- The paper demonstrates a novel hybrid ensembling method combining natural language (CoT) and programmatic (PoT) reasoning to achieve self-consistency with only two samples.
- It employs cross-modal early-stopping using Bayesian hypothesis tests, reducing sample usage by a factor of 9.3× compared to traditional approaches.
- Empirical results across diverse benchmarks show improved accuracy and efficiency, enabling cost-effective large-scale LLM reasoning deployments.
Self-Consistency from Only Two Samples: CoT-PoT Ensembling for Efficient LLM Reasoning
Introduction
The sampled-based ensembling paradigm—self-consistency (SC)—is a primary method for increasing the robustness of LLM-generated reasoning. However, standard SC typically requires large decoding budgets, with 20-40 samples per input being common for state-of-the-art accuracy, resulting in substantial computational overhead. This paper introduces a hybrid ensembling framework that leverages diverse reasoning modalities—specifically, Chain-of-Thought (CoT) and Program-of-Thought (PoT)—to enable higher accuracy and, notably, achieves self-consistency in the majority of cases with only two samples, a scenario unattainable with prior approaches (2604.17433).
Method: Cross-Modal Self-Consistency via CoT and PoT
Standard SC exploits temperature sampling to engender diverse inference trajectories, but empirical analysis shows most diversity is superficial—CoT paths predominantly deliver stochastic rewordings rather than substantively distinct reasoning. This work innovates by sampling one CoT (natural language step-wise reasoning) and one PoT (symbolic or code-based reasoning), harnessing the intrinsic orthogonality in their strengths and error modes.
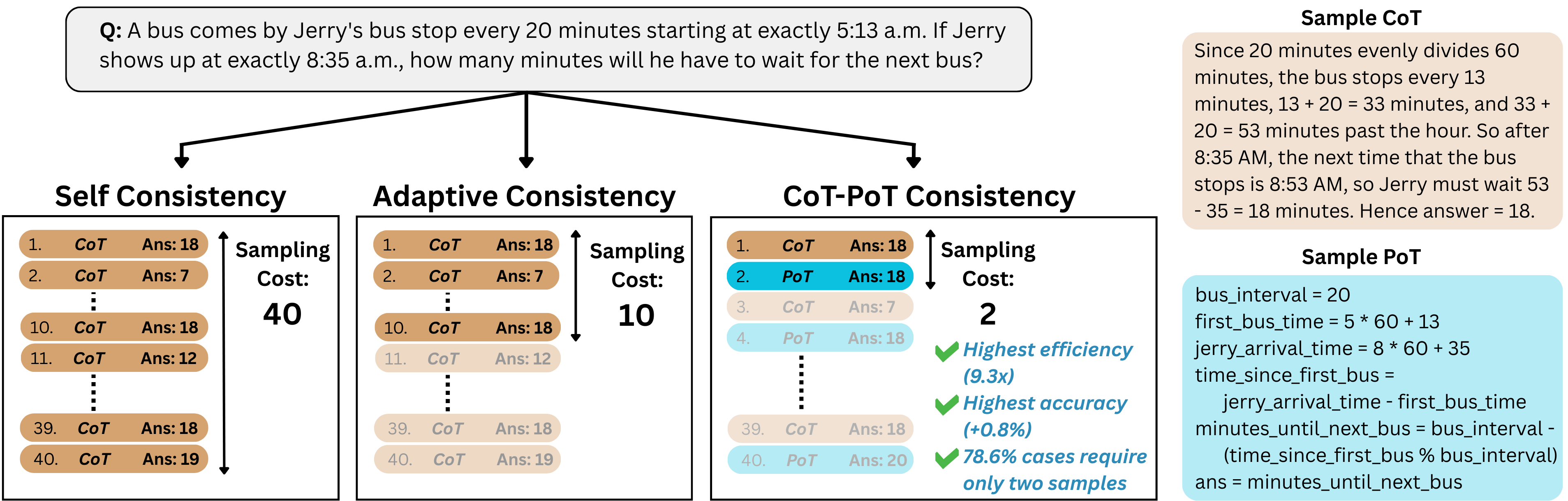
Figure 1: CoT-PoT consistency provides the highest accuracy, the highest efficiency, and can solve most problems with only two samples, unlike any prior self-consistency method.
