- The paper introduces CoPoLLM, a framework that integrates reinforcement learning for policy acquisition and dual-stream conditional optimization for precise cognitive intervention.
- The paper leverages the innovative CogBiasESC dataset with fine-grained annotations to reliably detect and measure eight types of cognitive distortions in emotional support dialogues.
- The paper demonstrates significant improvements in diagnostic accuracy, crisis intervention precision, and safety metrics over conventional ESC models, validated through human expert evaluations.
Cognitive Policy-Driven LLMs for Cognitive Distortion Diagnosis and Intervention in Emotional Support Conversations
Introduction and Motivation
The intersection of NLP and mental health presents unique challenges for automated Emotional Support Conversation (ESC) systems. Conventional LLM-based ESC agents predominantly offer empathetic comfort; however, they inherently lack mechanisms for engaging in cognitive interventions that are critical for actual therapeutic progress. The primary clinical bottleneck is the identification and correction of cognitive distortions in help-seeker expressions—irrational thinking patterns (e.g., catastrophizing, personalization) that perpetuate psychological distress. This paper formulates a rigorously structured approach, CoPoLLM (Cognitive Policy-Driven LLM), to upgrade LLM-based ESCs beyond surface empathy by integrating cognitive distortion diagnosis and policy-driven intervention aligned with Cognitive Behavioral Therapy (CBT).
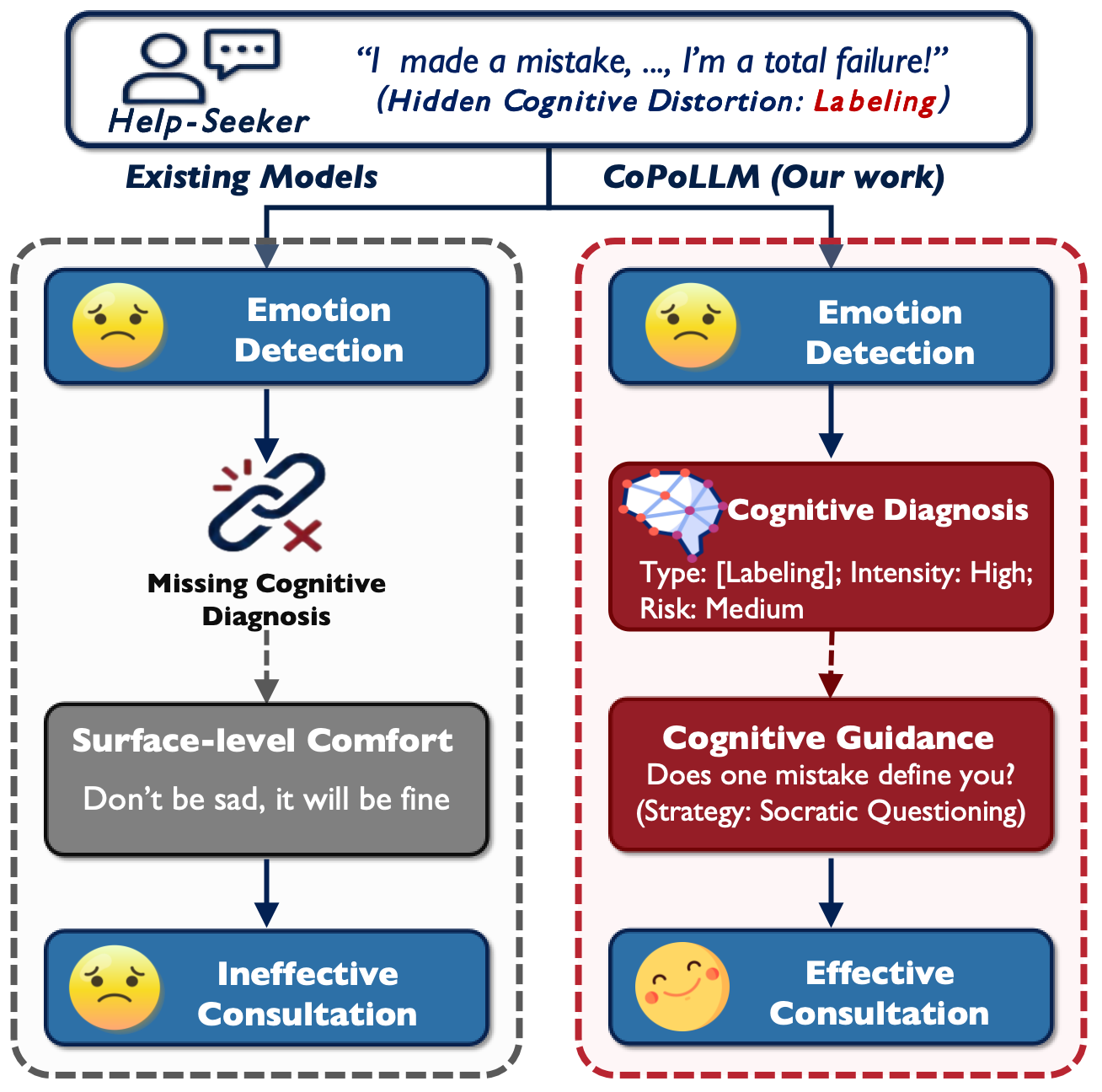
Figure 1: Cognitive Policy-Driven models contrast with traditional psychological models by explicitly modeling cognitive state and policy-driven strategy selection.
