- The paper introduces a hierarchical encoder-decoder network that predicts dense deformation fields from sparse, noisy intra-operative point clouds for accurate brain shift compensation.
- The method utilizes set abstraction and Transformer-based feature propagation modules, achieving impressive metrics with a mean EPE of 1.13 mm and RMSE of 1.33 mm.
- Experimental results demonstrate robust performance under low visibility and high noise conditions, with an efficient runtime of 175 ms per case suitable for surgical workflows.
Deep Learning-Based Non-Rigid Volume-to-Surface Registration for Brain Shift Compensation Using Point Cloud
Introduction and Problem Context
Non-rigid brain deformation, or brain shift, remains a significant barrier in neurosurgical navigation, disrupting the spatial correspondence between pre-operative imaging (e.g., MRI) and intra-operative anatomy. Traditional compensation strategies rely on intra-operative volumetric modalities (MRI, CT, or US), which are not workflow-compatible due to their cost, invasiveness, and acquisition time. Instead, limited, sparse 3D intra-operative surface data—available as point clouds from stereoscopic microscopes or laser range scanners—have motivated volumetric-to-surface registration as a practical alternative. Crucially, these point clouds are partial, noisy, and lack explicit correspondence to the full pre-operative model, making deformation estimation intrinsically ill-posed.
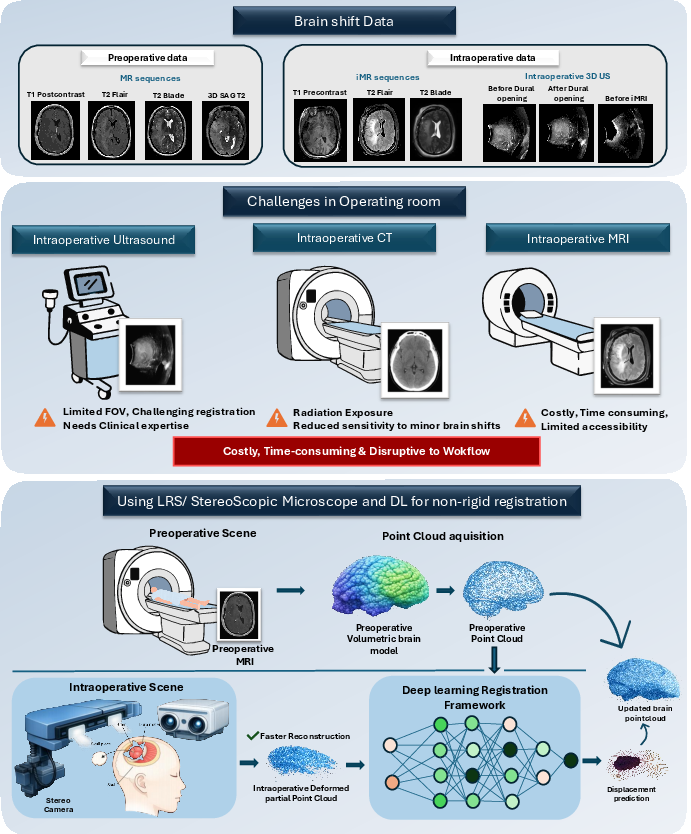
Figure 1: Overview of the brain-shift compensation scenario, limitations of intra-operative imaging, and integration of pre-operative MRI, intra-operative point cloud acquisition, and deep learning-based deformation estimation.
This paper proposes a deep learning-based framework that learns to predict dense volumetric deformation fields (DVFs) directly from partial intra-operative point clouds, allowing robust brain shift compensation without requiring explicit correspondences or intraoperative volumetric imaging (2604.17389).
Methodology
Network Architecture
The core contribution is a hierarchical encoder-decoder network that processes both the dense pre-operative point cloud and the partial intra-operative surface. The encoder uses successive Set Abstraction (SA) modules for hierarchical feature extraction—downsampling the geometry and aggregating local and global context—while the decoder uses Transformer-based Feature Propagation (FP) modules to iteratively upsample and refine features, enabling both local and global geometric reasoning.