Rather than sampling many instances in a single modality, alternation is imposed: one CoT, one PoT, repeat, until either a stop criterion is reached or the full decode budget is exhausted. Aggregation across modalities is performed via multiple variants: global majority voting over both modalities (CP-F-maj), dominance by maximal confidence in a single modality (CP-F-max), and prioritization of answers where both modalities agree (CP-F-agr).
Early-Stopping via Cross-Modal Agreement
The critical empirical insight is that agreement between CoT and PoT is a strong indicator of answer safety (i.e., correctness, or that extended sampling will not change the answer). To formalize this, a Bayesian hypothesis test is constructed for each unique answer: observing k cross-modal agreements in t trials yields a posterior confidence score for answer safety. Sampling terminates if any answer’s confidence exceeds a threshold ρ (typically 0.975). Data-driven estimation of all necessary probabilities c,a1,a2 is performed on held-out data for each model and domain.
Various instantiations are analyzed: "any-to-any" (stop on the first CoT-PoT agreement for any sample), "first-to-any" (stop when any other sample agrees with the first answer posited by either modality), and the most conservative, "first-to-first" (stop on agreement between the initial zero-temperature CoT and PoT samples only).
Importantly, all of these are fused with adaptive consistency—majority stopping within modalities via the Beta-Bernoulli posterior—guaranteeing the approach can fall back to standard SC stopping if cross-modal agreement never emerges.
Empirical Results
Five benchmarks are evaluated, spanning mathematical, financial, and tabular reasoning (GSM8K, MATH, FinQA, SVAMP, TabMWP). Models are sampled from across the current state of LLM research: GPT-3.5, GPT-4o, Mistral-Large, Qwen3-Coder, and DeepSeek-R1.
