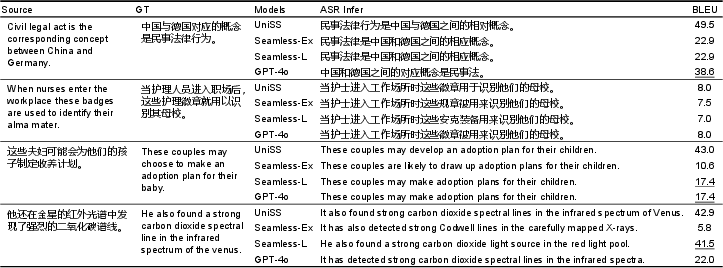
- The paper introduces a unified autoregressive framework that integrates pre-trained text LLMs using cross-modal chain-of-thought prompting for expressive speech-to-speech translation.
- It employs a triple-tokenizer strategy and a progressive training protocol to accurately capture linguistic content, speaker identity, and prosody.
- Experimental results show significant improvements in translation fidelity, speaker preservation, and naturalness compared to cascaded and end-to-end systems.
UniSS: Unified Expressive Speech-to-Speech Translation with Your Voice
Introduction and Motivation
Expressive speech-to-speech translation (S2ST) aims to convert spoken utterances from one language to another while preserving speaker identity, emotional style, and prosodic features. Traditional cascaded S2ST systems, which sequentially apply ASR, MT, and TTS, suffer from error accumulation and loss of paralinguistic information. Recent end-to-end and unit-based approaches have improved semantic fidelity but still struggle with expressive preservation and architectural complexity. The integration of LLMs into S2ST has accelerated progress, yet most systems fail to fully leverage the translation capabilities of pre-trained text LLMs and often require multi-stage or multi-model pipelines.
UniSS addresses these limitations by proposing a unified, single-stage autoregressive (AR) framework that directly incorporates a pre-trained text LLM backbone, Qwen2.5-1.5B-Instruct, and transfers its translation capabilities to the speech domain via cross-modal chain-of-thought (CoT) prompting. The system is trained on UniST, a large-scale, high-quality Chinese-English expressive S2ST dataset (44.8k hours), constructed through a scalable synthesis pipeline that ensures translation fidelity and speaker expressiveness.
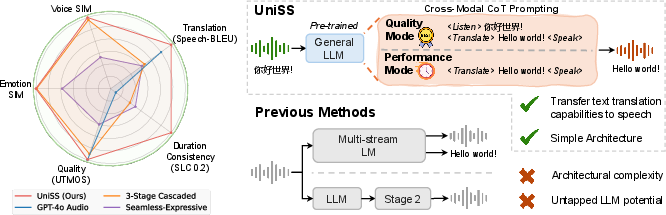
Figure 1: UniSS integrates pre-trained text LLMs and transfers their translation capabilities to the speech domain. UniSS outperforms both end-to-end S2ST systems and cascaded systems on translation fidelity, voice preservation, duration consistency, and speech quality.
Model Architecture and Training Paradigm
Unified Text-Speech LLM
UniSS expands the vocabulary of a pre-trained LLM to include discrete speech tokens, enabling the model to process both text and speech as token sequences within a single transformer architecture. The input consists of concatenated speaker tokens (capturing timbre, prosody, emotion) and linguistic tokens (encoding content), and the output is a sequence of semantic tokens representing the expressive target utterance. The AR generation objective is standard next-token prediction over the unified token space.
Triple-Tokenizer Strategy
- Speaker Tokenizer: BiCodec global encoder extracts 32 fixed-length tokens for speaker attributes.
- Linguistic Tokenizer: GLM-4 speech tokenizer (quantized Whisper encoder) produces variable-length tokens for robust content understanding.
- Semantic Tokenizer: BiCodec semantic encoder generates 50 tokens/sec for expressive waveform reconstruction.
This separation enables accurate modeling and control over content, speaker identity, and expressiveness, outperforming self-supervised semantic-only tokenization for S2ST.
Speech Detokenizer
The BiCodec decoder reconstructs the target waveform from semantic tokens, conditioned on source speaker tokens, ensuring high-fidelity audio with preserved voice and emotional style.
Cross-Modal Chain-of-Thought Prompting
Inspired by CoT prompting in LLMs, UniSS decomposes S2ST into sequential "listen, translate, speak" steps, explicitly leveraging the LLM's text translation expertise. Two modes are supported:
- Quality Mode: Generates source transcription, target translation, and semantic tokens, maximizing fidelity.