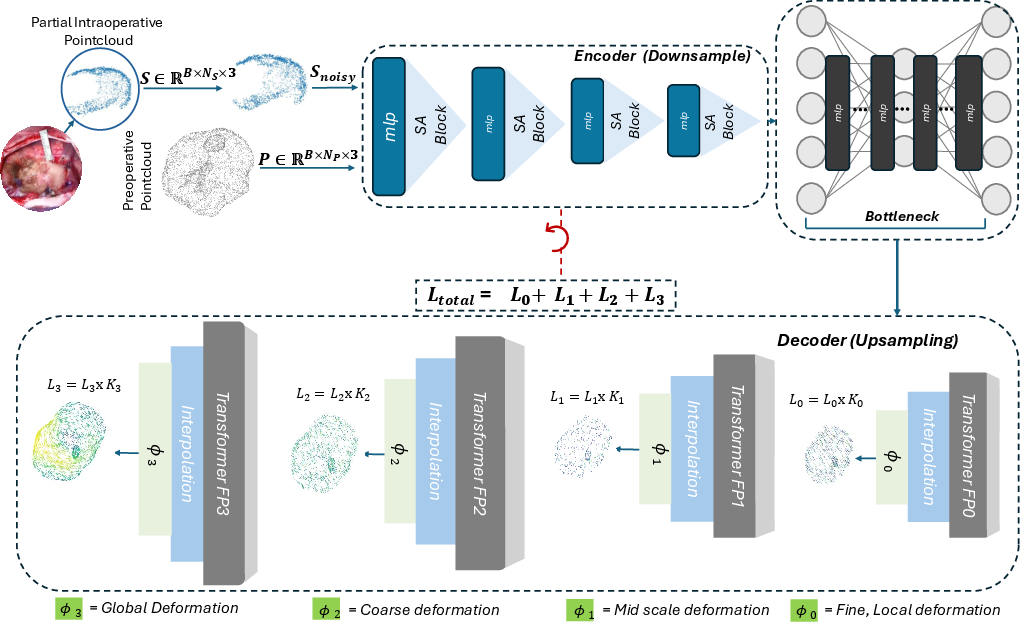
Figure 2: The proposed volume-to-surface registration network with an encoder-decoder architecture. The encoder applies SA on both pre-operative and partial intra-operative point clouds, and the decoder uses FP modules and Transformers to output multi-scale deformation fields.
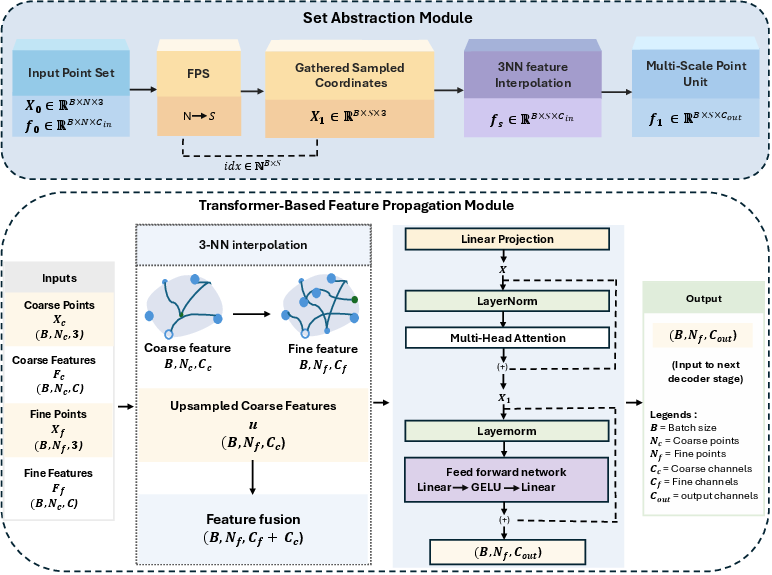
Figure 3: SA module (top) applies farthest point sampling and multi-scale neighborhood aggregation. The FP-Transformer module (bottom) interpolates, fuses, and globally refines features via self-attention.
Deformation fields are predicted at multiple decoder scales, with the highest-resolution output providing the final dense DVF. Training leverages deep supervision at all scales, using a weighted sum of per-point ℓ2 errors between predicted and ground-truth displacements.
Synthetic Data Generation
To address the lack of paired real intra-operative data, synthetic brain shift is modeled on MRI-derived patient-specific brain, tumor, and ventricular geometries sourced from the ReMIND dataset. The framework applies a sequence of analytically-defined non-rigid deformation operators—bulge, sliding, twist, and global sinusoidal warp—composed and regularized via Taubin smoothing to produce anatomically plausible intra-operative states.
