- The paper introduces a novel MatRIS-MoE architecture combined with the Janus framework, dramatically accelerating billion-parameter uMLIP training.
- It employs a sparse, element-aware MoE routing strategy with second-order optimization and FS-3D parallelism to enhance performance and efficiency.
- Results demonstrate quantum-accurate predictions across diverse simulation domains, achieving >90% parallel efficiency and near-linear weak scaling at Exascale.
Breaking the Training Barrier of Billion-Parameter Universal Machine Learning Interatomic Potentials
Introduction
Universal Machine Learning Interatomic Potentials (uMLIPs) are increasingly central in quantum-accurate molecular simulations, offering transferable surrogate models in lieu of expensive quantum mechanical calculations. The unprecedented scaling of uMLIPs, from millions to over a billion parameters, promises robust applicability across heterogeneous domains (organic molecules, inorganic materials, catalytic interfaces, etc.), but also poses a formidable challenge: efficient, accurate, and scalable training given the prohibitive computational and communication costs instigated by second-order optimizations, single-precision requirements, and extreme throughput demands.
This paper presents MatRIS-MoE, a billion-parameter Mixture-of-Experts (MoE) uMLIP based on the invariant MatRIS framework, alongside Janus, a highly-optimized, hardware-aware parallel framework enabling efficient second-order training at Exascale. The system achieves 1.2 EFLOPS peak performance at >90% parallel efficiency, compressing billion-parameter uMLIP training times from weeks to hours and defining a new operational regime for foundation models in scientific simulation.
Technical Advances in MatRIS-MoE Architecture
To address the limitations inherent in existing uMLIPs, the authors scale the invariant MatRIS architecture—originally optimized for Pareto-efficiency in 10M-parameter models—to the billion-parameter regime through several architectural and algorithmic innovations.
