- The paper introduces Conditional Diffusion Posterior Alignment (CDPA), integrating conditional diffusion with data-consistency optimization to enhance sparse-view CT reconstruction.
- The paper demonstrates state-of-the-art performance on synthetic and real datasets by robustly reducing artifacts and preserving anatomical details in high-resolution volumes.
- The paper also presents an efficient FDK-denoising branch with slice-aware conditioning and uncertainty quantification, offering a practical solution for clinical CT imaging.
Conditional Diffusion Posterior Alignment for Sparse-View CT: A Detailed Examination
Motivation and Problem Context
Sparse-view CT reconstruction is central to minimizing both X-ray dose and acquisition time in medical and industrial tomography. The reduction in available projection views exacerbates the inherent ill-posedness of tomographic reconstruction, particularly in CBCT where volumetric coupling introduces pronounced streak artifacts and severe undersampling challenges. Traditional analytical algorithms (FDK/FBP) and hand-crafted iterative solvers break down in these regimes, either by producing structured artifacts or by extensive computational overheads with suboptimal reconstructions. Data-driven methods—particularly deep convolutional networks—have demonstrated artifact suppression capabilities, but scaling learned models to high-resolution 3D remains problematic due to memory, data, and architectural bottlenecks, especially with diffusion models.
Methodological Advances
This work introduces Conditional Diffusion Posterior Alignment (CDPA), which leverages the strengths of diffusion-based generative models while addressing their practical limitations for large 3D CBCT volumes. The framework integrates three synergistic ingredients:
- Conditional Diffusion Modeling: A 2D U-Net diffusion model is trained to predict denoising scores conditional on an initial FDK (or FBP) reconstruction, effectively learning p(xt∣FDK(y),t) and incorporating global volumetric priors via slice conditioning. The FDK reconstruction provides a context prior and stabilizes the conditional generation, promoting inter-slice volumetric consistency and alleviating hallucinations typical in naive slice-wise diffusion.
- Explicit Data-Consistency Alignment: Posterior samples are refined through data-consistency-driven optimization over the denoised estimate, utilizing a loss LDC penalizing deviation between measured and projected estimates. This is realized via alternating updates in image space followed by resampling to diffusion space—a computationally tractable alternative to end-to-end backpropagation through the diffusion chain.
- Slice and Position-Aware Conditioning: Recognizing the spatial variability in CBCT artifacts, slice indices are encoded (e.g., via cross-attention) to enable position-aware artifact removal, improving uniformity of reconstruction quality throughout the volume.
Besides CDPA, the study revisits FDK-denoising models (modern U-Nets with cross-attention and slice encoding), supplemented by an efficient inference-time data-consistency fine-tuning step using gradient descent, ensuring strict measurement-consistent outputs.
Experimental Evaluation
State-of-the-art performance is established on both synthetic and real CBCT datasets (dental, spine, and walnut), at resolutions up to 5013 voxels. Training and inference protocols reflect clinical conditions, using as few as 20–180 uniformly distributed projection views.
Key numerical findings include:
- CDPA with posterior averaging (μ(CDPA)) achieves the highest PSNR/SSIM across all datasets tested:
- On Walnut (20 views): 30.71±0.75 dB (PSNR), 0.815±0.012 (SSIM)
- On Dental (20 views): 34.76±0.67 dB, 0.919±0.010
- Fine-tuned FDK-denoiser models, with positional encoding, nearly match CDPA performance at a fraction (∼18×) of the computational cost.
Comparison with recent strong baselines (GAAL, S-STAR Net, DIF-Net) confirms that CDPA outperforms prior supervised and generative techniques (Table 1 in paper).
Visual qualitative results demonstrate artifact suppression, anatomical detail preservation, and enhanced 3D consistency, especially notable in high-resolution walnut scans. In Figure 1 (presented below), coronal, axial, and sagittal slices expose the granularity of improvement from the test set using 20 views.