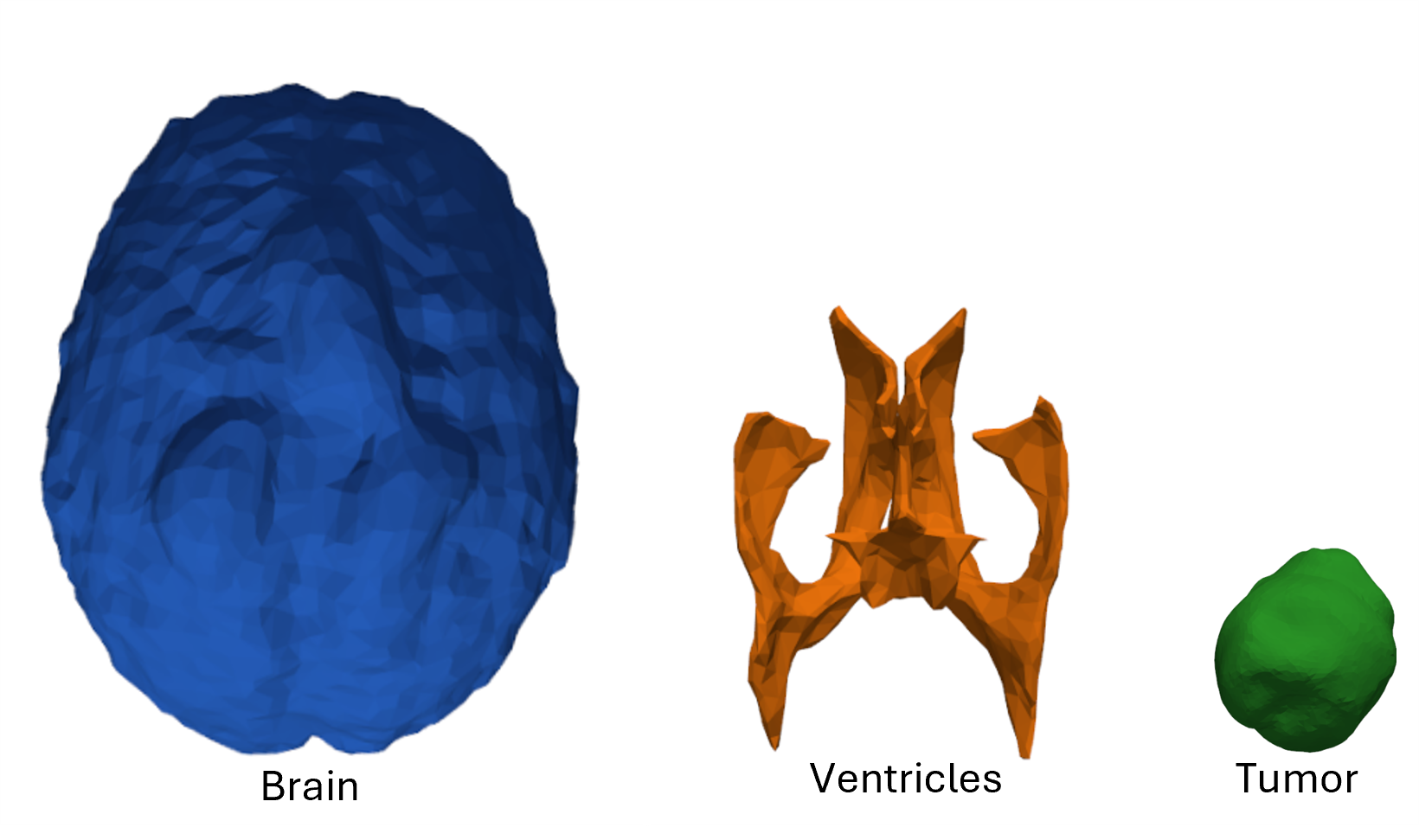
Figure 4: Simplified surface mesh models: brain surface (blue), ventricle (orange), and tumor (green).