MatRIS-MoE represents atomic configurations as graphs under periodic boundary conditions, leveraging a pipeline of feature embedding, invariant message passing, and readout blocks. Within the interaction blocks, a transition is made from O(N) separable attention to compute-intensive multi-head self-attention, improving GPU utilization while enhancing many-body expressiveness. Critically, the architecture introduces a sparse, element-aware MoE routing strategy, with routing determined by chemical identity and task context, permitting both specialization across chemical domains and compute/memory efficiency.
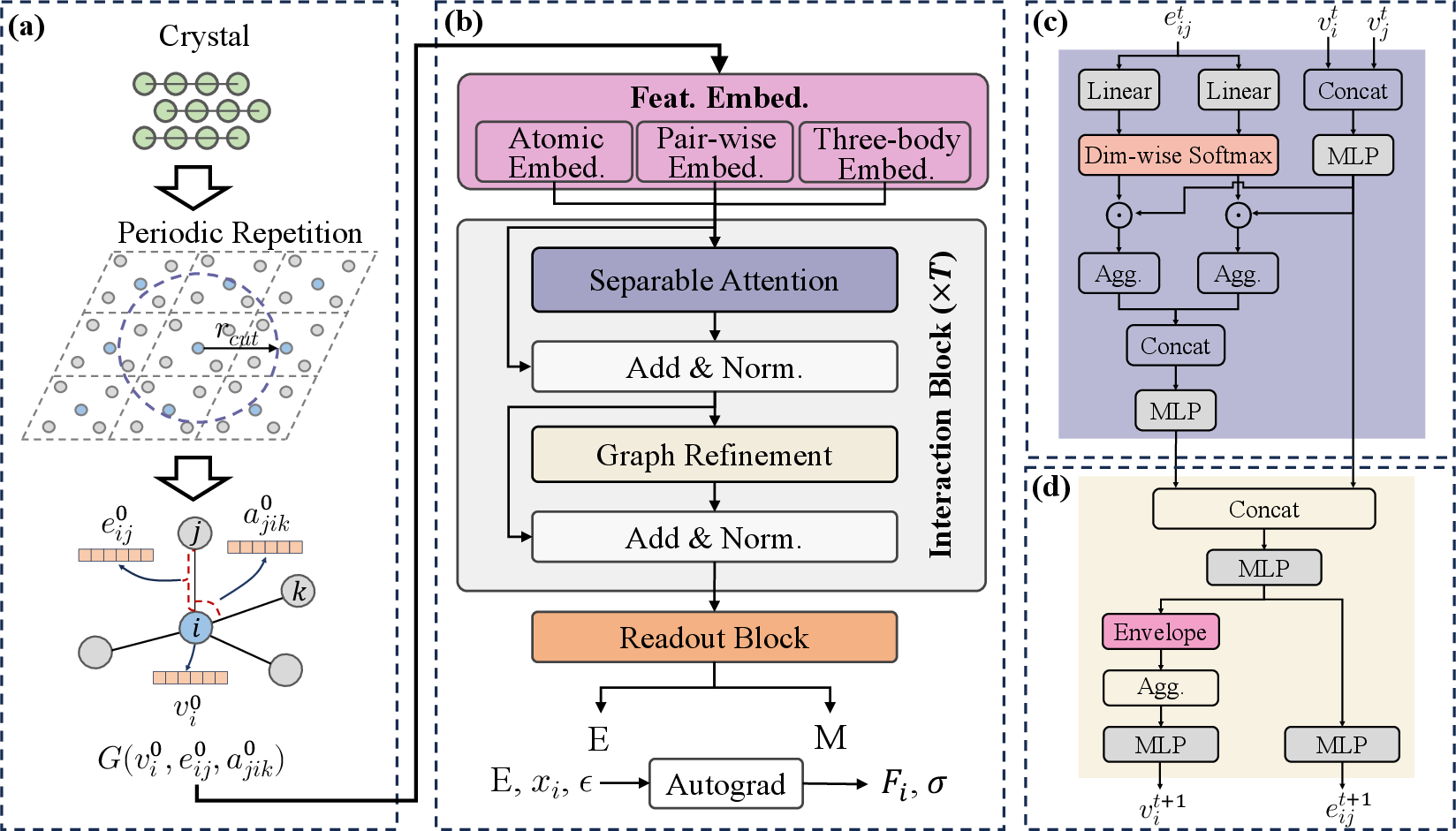
Figure 1: Architecture overview of MatRIS and core components: periodic graph construction, invariant message passing, separable attention, and refinement.
Task alignment in multi-domain datasets is enabled through per-task/dataset embeddings, charge and spin encodings, and global feature vectors, all supporting robust cross-domain performance. For robust optimization, a multi-task, robust loss is employed, leveraging batch-wise normalized per-task outlier mitigation to stabilize training across highly heterogeneous samples.
Scalable Training with the Janus Framework
The central technical contribution is the development of Janus, a hybrid-parallel training framework uniquely capable of supporting double-backward (second-order) uMLIP optimization at scale—in contrast to previous works focused on first-order LLM training.
Janus implements FS-3D (Fully Sharded 3 Dimensions), integrating:
- FSDP (fully sharded data parallelism): Reduces static memory usage.
- FSGP (fully sharded graph parallelism): Splits atomic graphs across devices.
- FSEP (fully sharded expert parallelism): Distributes MoE expert parameters, exploiting just-in-time expert routing/planning for load balancing and communication reduction.
This enables sharded execution, memory savings, expert sparsification, and guarantees balanced resource utilization. Crucially, Janus supports a double-backward-aware lifecycle with multi-phase, pipelined computation and deferred gradient synchronization, maximizing overlap and minimizing idle time in Exascale settings.
