- The paper introduces Par-S²ZPO, which approximates gradient directions using binary perturbations to enable federated RLHF in resource-constrained settings.
- The method partitions policy parameters across agents, drastically reducing memory and communication costs while maintaining sample efficiency.
- Empirical evaluations on MuJoCo environments validate that Par-S²ZPO outperforms traditional Federated RLHF methods, confirming its theoretical convergence and practical efficiency.
Efficient Federated RLHF via Zeroth-Order Policy Optimization: An Expert Analysis
Problem Setting and Motivation
The paper addresses Federated Reinforcement Learning from Human Feedback (RLHF) in distributed, resource-constrained environments, such as edge computing devices. Traditional federated algorithms, notably FedAvg, rely on communication of full-network gradients, which is prohibitive when model size, computation, and communication capacity are severely limited. Fine-tuning large policies in RLHF using such methods is practically infeasible for edge devices, motivating a search for fundamentally more efficient protocols.
Algorithmic Innovations: Par-S2ZPO
The core contribution is the Partitioned, Sign-based Stochastic Zeroth-order Policy Optimization (Par-S2ZPO), which integrates three key elements:
- Zeroth-Order Gradient Approximation with Binary Perturbations: Par-S2ZPO avoids gradient calculation entirely, instead using Rademacher (±1) perturbations to approximate policy improvement directions by querying single-bit human feedback on perturbed trajectory batches. This yields minimal communication cost, as only the direction (sign) of policy preference is broadcast.
- Parameter Partitioning Across Agents: The policy parameter vector is divided into K equal blocks, each assigned to a federated agent. Each agent perturbs only its own subset, drastically reducing local memory requirements and communication—only d+K bits per update.
- Binary Policy Feedback Aggregation: Each agent queries its local panel to compare trajectories from current and perturbed policies, broadcasts a one-bit signal (±1) indicating the preference direction, and the central server updates the global policy by stacking these partial directions.
This design leverages distributed human preference evaluation while minimizing computational and resource demands.
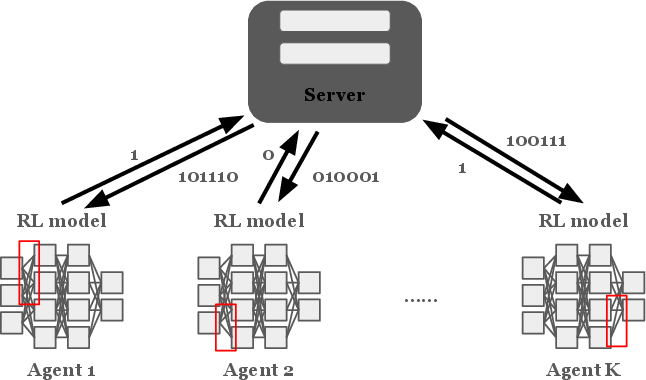
Figure 1: Block diagram of the ParFed RL framework illustrating partitioned parameter updates and federated aggregation.
Theoretical Analysis: Convergence and Sample Complexity
The paper rigorously analyzes Par-S2ZPO, deriving an upper bound on the convergence rate in terms of block-sum gradient norm. The analysis proceeds under standard smoothness assumptions and models the panel's human feedback as a general link function, covering diverse panel accuracy regimes.
Key theoretical results:
- Sample Complexity Independence from Agent Count (K): For fixed total number of trajectory rollouts (sample complexity), the rate bound is strictly independent of K. This implies that federated multi-agent systems are as sample-efficient as centralized single-agent schemes given equal total rollouts, even though federated agents operate fewer policy update iterations (each agent's iteration count is reduced proportionally to 20).
- Tradeoff in Batch Size (21): Larger batch sizes improve distinguishability of policy differences by panelists, reducing feedback noise, but also reduce total number of training iterations. Optimal 22 depends on environment-specific distinguishability and panel accuracy.
- Optimal Perturbation Magnitude (23): The bound exhibits competing terms: increasing 24 accelerates coverage of the parameter space, but too-large perturbations degrade local policy optimization accuracy; optimal 25 balances these effects.