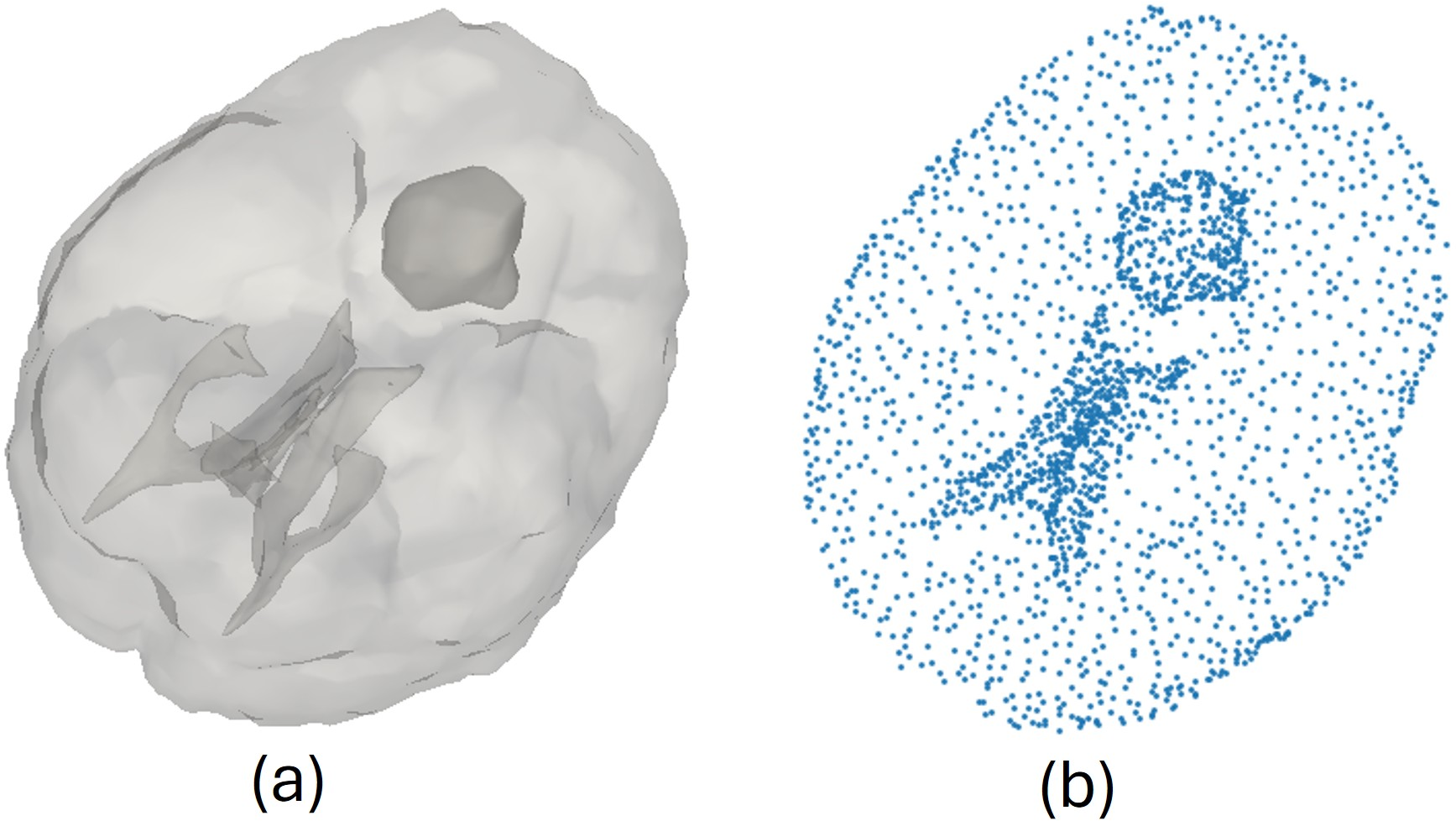
Figure 5: (a) Combined anatomical model for data generation; (b) point cloud sampling for learning non-rigid deformations.
Partial intra-operative point clouds are simulated by randomly sampling contiguous patches at varying visibility ratios (25%–65%), reflecting typical intra-operative exposures.

Figure 6: Partial intra-operative surfaces from a deformed brain at varying visibility ratios, simulating different intra-operative exposure levels.
During training, no explicit one-to-one point correspondences between the input point clouds are assumed, reflecting clinical realities and maximizing the generality of the proposed approach.