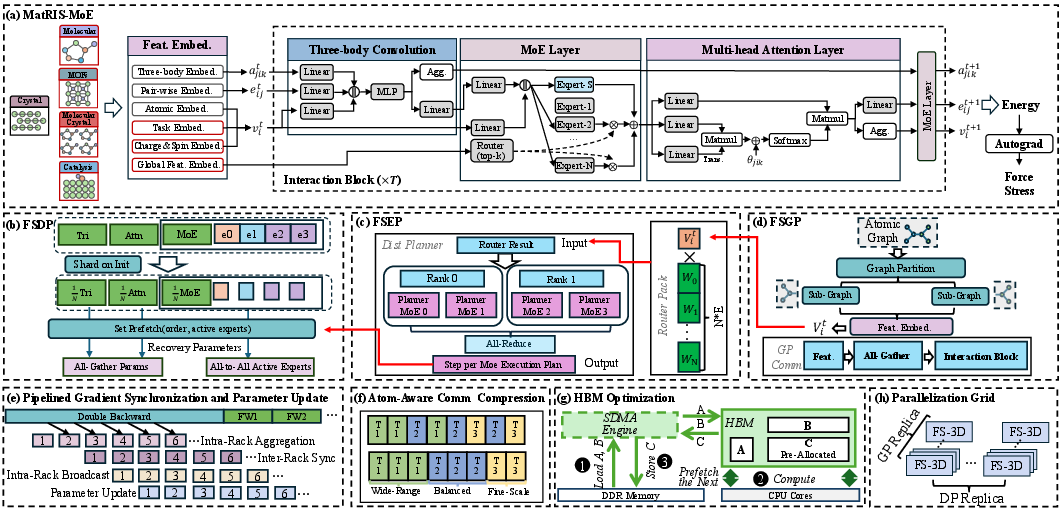
Figure 2: System overview: model architecture, framework-level (FSDP, FSEP, FSGP) and platform-level optimizations, and FS-3D parallelization.
The system provides hardware-specific optimizations: pipelined gradient synchronization, atom-type-aware FP16 communication compression for MoE routing (compensating for bandwidth constraints), and tailored kernel engineering for graph and MoE operators. On ARM-based platforms (LineShine), further optimizations in memory movement (SDMA engines), and async MPI scheduling leverage hardware characteristics for maximal throughput.
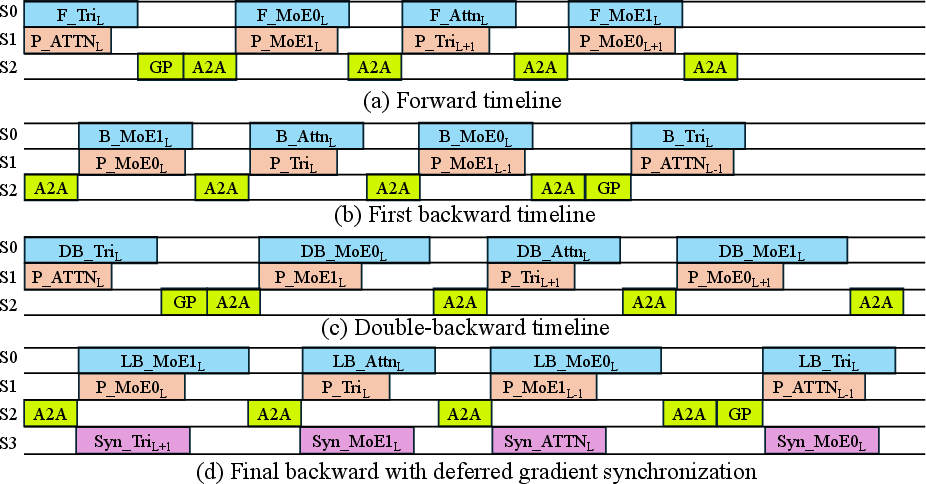
Figure 3: MatRIS-MoE execution timeline; block-level breakdown of operator computation, prefetching, communication, and gradient synchronization.
