- The paper introduces a CBC-SLP architecture that decomposes features into shared and modality-specific subspaces using structured latent projection.
- It employs dedicated modality encoders with gated masking to handle missing data, achieving superior performance on multiple remote sensing benchmarks.
- The approach offers a unified, plug-and-play segmentation solution that enhances robustness and accuracy across diverse, heterogeneous datasets.
Robust Multispectral Semantic Segmentation via Structured Latent Projection: An Expert Analysis
Introduction and Motivation
Robust semantic segmentation of remote sensing imagery under conditions of missing or fully available multispectral modalities remains a critical challenge in multimodal learning. The paper "Robust Multispectral Semantic Segmentation under Missing or Full Modalities via Structured Latent Projection" (2604.15856) systematically addresses this challenge by questioning the optimality of prevailing modality alignment strategies that focus on learning only shared feature representations. The proposed CBC-SLP framework introduces a structured latent projection mechanism that explicitly decomposes features into modality-invariant (shared) and modality-specific (private) subspaces and adaptively routes these according to input modality availability during decoding. This enables robust, high-fidelity land-cover segmentation when some modalities are missing, without degrading performance in the full-modality case.
Methodological Framework: CBC-SLP Architecture
The CBC-SLP model uses a dedicated encoder per modality, based on inflated 3D ResNet50 networks, to handle the heterogeneous spatial and spectral properties of input data. Each encoder is gated with a modality-availability mask throughout all layers, thereby enforcing architectural awareness of absent inputs. Cross-modal fusion is performed at multiple levels by concatenating gated modality features and projecting them through 1×1×1 convolutions.
Following the encoder stack, feature tokens are extracted and processed with intra-modal Transformers employing multi-head self-attention to learn deep feature representations that are resilient to input variance. The outputs then flow through an inter-modal correlation block, which enriches per-modality features with weighted, pixel-wise cross-modal information via attention-based aggregation.
Crucially, the structured latent projection module factorizes these fused deep representations into shared and modality-specific latents. The shared latent is always used for decoding, while private components are masked out if their corresponding input modality is missing, preventing introduction of spurious or hallucinated features from unobserved modalities.
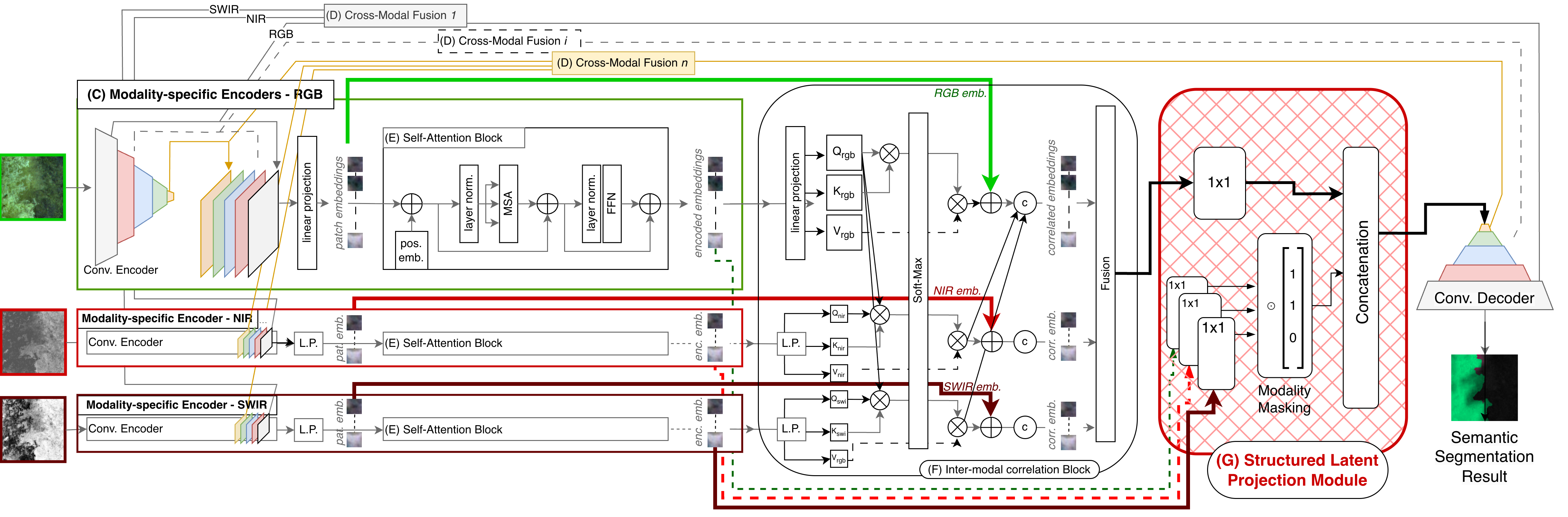
Figure 1: The CBC-SLP model features a structured latent projection that maintains both modality-invariant and modality-specific representation streams, ensuring resilience to modality dropout.