Dataset Innovation: CogBiasESC
The inadequacy of prior ESC datasets—lacking fine-grained annotation at the cognitive level—motivated the construction of CogBiasESC, a domain-specific dataset mapping eight core cognitive distortion types (e.g., emotional reasoning, catastrophizing, overgeneralization) with explicit tags for distortion intensity and risk level. Annotation leveraged a dual-phase process: initial filtering with GPT-4o and subsequent triple-expert adjudication, reaching substantial to almost-perfect κ agreement (0.73–0.85). The dataset exhibits a clinically accurate long-tail distribution, with labels capturing simultaneous, multi-distortion episodes per seeker. This structure supports nuanced benchmarking of both diagnostic and intervention responses.
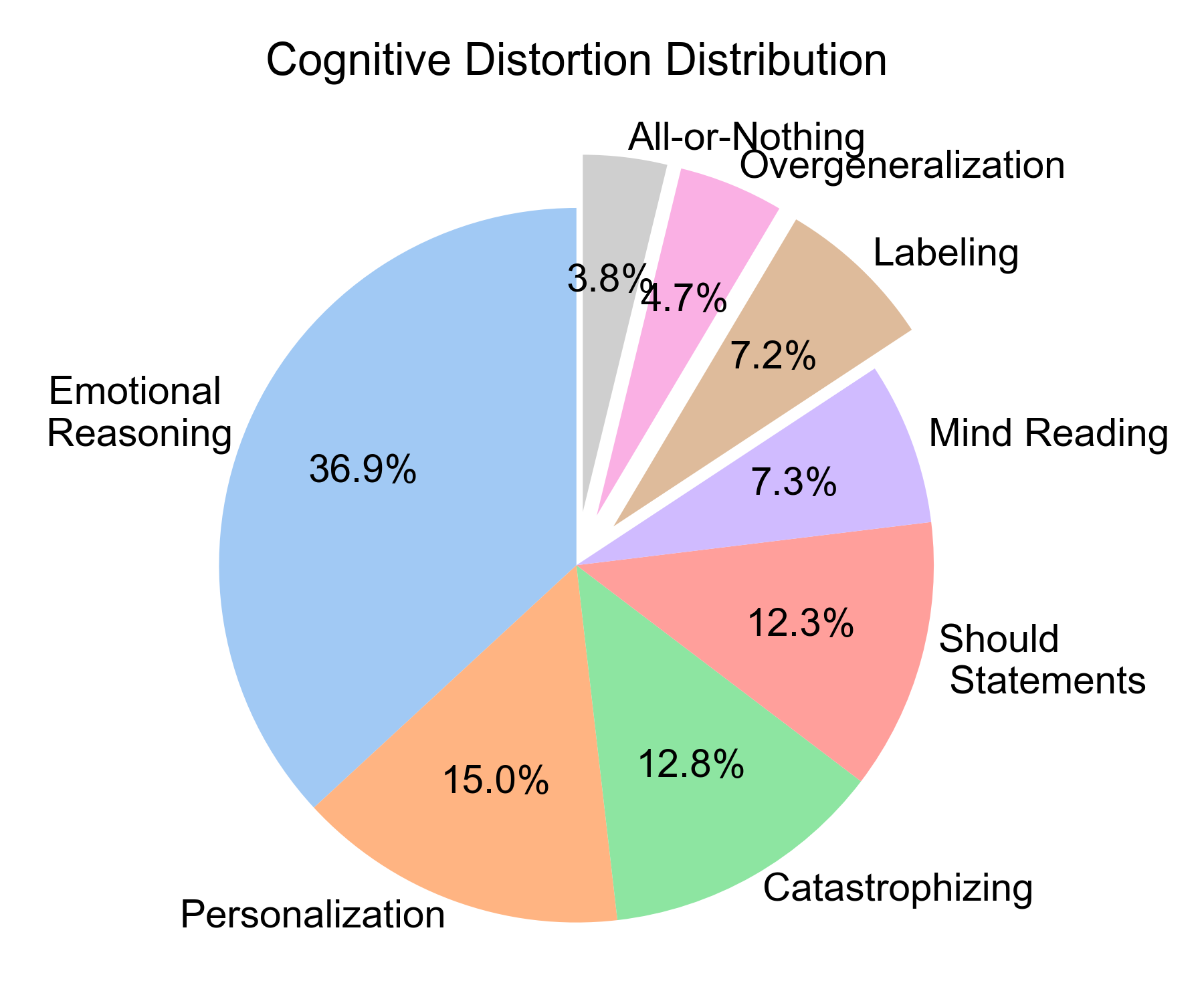
Figure 2: CogBiasESC distribution reveals dominance of Emotional Reasoning and Personalization with a long-tailed frequency spectrum.
