- The paper introduces BookAgent, an end-to-end multi-agent framework that ensures safety-aware, consistent visual narrative generation.
- It employs specialized agents for value-aligned storyboarding, iterative cross-modal refinement, and temporal cognitive calibration to maintain narrative and visual consistency.
- Empirical results demonstrate superior image-text and character consistency scores compared to baselines, along with robust safety adherence in multi-page story synthesis.
BookAgent: Multi-Agent Cognitive Calibration for Safety-Aware Visual Story Generation
Motivation and Problem Statement
Illustrated storybook synthesis is a multifaceted generative task, requiring tight multimodal coupling between textual narrative and visual rendering while maintaining strong long-horizon consistency and explicit child-safety. Existing approaches either (1) decouple textual and visual streams with stage-wise or autoregressive pipelines, resulting in brittle multimodal alignment and semantic drift, or (2) treat safety as an afterthought, insufficiently integrating child-centric guardrails into the generative process. The "BOOKAGENT" framework (2604.16541) directly addresses these limitations by formulating storybook synthesis as an end-to-end, closed-loop collaboration between specialized agents, each targeting a critical aspect of consistency, verification, and safety.

Figure 1: Comparison between single-pass baseline (top) and BookAgent (bottom) on multi-page story synthesis, highlighting BookAgent's maintenance of character identity, temporal order, and visual consistency.
Architecture: Orchestrated Multi-Agent Workflow
BookAgent adopts a hierarchical, role-specialized architecture built on large multi-modal LLM backbones (Gemini 3.0 and Nano-Banana) to implement collaborative reasoning and generation cycles. The pipeline is decomposed into three core mechanisms:
- Value-Aligned Storyboarding (VAS): Intake and auditing of user draft for explicit safety compliance, script refinement to align with page/character constraints, and extraction of canonical character sheets to serve as identity anchors.
- Iterative Cross-modal Refinement (ICR): Per-page multimodal generation with a generate–verify–revise loop. Image/text consistency (frame-level), identity anchoring, and multimodal safety are orchestrated by specialized agent roles (Frame Director, Identity Director, etc.). Local critiques are aggregated and rolled into prompt updates to ensure progressive error correction at generation time.
