- The paper introduces a unified taxonomy of 45 NVV types and a bilingual dataset covering English and Chinese for systematic evaluation.
- The paper presents a multi-axis protocol that decouples general speech quality from NVV controllability using objective metrics and LLM-based ratings.
- The paper benchmarks 15 TTS systems, revealing trade-offs between inventory breadth and NVV precision while identifying synthesis bottlenecks.
NVBench: A Systematic Benchmark for TTS with Non-Verbal Vocalizations
Motivation and Contributions
Standard speech synthesis evaluation has long treated speech largely as a sequence of lexical units, neglecting the profound communicative and affective functions of non-verbal vocalizations (NVVs) such as laughter, sighs, sobs, and subtle oral cues. These events play a central role in emotional nuance, conversational realism, and user engagement, defining the boundaries of human-like synthetic speech. However, progress in the synthesis of NVVs has been hampered by inadequate evaluation: prior resources are limited in taxonomy, language, or interface coverage, and lack standardized protocols that clearly differentiate between speech quality and NVV-specific controllability, placement, and salience.
"NVBench: A Benchmark for Speech Synthesis with Non-Verbal Vocalizations" (2604.16211) introduces a comprehensive bilingual (English/Chinese) benchmark addressing these critical gaps. NVBench encompasses the following primary components:
- A unified taxonomy comprising 45 fine-grained NVV types covering respiratory, physiological, affective, and oral events.
- A balanced bilingual evaluation set, comprising 4,500 human-audited utterances (2,250 per language), ensuring uniform per-type representation.
- Flexible evaluation interfaces including prompt-based (caption-specified) and tag-based (inline annotation) NVV controls.
- A multi-axis protocol that rigorously separates lexical naturalness/quality from NVV controllability, placement, and perceptual effect, assessed through a combination of objective metrics, human listening, and LLM-based multi-rater evaluation.
- Exhaustive experimental benchmarking of 15 TTS systems, spanning both commercial and open-source models, with explicit per-type and per-interface breakdowns.
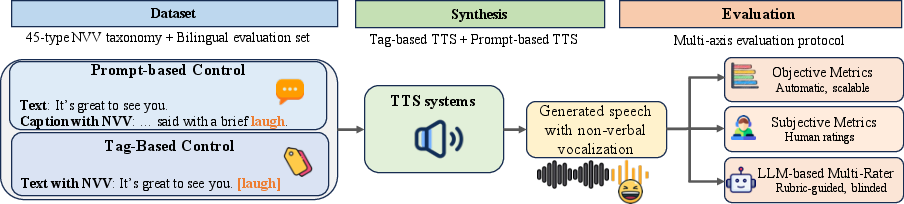
Figure 1: Overview of NVBench design, illustrating unified taxonomy, multi-interface evaluation, and multi-axis metric protocol.
Unified Taxonomy and Dataset Construction
NVBench establishes a model-agnostic, production- and function-aware taxonomy, systematizing the NVV space into six superordinate classes: respiratory events (e.g., breath, sigh, gasp), throat/physiological reflexes (e.g., cough, sneeze), laughter/cry spectra (differentiating intensities and conversational functions), emotional vocalizations (e.g., hum, grunt, moan), and a diverse array of oral/miscellaneous cues (e.g., lipsmack, gulp, whisper). This surpasses prior datasets and system inventories, which are typically fragmented and inconsistent in label space.
Bilingual data construction is achieved via a three-stage pipeline:
- LLM-assisted mining of NVVs from expressive human speech corpora.
- Taxonomy-driven controlled prompt generation for coverage normalization.
- Exhaustive human validation and iterative replenishment for plausibility and clarity.
This pipeline yields uniform coverage across 45 NVV types, tightly controlling representation across English and Chinese, and ensuring high signal-to-noise for both modeling and evaluation.
Evaluation Protocol and Metrics
NVBench's evaluation protocol operates along several axes:
- General speech quality and intelligibility (e.g., DNSMOS P.835, word/character error rates).
- Caption-speech semantic alignment for prompt-based systems (e.g., CLAP score).