Decoding proceeds by aggregating these structured latents with skip connections from early encoder stages, enabling fine spatial detail reconstruction and precise boundary delineation.
Datasets and Experimental Protocol
CBC-SLP is validated on three challenging benchmarks representative of real-world multimodal remote sensing conditions:
- DSTL: 25 satellite images with RGB, NIR, and SWIR bands, focusing on agricultural land-cover segmentation.
- Potsdam: Aerial dataset with RGB, IRRG (NIR-R-G), and DSM, targeting tree class segmentation.
- Hunan: Sentinel-1/2 and DEM fusion, designed to capture forest class regions with disparate spatial resolutions.
In all experiments, a random modality dropout mechanism is used during training, and stratified train/val/test splits are maintained. Metrics of interest include per-class IoU and F1 scores, providing robust coverage of both overlap and error trade-offs across synthetic and real missing-modality regimes.
Empirical Results and Comparative Evaluation
Extensive comparison with state-of-the-art methods including M3L, MMANet, and CMX demonstrates that CBC-SLP achieves superior or competitive results across all tested scenarios. Notably, it consistently avoids the negative performance trade-off observed in methods that optimize for either missing modality robustness or full modality accuracy but not both.
In ablation studies, CBC-SLP is shown to outperform route-based baselines under random modality dropout, with notable improvements on IoU (e.g., up to +1.8% on DSTL and +3.8% on Hunan full-modality settings). Table-based analyses also reveal limited marginal benefit from training one specialized model per modality configuration. Instead, a single unified CBC-SLP model offers both computational efficiency and resilience to arbitrary sensor dropouts.
Qualitative visualizations further support these claims:

Figure 2: CBC-SLP (e) yields less noisy segmentation masks and improved class boundary adherence compared to other methods on DSTL under both full and missing modality settings.

Figure 3: On Potsdam, the CBC-SLP model maintains superior accuracy in tree delineation, especially when only DSM is available or IRRG is excluded.
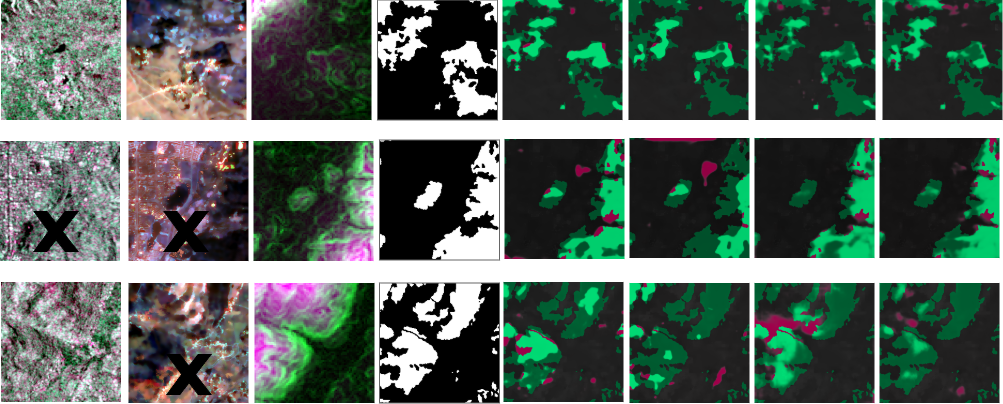
Figure 4: On Hunan, the model preserves fine-grained forest structures and avoids spurious labeling, even when input approaches a unimodal (DEM-only) configuration.
Information gap analysis, using conditional entropy proxies on decoder features, quantitatively demonstrates that structured latent projection delivers more informative, lower-uncertainty decoding features—especially in heterogeneous modalities—than models projecting solely into shared latent spaces.