- Majority Vote Error: The bound quantifies the convergence degradation due to finite panel size and batch sampling noise, with explicit dependence on panel preference deviation and batch count.
Empirical Validation: MuJoCo Environments
Experiments are performed on four continuous control environments: Half Cheetah, Hopper, Swimmer, Walker2D, using actor networks of two hidden layers. Each policy is pretrained with PPO for stability, then fine-tuned via Par-S26ZPO. Human feedback is simulated using a linear link function with anonymized parameters, sampled from panels of 100 simulated panelists.
Numerical findings substantiate theoretical claims:
- Batch Size Tradeoff: Analysis of empirical return distributions shows that in some environments (e.g., Hopper, Swimmer), batch size 27 suffices for panel distinction, whereas in environments with more overlapping returns (Half Cheetah, Walker2D), 28 substantially improves distinguishability.
- Agent Count Robustness: Performance is statistically invariant across 29 agents under fixed sample complexity, confirming theoretical predictions.
- Binary vs. Gaussian Perturbations: Binary perturbations match the performance of Gaussian ones, validating the choice of Rademacher perturbation for communication and memory efficiency.
- Algorithm Superiority: Par-S20ZPO consistently outperforms FedAvg-based RLHF in cumulative rewards across all environments—both in terms of final policy score and learning efficiency.
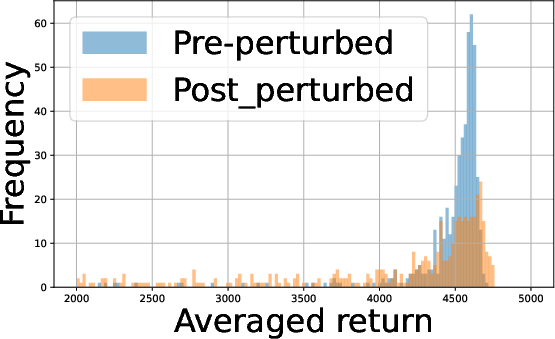
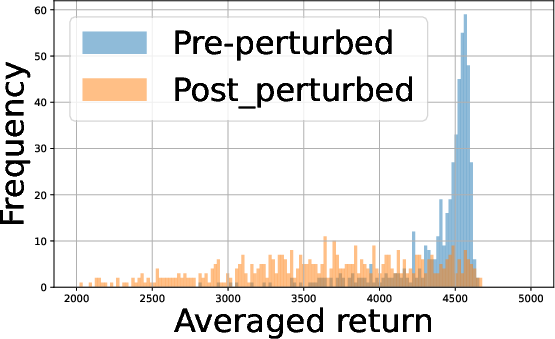
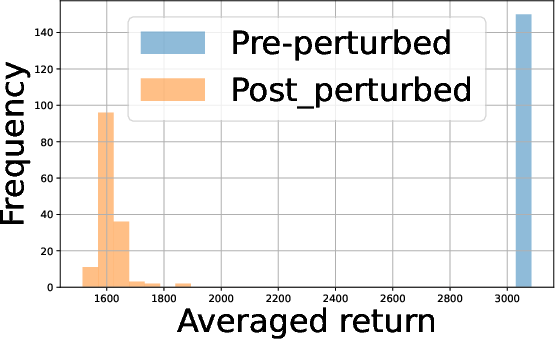
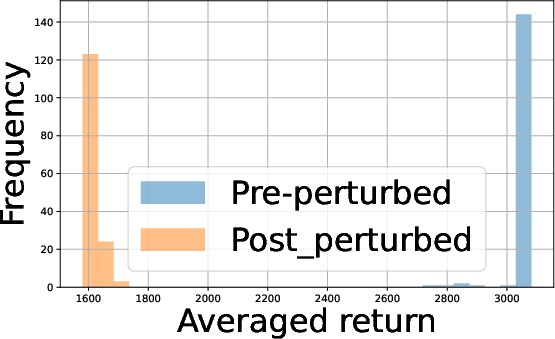
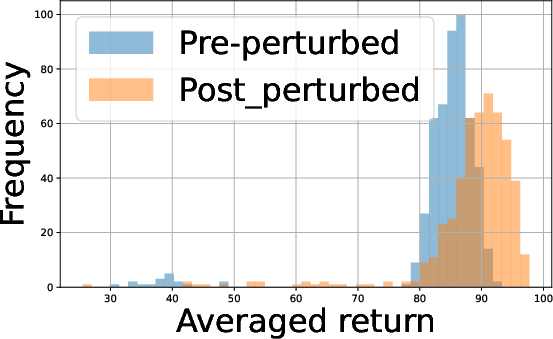
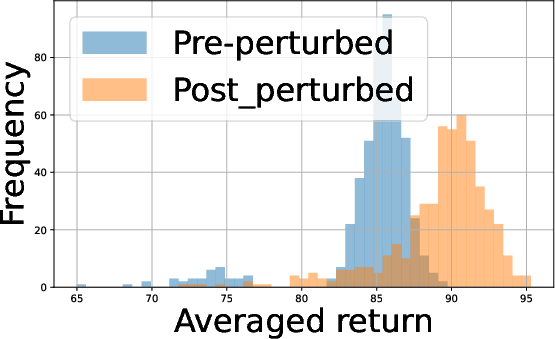
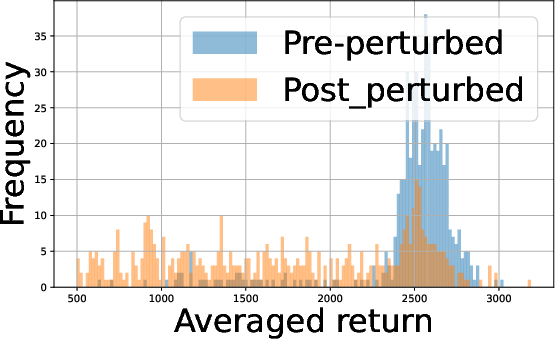
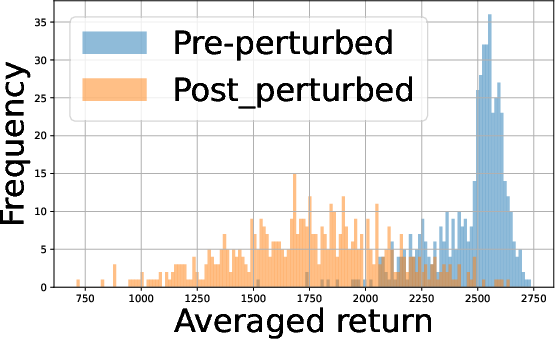
Figure 2: Performance profiles in the Half Cheetah environment illustrating the impact of batch size and agent count on policy returns.
