tenants
- Sectors: Healthcare, Finance, Government IT
- Use case: Deploy organization-controlled egress proxies that add packet injection/batching for LLM traffic only (domain/URL-based policies).
- Tools/products/workflows:
- Sidecar or forward proxy integrating timing/size obfuscation for specific destinations.
- Policy bundles that apply heavier protections for sensitive departments or topics.
- Assumptions/dependencies: Visibility into (and control over) egress; careful QA to avoid breaking HTTP/2/3 framing; performance budgets.
- Policy and compliance guidance updates
- Sectors: Policy, Compliance, Data Protection Offices
- Use case: Incorporate metadata leakage into DPIAs, privacy notices, and vendor risk frameworks.
- Tools/products/workflows:
- Template DPIA language on streaming side-channel risks; contractual clauses requiring mitigations and transparency of batching/padding parameters.
- Assumptions/dependencies: Regulatory acceptance of metadata as personal data in some jurisdictions; need for measurable vendor attestations.
- Incident response enhancements for high-risk populations
- Sectors: NGOs, Journalism, Human Rights, Legal Aid
- Use case: Advise at-risk users on safer LLM use in monitored networks (e.g., prefer on-device models, avoid streaming on hostile Wi‑Fi).
- Tools/products/workflows:
- Short guidance documents and checklists; curated toolkits (on-device LLMs; privacy networks; use of non-streaming modes).
- Assumptions/dependencies: Usability of alternatives; candid disclosure of residual risk (VPN/Tor can reduce observer scope but do not eliminate size/timing leakage).
- Academic benchmarking and replication kits
- Sectors: Academia, Security Research
- Use case: Standardize datasets, metrics, and pipelines to compare defenses and attacks (topic inference from TLS metadata).
- Tools/products/workflows:
- Open-source scripts for capture, featurization, model training (LightGBM/LSTM/BERT variants as in the paper).
- Leaderboards focused on precision under extreme class imbalance.
- Assumptions/dependencies: IRB/ethics review; non-identifying traffic capture; responsible release policies.
- Provider documentation and transparency reporting
- Sectors: Software, Cloud AI
- Use case: Disclose streaming behavior (batch size ranges, padding policies) and privacy-performance trade-offs.
- Tools/products/workflows:
- Model cards and API docs including “metadata privacy” sections; change logs when mitigation parameters change.
- Assumptions/dependencies: Competitive sensitivity; balancing transparency with not gifting adversaries exact defense parameters.
Long-Term Applications
The following items require further research, standardization, or engineering scale-out before broad deployment.
- Differentially private, protocol-level traffic shaping for AI streaming
- Sectors: Software, Networking, Standards
- Use case: Define QUIC/HTTP3 extensions or middlebox standards that provide formal DP guarantees for packet sizes/timings (generalizing systems like NetShaper to LLM workloads).
- Tools/products/workflows:
- IETF drafts for “oblivious” streaming profiles; tunable privacy knobs with provable epsilon-delta budgets.
- Assumptions/dependencies: Standards adoption; rigorous proofs vs. adaptive ML adversaries; acceptable performance overhead.
- Privacy “tiers” and SLAs for AI services
- Sectors: Cloud AI, Procurement, Compliance
- Use case: Offer contractual SLAs for metadata-leakage bounds (e.g., max precision at 10,000:1 for named sensitive-topic classes), with automatic audits.
- Tools/products/workflows:
- Managed “Privacy Enhanced Streaming” tiers with constant-rate windows, adaptive padding, and dynamic batching based on load/latency.
- Assumptions/dependencies: Reliable, independent verification; economic models for higher-cost privacy tiers.
- Oblivious inference relays and mix-based aggregation for AI traffic
- Sectors: Networking, Privacy Infrastructure, CDNs
- Use case: Route AI streaming via privacy relays/mixnets that aggregate and re-time flows to blur per-user traffic signatures.
- Tools/products/workflows:
- “Oblivious AI” relays (akin to OHTTP/Oblivious DoH concepts) that multiplex multiple clients and equalize burstiness.
- Assumptions/dependencies: Trust in relay operators; complexity of session stickiness and backpressure; residual fingerprinting risks.
