- The paper introduces a voxel-space diffusion framework that predicts clean data directly, preserving anatomical details in 3D images.
- It employs sparse timestep scheduling and velocity supervision to significantly accelerate training and improve denoising stability.
- Experimental results on CT, PET, and MRI data show state-of-the-art improvements in PSNR, SSIM, and training efficiency with up to 10× faster convergence.
Structure-Adaptive Sparse Diffusion in Voxel Space for 3D Medical Image Enhancement
Introduction
The paper "Structure-Adaptive Sparse Diffusion in Voxel Space for 3D Medical Image Enhancement" (2604.17773) addresses the challenge of enhancing three-dimensional medical images, particularly in modalities like CT, MRI, and PET. The inherent issues of noise and poor resolution in these images, caused by constraints such as radiation dose, scan duration, and hardware limitations, necessitate effective enhancement techniques to improve diagnostic outcomes. Traditional methods, including slice-by-slice and 2.5D approaches, faced limitations in fully utilizing volumetric data, leading to inconsistencies and compromises in detail preservation. The advent of diffusion models offered a promising alternative, yet scaling them to high-resolution 3D imaging is computationally intensive.
Methodology
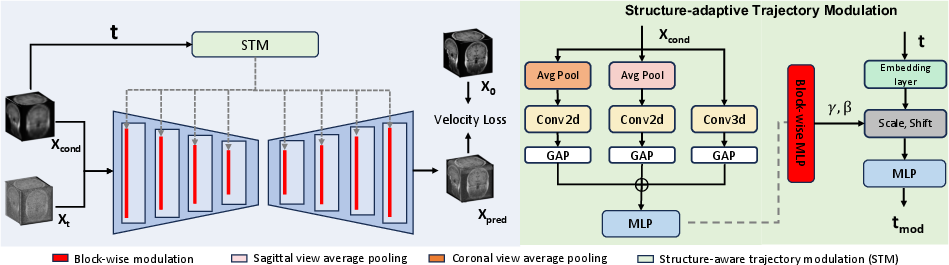
The authors propose a framework that operates directly in voxel space, eschewing lossy compressions common in generative models. By leveraging anatomical priors present in degraded inputs, the framework simplifies the diffusion process through sparse sampling, facilitating efficient training without compromising detail recovery. The methodology encompasses several innovations:
Structure-aware Trajectory Modulation
The Structure-aware Trajectory Modulation (STM) module is central to the proposed framework, introducing anatomical awareness within the diffusion process. STM employs multi-structure encoding to extract and integrate structural cues from various spatial dimensions of the input, adapting denoising behavior to local content variability:
- Multi-structure Encoder: Structural representation is derived from tri-planar projections, capturing distinct anatomical patterns across volumetric and 2D orientations.
- Block-wise Trajectory Modulation: Time embedding modulation occurs at each UNet block, permitting detailed anatomical encoding across network depths—facilitating differentiated denoising strengths based on local complexities.
Experimental Results
The experiments span denoising and super-resolution tasks across CT, PET, and MRI datasets, emphasizing the framework's robustness and efficiency. Results consistently demonstrate state-of-the-art performance, with notable gains in PSNR, SSIM, MS-SSIM, and HFEN metrics across all evaluations. The visual reconstructions validate the model's efficacy in recovering sharp anatomical details, highlighting its superiority over existing baselines.