Robustness Enhancements
To address the realistic noise found in intra-operative surfaces, the training data for partial surfaces is augmented by both independent Gaussian jitter and spatially coherent displacement fields. This combination mimics realistic measurement uncertainties and structured distortions.
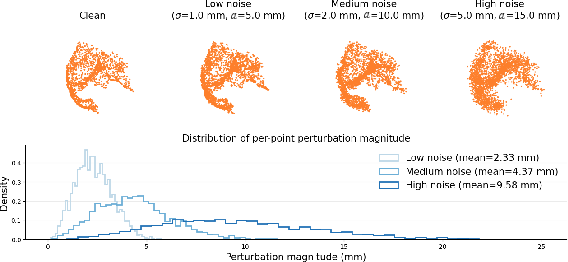
Figure 7: Surface augmentation with increasing noise levels shows the geometric impact of Gaussian and correlated noise on point cloud input.
Experimental Evaluation
Baselines
The framework is quantitatively and qualitatively compared against classical and state-of-the-art learning-based registration methods, including ICP, CPD, NICP, Livermatch, C2P-Net, and Robust DefReg, all retrained and tuned on the same synthetic dataset.
Metrics
Evaluation uses endpoint error (EPE) and root-mean-square error (RMSE) on the final predicted displacements with respect to ground truth, reporting distribution across all test data and performing ablations on surface visibility and noise levels.
Qualitative Results
Across diverse test cases, the proposed method provides markedly better surface and volumetric alignment, reducing local errors even in challenging, asymmetrical, or highly incomplete exposure settings.
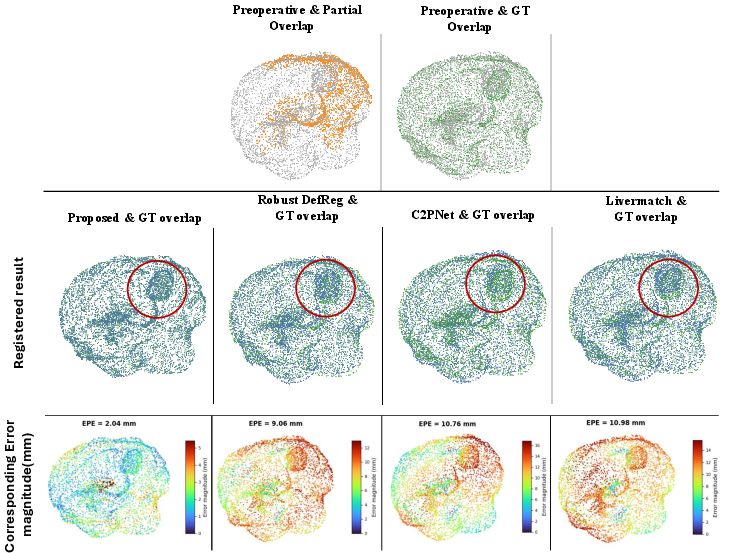
Figure 8: Qualitative registration comparison for Case 1; the proposed method shows lower error and better alignment than competing approaches.
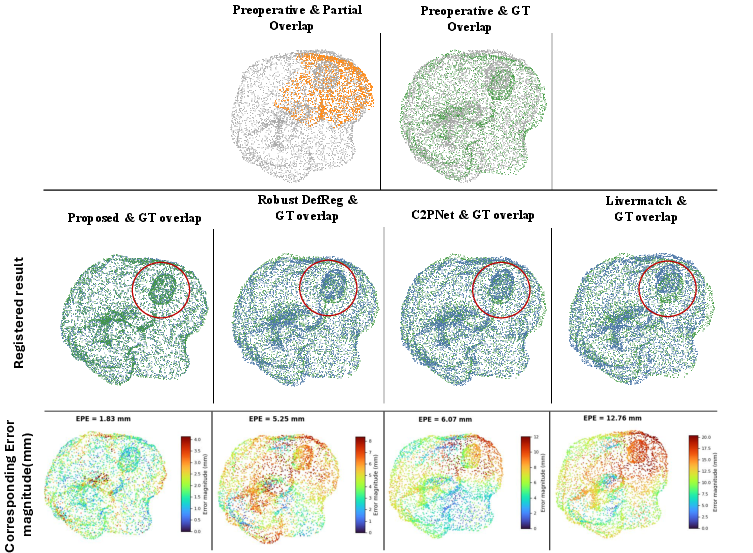
Figure 9: Qualitative registration comparison for Case 2, again favoring the proposed method, especially in poorly covered regions.