- Hardware and NIC offload for padding/constant-rate transmission
- Sectors: Hardware, Cloud Infrastructure
- Use case: Offload padding, batching, and packet injection to smart NICs/DPUs to reduce CPU overhead and jitter while sustaining privacy envelopes.
- Tools/products/workflows:
- eBPF/DPDK pipelines; DPU-resident traffic shapers with per-tenant privacy policies.
- Assumptions/dependencies: Vendor support; correctness under HTTP/2/3 framing; hardware cost/benefit.
- Topic-aware adaptive defenses
- Sectors: Software, Applied ML Security
- Use case: Dynamically ramp up obfuscation when prompts likely touch sensitive categories (while using lighter settings otherwise).
- Tools/products/workflows:
- On-server classifiers with strict privacy controls; policy engines that trade latency for privacy by topic.
- Assumptions/dependencies: Accurate, fair, and safe topic detection without introducing new privacy risks; policy governance.
- End-to-end “privacy by design” protocols for generative streaming
- Sectors: Standards, Software, Research
- Use case: New streaming paradigms that decouple user-visible interactivity from network-visible token cadence (e.g., server buffers generate at native speed but emit to client at constant-rate, with cryptographic receipts for freshness).
- Tools/products/workflows:
- Protocol design combining pacing, padding, and authenticated freshness proofs.
- Assumptions/dependencies: UX acceptance of slight smoothing; protocol interoperability; formal analyses vs. advanced traffic-analysis ML.
- Certified evaluation suites for national/sectoral regulation
- Sectors: Policy, Regulators, Testing Labs
- Use case: Establish conformance tests for AI services handling regulated data (health, finance, children’s data), covering metadata leakage.
- Tools/products/workflows:
- Government-approved test harnesses; periodic audits; public registry of results.
- Assumptions/dependencies: Legislative mandate; inter-agency alignment; avoiding “teaching to the test.”
- Privacy-preserving client stacks and OS-level mediation
- Sectors: Operating Systems, Mobile Platforms, Browsers
- Use case: OS/browser features that detect AI streaming and apply per-app traffic shaping (user-controlled “Privacy Mode”).
- Tools/products/workflows:
- System APIs exposing constant-rate sockets or background padding; app entitlements with disclosure to users.
- Assumptions/dependencies: Platform vendor priorities; battery/network impact on mobile; developer adoption.
- On-device and edge inference for sensitive use cases
- Sectors: Healthcare, Legal, Education, Defense
- Use case: Push more inference on-device or at trusted edge to avoid wide-area streaming of token-by-token traffic.
- Tools/products/workflows:
- Hybrid pipelines: local draft + server refine without streaming; local “privacy-critical topics” handled entirely on device.
- Assumptions/dependencies: Model size/quality constraints; secure runtime; user hardware capabilities.
- Academic advances in robust defenses and realistic threat modeling
- Sectors: Academia, Security Research
- Use case: Extend beyond a single sensitive topic to multi-topic, multilingual, multi-turn scenarios; design adaptive attacks vs. mitigations; formalize lower bounds on leakage.
- Tools/products/workflows:
- Shared corpora; simulators injecting real network noise; benchmarks for defense robustness under distribution shift.
- Assumptions/dependencies: Ethical data collection; collaboration with providers; reproducibility across evolving APIs.
Notes on Feasibility and Dependencies
- Threat model dependence: Applications assume a passive adversary with traffic visibility (e.g., ISP, local Wi‑Fi). VPNs/Tor can change who the adversary is but do not eliminate size/timing leakage per se.
- Generalization: The paper’s demonstration centers on one sensitive topic (“money laundering”) and many models; performance for other topics/languages is plausible but requires validation.
- Performance trade-offs: All mitigations impose latency/bandwidth/compute overhead; sector adoption depends on SLOs and user tolerance.
- Evolving countermeasures: As providers change batching/padding strategies, audits and certifications must be continuous rather than one‑off.
- Legal/ethical constraints: Offensive use of these techniques raises serious concerns; all applications here are framed for defense, assurance, and policy compliance.
Glossary
- Ablation study: An experiment that removes or varies components (like data volume or parameters) to assess their impact on results. "Ablation study: Data volume"
- AES: A widely used symmetric block cipher that encrypts data in fixed-size blocks. "Block ciphers (e.g., AES): Encrypt data in fixed-size blocks (e.g., 16 bytes)."