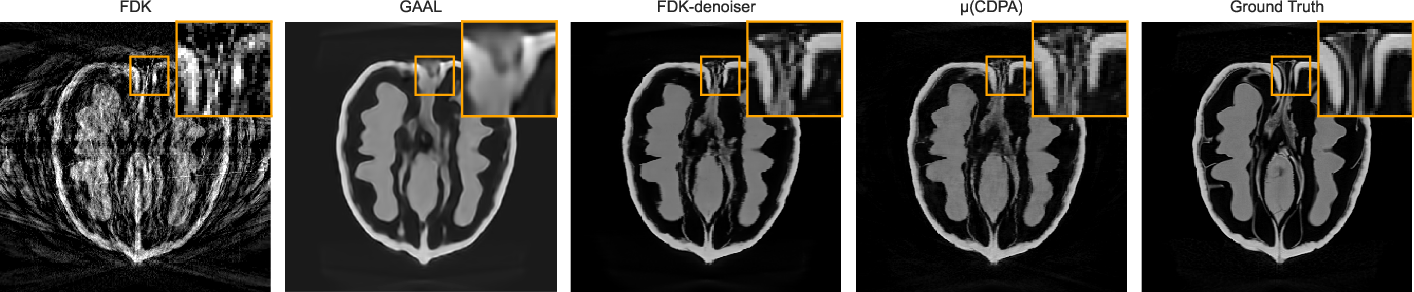
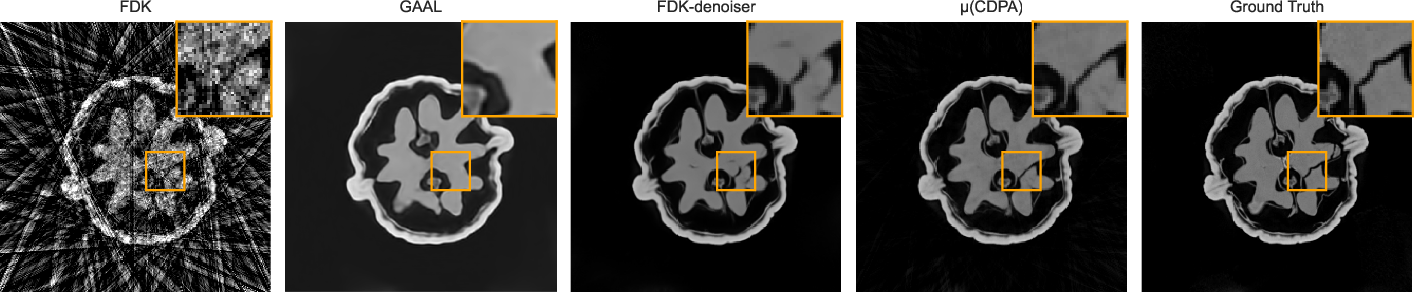
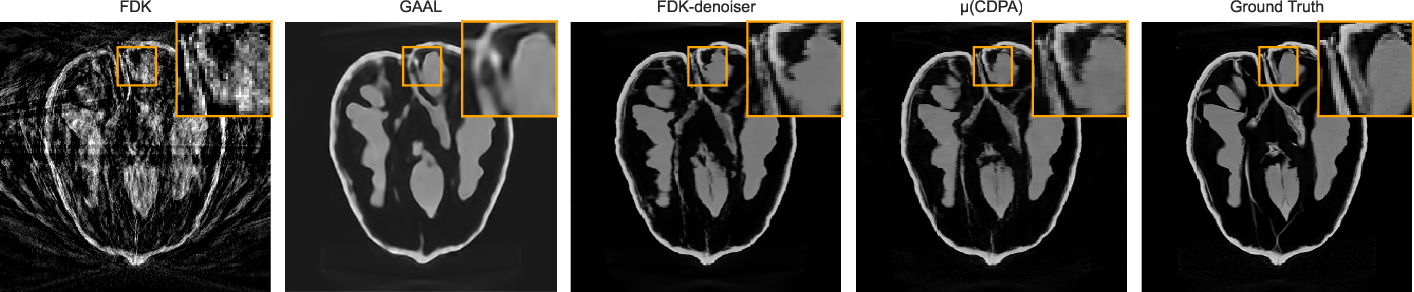
Figure 1: Slices (coronal, axial, sagittal; top-to-bottom) of walnut reconstructions at 2563 resolution from the test dataset using 20 uniformly spaced views from the 1200 available (middle scan).