- Performance Mode: Skips transcription, directly generating target translation and semantic tokens for faster inference.
Control tokens specify task mode, target language, and output speed ratio, enabling fine-grained control over translation and synthesis.
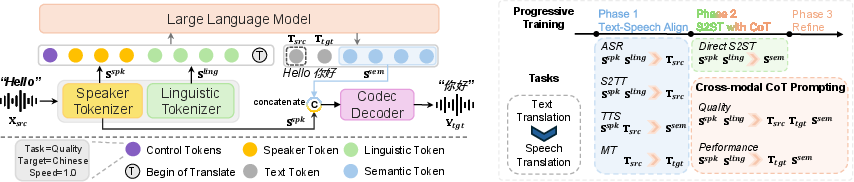
Figure 2: Overview of UniSS, cross-modal CoT prompting, and 3-phase progressive training. Control Tokens instruct the task, target language, and output speed ratio.
Progressive Training Strategy
A three-phase protocol is adopted:
- Speech-Text Alignment: Multi-task learning on ASR, TTS, S2TT, and MT tasks to align speech and text modalities and preserve translation capabilities.
- S2ST with CoT: Training on S2ST tasks with CoT prompting and direct generation, transferring LLM translation expertise to speech.
- Refinement: Fine-tuning on high-quality S2ST data with annealed learning rate to stabilize CoT patterns and optimize performance.
UniST Dataset Construction
UniST is synthesized from large-scale TTS corpora, cleaned via ASR and WER filtering, translated using Qwen2.5-72B-Instruct, and synthesized with SparkTTS conditioned on source speech for voice preservation. Duration ratios are discretized for speed control. Final filtering ensures high translation fidelity and temporal consistency, resulting in General (44.8k hours) and High-Quality (19.8k hours) variants.
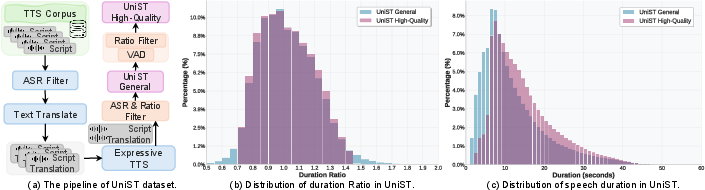
Figure 3: Overview of the UniST data construction pipeline and analysis of duration ratio and speech duration distributions.
Experimental Results
Objective Metrics
UniSS establishes new SOTA on CVSS-T and FLEURS benchmarks for both EN-ZH and ZH-EN directions:
Subjective Evaluation
MOS studies confirm UniSS's expressive capabilities:
Inference Speed and Quality Trade-off
Performance mode yields a 1.07× speedup over Quality mode with only a 1.84 BLEU reduction. UniSS-Small (0.5B) achieves 1.25× speedup with competitive fidelity, enabling deployment in resource-constrained scenarios.
Ablation Studies
- Progressive Training: Phase 1 alignment is essential; omitting it degrades BLEU by up to 10 points.
- Linguistic Tokenizer: Removing GLM-4 drops BLEU by 8–15 points, confirming the necessity of content-focused tokenization.
- CoT Prompting: Direct S2ST (no intermediate text) reduces BLEU by ~15 points, demonstrating the effectiveness of cross-modal CoT for translation transfer.
Implications and Future Directions
UniSS demonstrates that a unified, single-stage AR LLM can achieve high-fidelity, expressive S2ST by leveraging pre-trained text translation capabilities and cross-modal CoT prompting. The approach simplifies architecture, reduces error propagation, and enables flexible quality-efficiency trade-offs. The UniST dataset sets a new standard for expressive S2ST data, facilitating further research.
Practical implications include real-time interpretation, cross-lingual dubbing, and personalized voice assistants. The framework is extensible to multilingual scenarios and can be adapted for other expressive speech tasks. Future work should focus on:
- Extending language coverage via scalable data synthesis.
- Developing unified tokenizers to reduce vocabulary size and further streamline the model.
- Investigating robustness to noisy or spontaneous speech and domain adaptation.
Conclusion
UniSS introduces a unified, expressive S2ST framework that directly leverages pre-trained LLMs for translation, achieving SOTA results in fidelity, expressiveness, and efficiency. The cross-modal CoT prompting and progressive training paradigm are critical for transferring textual translation expertise to speech. The release of UniST enables reproducible research and sets a new benchmark for expressive S2ST. The work provides a practical and theoretically sound foundation for next-generation speech translation systems, with clear paths for future expansion and improvement.