- The paper introduces an ICL-based framework incorporating chain-of-thought to enhance distractor quality by aligning with expert reasoning.
- It employs k-NN retrieval of semantically similar examples to condition LLMs, achieving significant improvements in performance metrics.
- Empirical results demonstrate notable F1@3 score increases across science, general knowledge, and medical benchmarks.
In-Context Learning and Chain-of-Thought Rationale for Advanced Distractor Generation
Introduction
Distractor generation (DG) for multiple-choice questions (MCQs) is central to automated assessment, but constructing plausible and pedagogically sound distractors remains an expert-intensive challenge. Historically, DG methods leveraged fine-tuned pre-trained encoder-decoder models and contrastive learning to generate distractors that were contextually relevant, yet these pipelines often struggled to align with the implicit reasoning processes that human experts employ. The paper “Beyond Fine-Tuning: In-Context Learning and Chain-of-Thought for Reasoned Distractor Generation” (2604.17574) presents an alternative paradigm, leveraging LLMs via in-context learning (ICL) and augmenting the prompt space with explicit chain-of-thought (COT) rationales. This rationale-centric strategy is empirically validated across diverse benchmarks and domains, demonstrating consistent state-of-the-art (SOTA) performance and improved alignment with human distractor construction.
The core task is to generate plausible, semantically relevant distractors for a given question-answer pair, formulated as a conditional text generation problem. Prior art in DG, most notably the candidate selection/generation (CSG-DS) and Text2Text architectures, capitalized on pre-trained models and, more recently, on contrastive objectives to improve semantic representation. Nevertheless, these models frequently produce distractors that fail to encode the nuanced reasoning and pedagogical traps valued by domain experts. For instance, contrastive models generate plausible options based on local context but miss the fine-grained reasoning behind what constitutes a genuinely misleading distractor (Figure 1).
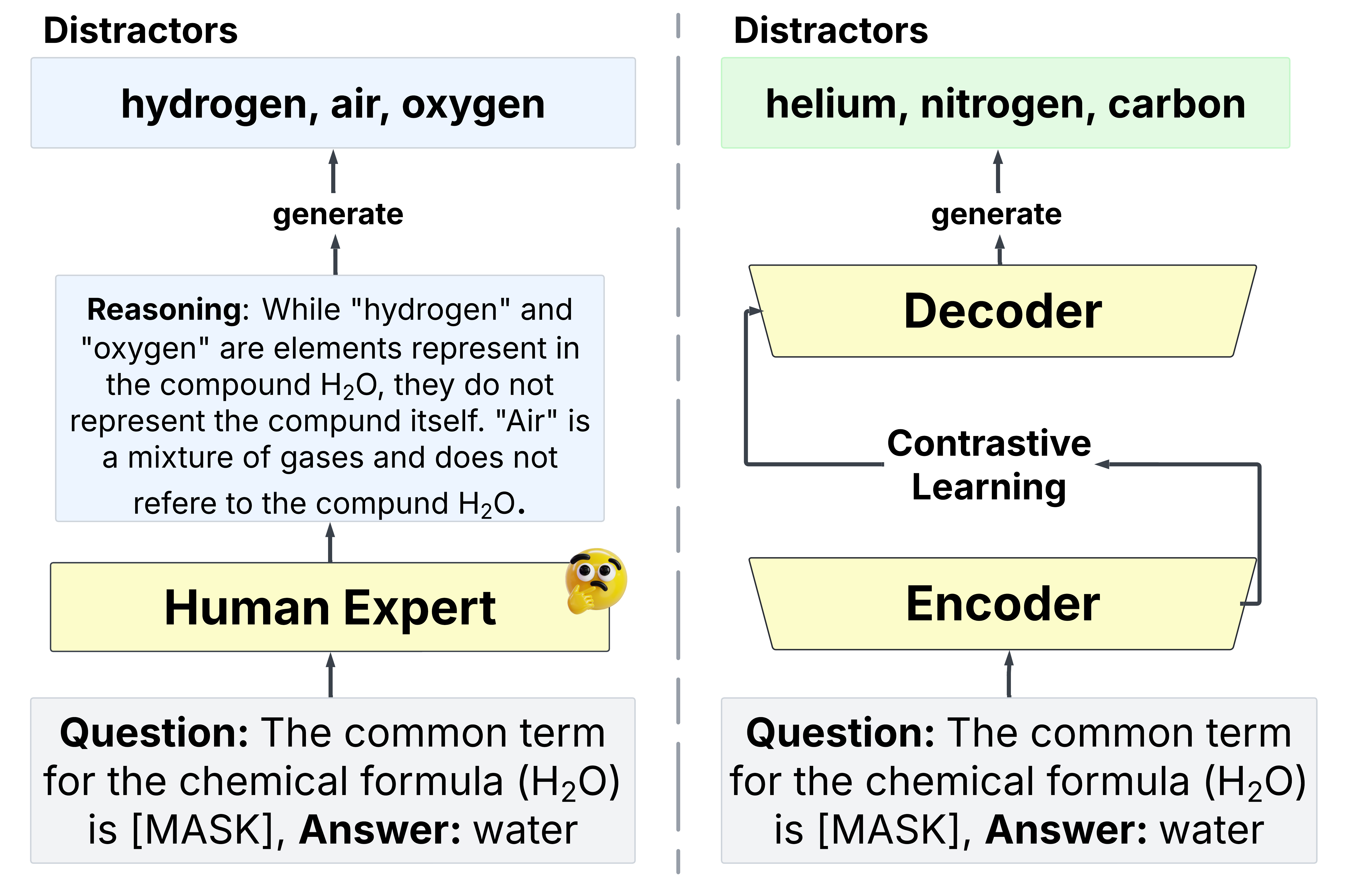
Figure 1: Comparison of distractors generated via human reasoning versus contrastive pre-trained encoder-decoder models, illustrating the gap in reasoning alignment.
In-Context Learning and Chain-of-Thought Augmentation
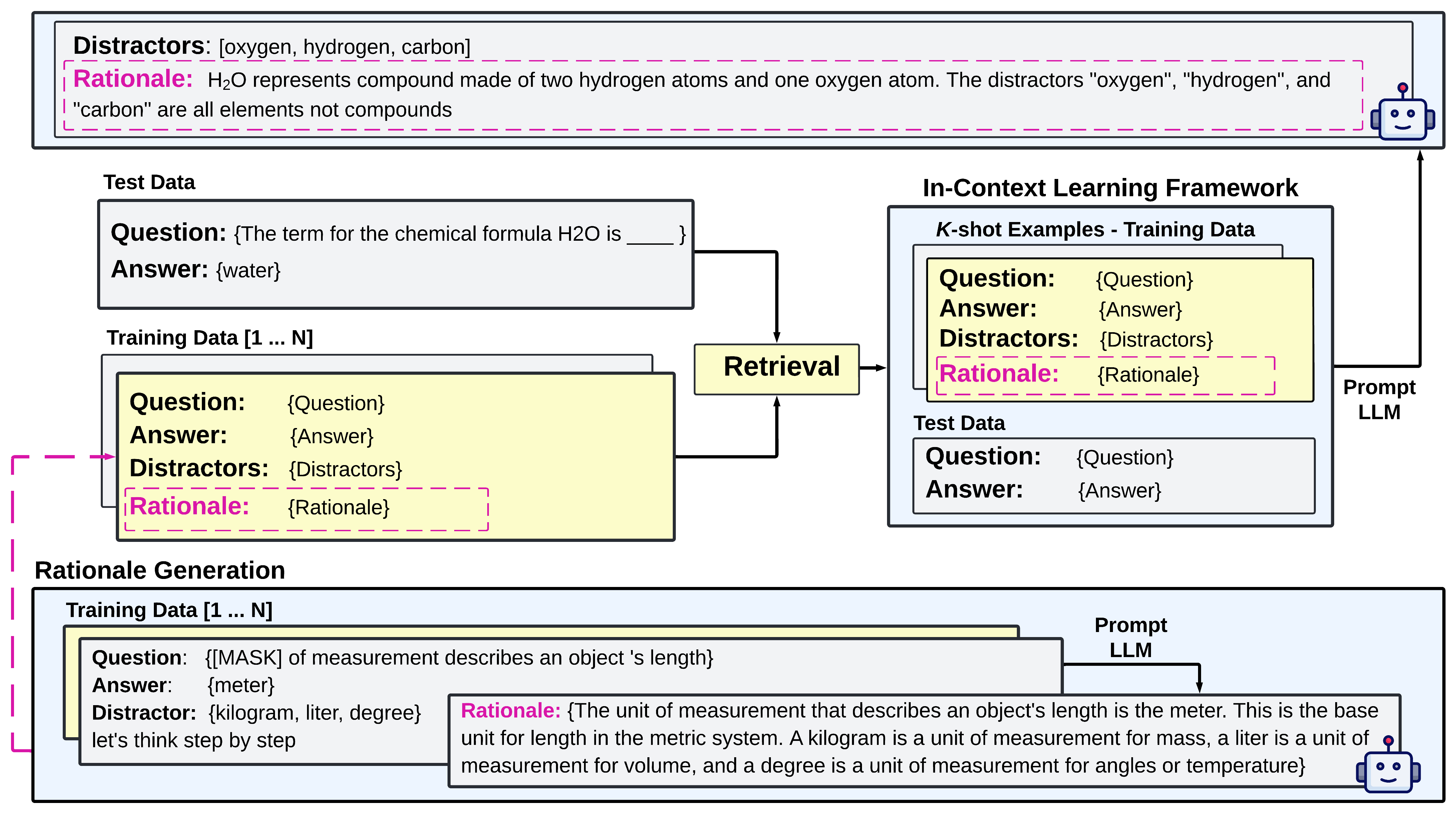
The authors introduce an in-context learning (ICL) framework wherein LLMs (notably GPT-3.5-turbo) synthesize distractors by conditioning on a set of semantically retrieved few-shot examples, selected via unsupervised k-nearest neighbor (k-NN) retrieval over pre-trained sentence embeddings (e.g., MPNet). Crucially, the context for the target prompt is further enriched with chain-of-thought rationales: explicit, stepwise justifications attached to each training example.