Methodology: The CoPoLLM Architecture
CoPoLLM decomposes the ESC task into two explicit modules: (1) Cognitive Policy Reinforcement Learning (CPRL) and (2) Dual-Stream Conditional Optimization (DSCO).
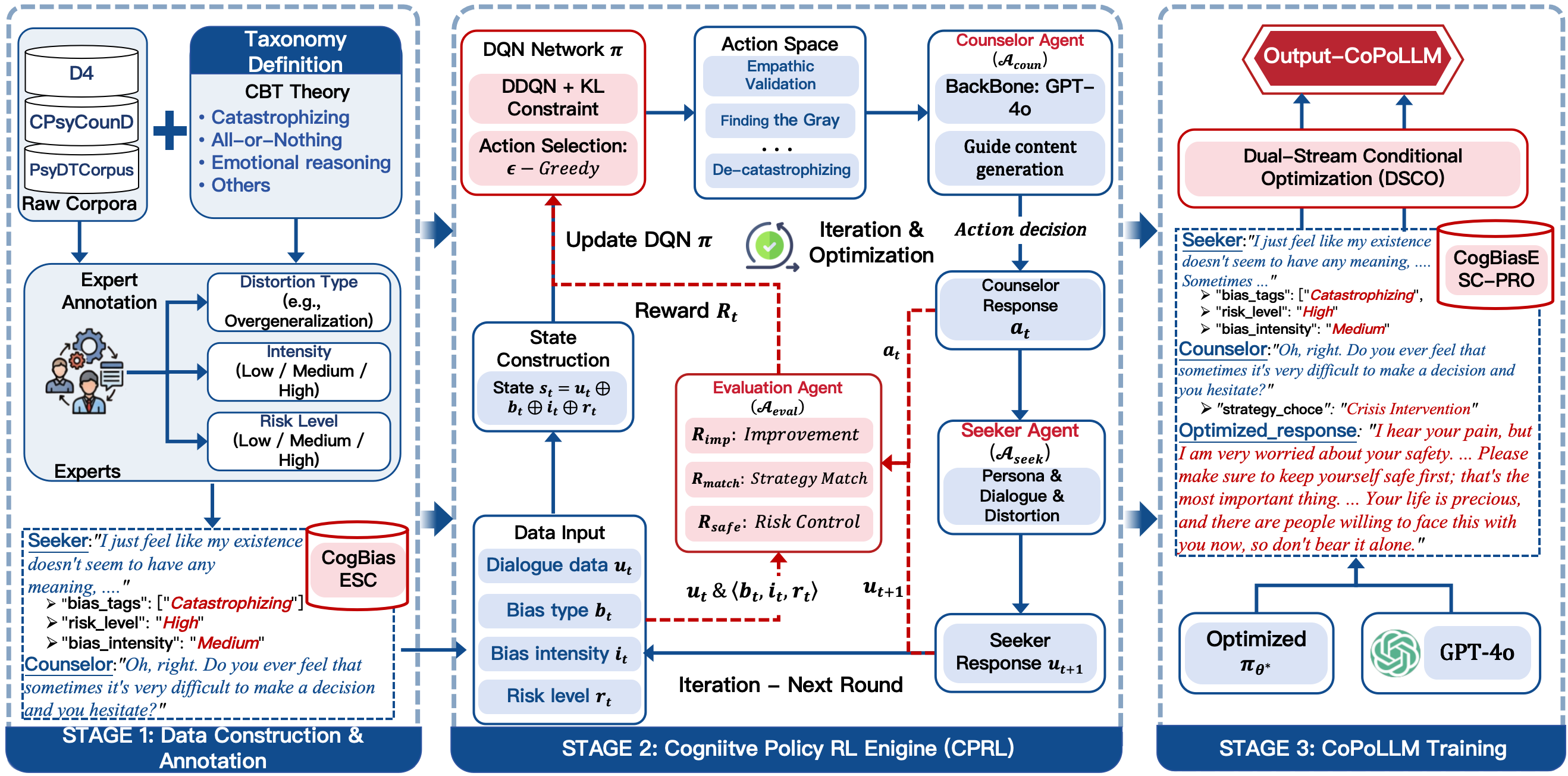
Figure 3: The CoPoLLM architecture: CPRL governs policy acquisition in a multi-agent simulation, while DSCO distills this policy into intervention-oriented LLMs.
