- The paper introduces MoVE, a scalable architecture that integrates mixture-of-experts to preserve non-verbal vocalizations in speech-to-speech translation.
- Efficient adaptation is achieved with LoRA adapters and expressive data synthesis, recovering 95% of full-data performance with only 30 minutes of curated expressive data.
- MoVE delivers state-of-the-art performance with a BLEU score of 32.5 and an NV match rate of 76%, outperforming conventional S2ST methods in objective and subjective evaluations.
MoVE: Mixture of Vocalization Experts for Expressive Speech-to-Speech Translation
Introduction
Conventional speech-to-speech translation (S2ST) systems achieve high semantic fidelity but systematically remove non-verbal vocalizations (NVs), such as laughter or crying, thereby sharply limiting their communicative utility in natural human interactions. The loss of such paralinguistic content degrades pragmatic and emotional nuance and reduces the naturalness of the output. This work addresses these limitations through both data-centric and architectural advancements, demonstrating that expressive S2ST with high fidelity is feasible with extremely limited curated data when leveraging AudioLLMs.
Scalable Expressive S2ST Data Synthesis
A primary obstacle in modeling NVs is the lack of large-scale, high-quality expressive parallel speech corpora. The authors present a pipeline for scalable expressive data synthesis using emotion-adaptive prompts and attribute-decoupled TTS, specifically focusing on five acoustic manifolds: Happy, Sad, Angry, Laugh, and Cry. Extreme NVs are curated using a combination of high-confidence detections and manual verification, while speaker identity and expressive state cues are decoupled in TTS conditioning to ensure coverage and diversity. The resulting corpus supports robust S2ST training with effective quality assurance via silence trimming, ASR filtering, and pair-level alignment.
MoVE Architecture and Training Paradigm
The proposed MoVE architecture is instantiated atop a frozen AudioLLM (Kimi-Audio) backbone with expressivity adaptation implemented via parallel LoRA adapters, each trained on a distinct expressive sub-corpus. To counteract interference across emotional manifolds, adapters are not shared; instead, a dynamic soft-weighting router is optimized to output fine-grained token-level mixture coefficients, enabling the system to model complex or hybrid expressive states. MoVE training follows a two-stage procedure: first, expert adapters are independently specialized, and then a router is trained over frozen experts to learn optimal mixture weights from language modeling loss alone.
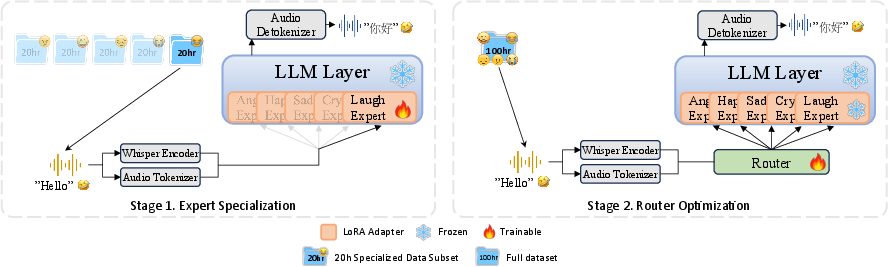
Figure 1: The two-stage training paradigm—expert specialization followed by router optimization—enables robust modeling of expressive speech-to-speech translation.
Notably, the expressive detokenizer is also fine-tuned to address AudioLLM base detokenizers' documented failure to reconstruct extreme NVs, enabling robust waveform generation for expressive and NV-rich speech.
Data Efficiency and Transfer Behavior
Systematic scaling experiments reveal that fine-tuning as little as 30 minutes of curated expressive data (with LoRA on a pretrained AudioLLM) recovers 95% of full (1000h) data emotional fidelity, even while maintaining semantic translation accuracy—an exceptionally strong claim regarding data efficiency. Comparative runs from random initialization result in non-convergent outputs, confirming that pretraining is essential and that LoRA acts primarily as a selector or activator of latent expressive priors in the backbone rather than learning them from scratch.
Experimental Results
Extensive benchmarking against SOTA S2ST backbones (SeamlessM4T-Large-v2, SeamlessExpressive, gpt-4o-audio-preview, Kimi-Audio) and single-LoRA baselines demonstrates that MoVE yields optimal performance across semantic, objective, and subjective metrics when balancing expressivity and translation fidelity. For English-to-Chinese S2ST, MoVE achieves BLEU scores of 32.5, attaining new state-of-the-art performance. The NV match rate is 76%, a dramatic improvement over previous bests (≤14%).
