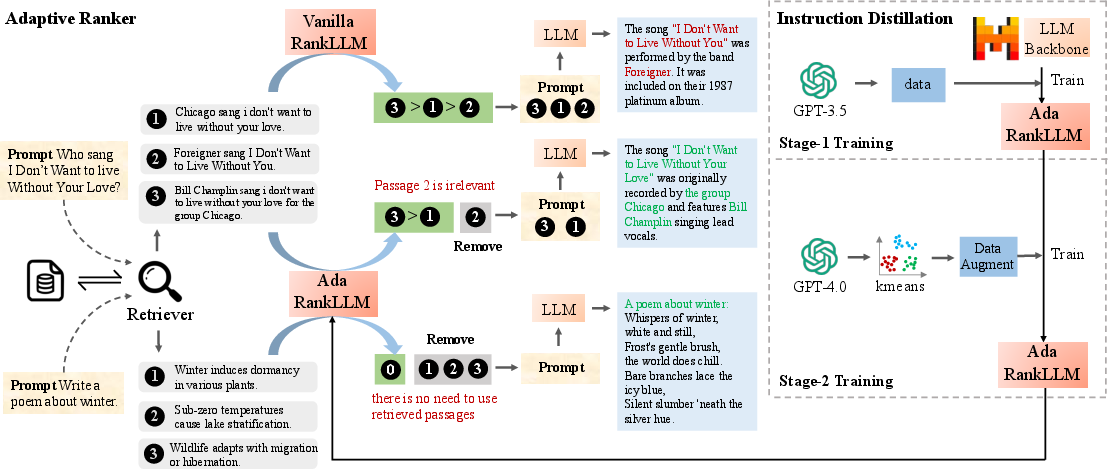
- The paper introduces AdaRankLLM, a novel adaptive retrieval framework using listwise ranking and passage dropout to filter irrelevant context.
- It employs a progressive two-stage distillation process, transferring robust evidence filtering skills from advanced LLMs to cost-effective open-source models.
- Experimental results demonstrate that adaptive retrieval enhances noise suppression for weaker models and improves computational efficiency for stronger LLMs.
Reassessing Adaptive Retrieval-Augmented Generation via Listwise Ranking: AdaRankLLM
Retrieval-Augmented Generation (RAG) is central to knowledge-intensive applications powered by LLMs, allowing generated responses to be grounded in externally retrieved evidence. Traditional RAG strategies utilize fixed-depth retrieval, fetching a set number of passages for each query, but recent empirical evidence indicates suboptimality due to noisy or insufficient context. Adaptive retrieval—dynamically deciding if and how much to retrieve per query—has gained traction as a noise mitigation approach. However, as LLMs exhibit increasing resilience to irrelevant retrievals, the enduring necessity and the optimal operational role of adaptive retrieval require critical reevaluation.
AdaRankLLM is introduced to systematically examine this question through the lens of adaptive listwise ranking, seeking to disentangle retrieval necessity and probe the evolving utilization of adaptive mechanisms across LLM scale and capability.
Methodology: Adaptive Ranker and Distillation Paradigm
AdaRankLLM operationalizes adaptive retrieval with two core design components:
This methodology yields a system that, at inference time, autonomously determines if retrieval is needed and dynamically selects a relevant passage subset tailored to the query.
Experimental Validation and Quantitative Results
AdaRankLLM is evaluated on three knowledge-intensive QA datasets (ASQA, QAMPARI, ELI5) and eight LLM backbones, covering both open-source and advanced proprietary architectures. Performance is measured in terms of EM (ASQA), F1 (QAMPARI), Claim Recall (ELI5), along with averaged overall scores.
Key quantitative findings:
- On weaker backbones (Alpaca-7B, Mistral-7B), fixed-depth retrieval (k=10) leads to sharp performance drops—noise sensitivity is pronounced. AdaRankLLM consistently matches or exceeds the best static configuration, demonstrating a critical noise filtration effect.
- On stronger models (e.g., Qwen3-8B, GPT-4o), AdaRankLLM achieves parity with maximum-recall settings using a much more compact context, evidencing its efficiency-optimization capability, not a necessity for robust generation.
- Distillation yields student models (e.g., Mistral-AdaRankLLM) that closely approximate teacher (GPT-4 AdaRank) performance, establishing the viability of listwise adaptive skills transfer to resource-limited backbones.
Notably, the paper claims:
- Adaptive retrieval is indispensable as a noise filter for weaker models but is primarily an efficiency tool once LLMs reach a sufficient level of noise robustness and internal verification.
- Fixed-depth strategies are universally suboptimal due to high variance in optimal retrieval depth across tasks, models, and datasets.
- Even with adaptive mechanisms and superior LLMs, a significant gap to the theoretical oracle remains, highlighting lingering limitations in retrieval-integration protocols.
Analysis and Theoretical Implications
The experiments partition the utility of adaptive retrieval along a capability axis:
- For low-capacity LLMs: Adaptive ranking is mission-critical. These architectures lack the internal attention granularity to suppress distracting context; thus, extrinsic adaptive filtering governs downstream generation quality.
- For advanced LLMs with strong attention/reasoning: Internal mechanisms suffice for noise rejection, yet processing redundant context is computationally inefficient. AdaRankLLM acts as a cost optimizer, pruning to the minimal sufficient context required for maximum task success, while avoiding performance loss due to missing evidence.
Additionally, the persistent oracle gap indicates diminishing returns from increasing model scale, static filtering, or even basic adaptive strategies, urging new retrieval-generation paradigms and tighter integration of evidence selection with reasoning processes.
Practical Implications and Prospects
Deployment
AdaRankLLM is explicitly designed for tractable deployment in cost-sensitive environments, democratizing adaptive listwise ranking to the open-source ecosystem through effective distillation. The lightweight inference mechanism—prompt-driven reranking with dropout—avoids complex iterative control flows, ensuring practical applicability for latency- and resource-constrained use cases.
Theoretical Outlook
Looking ahead, several research directions are prompted:
- Hybrid agentic retrieval: Incorporating agent-like, iterative retrieval policies that update evidence as generation unfolds, especially for tasks with evolving information needs.
- Interleaved retrieval-reranking-generation: Directly coupling the evidence selection and generation streams, possibly via end-to-end differentiable architectures or fine-grained decoder supervision.
- Domain-adaptive filtering: Applying adaptive listwise principles beyond QA—in personalized recommendation, schema-driven extraction, or privacy-sensitive deployments, targeting evidence sufficiency, efficiency, and safety tradeoffs.
Conclusion
AdaRankLLM systematically clarifies the shifting utility of adaptive retrieval across the landscape of LLM capabilities. By unifying zero-shot adaptive listwise ranking with a scalable distillation approach, it provides both a robust noise filter for weaker LLMs and an efficiency lever for stronger models. Despite these advances, current paradigms leave a substantial gap to oracle-optimal generation, motivating further exploration of integrated, context-aware retrieval-evidence selection mechanisms for the next era of knowledge-intensive AI.