- The paper presents a novel curvature-aware optimization method that adaptively corrects gradients using secant-based curvature estimation.
- It significantly reduces L2 error on challenging PDE benchmarks, with improvements up to two orders of magnitude over standard methods.
- The framework enhances convergence stability and is compatible with existing optimizers, paving the way for advanced physics-informed neural network applications.
Lightweight Geometric Adaptation for PINN Optimization
Motivation and Background
Physics-Informed Neural Networks (PINNs) represent a versatile paradigm for solving forward and inverse problems governed by Partial Differential Equations (PDEs), leveraging the approximation power of deep learning while embedding physical constraints via automatic differentiation. PINNs have been demonstrated across a spectrum of regimes including heat transfer, solid mechanics, stochastic phenomena, and uncertainty quantification. Despite their theoretical appeal, PINNs often encounter significant optimization bottlenecks: convergence is slow, training instability is frequent, and solution accuracy degrades for challenging settings such as stiff multi-scale equations, high-frequency regimes, or strongly coupled residual/boundary constraints. These issues are largely attributable to the highly anisotropic, ill-conditioned, and rapidly-varying geometry of the loss landscapes induced by the PINN objective.
The paper identifies the inadequacy of standard first-order optimization—especially the reactive nature of momentum and the sensitivity of instantaneous gradients—in navigating such heterogeneous landscapes. Instead, robust adaptation requires mechanism that can efficiently extract and utilize geometry information related to local curvature and trajectory-dependent characteristics of the loss. The premise is that modulating updates in accordance to directional curvature variation—not simply magnitude—is essential for efficient and stable PINN training.
Secant-Based Curvature-Adaptive Framework
The core methodological contribution is a lightweight curvature-aware optimization framework for PINNs that augments standard first-order methods (e.g., AdamW, SOAP, Muon) with an adaptive secant-based predictive correction, coupled with a dynamic gating mechanism sensitive to recent local geometry.
The framework operates by computing the consecutive gradient difference yk=gk−gk−1 at each iteration, using this signal as a computationally inexpensive proxy for the directional curvature along the recent step. This correction is incorporated as a predictive boost to the optimizer's input gradient, but crucially, modulated by a gating coefficient determined by a secant curvature indicator:
κk=∥sk∥22sk⊤yk
where sk is the displacement between consecutive parameters. The coefficient αk is constructed as a monotonically decreasing function of κk, typically αk=αbase(1+tanh(−κk)), ensuring aggressive extrapolation in flat directions and conservative correction in stiff regions. This mechanism provides dynamic control over the predictive signal, matching update sensitivity to the evolving loss landscape without explicit second-order computations.
The theoretical analysis demonstrates that, under mild L-smoothness and Lipschitz Hessian assumptions, the corrected gradient behaves as a first-order surrogate for a Hessian-vector product up to O(η2) remainder. A rigorous non-asymptotic convergence bound is established, confirming stationarity up to stochastic oracle variance.
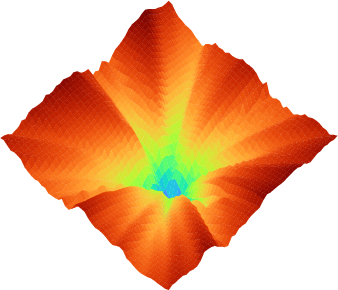
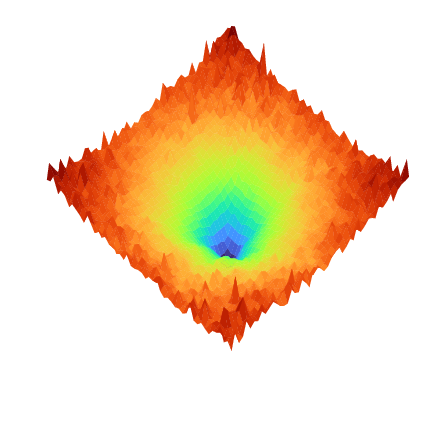
Figure 1: Projection of the loss landscape L for Burgers' equation, illustrating the marked geometric heterogeneity introduced by stiff PDE residuals.
Empirical Results on PINN PDE Benchmarks
The empirical evaluation spans four challenging benchmarks: the high-dimensional (10D) heat equation, Gray-Scott reaction-diffusion system, Belousov-Zhabotinsky (BZ) chemical oscillator, and the 2D Kuramoto–Sivashinsky chaotic PDE. Each benchmark exposes distinct optimization pathologies—multi-scale stiffness, rapid error accumulation, nonlinear coupling, and high-order chaotic dynamics. The curvature-aware (CA) modification is applied to AdamW, SOAP, and Muon optimizers, demonstrating robust, consistent improvements across all families.