The workflow proceeds as follows:
Empirical Evaluation and Numerical Results
Experiments cover six benchmarks spanning science, general knowledge, and medical domains, with highly variable distractor lengths and complexity. The evaluation employs token-level and ranking-based automatic metrics (F1@3, P@1, NDCG@3), human quality ratings (relevance, difficulty, fluency), and QA model-based answerability (using T5 and BART).
The ICL-based framework sets new or near-SOTA results on all datasets, with striking jumps over both fine-tuning and contrastive Text2Text models. For example:
- On MCQ, F1@3 improves from 15.70 (T5+contrastive) to 19.69 (GPT-3 ICL).
- On MCQL (college-level science), F1@3 surges from 13.67 (T5+contrastive) to 24.44 (GPT-3 ICL with k-NN), an absolute increase of over 10 points.
- In the medical domain (MedQA), F1@3 increases from 3.50 (T5+contrastive) to 15.08 (GPT-3 ICL with k-NN).
ICL with k-NN is consistently more reliable than random retrieval, confirming that semantically relevant few-shot examples constitute optimal context for DG in LLMs. COT augmentation does not always boost aggregate metrics but yields interpretability benefits and secures best-in-class P@1 and R@1 for several datasets.
For further evidence, comparison of QA accuracy with BART and T5 (Figures 3) reveals that ICL-generated distractors achieve lower test accuracy than other baselines, indicating their greater ability to mislead competitive QA models—an essential goal of high-quality DG.