Subjective MOS and SMOS scores, as well as preference tests, confirm that MoVE's outputs are consistently rated as both more emotionally faithful and natural compared to both single-LoRA and cascaded pipeline baselines. These differences persist even when attention is restricted to extremes such as laughter-in-speech or crying-in-speech scenarios, citing substantial performance margins in NV match rates and subjective preference experiments.
Router Behavior and Expressive Disentanglement
Router alignment analysis indicates a 63.68% match between the dominant expert activated on an utterance and its ground-truth emotion/NV label, despite the absence of direct supervision. Off-diagonal confusion matrix elements reflect linguistically plausible blends, not model errors, highlighting effective unsupervised disentanglement and complex affective blending.
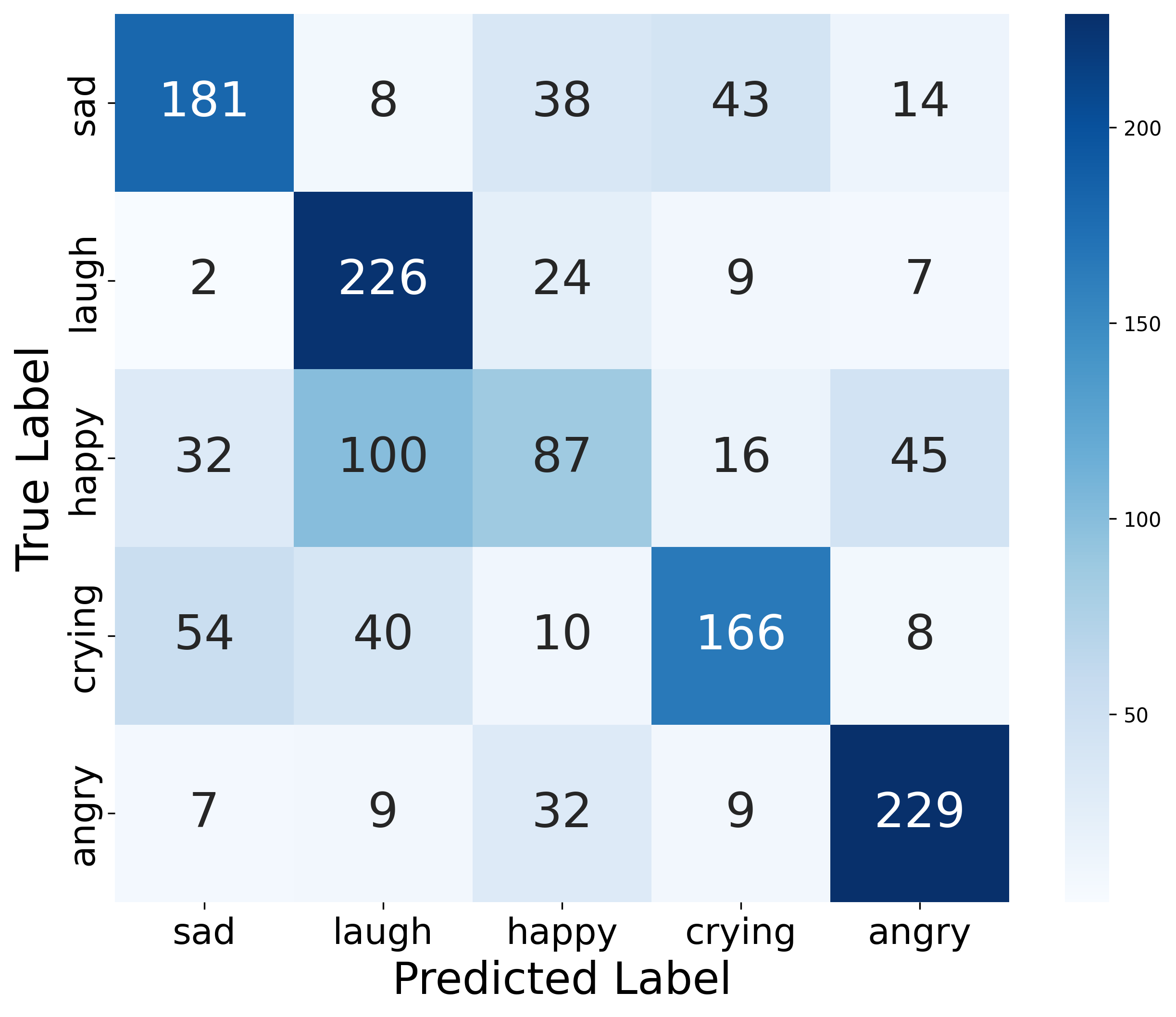
Figure 2: Confusion matrix illustrating the alignment between router expert selection and intended expressive categories, indicating substantial unsupervised disentanglement.