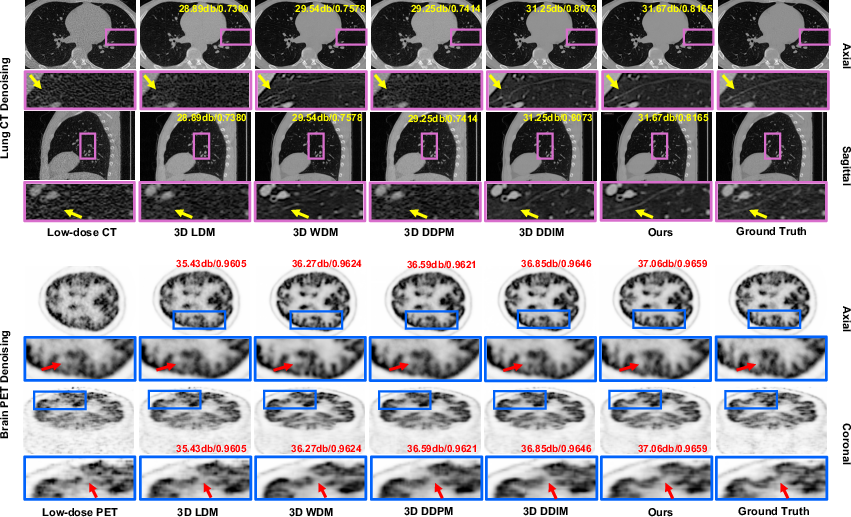
Figure 2: Qualitative denoising results on lung CT and brain PET. Our model preserves sharper, more structurally consistent details than all baselines.
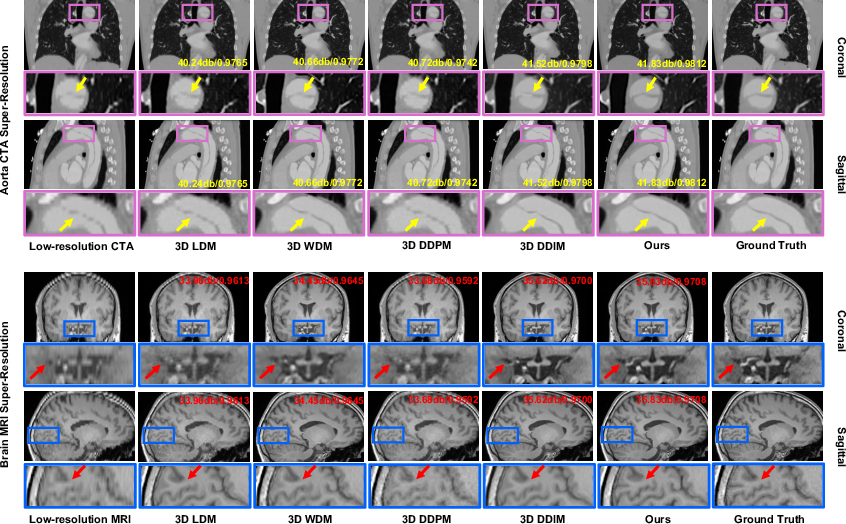
Figure 3: Qualitative 4× super-resolution results on aorta CTA and brain MRI. Our model recovers finer anatomical details with fewer artifacts than all baselines.
Furthermore, the computational advantage is manifest in the convergence curves, illustrating up to 10× faster training without sacrificing enhancement quality.
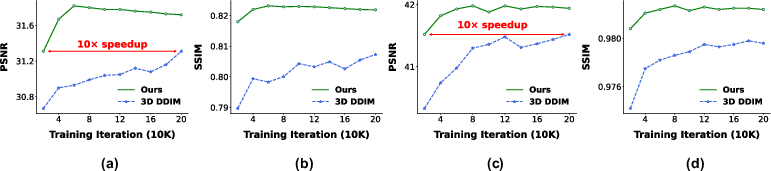
Figure 4: Training convergence curves for lung CT denoising and aorta CTA 4× super-resolution. Our method reaches the baseline's final performance with up to 10× fewer iterations.
Implications and Future Directions
This research contributes significantly to the domain of 3D medical image processing, providing a pathway to more efficient, anatomically adaptive enhancement approaches. The insights regarding anatomical priors and sparse diffusion trajectories offer avenues for further optimization in medical imaging technologies. The potential extension of these findings to other volumetric generative tasks underlines the versatility and applicability of the framework.
Conclusion
The proposed sparse voxel-space diffusion framework stands out by promoting efficient and high-quality 3D medical image enhancement. Through strategic anatomical encoding and sparse sampling, it achieves remarkable improvements in both computational speed and outcome fidelity. As medical imaging continues to evolve, the methods introduced herein set a foundational precedent for adaptive, efficient processing in clinical and research settings.