Cognitive Policy RL (CPRL) Module
CPRL reframes counseling as a multi-agent environment, with explicit counselor, seeker, and evaluator agents. The state encodes help-seeker utterances and their cognitive labels; actions correspond to discrete CBT strategies (e.g., “Finding the Gray Area,” “Crisis Intervention”). The agent optimizes a value function Q(s,a) using DQN and receives hybrid rewards incorporating symptom improvement, strategy–distortion alignment, and hard-penalty safety compliance. In high-risk (rt) scenarios, only pre-approved crisis strategies are permitted, with the penalty Prisk acting as an asymptotic incentive for policy concentration on safety, as formalized via Boltzmann policy convergence.
Dual-Stream Conditional Optimization (DSCO)
DSCO facilitates explicit transfer of policy knowledge into LLMs. Using augmented data (CogBiasESC-PRO), each training instance encodes both the diagnostic output (set of distortions and risk) and the intervention response, guided by the RL-trained policy. The model is trained with selectively masked loss functions to avoid interference between recognition and response generation, ensuring that the LLM achieves high-fidelity cognitive diagnosis while conditioning responses on the optimal intervention strategy.
Experimental Evaluation
CoPoLLM substantially outperforms both general and domain-specific ESC baselines across all diagnostic and intervention metrics. The macro-F1 for cognitive distortion classification reaches 0.64 (CoPoLLM-Qwen3-8B), exceeding the best closed-source baseline (0.580, Gemini2.5). High-Risk Missed Detection Rate (HRMDR) is suppressed to 0.203, demonstrating robust crisis signal sensitivity.
Clinical Quality Divergence
A critical empirical finding is the pronounced deficit within baseline models: classic LLMs and domain-tuned models exhibit high Emotional Empathy (EmoE > 3.8), but they systematically underperform in Cognitive Awareness (CogA < 2) and Distortion Guidance (BiaG < 1.8). CoPoLLM resolves this decoupling, achieving CogA > 3.5 and BiaG > 3.2 across high-intensity cases, while retaining top-tier empathy. Notably, in human evaluations (Figure 4, Figure 5), CoPoLLM emerges as the only model maintaining balanced scores across all clinical dimensions, including Safety and Risk Management (SaRM), Clinical Professionalism (CliP), and Strategy Effectiveness (StraE), even in high-risk (e.g., suicidal ideation) dialogue groups.