- Temporal Cognitive Calibration (TCC): Post-sequence global verification for cross-page consistency in attributes, narrative, and object logic. Selective re-synthesis and repair are triggered for pages violating long-horizon constraints, informed by structured feedback on detected inconsistencies.
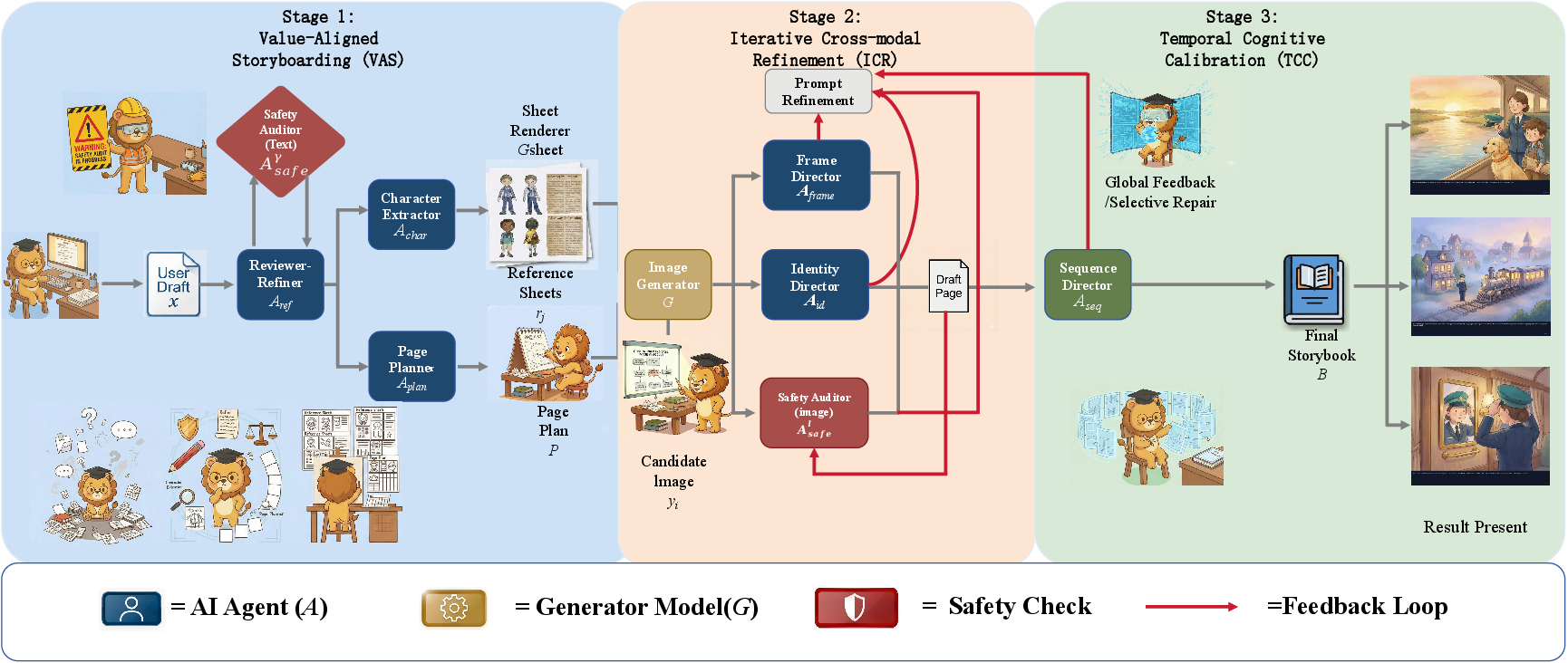
Figure 2: Schematic overview of BookAgent, presenting the closed-loop, multi-agent architecture with VAS, ICR, and TCC mechanisms.
The framework enforces hard safety constraints via dual text and image auditors at each stage and is instantiated to maximize multimodal attribute faithfulness, identity consistency, and sequence coherence under explicit safety requirements.
Empirical Evaluation: Robustness, Consistency, and Safety
Qualitative and Quantitative Benchmarking
BookAgent was benchmarked on a suite of 16 multi-page stories (5–20 pages each) designed with compositional constraints involving spatial, symbolic, and procedural invariants across pages. Comparative baselines include StoryGPT-V, MovieAgent, and StoryGen. The evaluation protocol spans semantic image-text alignment, cross-frame character/object continuity, and strict safety adherence.
Notably, BookAgent achieves significantly higher scores in cross-frame consistency and semantic alignment:
- Image-Text Consistency: 4.6 (BookAgent) vs. 3.1 (StoryGPT-V)
- Character Consistency: 4.7 (BookAgent) vs. 2.4 (StoryGPT-V)
- Safety: 4.8 (BookAgent) vs. 4.5 (StoryGPT-V), outperforming all baselines.
Qualitative analyses (see below) reveal that baselines are susceptible to attribute drift, inconsistent narration, and safety violations, while BookAgent robustly preserves logical bindings, object trajectories, and visual semantics over long horizons.

Figure 3: Visual comparison on character/object consistency in the Milo story, showing appearance drift in baselines and stable identity maintenance by BookAgent.

Figure 4: Handling hard attribute constraints (Rowan); only BookAgent reliably enforces symbolic logic and object counts across all frames.
User Study
A structured user study targeting parents of children aged 4–10 confirms BookAgent's superiority, with preference ratings substantially above competing methods, attributed to improved story coherence and visual engagement.