Model Configurations and Scaling
Three MatRIS-MoE variants—Small (S, 1.09B total params), Medium (M, 2.47B), and Large (L, 11.5B)—were benchmarked on multi-domain datasets comprising 473M atomic configurations (3.6T edges). All variants share a six-layer interaction block backbone with sparse MoE, multi-head attention, and task-aware embeddings.
Convergence studies demonstrate that, with appropriate learning rate scaling, batch sizes up to 15K can be stably accommodated, with negligible accuracy loss.
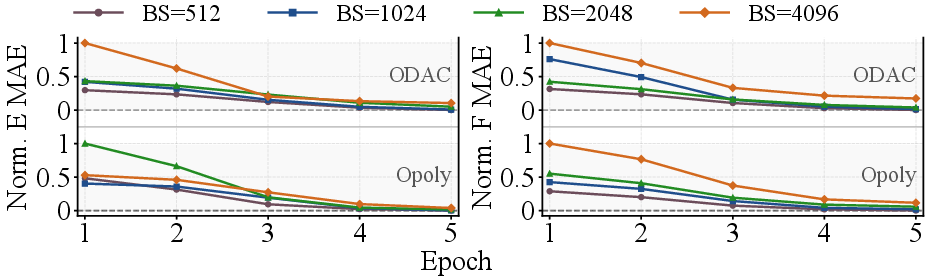
Figure 4: Convergence behavior under varying batch sizes; robust optimization at scale.
Accuracy
Despite the complexity of the tasks (molecules, crystals, catalysis, MOFs), the 1B-parameter MatRIS-MoE achieves SOTA or near-SOTA across domains, delivering robust out-of-the-box accuracy without