The dominant finding is that CoT-PoT ensembling surpasses both CoT-only and PoT-only SC—with average absolute accuracy gains of 1.1% under constant decode budget. Moreover, CoT-PoT early-stopping achieves optimal efficiency: 78.6% of cases can be solved with only two samples (one CoT, one PoT), and this number increases with model quality.
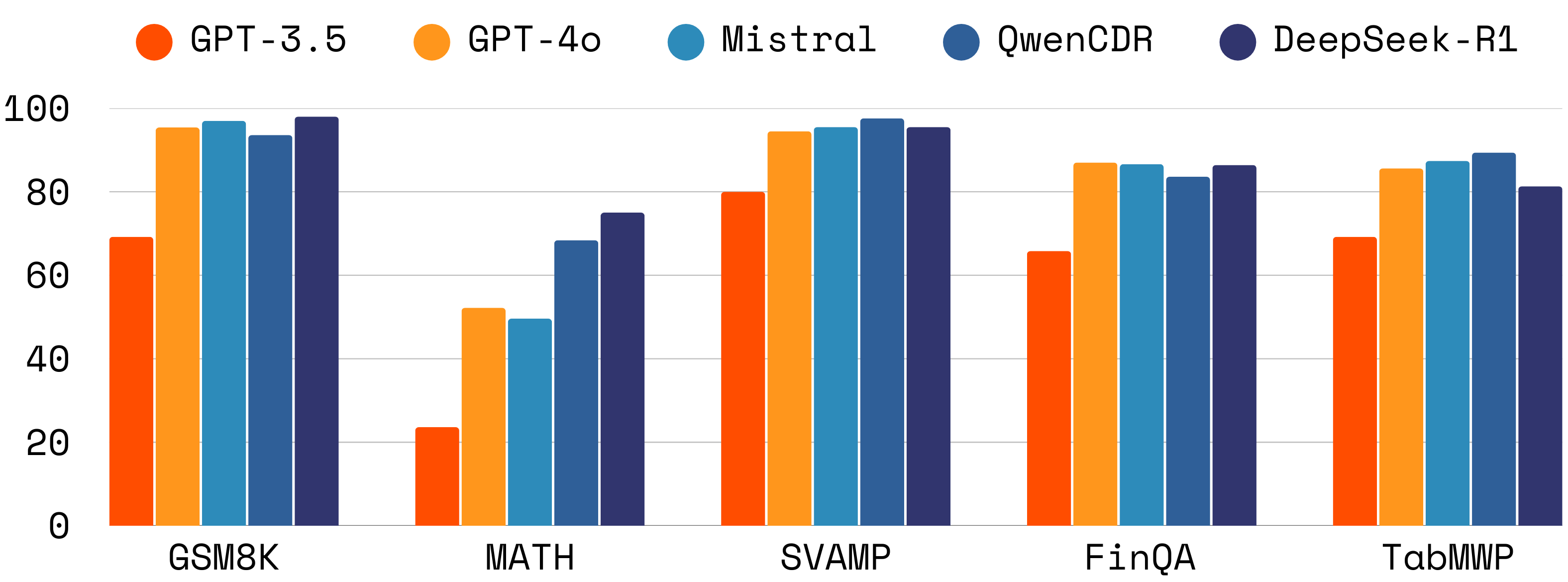
Figure 2: Percentage of problems solved with only two samples by early-stopping CoT-PoT methods.
Further, across all models, the number of samples required for high-confidence self-consistency falls by a factor of 9.3× compared to standard SC. For each dataset, CoT-PoT early-stopping either matches or exceeds the accuracy of full sampling, with efficiency gains compounding as the sample budget increases.
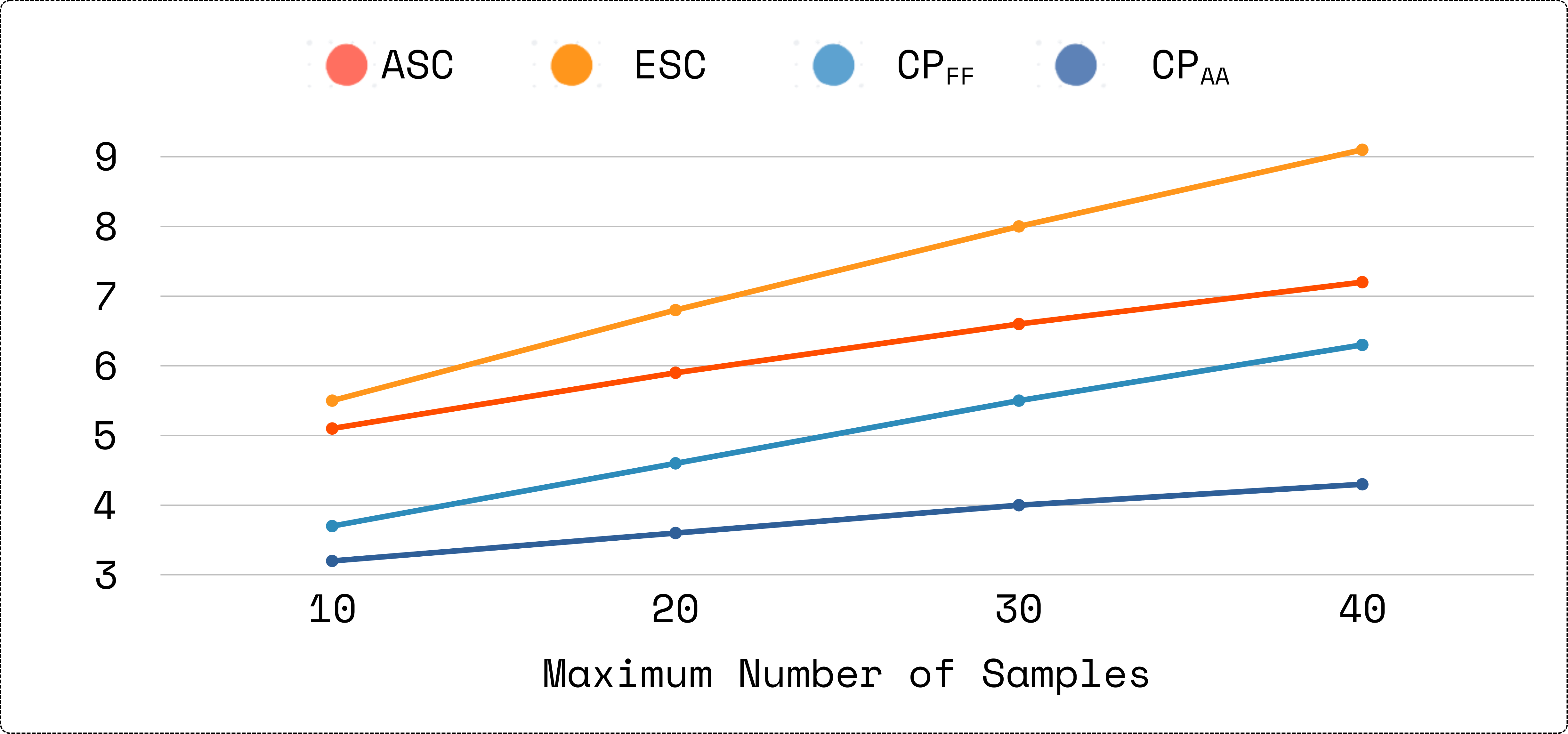
Figure 3: Efficiency vs. sampling budget for different early-stopping strategies, with CoT-PoT ensembling sustaining superior sample efficiency as the budget increases.
Ablations establish the necessity of true cross-modal agreement: early-stopping on intra-modality agreement (e.g., two CoTs with the same answer), as in standard SC, leads to both lower accuracy and higher sample usage. Furthermore, a bootstrapped learning experiment shows that weak models with poor PoT capability can use CoT-to-PoT self-training to close the gap, and still profit from the ensembling method, though in this scenario data-driven (rather than heuristic) confidence estimation is critical.
Practical and Theoretical Implications
Practically, the implications are unambiguous: for mathematical or programmatically structured reasoning, a cross-modal SC protocol can retain or exceed state-of-the-art accuracy with an order-of-magnitude less compute. This enables affordable mass deployment of LLMs in test-time settings that previously would have been bottlenecked by compute cost, such as automated grading, mass mathematical annotation, or large-scale code analysis. Notably, these efficiency gains become more beneficial as models grow stronger—since the probability of early CoT-PoT agreement (and thus low sample count) increases.