Additional figures illustrate similar performance on synthetic dental/spine datasets and high-resolution progressive improvements as view counts increase.
Ablation and Efficiency Analyses
A critical ablation (see Figure 2) dissects the roles of slice conditioning and fine-tuning, affirming that both are necessary to close the performance gap to diffusion models. Notably, computational efficiency is substantially increased in the FDK-denoising branch, recommending it for real-time or resource-limited scenarios.
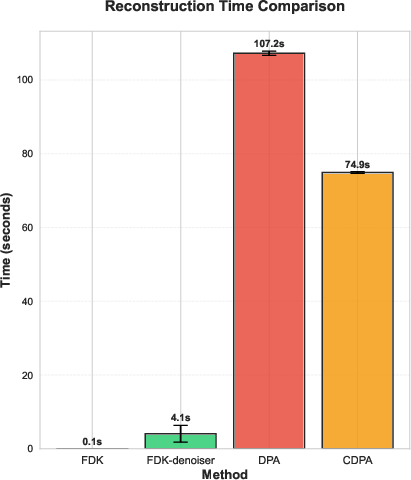
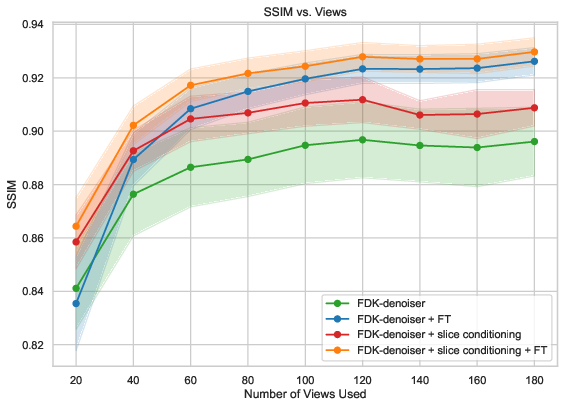
Figure 2: Left—Runtime comparison; conditional diffusion models require fewer data-consistency steps while FDK-denoising with fine-tuning is dramatically faster. Right—Ablation study establishes essential contributions from slice conditioning and data-consistency fine-tuning for state-of-the-art performance.
Uncertainty Quantification
The study presents a compelling uncertainty quantification (UQ) analysis leveraging sample-wise variance from the diffusion posterior. As shown in Figure 3, the standard deviation of posterior samples strongly correlates (LDC0) with absolute reconstruction error, supporting practical UQ and error flagging in clinical settings.
