- The paper introduces a novel lookaside paradigm that exploits directional language cues for efficient aerial navigation in complex urban settings.
- It presents an Egocentric Lookaside Graph and a Spatial Landmark Knowledge Base to capture and align instruction-relevant spatial information.
- Empirical results on city-scale benchmarks demonstrate state-of-the-art success rates, improved generalization, and reduced computational overhead.
Direction-Aware Aerial Vision-and-Language Navigation with LookasideVLN
Introduction and Motivation
Robust navigation in complex urban environments via natural language guidance remains a strenuous challenge for embodied systems, particularly in aerial domains where landmark ambiguity and vast spatial scales pose unique obstacles. The paper "LookasideVLN: Direction-Aware Aerial Vision-and-Language Navigation" (2604.17190) critiques the prior reliance on landmark sequence alignment—lookahead paradigms—for urban vision-and-language navigation (VLN) and instead introduces a path planning model that centers on the exploitation of directional cues in human instructions. This approach not only augments spatial reasoning fidelity but also significantly improves computational efficiency compared to large-scale scene graph operations.
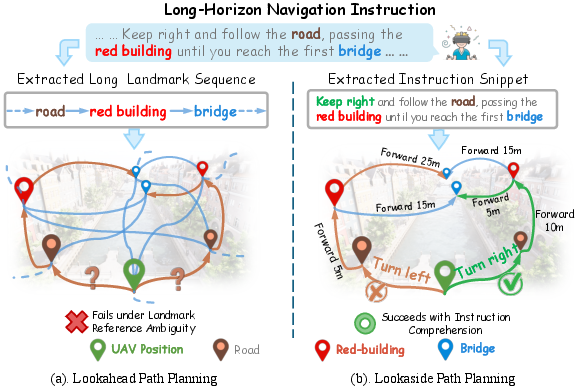
Figure 1: Comparison of two path planning paradigms. (a) Lookahead sequence alignment is inefficient and ambiguous in urban settings with repeated landmarks; (b) The lookaside paradigm leverages directional cues for disambiguation and reduces computational requirements.
System Architecture and Key Components
LookasideVLN operationalizes a modular framework consisting of three main innovations:
- Egocentric Lookaside Graph (ELG): A compact, dynamically constructed graph representing instruction-relevant landmarks and their egocentrically-defined directional relationships.
- Spatial Landmark Knowledge Base (SLKB): A lightweight, efficient memory module recording textual descriptions and 3D positions of historically observed landmarks, supporting fast retrieval and continual scene knowledge acquisition.
- Lookaside MLLM Navigation Agent: An instruction-following agent based on a multimodal LLM (MLLM) that aligns visual observations, ELG-derived direction-aware paths, and instruction segments, conducting reasoning for robust path selection.
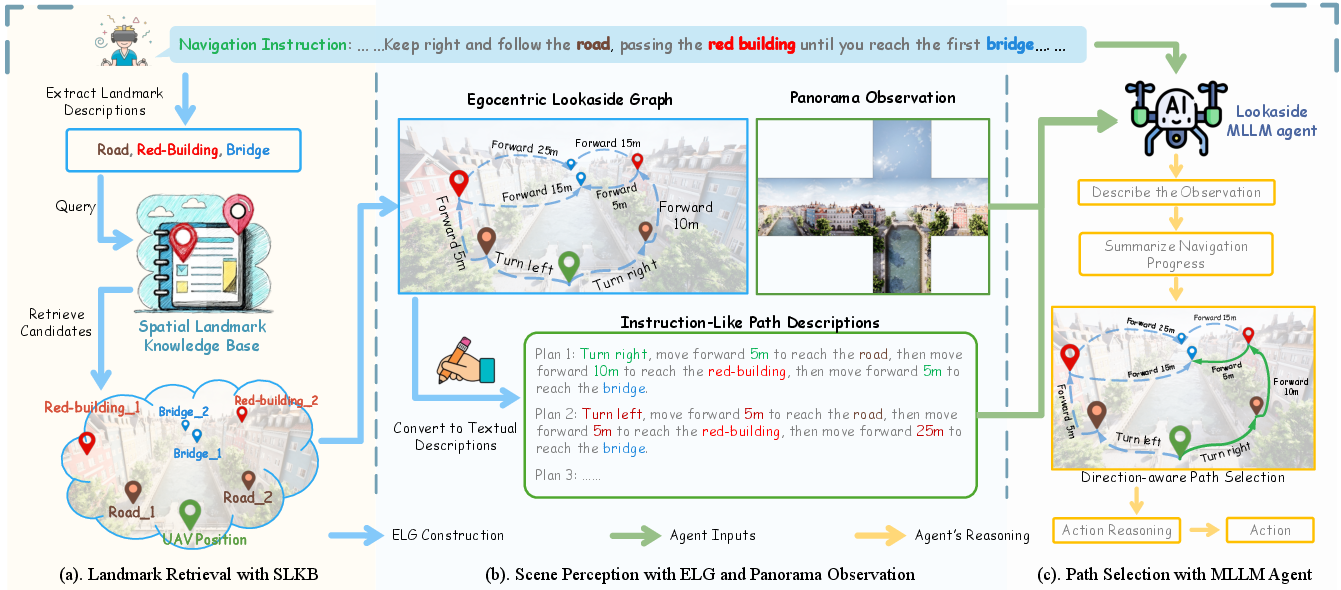
Figure 2: LookasideVLN framework. The agent queries SLKB to generate an Egocentric Lookaside Graph, translates graph paths to direction-aware instruction-like descriptions, and utilizes an MLLM agent for path alignment and action selection.