Human Evaluation Protocol
The subjective evaluation leverages a bilingual multi-stimulus MOS interface and an A/B pairwise test, with clear definitions and anchors provided to evaluators.

Figure 3: Bilingual instruction interface for evaluators, detailing rating scales and guidelines for non-verbal vocalizations.
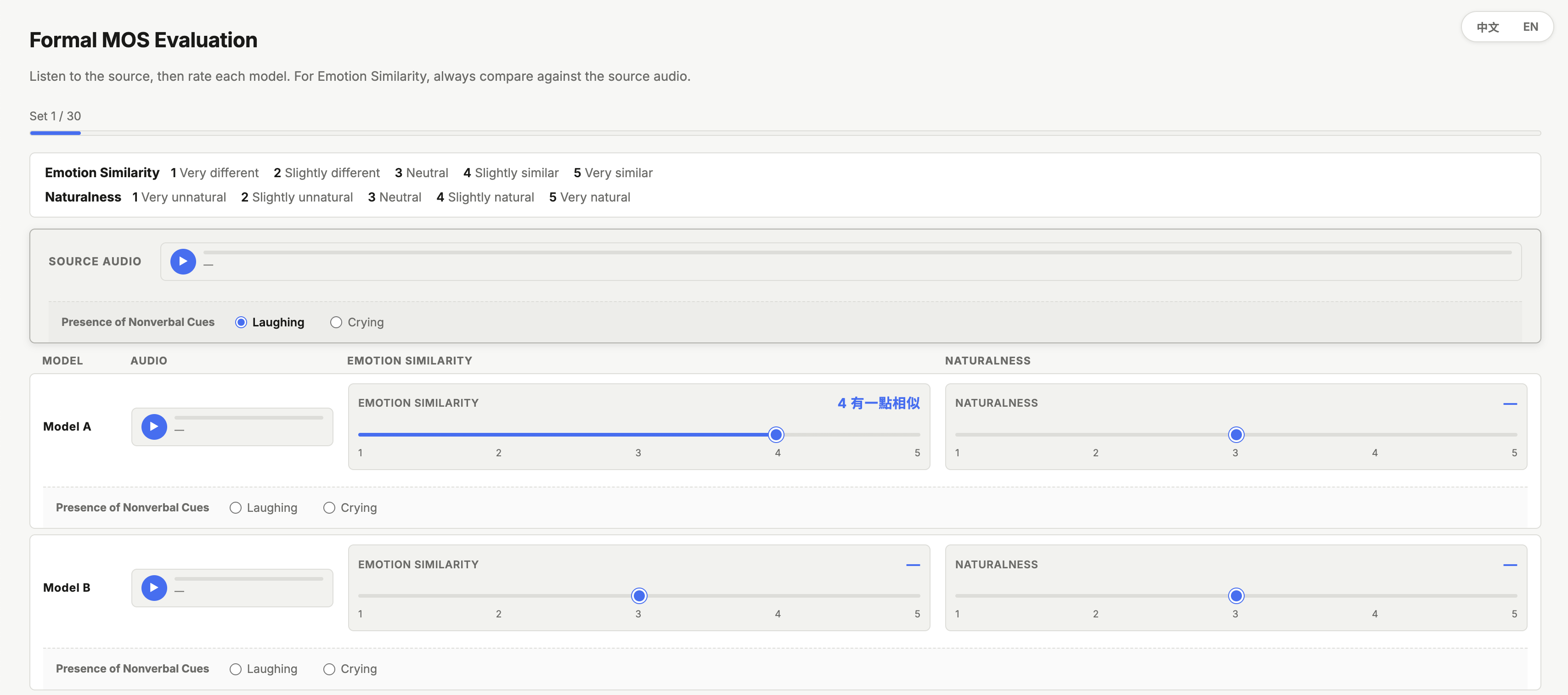
Figure 4: The multi-stimulus MOS interface for subjective naturalness and emotion similarity evaluation.