Further qualitative ablation reveals that increasing visibility ratio improves alignment, but accurate registration is frequently achieved even with low and/or non-tumor-side coverage, indicating the network’s ability to generalize from global anatomy and learned deformation priors.
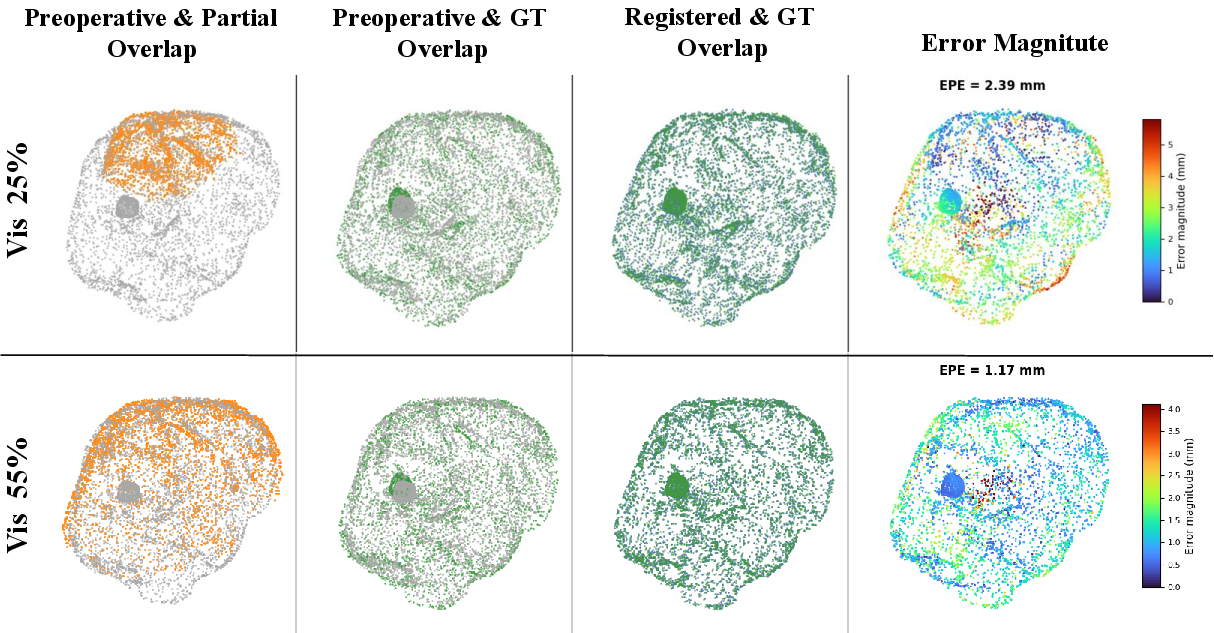
Figure 10: Registration results for Case 3: increasing visibility (25% to 45%) yields visibly improved alignment.