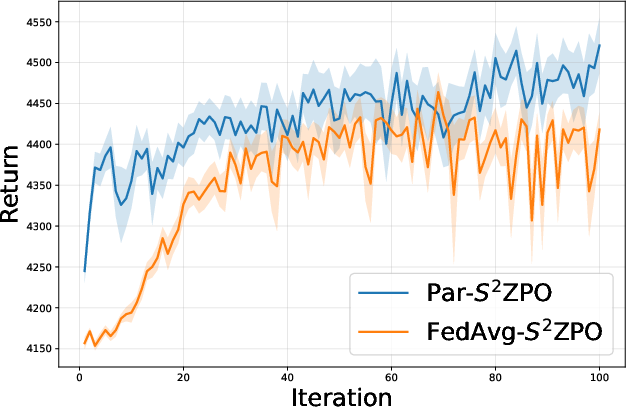
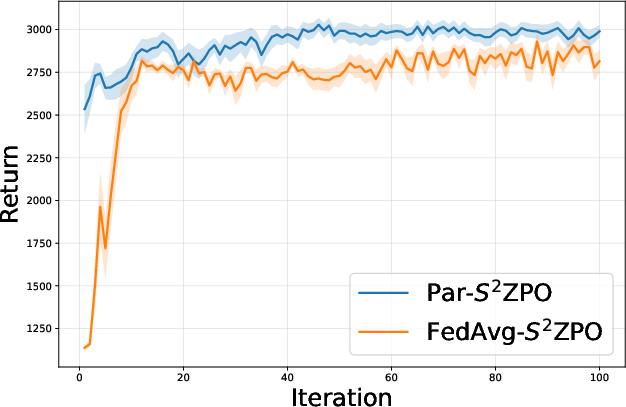
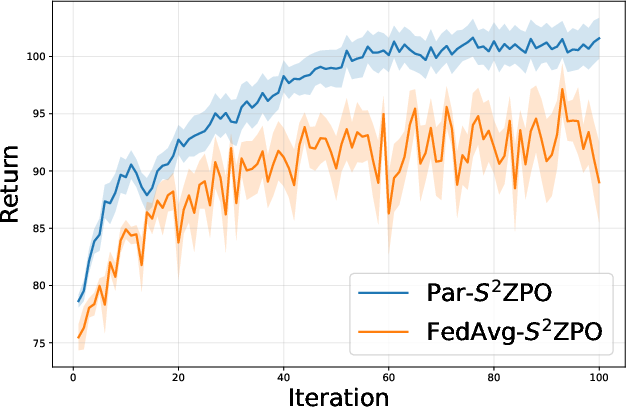
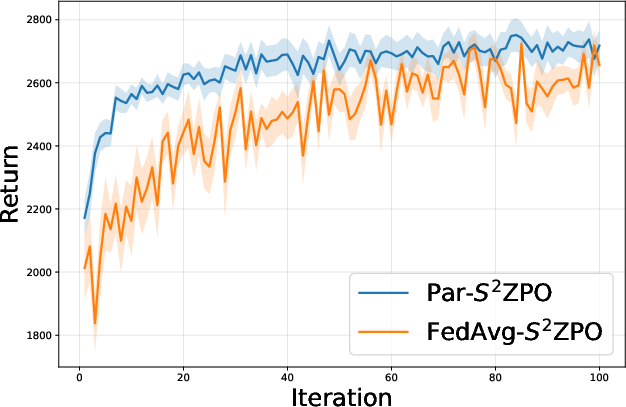
Figure 3: Comparison of Par-S21ZPO against FedAvg-S22ZPO, showing superior learning curves for binary perturbation-based federated updates.
Implications and Future Directions
Par-S23ZPO offers a practical solution for federated RLHF under stringent resource constraints. The convergence analysis suggests that federated RLHF is no less sample-efficient than centralized RLHF when agent partitioning and zeroth-order feedback aggregation are properly implemented. The approach opens avenues for distributed RLHF in settings where privacy, capacity, or battery limitations preclude conventional gradient-based federated updates.
Future research directions include:
- Panelist Modeling and Link Function Estimation: Extending the analysis to adaptive or heterogeneous panelist feedback models, possibly leveraging active learning to optimize feedback allocation.
- Hardware Implementation and Large-Scale Deployment: Adapting Par-S24ZPO for real-world edge hardware, e.g., federated robotic systems or mobile devices fine-tuning LLMs or vision policies.
- Multi-Agent Coordination and Partial Observability: Investigating extensions where agents operate in partially observable environments with noisy or delayed feedback.
- Reduction of Feedback Overhead: Exploring further reduction in query complexity, including probabilistic aggregation or semi-supervised feedback mechanisms.
Conclusion
This paper introduces Par-S25ZPO, a communication- and memory-efficient method for federated RLHF via zeroth-order policy optimization with binary perturbations and parameter partitioning. Rigorous theoretical and empirical analyses demonstrate that sample-wise federated RLHF can match or exceed centralized performance, with strong advantages in practical deployment on edge devices. The methods and findings provide a foundation for scalable, resource-aware federated RLHF algorithms, enabling distributed policy learning in constrained environments.