Spatial Landmark Knowledge Base: Construction and Retrieval
The SLKB encodes landmark data as pairs of textual descriptions and their corresponding world coordinates, continually updated during missions. Newly observed landmarks are extracted via MLLM-based captioning and grounded via object detection (e.g., GroundingDINO) with 3D localization using camera intrinsics and depth (see pixel-to-world transformation in Figure 3). Redundance is managed by merging spatially close instances pointing to the same landmark type.
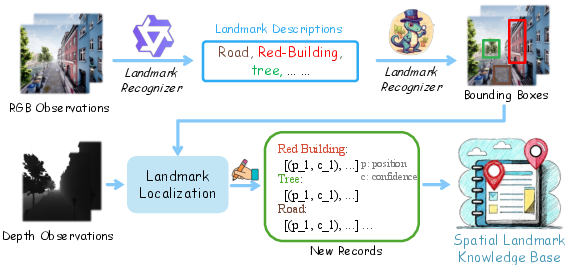
Figure 4: Spatial Landmark Knowledge Base construction pipeline. Landmarks are detected and localized, then inserted or merged into the hierarchical, description-indexed database.
Egocentric Lookaside Graph: Representation of Directional Spatial Knowledge
The ELG is hierarchically organized, layer-wise aligning unvisited instruction-specified landmarks. Within ELG edges, egocentric directions (e.g., left/right turn angles, elevation gain, relative distance) are attached by computing vector transitions between nodes. This encapsulation enables path descriptions in an instruction-like form, facilitating subsequent alignment with the agent's chain-of-thought reasoning.
MLLM-based Navigation Agent
At the decision level, an MLLM agent receives the ELG-induced path candidates (as natural language), current panoramic observations, and the navigation instruction. It sequentially:
Empirical Evaluation
Benchmarking and Metrics
LookasideVLN is evaluated on the AerialVLN and AerialVLN-S benchmarks involving 25 city-scale synthetic environments with long-horizon language-goal navigation. Metrics include Success Rate (SR), Oracle Success Rate (OSR), Navigation Error (NE), and SDTW (combining SR with trajectory-path similarity).
LookasideVLN demonstrates state-of-the-art performance across multiple metrics. On AerialVLN-S, it achieves an SR of 14.7 (Seen) and 12.6 (Unseen), surpassing previous approaches including CityNavAgent, despite being training-free and using only a two-step lookahead. Notably, its generalization to unseen environments is superior to end-to-end trained baselines, attributable to its reliance on instruction-centric directional cues rather than brittle visual similarity or global scene memory.
Analysis and Ablation
Ablation studies confirm the utility of each architectural module:
Failure analysis (Figure 7) reveals susceptibility to instruction parsing errors, particularly with temporally compound directional cues (e.g., missing a "turn around" cue following "slightly left"), underscoring ongoing challenges in instruction comprehension.

Figure 7: Failure case—incorrect action due to missed complex directional cues in instruction.
Practical and Theoretical Implications
LookasideVLN substantiates the hypothesis that explicit modeling of directional language semantics—rather than exhaustive graph-based landmark matching—yields more scalable, interpretable, and generalizable navigation systems for complex aerial domains. Its modular design supports continual knowledge accrual (via SLKB) and reduces computational overhead, making it attractive for real-world application under resource constraints or in environments with high landmark ambiguity.
Theoretically, this work suggests that embodied language agents benefit significantly from egocentric, instruction-grounded spatial reasoning architectures, particularly when rich multimodal alignments can be mediated by large-scale MLLMs.
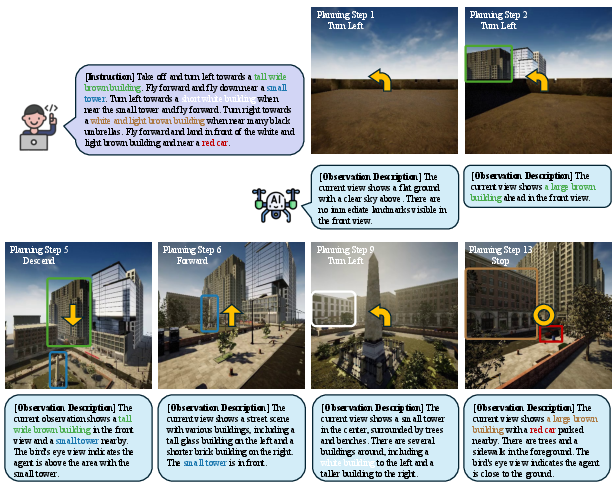
Figure 8: Key steps in a navigation episode—combining accurate observation understanding with context-appropriate action leads to effective navigation.
Future Directions
While LookasideVLN achieves robust simulation performance, real-world deployment will require addressing sim-to-real transfer, further optimizing the efficiency of prompting and planning, and exploring richer representations for 3D and ego-motion understanding. The compositional reasoning ability of MLLMs, when anchored by explicit direction-aware graph constructs, remains a fertile area for advancing embodied navigation models in both aerial and terrestrial settings.
Conclusion
LookasideVLN establishes a new direction-aware paradigm for Aerial VLN by exploiting instruction-level spatial semantics for path planning. Its integration of egocentric graph-based modeling, lightweight spatial memory, and advanced language-vision reasoning yields state-of-the-art performance, computational efficiency, and enhanced generalization. The results demonstrate that leveraging rich directional cues in language significantly advances both the theory and practice of outdoor vision-and-language navigation for UAVs (2604.17190).