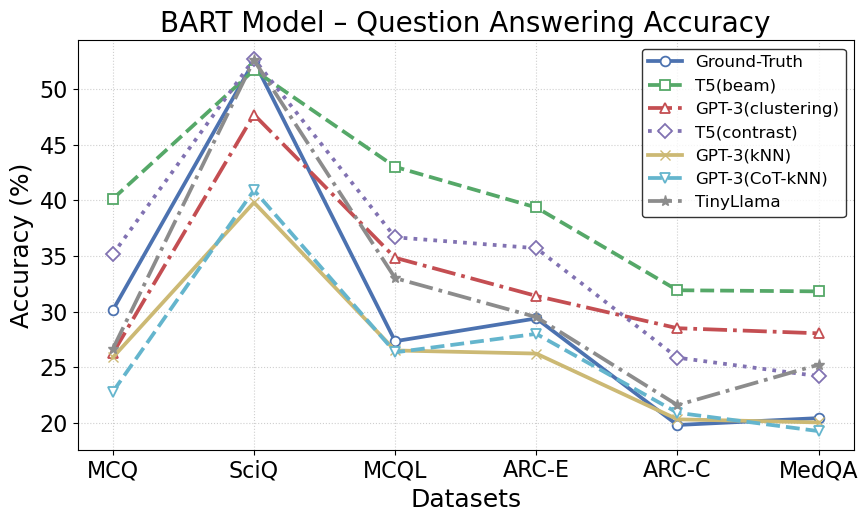
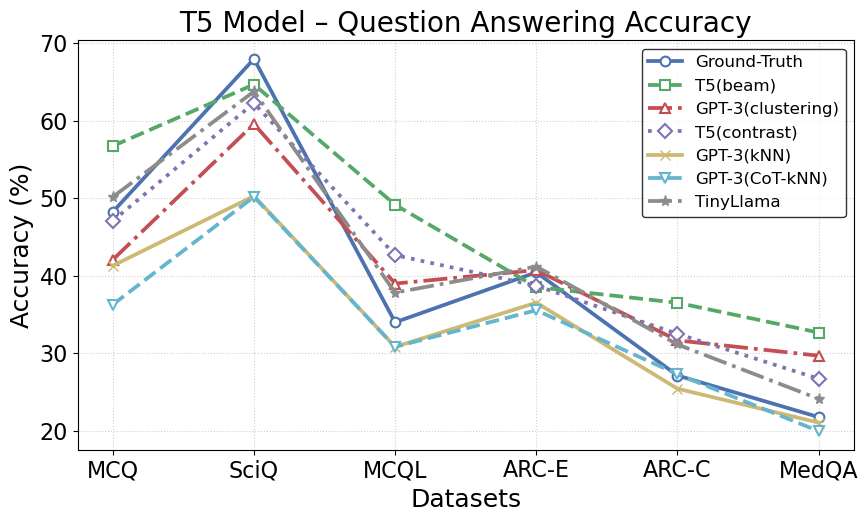
Figure 3: BART model's QA accuracy using distractors generated by different DG approaches, where ICL-generated distractors lead to lower system accuracy, denoting stronger distractive quality.
The effect of model and context selection is further systematized. Mistral-7B under k-NN ICL improves over classical methods but is consistently outperformed by GPT-3. Adjusting the number of in-context examples (k=5,7,20,30) shows monotonic improvements, peaking with k=30 and establishing new SOTA results across all datasets (Figure 4).