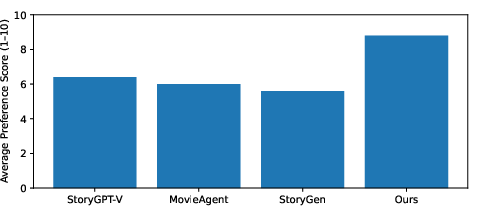
Figure 5: User study results reporting mean preference scores, with BookAgent outperforming alternatives across the board.
Ablation Analysis
Ablation experiments quantify the contributions of VAS, ICR, and TCC:
Long-Horizon Stress Testing
In expert-level tests (see below), BookAgent maintains invariance on complex, interdependent constraints (e.g., attribute bindings, object locations, ticket counts), successfully detecting and correcting intentional rule violations throughout extended illustrated narratives.

Figure 7: Consecutive panels from the long narrative stress test, illustrating BookAgent's strict maintenance and repair of rule-based invariants across dense narrative progression.
Structured Feedback and Interactive Deployment
The core generate-verify-correct loop is operationalized via real-time structured feedback. The system iteratively diagnoses and annotates fine-grained errors, including attribute drift, semantic mismatch, and prop continuity violations, activating targeted repair routines where necessary.
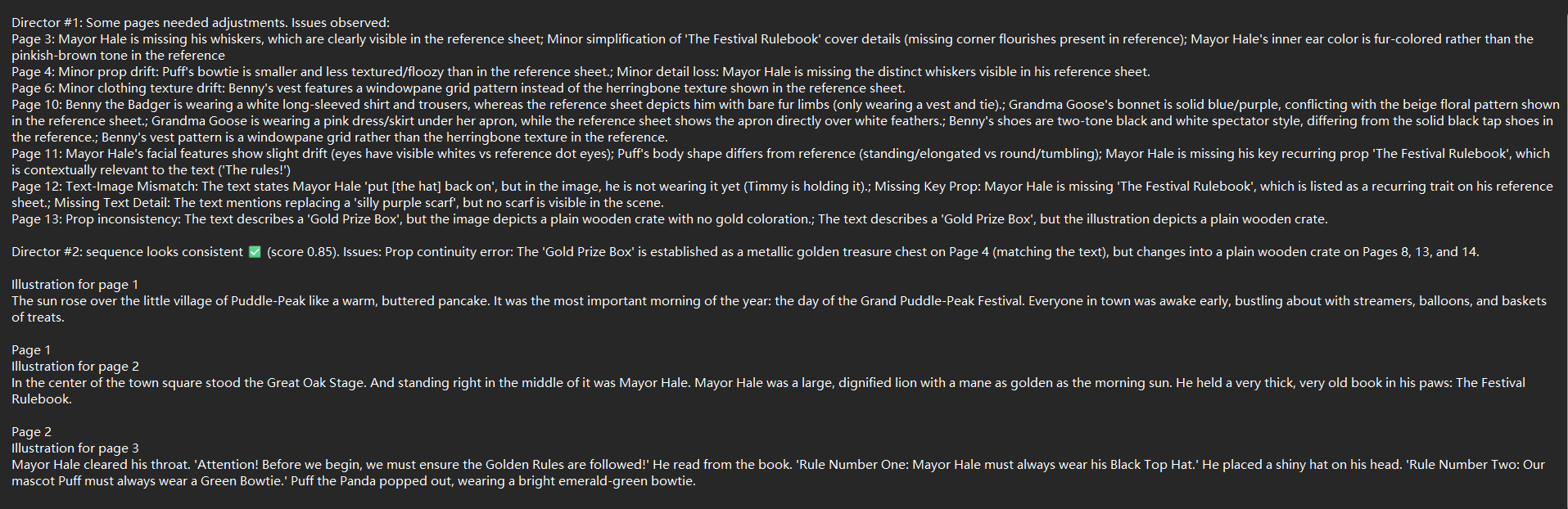
Figure 8: Sampling of structured feedback highlighting cross-page inconsistencies not locally detectable at generation time.