- NVV controllability: precision, recall, F1, and normalized onset distance with respect to the requested NVV types and positions (tag-based).
- Perceptual salience of NVVs via targeted human and LLM-based ratings.
- Multi-axis subjective listening, rigorously distinguishing naturalness, quality, NVV accuracy, and expressiveness.
- LLM-as-a-judge scoring for scalable, reproducible, and bias-attenuated evaluation of synthetic speech qualities, leveraging recent advances in instruction-tuned audio-aware models.
This multi-pronged protocol directly addresses the observed partial decoupling between general audio quality and NVV controllability, allowing for precise diagnosis of system failure modes.
Systematic Benchmarking and Strong Numerical Results
Fifteen representative TTS systems are evaluated, encompassing both prompt-based and tag-based paradigms. Key experimental findings include:
- Decoupling of NVV controllability from general speech quality: Systems can achieve high signal fidelity or naturalness (DNSMOS, MOS) while failing at precise and perceptually salient NVV realization, and vice versa.
- Breadth versus accuracy trade-offs: Systems with broader NVV event inventories often realize individual events less reliably, while highly accurate realization is observed primarily in systems with minimal inventory (e.g., ChatTTS effectively only for "laugh").
- Persistent synthesis bottlenecks: Low-SNR oral cues (e.g., tsk, lipsmack) and temporally extended affective NVVs (e.g., sobbing, wailing) remain the most challenging, with salient perceptual effects rarely attained across all systems. Statistical analyses and per-type heatmaps highlight this issue and reveal significant gaps even in commercial models.
- Coverage limitations in open source: Most open-source tag-based systems support only a small fraction (~1–13/45) of NVV types; commercial models (e.g., ElevenLabs) offer broader support but still display per-type inconsistencies.
- Objective metrics misalignment: Traditional WER/CER and signal-level scores penalize non-lexical segments or NVV insertions leading to paradoxical objective degradation when enabling NVV synthesis, even when human preference increases.
- Consistent cross-modal trends: LLM-based evaluation rankings align strongly with human listening, validating the use of scalable automated raters for nuanced paralinguistic assessment.


Figure 2: NVV perceptual effect heatmaps for English (left) and Chinese (right) for both tag-based (upper) and prompt-based (lower) control interfaces, visualizing type coverage and realization gaps.
Implications and Prospective Directions
Practically, NVBench establishes new standards for both system and dataset development in TTS with NVV control. Explicitly, the findings motivate:
- The need for inventory expansion and disambiguated control across the full physiological and affective spectrum of NVVs for human-like conversational agents.
- Rigorous separation of lexical/audio quality from non-verbal expressivity in both training and evaluation pipelines.
- Data-centric enhancements targeting underrepresented, low-SNR, or temporally sustained NVV classes.
- Development of specialized, NVV-aware objective metrics, as conventional signal and transcriptional benchmarks are inadequate for non-lexical content.
- Adoption of scalable, robust LLM-based judge frameworks for diverse speech synthesis assessment.
Theoretically, the observed bottlenecks and decouplings suggest that current generative models lack sufficient paralinguistic granularity in internal representations, especially for events that demand temporal coherence and fine-grained control over rapid, low-energy articulatory gestures. Progress may require architectural innovations (e.g., hierarchical or hybrid generative paradigms) and paralinguistic supervision strategies.
Looking forward, NVBench's unified evaluation suite is primed for future developments in expressive, multi-modal, and context-aware speech synthesis, providing a critical scaffold for candidates aspiring to super-human conversational fluency.
Conclusion
NVBench constitutes a rigorous, extensible benchmark for evaluating the inclusion and controllability of NVVs in speech synthesis, facilitating standardized, multi-dimensional, and bilingual assessment. Through exhaustive empirical and perceptual study, the benchmark exposes the complex interplay—and frequent misalignment—between standard TTS quality and true non-verbal expressiveness. These insights will catalyze both practical advances in conversational AI and theoretical inquiry into multimodal paralinguistic generation.