domain-specific retraining. Notably, the model maintains quantum-accurate prediction fidelity (energies, forces, magnetic moments) required for long-timescale and thermodynamically consistent MD simulations.
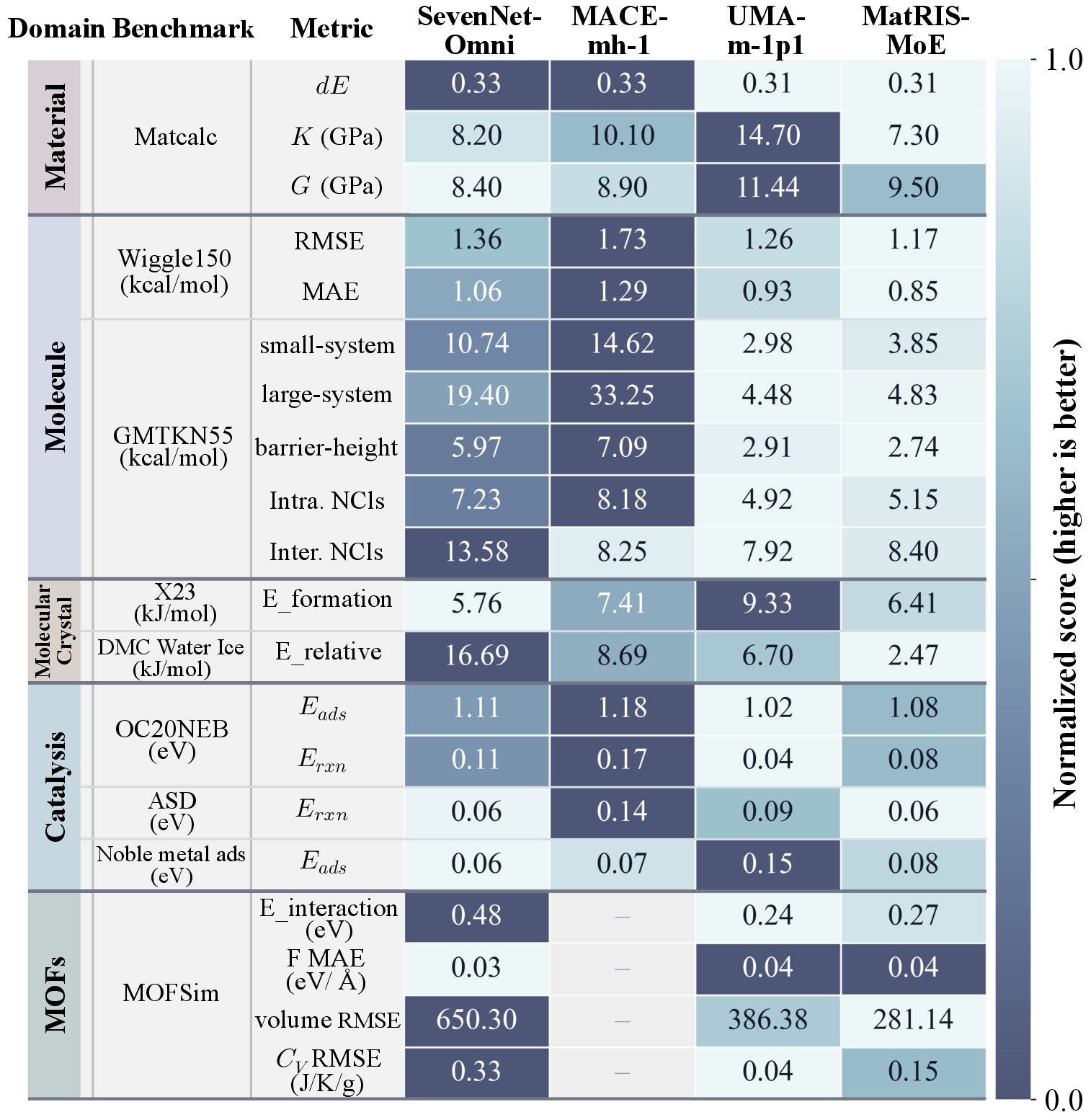
Figure 5: Out-of-box cross-domain accuracy of MatRIS-MoE on diverse benchmarks; lighter color denotes higher accuracy.
Strong and Weak Scaling
Strong scaling experiments demonstrate that both MatRIS-MoE (M) and (L) maintain >50% parallel efficiency up to Exascale full-machine scale, with throughput scaling nearly linearly in weak scaling tests (1.2 EFLOPS on LineShine, 1.05 EFLOPS on CNIS, >90% parallel efficiency).
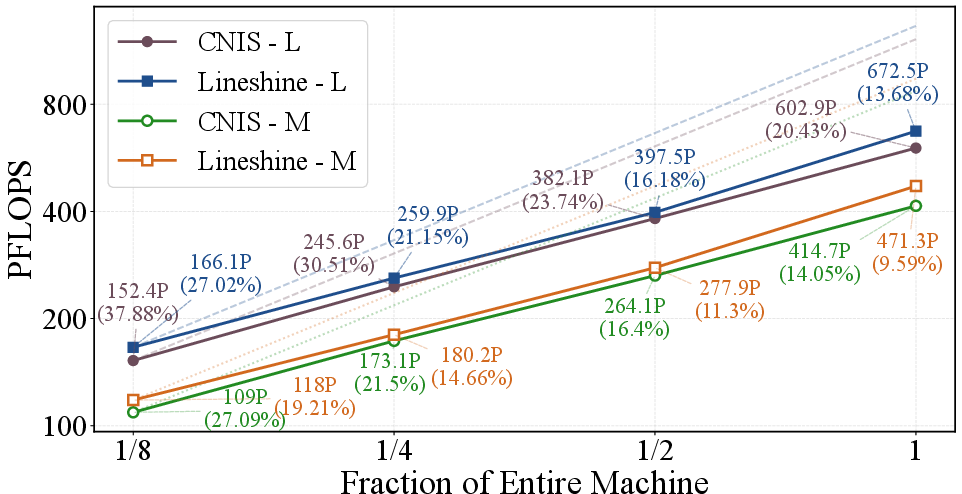
Figure 6: Strong scaling—relative parallel efficiency and PFLOPS throughput at fixed problem size as machine scale increases.