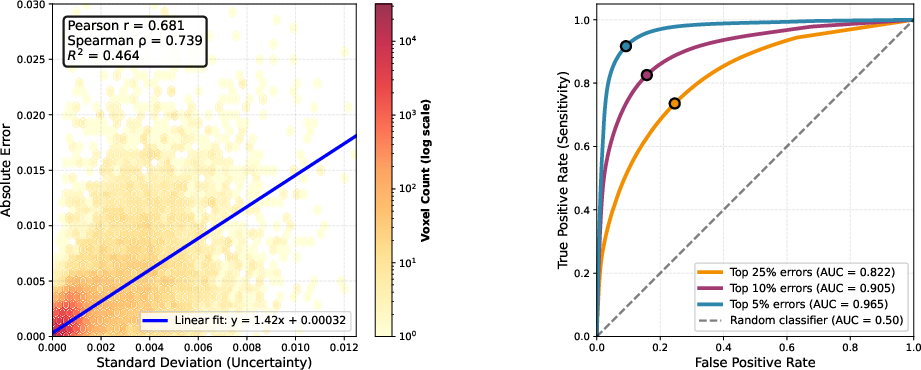
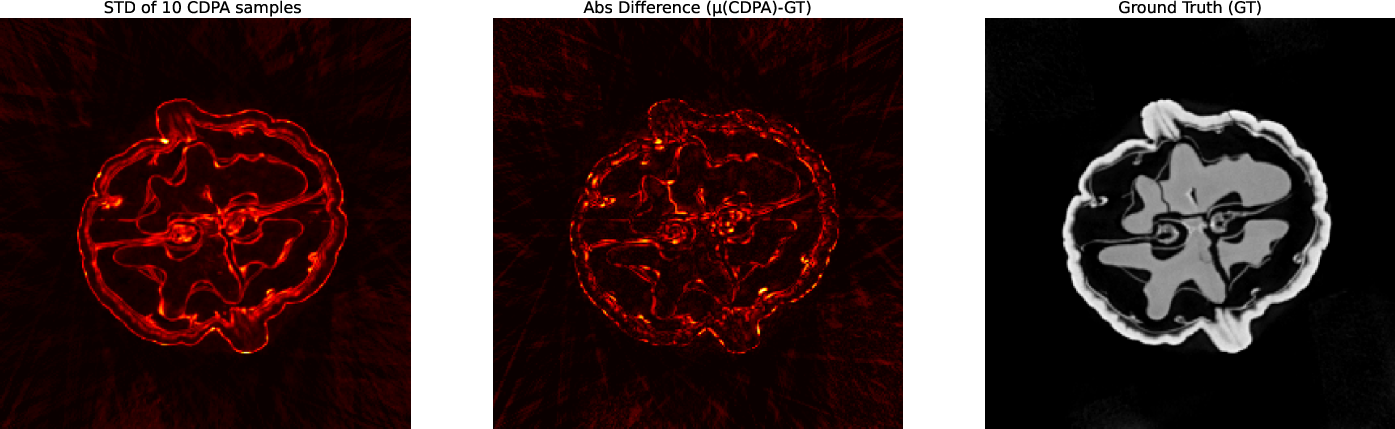
Figure 3: Correlation between sample STD and reconstruction error for the LDC1 walnut dataset (20 projections); strong positive correlation demonstrates utility of diffusion sample variance as a spatially localized UQ metric.
The ROC curves for detection of high-error voxels (AUC up to 0.961 for the most severe errors) underline the discriminative strength of this UQ strategy.
Implications, Limitations, and Future Directions
The demonstrated scalability of CDPA—using conditional 2D slice-wise models with explicit data-consistency refinement—makes high-fidelity, high-resolution CBCT reconstruction tractable without extensive 3D networks or prohibitively large training datasets. This pragmatic approach advances practical deployment in clinical and industrial CT, making aggressive dose/time reduction plausible with minimal loss in fidelity.
However, limitations persist. While UQ is promising, diffusion-based posteriors do not constitute the true Bayesian posterior; formal guarantees on calibration and coverage are not provided, especially in the presence of model mismatch or severe undersampling. Advancements may arise from integrating principled uncertainty quantification (e.g., likelihood mixing, MCMC-based Bayesian inference, or equivariant bootstrapping). Additionally, scaling data-consistency refinement and exploring latent diffusion for even larger volumes remain active areas.
Conclusion
Conditional Diffusion Posterior Alignment represents a significant methodological improvement for sparse-view CBCT reconstruction, resolving inter-slice inconsistencies and enforcing explicit measurement consistency, while remaining scalable to high-resolution volumes. The evidence presented demonstrates superior numerical and visual performance relative to established methods, with practical uncertainty quantification and efficient FDK-denoiser-based alternatives. These developments set a new bar for data-driven CT reconstruction under severe measurement constraints and open multiple avenues for future research in robust, uncertainty-aware inverse imaging.