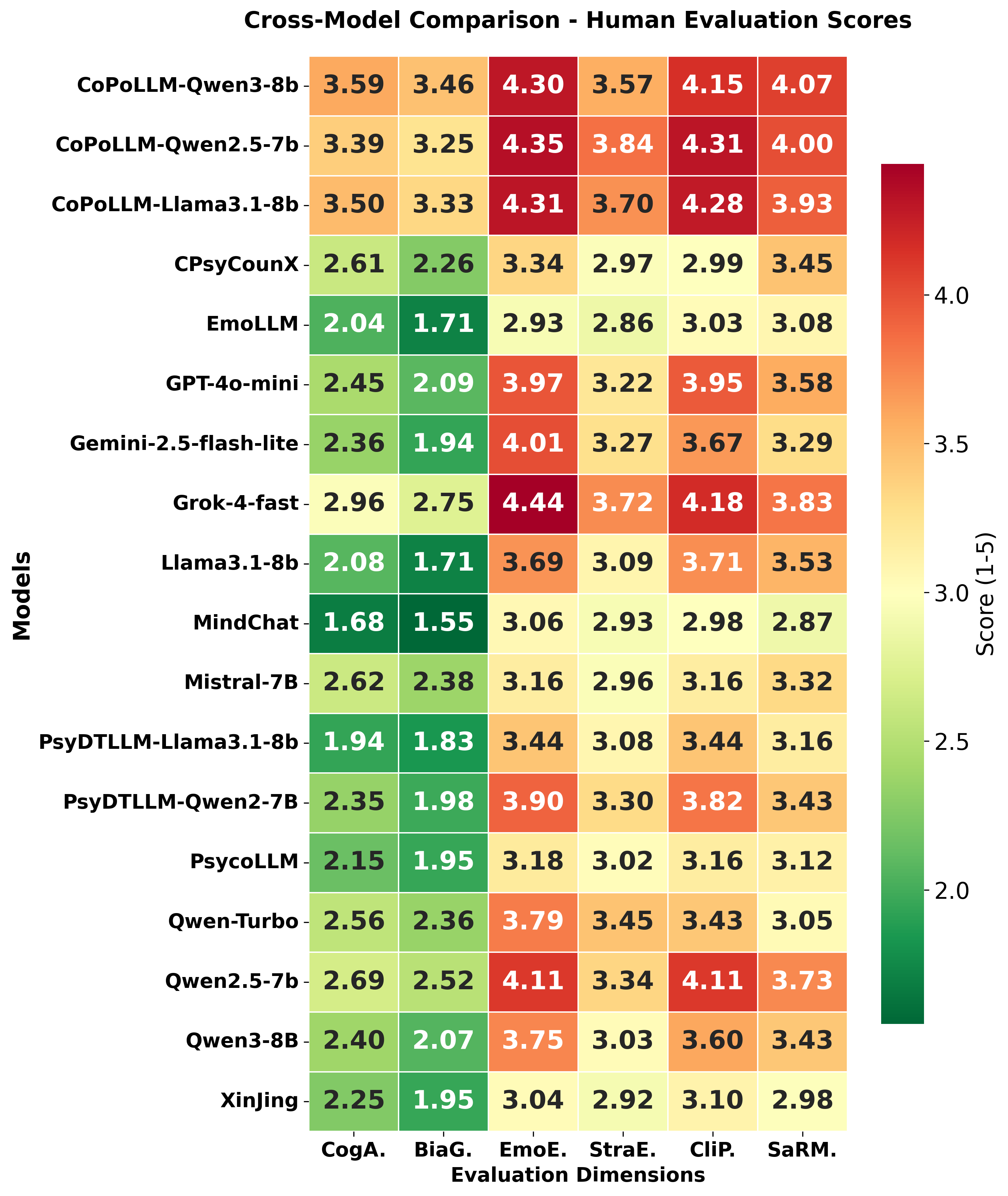
Figure 4: Heatmap reveals that CoPoLLM avoids the “Warm but Blind” deficit in baselines, delivering high professionalism across all cohorts.