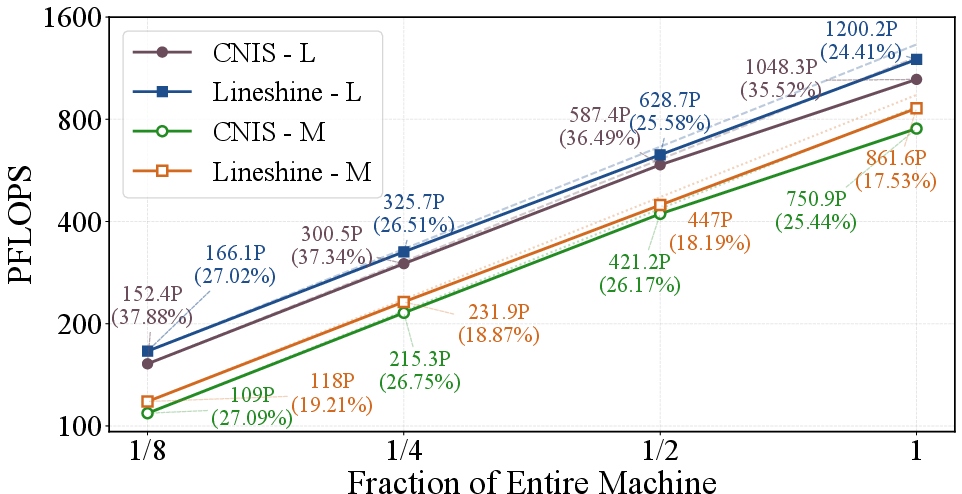
Figure 7: Weak scaling—throughput improvement as both problem size and resources scale proportionally; near-linear performance up to 1.2 EFLOPS.
With system-level and hardware-specialized optimizations, per-step training time is reduced by 2.7–5×, and sustained performance, accounting for I/O and initialization, reaches 762 PFLOPS (CNIS) and 1.03 EFLOPS (LineShine).
Scientific and Practical Implications
The MatRIS-MoE model, enabled by Janus, provides a transformative simulation engine for a broad spectrum of high-value tasks:
- Accurate polymorph ranking and structural relaxation with quantum-level agreement.
- High-fidelity molecular dynamics (e.g., MOFs), sustaining structural integrity and preserving thermodynamic properties over long trajectories.
- Direct catalytic energy profile prediction along reaction coordinates.
- Robust generalization and speedup (orders of magnitude over DFT) for practical screening and discovery.
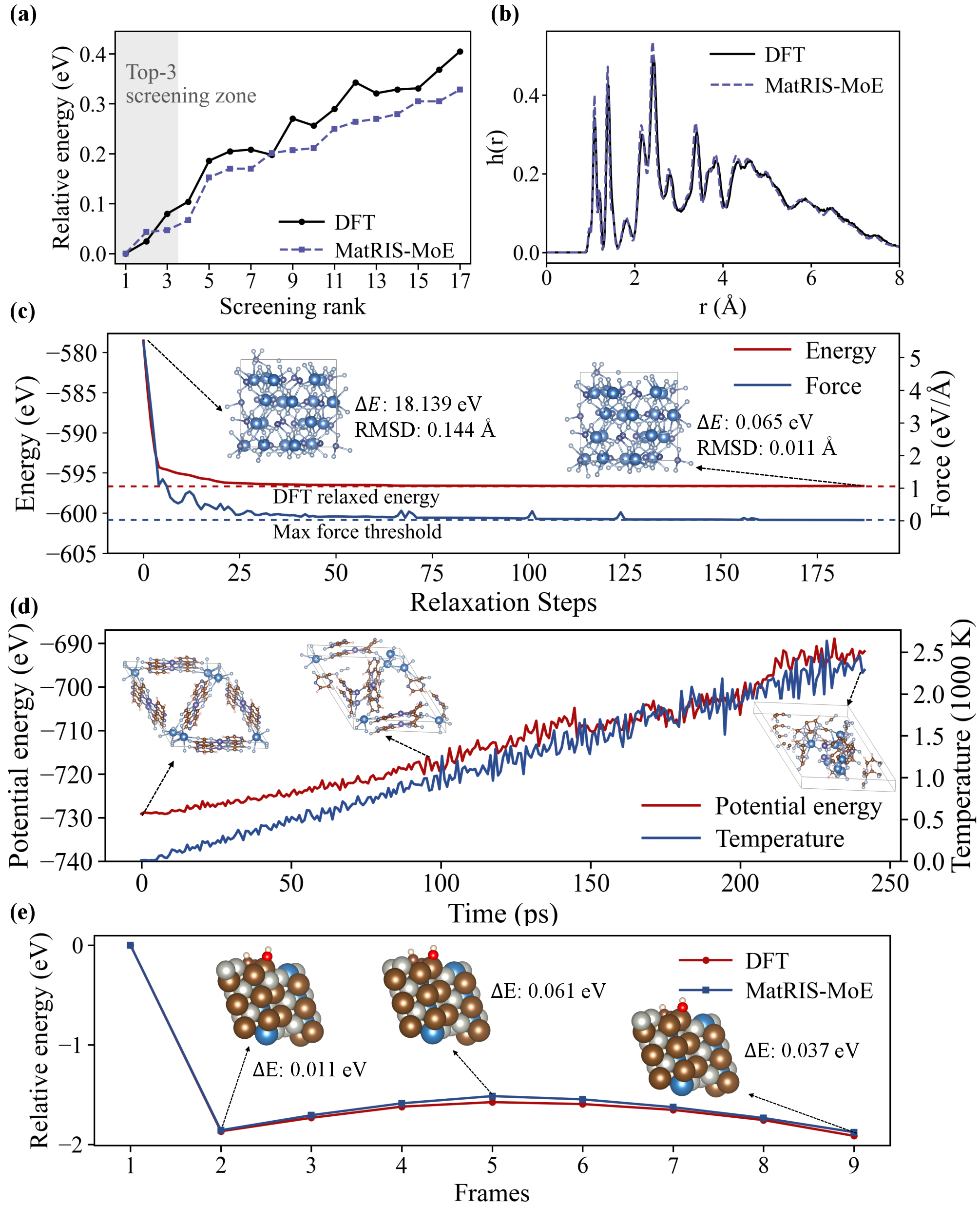
Figure 8: Applicability: (a) energy ranking, (b) molecular distribution functions, (c) relaxation, (d) molecular dynamics, (e) catalytic reaction profiles.
On the systems side, the work defines billion-parameter uMLIP training as a flagship AI-for-Science Exascale workload, highlighting the necessity—and limitations—of current HPC co-design. The roadmap for further scaling points to the continued need for algorithm–framework–system co-design: improved hardware utilization, memory compression for second-order graphs, and communication reduction. These elements will be critical as universal atomic foundation models expand beyond 10B parameters and underpin AI-driven discovery pipelines in clean energy, advanced materials, and pharmaceuticals.
Conclusion
The development of MatRIS-MoE and the Janus framework marks a significant departure from LLM-inspired architectures and frameworks ill-suited for second-order, high-fidelity scientific MLIPs. The demonstrated billion-parameter, multi-domain uMLIP efficiency and accuracy at Exascale redefine feasible model complexity, training acceleration, and cross-domain generalization for atomistic simulation. Future research will likely see scaling to even larger models, deeper integration with traditional simulation pipelines, and increasingly sophisticated hybrid HPC/AI programming frameworks to maximize efficiency, scientific impact, and accessibility.