A production-quality web interface exposes interactive story definition, style controls, and fine-grained generation configuration, supporting variable-length stories and advanced multimodal parameterization.
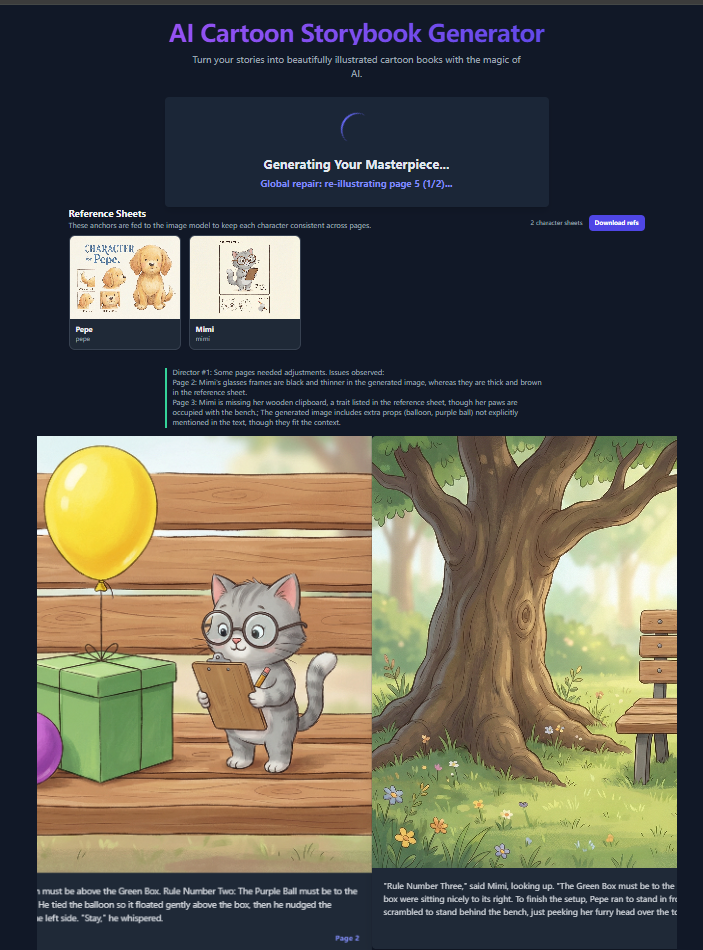
Figure 9: Left: Iterative global repair during generation, with reference-guided consistency enforcement. Right: User interface for parameterized control over the synthesis process.
Limitations and Implications
BookAgent marks a significant advancement in pushing agent-based multimodal generation toward robust, safety-aware, long-horizon storytelling. However, several challenges persist:
- Model Dependency: Overall performance is fundamentally bounded by the underlying multimodal foundation models. Low-level failures and rare misunderstandings still arise.
- Scalability: Maintaining consistent identity for a large and dynamic cast of entities presents memory and reasoning bottlenecks, especially as the number of tracked objects increases with story length.
- Efficiency: The iterative validation and repair paradigm increases inference overhead compared to feed-forward pipelines; thus, online or interactive deployments for very long stories are computationally expensive.
Practically, BookAgent provides a strong reference paradigm for safe, reliable storybook generation suitable for sensitive domains such as child education and entertainment. Theoretically, its approach to co-optimization and closed-loop cognitive calibration can lay the foundation for robust agentic control in broader multimodal AI applications—extensible to procedural animation, interactive fiction, or educational content generation.
Conclusion
BookAgent demonstrates that orchestrated multi-agent collaboration, with explicit cognitive calibration for safety and consistency, is effective for synthesizing coherent, safe visual narratives under complex constraints. The integration of planning, iterative multimodal refinement, and temporal global auditing critically improves long-horizon compositionality and safety compared to prior methods. Future directions include scalable multi-entity consistency, adaptive verification under computational constraints, and the extension of cognitive calibration paradigms to other domains of reliable, explainable multi-agent AI.