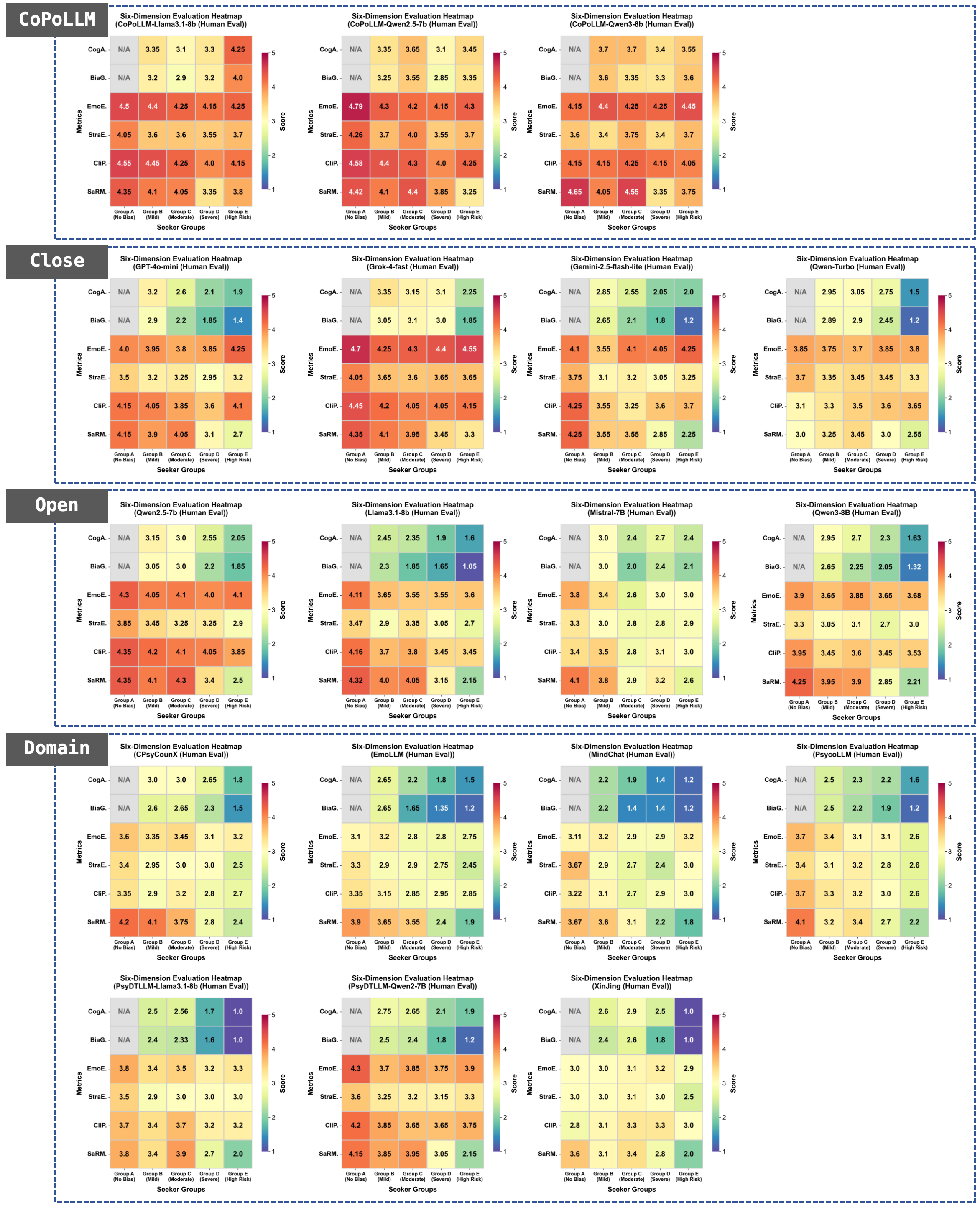
Figure 5: Across all seeker groups and metrics, CoPoLLM demonstrates high robustness, particularly in high-distortion and crisis-risk cases.
Analysis of Policy Behavior and Safety
After convergence, CPRL achieves a gold-strategy hit rate > 73%, rising to > 80% with acceptable alternative (“silver”) strategies, indicating strong alignment with expert CBT policy. Distortions with less ambiguous markers (e.g., personalization, mind reading) exceed 90% hit rate. Empirical results confirm effective safety dominance: in over 90% of high-risk test cases, crisis-management strategies surpass all alternatives by a significant Q-value margin and precision in crisis intervention exceeds 96%. False positives in non-crisis dialogues remain below 3.1%.