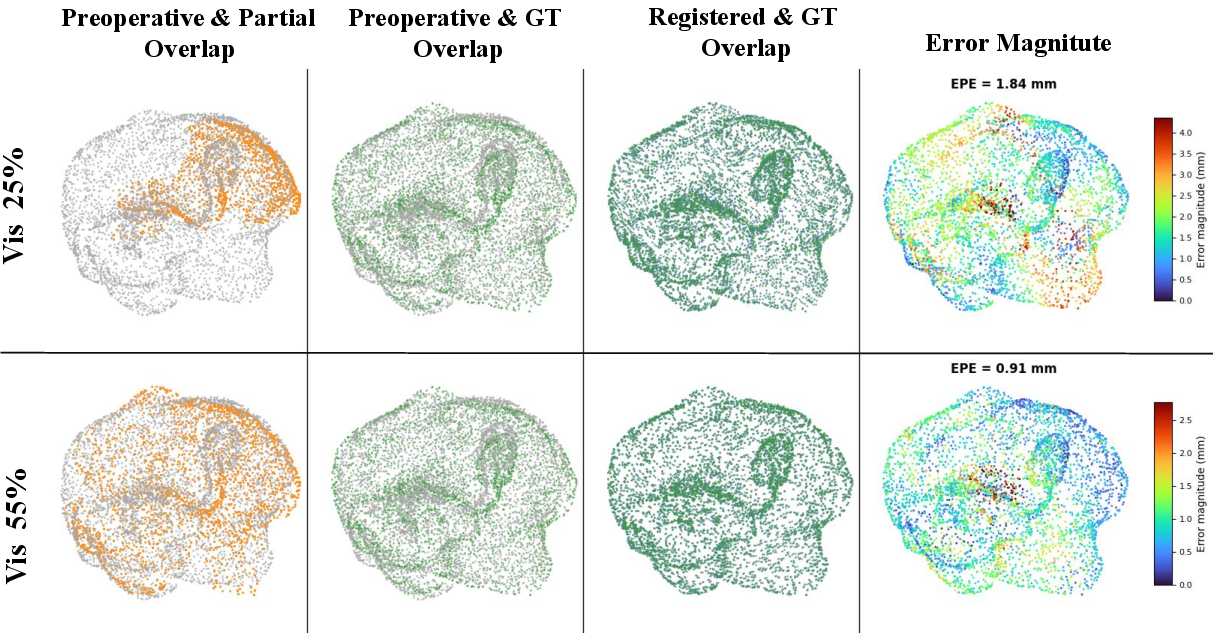
Figure 11: Registration result for Case 4 across visibility levels, highlighting robustness to spatial distribution.
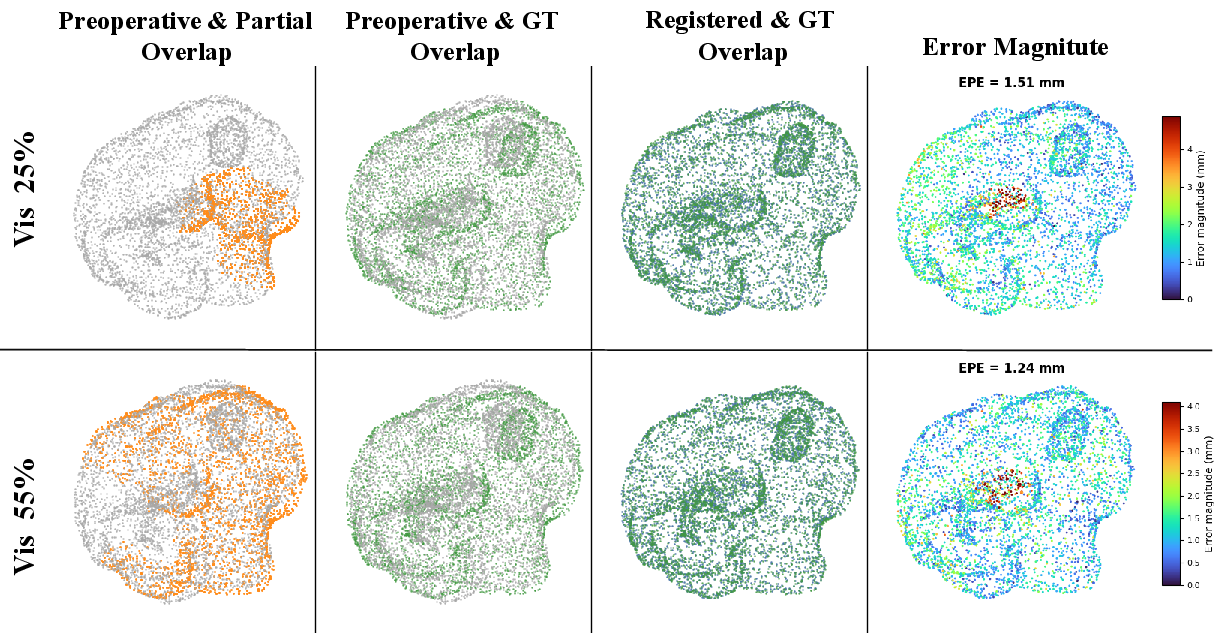
Figure 12: Case 5 shows consistent improvement with additional intra-operative surface observed.