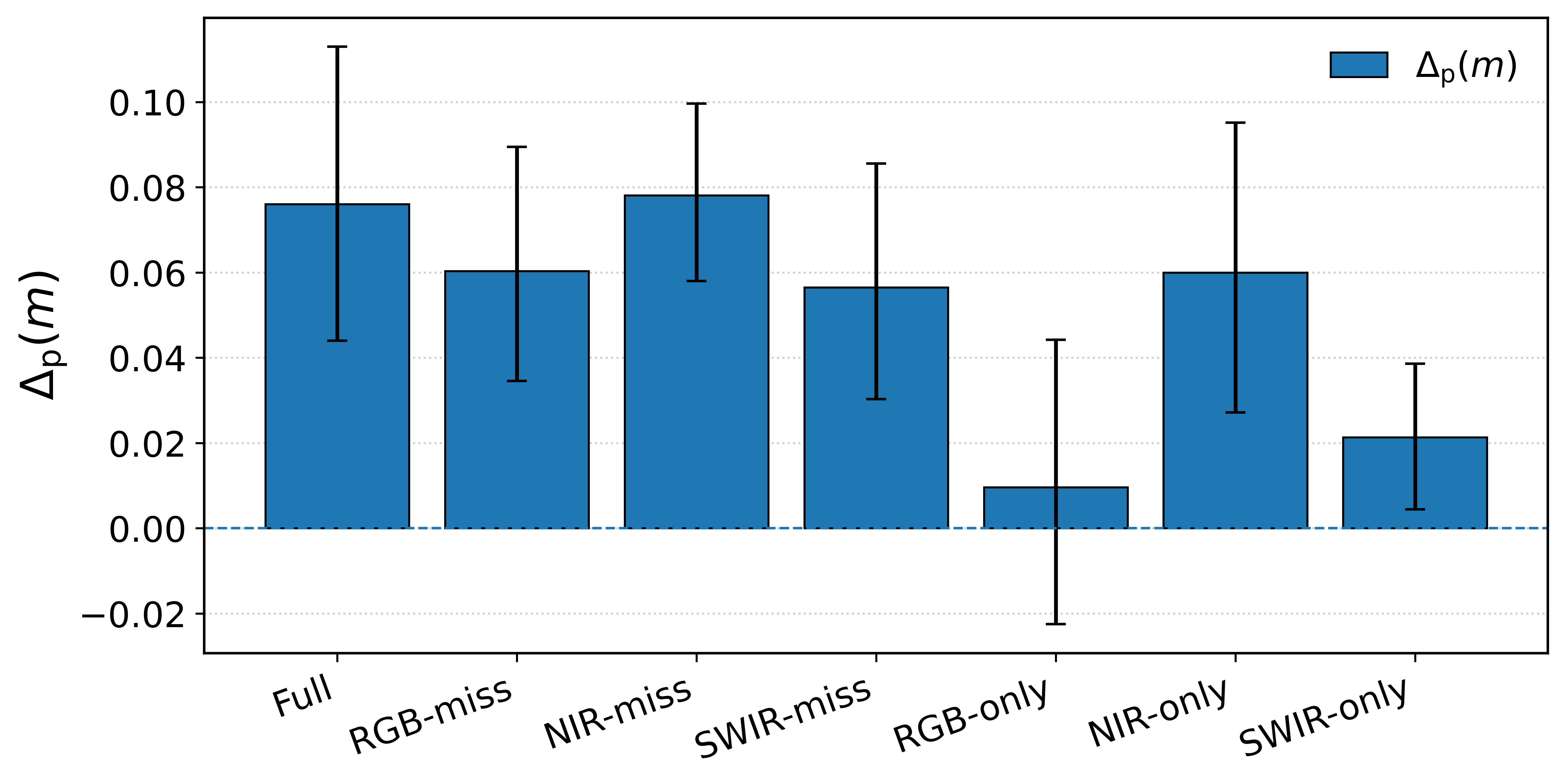
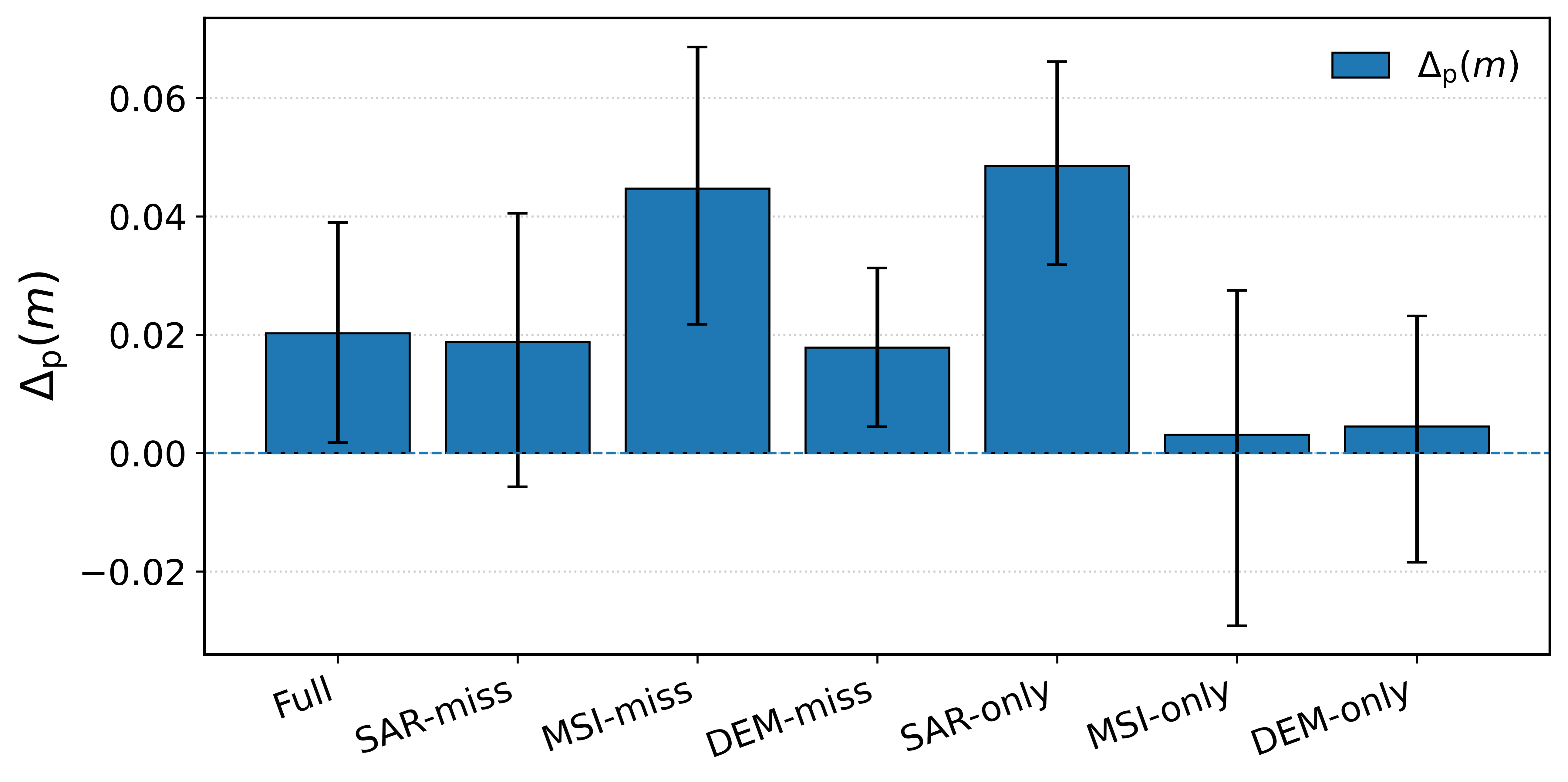
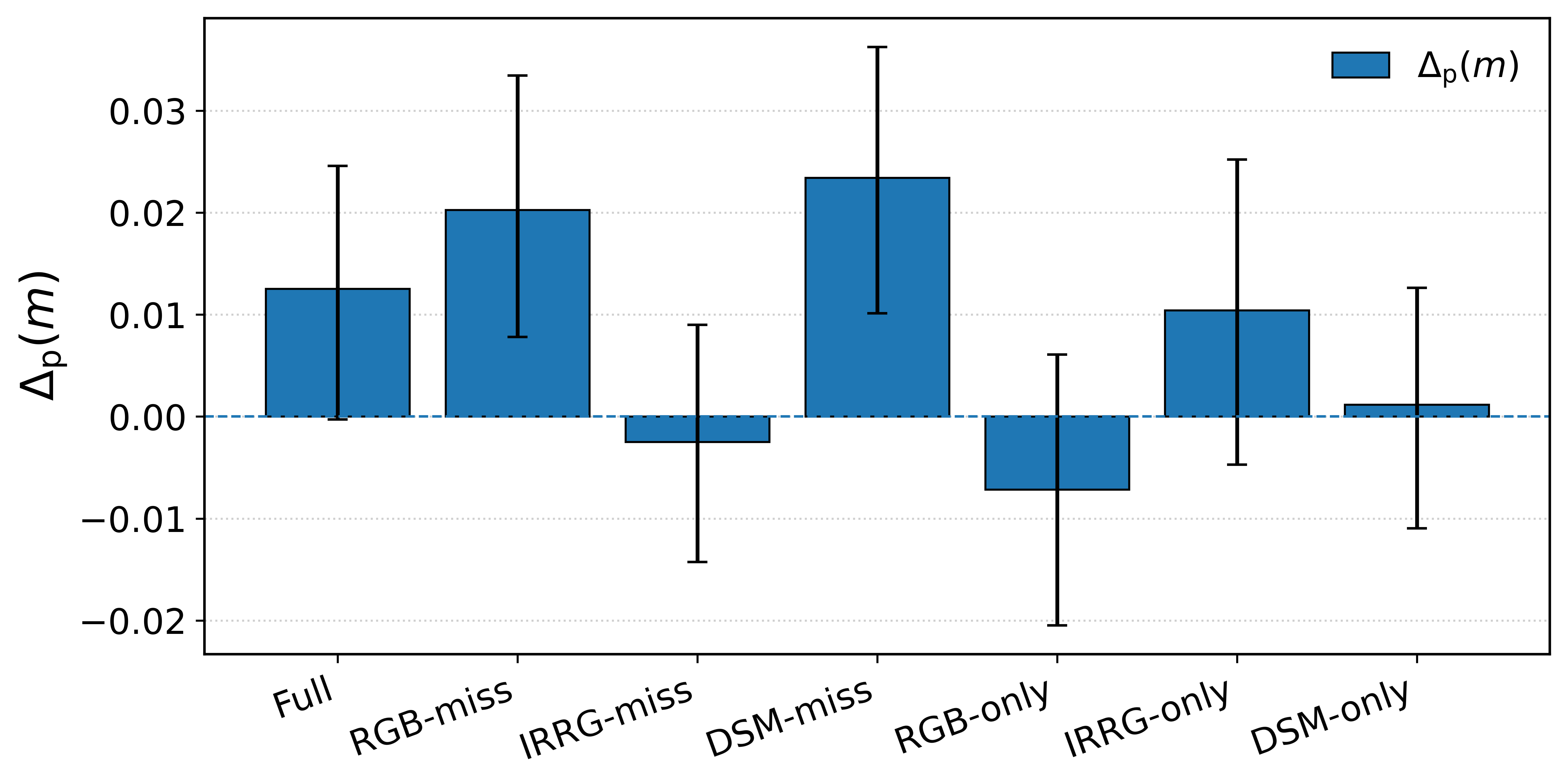
Figure 5: Information gap analysis across DSTL, Hunan, and Potsdam demonstrates that structured latent projection systematically reduces decoder uncertainty versus shared-only baselines, especially when missing modalities are highly informative.
Theoretical Implications
Using the theoretical framework from [Jiang et al., CVPR 2023], the paper shows that perfect modality alignment—where all latent features are forced into a unified space—provably leads to a lower mutual information bound relative to the original inputs by at least the difference between the most and least informative modalities, Δp. Thus, the strict alignment approach prevalent in prior works is fundamentally suboptimal for maximally exploiting the complementarity inherent in remote sensing data. The