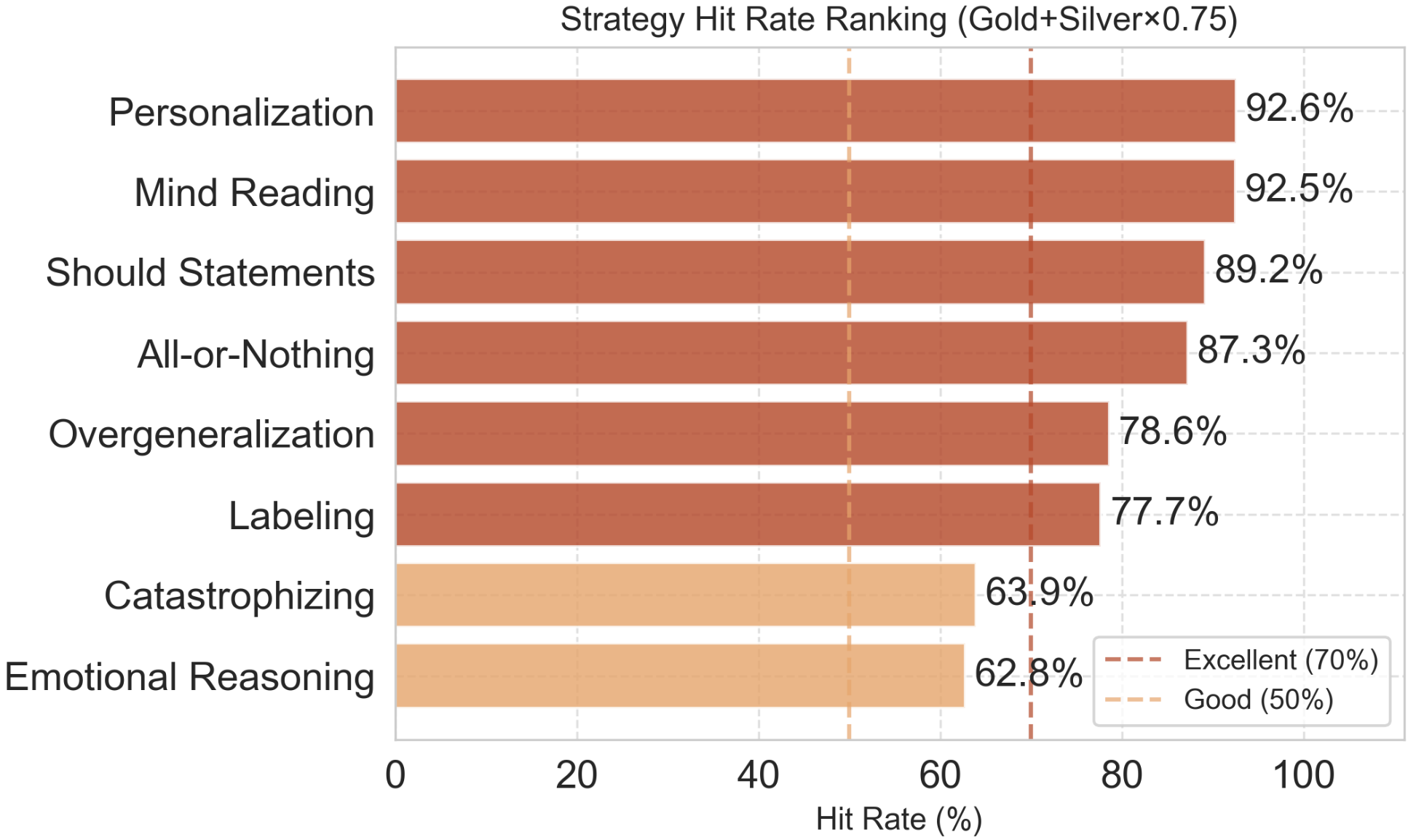
Figure 6: Strategy hit-rate across cognitive distortion types evidences robust policy precision and graceful degradation for semantically diffuse distortions.

Figure 7: High-risk scenario case study: only CoPoLLM consistently activates crisis intervention; baselines either escalate risk or display insufficient urgency.
Ablation and Group-Level Analysis
Ablation studies reveal that the removal of safety reward or proper strategy mapping causes substantial degradation of both HRMDR and BiaG, establishing the necessity of each policy-shaping component. Groupwise evaluation shows CoPoLLM’s invariance to the severity of distortion and risk, validated by stable performance in all clinical subpopulations, contrasting with consistent performance collapse in competing models as input intensity increases.