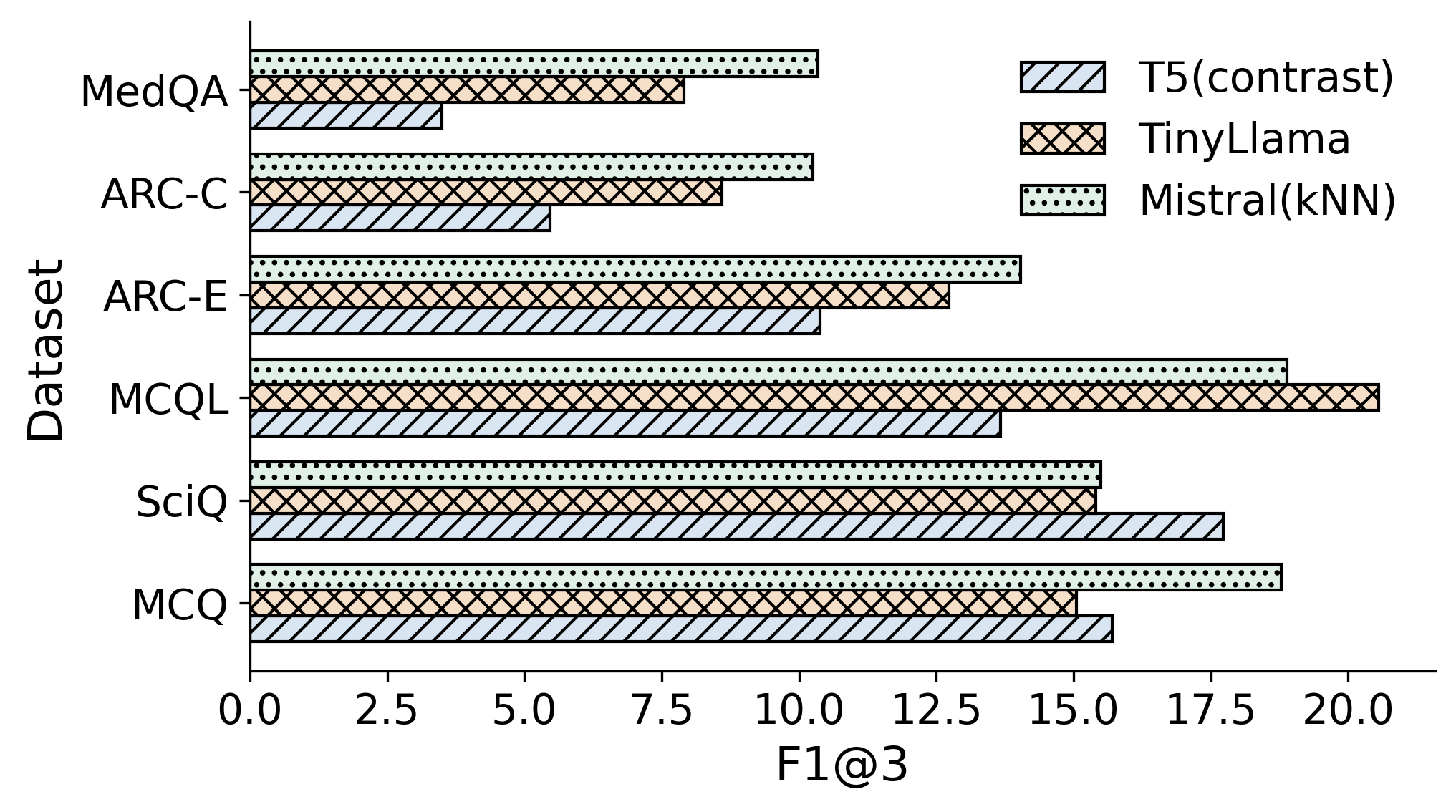
Figure 5: Comparative F1@3 performance of Mistral (k-NN) versus recent DG models, confirming the robustness of the ICL paradigm.