Quantitative Results
The proposed framework outperforms all baselines with a mean EPE of 1.13 ± 0.75 mm and mean RMSE of 1.33 ± 0.81 mm—an order-of-magnitude reduction over conventional non-rigid ICP and substantial absolute improvement over recent learning-based models.
Notably, the method does not require explicit correspondence or prior knowledge of observed region location and remains robust to both high input noise and low surface visibility.
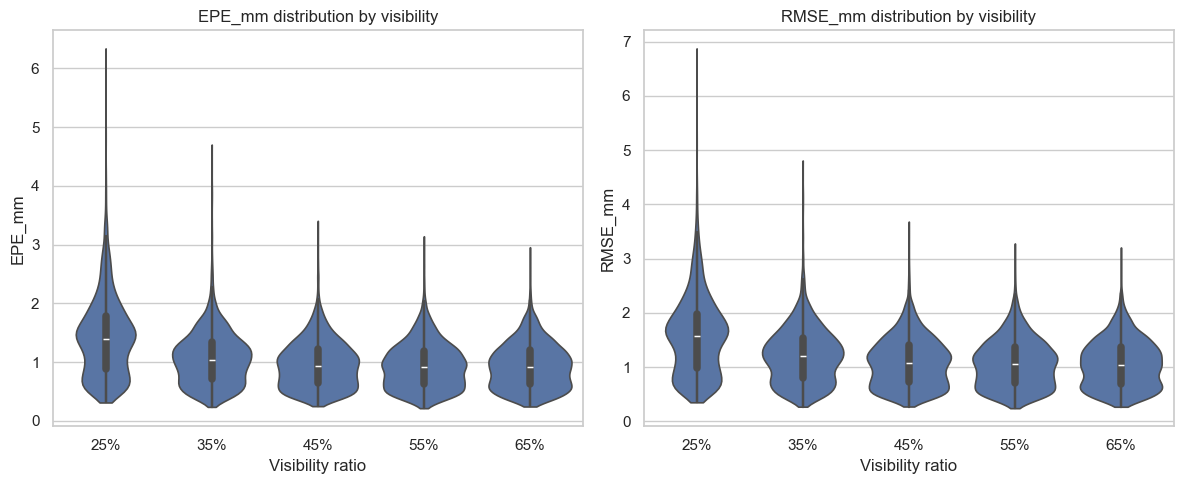
Figure 13: EPE and RMSE distributions for different partial surface visibility ratios—performance improves monotonically with increased exposure, but low-visibility registration remains practical.
Furthermore, the model exhibits graceful degradation with increasing noise: the EPE rises to 2.60 ± 1.02 mm under severe noise, still outperforming all learning and non-learning baselines.
Efficiency is also demonstrated, with an end-to-end average runtime of 175 ms per case (≈5.7 FPS) on an A100 GPU, exceeding the runtime of classical iterative methods and supporting practical intra-operative deployment.
Implications and Future Directions
The findings validate that direct, dense volumetric deformation estimation is feasible from sparse, noisy intra-operative surface observations using multi-scale geometric learning and hierarchical Transformer-based feature integration. The framework establishes a high-accuracy, real-time, and correspondence-free brain shift compensation pipeline compatible with practical surgical workflows, overcoming the bottle-necks of volumetric imaging and rigid registration.
Theoretically, this approach elucidates the sufficiency of global shape priors and implicit surface-geometry correlation for robust DVF inference, even in highly underdetermined settings. The strong performance under low visibility and high noise suggests high potential for generalization to other anatomical regions and soft-tissue surgical contexts.
Future research could address the current framework’s limitations by:
- Integrating physics-based or hybrid biomechanical constraints for physiologically-informed regularization
- Validating on real intra-operative surface reconstructions using LRS or stereo vision
- Extending to diffeomorphic deformation models to preserve anatomical topology
- Scaling to higher-resolution, multi-anatomical datasets and cross-modality registration scenarios.
Conclusion
This work demonstrates that deep learning-based non-rigid volume-to-surface registration, leveraging hierarchical, multi-scale geometric reasoning and robust noise augmentation, achieves state-of-the-art performance in the challenging context of brain shift compensation from partial intra-operative surface point clouds. The approach offers significant practical and theoretical advances in image-guided neurosurgery and sets a foundation for scalable, real-time, correspondence-free deformation tracking across soft-tissue procedures.