- AES-GCM: An authenticated encryption mode (often used in TLS) that is treated here under stream cipher implementations. "Stream ciphers (e.g., ChaCha20, AES-GCM): Generate a pseudo-random keystream..."
- Area Under the Precision-Recall Curve (AUPRC): A metric summarizing precision-recall performance, suitable for highly imbalanced datasets. "We evaluate attack performance using Area Under the Precision-Recall Curve (AUPRC)"
- Asymmetric cryptography: Cryptography using key pairs (public/private) for tasks like key exchange and authentication. "A shared secret key is established using asymmetric cryptography (e.g., RSA, ECDH)."
- Attention mechanism: A neural network component that weights parts of a sequence to focus on relevant information. "An attention mechanism computed a weighted context vector from the LSTM outputs."
- Autoregressive process: A sequential generation method where each token depends on previously generated tokens. "LLM generation time is roughly proportional to the number of output tokens due to the autoregressive process"
- BERT-based: A classification approach leveraging a BERT-family transformer with adapted tokenization. "BERT-based: Leveraging a pre-trained transformer model (DistilBERT-uncased) using transfer learning for sequence classification..."
- Bidirectional LSTM: An RNN that processes sequences forward and backward to capture context from both directions. "Bidirectional LSTM layers processed the embedded sequences."
- Cache sharing: Using shared caches (e.g., prefix or semantic caches) across requests to accelerate inference, potentially leaking information via timing. "Efficient inference techniques like speculative decoding \cite{carlini2024remote} and cache sharing \cite{zheng2024inputsnatch} are sometimes employed to speed up this process..."
- ChaCha20: A stream cipher commonly used in secure protocols due to performance and security properties. "Stream ciphers (e.g., ChaCha20, AES-GCM): Generate a pseudo-random keystream..."
- Cipher Suite: A negotiated set of algorithms (for key exchange, encryption, authentication) used in a TLS session. "Client and server negotiate the TLS protocol version and a Cipher Suite, which defines the cryptographic algorithms to be used."
- Constant-Rate Transmission: A mitigation that sends packets at fixed sizes and intervals to hide size and timing patterns. "Padding and Constant-Rate Transmission: Padding packets to uniform sizes (e.g., MTU) and sending at fixed rates provides strong protection..."
- DistilBERT-uncased: A compact version of BERT that ignores case, used here for sequence classification. "Leveraging a pre-trained transformer model (DistilBERT-uncased) using transfer learning for sequence classification..."
- Early stopping: A training technique that halts optimization when validation performance stops improving to prevent overfitting. "The validation set was used for early stopping during training."
- ECDH (Elliptic Curve Diffie-Hellman): An elliptic-curve-based key exchange method used to establish shared secrets securely. "A shared secret key is established using asymmetric cryptography (e.g., RSA, ECDH)."
- Grover's algorithm: A quantum search algorithm that threatens some cryptosystems by offering quadratic speedup. "Symmetric ciphers are generally considered secure against known quantum attacks like Grover's algorithm."
- HTTP-over-TLS: The standard way HTTPS secures web traffic by running HTTP over TLS. "Communications with LLM services over the internet are typically secured using Transport Layer Security (TLS), most commonly via HTTPS (HTTP-over-TLS)."
- Inter-arrival times: The time gaps between consecutive packets, used as a side-channel feature. "For each response stream, we extracted the sequence of application data record sizes (derived from TLS record lengths) and the inter-arrival times between these records."
- Key-value caching: Storing computed key/value pairs from attention for reuse, improving speed but potentially affecting timing patterns. "attention mechanisms, potential Mixture-of-Experts architectures, key-value caching \cite{zheng2024inputsnatch}"
- LightGBM: A gradient boosting framework optimized for efficiency on large feature sets. "LightGBM: A gradient boosting framework."
- Middlebox: A network device/service that processes traffic (e.g., for privacy shaping) between endpoints. "Implemented as a middlebox, it protects multiple applications with tunable privacy-overhead tradeoffs..."