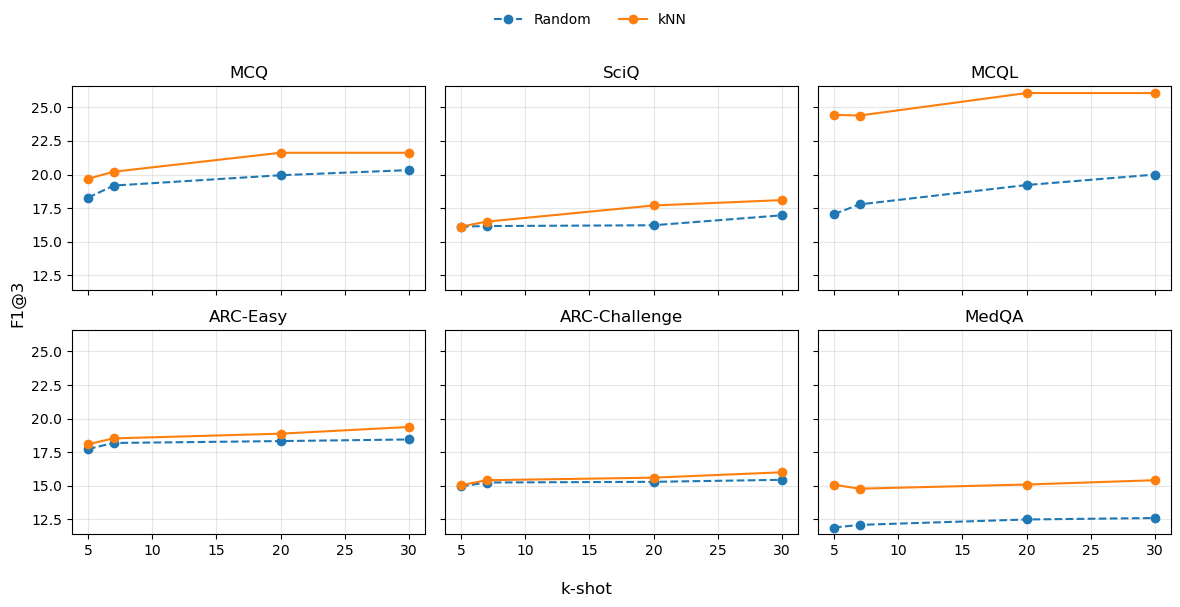
Figure 4: F1@3 score trajectories for varying few-shot k; performance improves significantly with larger shot counts and k-NN selection.
Qualitative Analysis and Rationale Effect
Case studies exhibit that previous approaches suffer from issues such as answer leakage, redundant outputs, and lack of nuanced reasoning in distractor choice. By contrast, the proposed ICL/COT framework produces distractors that exploit domain knowledge and pedagogical intent, mirroring human expert rationale. Human evaluators corroborate these findings: ICL (k-NN) achieves top scores for relevance, difficulty, and fluency, closely matching the ground-truth distractor quality.
Implications, Theoretical and Practical
The findings offer a strong demonstration that reasoning-aware prompting, as enabled by chain-of-thought and example selection via k-NN semantic retrieval, is essential for bridging the gap between human expert and automated DG systems. Practically, this reduces the burden for domain experts, provides richer distractor pools in knowledge assessment pipelines, and supports pedagogical validity in automated item development.
On a theoretical level, the work demonstrates the limitations of fine-tuning-centric paradigms for generation tasks where implicit, expert-crafted reasoning is key. It reaffirms the core advantage of LLMs as flexible few-shot learners, whose output quality scales with both the relevance and richness of contextual exemplars.
Future Directions
The paper highlights several limitations and avenues for further exploration:
- Residual hallucination in LLM-generated outputs, especially in zero-shot settings, requires enhanced output control.
- Automated evaluation that goes beyond token-level surface matching is critical, as high-quality distractors may be semantically correct and context-aligned without explicit match to ground truth.
- Integrating more advanced or learned retrieval mechanisms for in-context example selection (beyond k-NN) could further refine distractor plausibility.
- Extending similar rationale-centric ICL paradigms to other high-stakes generative tasks in education, assessment, and explainable AI is a promising direction.
Conclusion
The integration of in-context learning and chain-of-thought rationale generation with LLMs establishes a new SOTA in automated distractor generation. The explicit use of reasoning exemplars and semantically guided example selection produces distractors that demonstrably align with human expert practice, outperforming both fine-tuned encoder-decoder and classical contrastive approaches across all evaluation metrics and domains. This work substantiates the shift toward retrieval-augmented, rationale-aware generative modeling in AI-based educational and assessment systems, and lays groundwork for more explainable and robust generative pipelines in tasks that demand expert-level reasoning and output control.