CBC-SLP design, via explicit architectural bias, provides a constructively sound alternative evidenced both by theory and practice.
Practical Impact and Future Directions
The CBC-SLP approach has direct implications for operational satellite and aerial monitoring platforms where sensor failures, atmospheric opacity (e.g., clouds in MODIS/Landsat), or acquisition gaps frequently result in irregular modality availability. Rather than necessitating costly retraining for every sensor combination or accepting degraded segmentation performance, CBC-SLP offers a plug-and-play architecture for uniformly robust segmentation. From a deployment perspective, the architectural simplicity (modality-specific gating, no auxiliary loss terms) facilitates integration with resource-constrained systems.
Further, the information gap analysis methodology introduced provides a general tool for feature-level audit of multimodal models well beyond remote sensing, applicable to any domain where modality-invariant and -specific information content must be understood.
Conclusion
This work establishes that structured latent projections—decomposing features into shared and private streams and adaptively factoring these according to observed input—yield a principled, practical, and empirically validated solution for robust multispectral semantic segmentation under arbitrary modality availability. As remote sensing platforms trend toward increasing multi-sensor diversity and as mission requirements emphasize operational continuity, such architectures are likely to become foundational. Future research should extend these mechanisms to wider modality sets (including text/metadata) and more complex spatiotemporal segmentation regimes, further exploiting the latent structures elucidated herein.