- Mixture-of-Experts: A model architecture that routes inputs to specialized expert subnetworks, affecting compute and timing. "potential Mixture-of-Experts architectures"
- MTU: Maximum Transmission Unit; the largest packet size allowed on a network link without fragmentation. "Padding packets to uniform sizes (e.g., MTU) and sending at fixed rates provides strong protection..."
- NetShaper: A differential privacy-based traffic shaping system offering formal privacy guarantees. "NetShaper \cite{sabzi2024netshaper} provides formal differential privacy guarantees by shaping both packet sizes and timing in periodic intervals."
- Noise-to-target ratio: The proportion of non-target to target samples, used to model extreme class imbalance. "10,000:1 noise-to-target ratio"
- OPriv: An optimization-based obfuscation method that mutates packet sizes to balance privacy and bandwidth. "OPriv \cite{chaddad2021opriv} uses nonlinear programming to select optimal packet size mutations that maximize obfuscation while minimizing bandwidth costs..."
- Packet injection: A defense that adds synthetic packets to obscure real size and timing patterns. "Packet Injection: Injecting synthetic packets at random intervals obfuscates both size and timing patterns."
- Passive network adversary: An eavesdropper who can observe encrypted traffic metadata but cannot modify or decrypt it. "We consider a passive network adversary - an ISP, government agency, or local network observer (e.g., coffee shop WiFi) - who can monitor encrypted traffic but cannot decrypt it."
- Precision-Recall Curve: A performance curve plotting precision versus recall across thresholds, useful for imbalanced data. "We evaluate attack performance using Area Under the Precision-Recall Curve (AUPRC)"
- Prefix caching: Reusing results when a prompt shares an initial segment with cached inputs, changing response timings. "cache-sharing optimizations (prefix caching and semantic caching) in LLM services."
- Quora Questions Pair: A dataset of diverse question pairs used here as negative (non-target) traffic. "Quora Questions Pair\cite{quora_questions} dataset"
- RSA: A public-key cryptosystem used for authentication and key exchange in TLS handshakes. "A shared secret key is established using asymmetric cryptography (e.g., RSA, ECDH)."
- Semantic caching: Reusing results when a prompt is semantically similar to cached inputs, influencing timing. "cache-sharing optimizations (prefix caching and semantic caching) in LLM services."
- Side-channel attack: An attack that infers information from indirect signals (like sizes or timings) rather than decrypting content. "This paper introduces Whisper Leak, a side-channel attack that infers user prompt topics from encrypted LLM traffic..."
- Speculative decoding: An efficient inference technique that predicts multiple tokens ahead to speed generation, affecting timing. "Efficient inference techniques like speculative decoding \cite{carlini2024remote}..."
- Stream cipher: A cipher that generates a keystream to encrypt variable-length data without padding. "Stream ciphers (e.g., ChaCha20, AES-GCM): Generate a pseudo-random keystream..."
- Streaming APIs: Interfaces that deliver model outputs incrementally token-by-token for responsiveness. "using their streaming APIs with a high temperature setting (Temperature = 1.0) to encourage response diversity."
- Symmetric cryptography: Encryption using the same key for both encryption and decryption during data transfer. "Symmetric cryptography: The shared secret key is used with a symmetric cipher for encrypting the actual application data."
- tcpdump: A command-line packet capture tool for recording network traffic. "We used cloud-hosted Ubuntu machines running the packet capture tool tcpdump to record the TLS traffic..."
- Temperature: A parameter controlling randomness in LLM outputs; higher values increase diversity. "LLM temperature is a parameter controlling the randomness of the output."
- Token batching: Grouping multiple tokens per network event to reduce leakage granularity. "Token Batching: Grouping multiple tokens before transmission reduces the granularity of leaked information..."
- Transformer model: A neural architecture using self-attention, foundational to modern LLMs like BERT. "Leveraging a pre-trained transformer model (DistilBERT-uncased) using transfer learning..."
- Transport Layer Security (TLS): A protocol providing confidentiality, integrity, and authenticity for internet communications. "Transport Layer Security (TLS)"
- XOR: A bitwise operation used to combine keystream and plaintext in stream ciphers. "This keystream is combined (usually via XOR) with the plaintext to produce ciphertext."
Collections
Sign up for free to add this paper to one or more collections.