Theoretically, the findings suggest that "reasoning diversity" should be measured at a semantic level (modal or representational), not merely stochastic variation in model output induced by temperature. Furthermore, cross-modal agreement is empirically an indicator of "answer safety" (not simply correctness), tying into theoretical questions about reliability calibration in black-box LLMs under program synthesis or symbolic reasoning tasks.
Limitations and Future Directions
The main caveat is that tasks requiring exclusively natural language (e.g., open-ended QA) or where program synthesis cannot capture the reasoning steps (e.g., commonsense, ethical judgment) may see diminished returns from the PoT channel. Moreover, agreement due to parallel conceptual misinterpretations (as analyzed in failure cases) will not be resolved by increased sampling within this framework; adversarial design may target these failure modes specifically.
Extensions may include dynamic allocation of samples between modalities based on task structure or running confidence, as well as incorporating additional reasoning representations (e.g., diagrammatic or graphical), or auto-detecting which modalities to ensemble based on online estimation of their informativeness.
Conclusion
CoT-PoT ensembling constitutes a principled and highly effective SC strategy for LLM reasoning tasks over arithmetic, symbolic, and structured domains. By exploiting semantically independent error distributions between step-wise natural language reasoning and executable programmatic rationales, it sets a new standard in inference efficiency: most tasks now require only two samples for high-confidence outputs, with accuracy exceeding or matching that of compute-heavy SC baselines. This positions cross-modal early-stopping as a new default for practical large-scale LLM reasoning deployments (2604.17433).