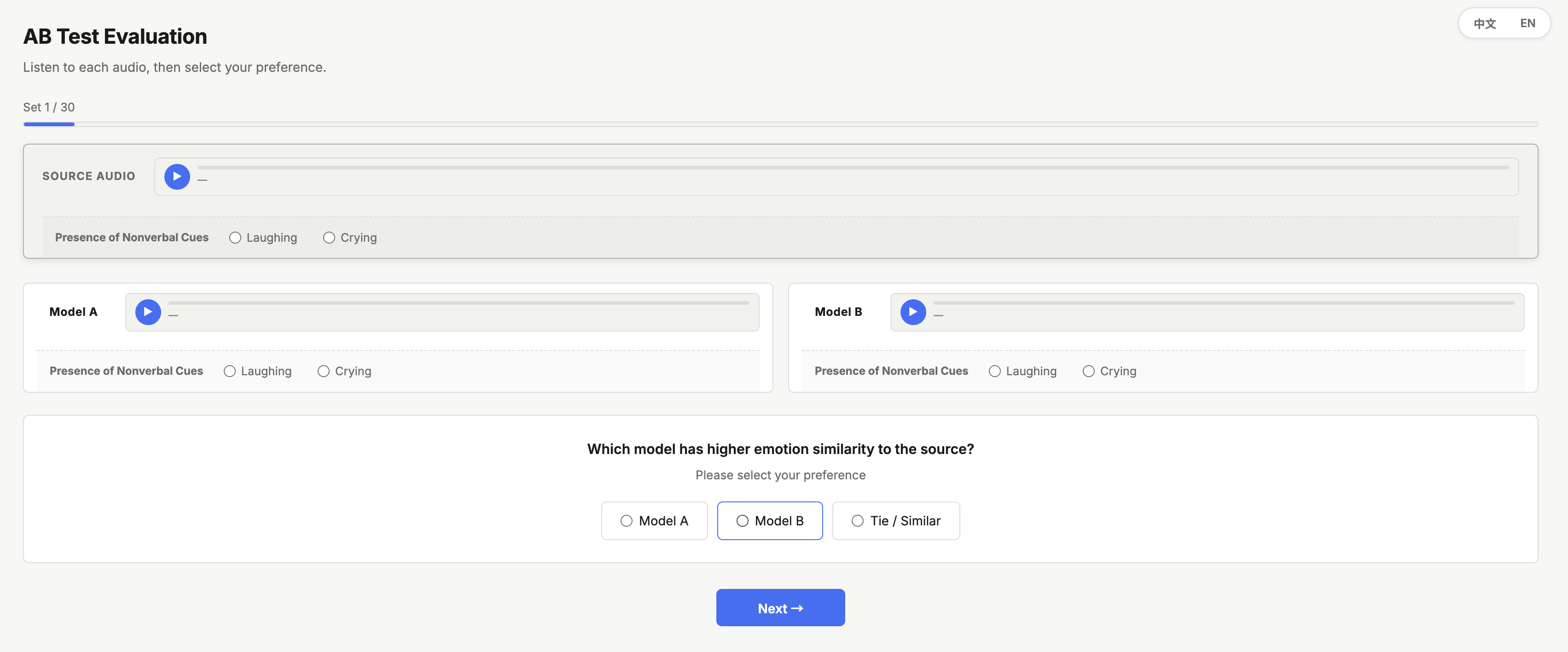
Figure 5: A/B preference test interface comparing emotional expressiveness between MoVE and single-LoRA baselines.
Results from these protocols reinforce that the architectural design and data synthesis pipeline deliver not only objective metric improvements but also substantial subjective human-perceived gains in expressiveness and naturalness.
Implications and Future Directions
MoVE demonstrates that highly data-efficient transfer of NVs and emotion is achievable with AudioLLMs, contingent on model pretraining and mixture-of-experts adaptation. The architecture and synthesis pipeline offer a scalable solution for expressive, pragmatic, and natural S2ST—closing key gaps left by text-based and cascaded approaches. Potential extensions include expanding to a broader inventory of paralinguistics, refining expressive disentanglement in truly in-the-wild conditions, and exploring multimodal integration. The findings suggest that future S2ST research can focus on fine-level pragmatic intent transfer with minimal training data, aided by expert-structured adapters and latent acoustic priors.
Conclusion
This work introduces a scalable method and architecture (MoVE) that raises the bar for expressive S2ST performance, both in terms of objective and human-perceived metrics, and establishes the importance of mixture-of-experts, data-efficient adaptation, and expressive dataset construction for translating human affect as well as linguistic meaning.
(2604.17435)