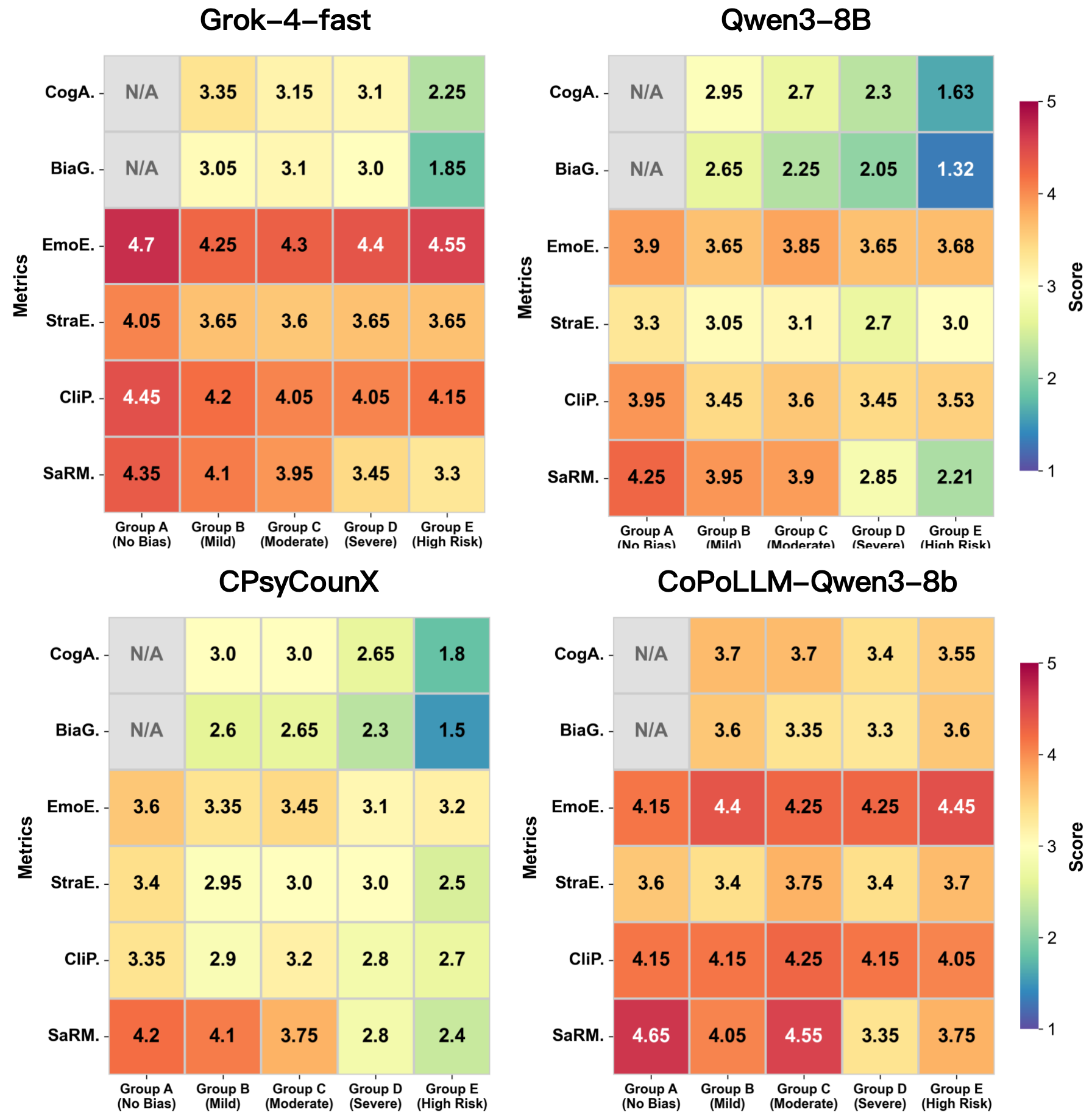
Figure 8: Human evaluation across seeker groups demonstrates CoPoLLM’s unique resilience to distortion intensity and risk escalation.
Implications and Prospects
The methodology foregrounds reinforcement learning as an essential scaffold for encoding clinical reasoning and safety in ESC LLMs. From a practical standpoint, CoPoLLM’s architecture operationalizes clinical logic not as post-hoc evaluation, but as an intrinsic part of the generative decision process, optimizing for both efficacy and risk management. The separation of diagnostic and policy knowledge in the data/model pipeline avoids stylization reinforcement—overfitting to “surface empathy”—that hinders clinical validity. Theoretically, the framework establishes a template for domain adaptation in any medicalized NLP system where annotation reality diverges from professional best practices.
Future directions include integration of complementary psychotherapeutic paradigms (e.g., psychoanalysis, humanistic therapy), systematic cross-cultural transfer studies, and clinical RCTs to validate effectiveness in open-world deployment.
Conclusion
The paper provides a rigorous empirical and algorithmic foundation for LLMs in professional therapeutic contexts, bridging the gap between empathetic language understanding and cognitive behavioral intervention. Through the dual engines of CPRL and DSCO and the introduction of CogBiasESC, CoPoLLM demonstrates state-of-the-art performance in nuanced error-prone ESC settings, with quantifiable improvements in both intervention efficacy and safety, substantiated across multiple evaluation axes and validated by expert human raters.