On the 10D heat equation, CA-AdamW achieves a final L2 error two orders of magnitude lower than baseline AdamW (κk=∥sk∥22sk⊤yk0 versus κk=∥sk∥22sk⊤yk1). For Gray-Scott, CA-AdamW reduces κk=∥sk∥22sk⊤yk2 error to κk=∥sk∥22sk⊤yk3 of the baseline, and CA-SOAP attains optimal fidelity in both variables. The BZ system, characterized by stiff dynamics, sees CA-SOAP drive κk=∥sk∥22sk⊤yk4 error below κk=∥sk∥22sk⊤yk5 for all species, outperforming even strong baselines. For the chaotic 2D KS system, CA variants yield sharp reductions: CA-AdamW and CA-SOAP achieve error reductions of κk=∥sk∥22sk⊤yk6 and κk=∥sk∥22sk⊤yk7 respectively, with CA-SOAP consistently providing the lowest overall errors.
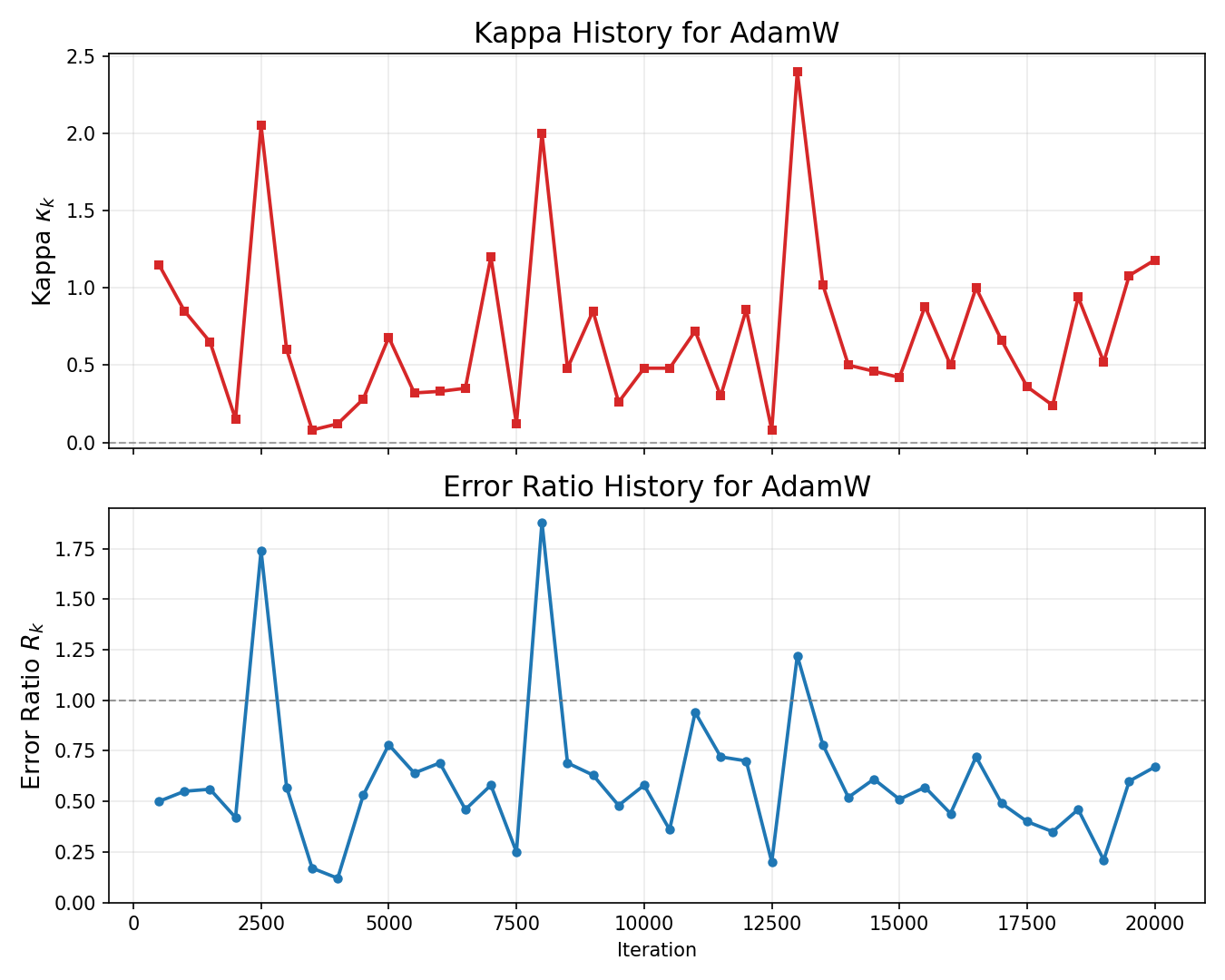
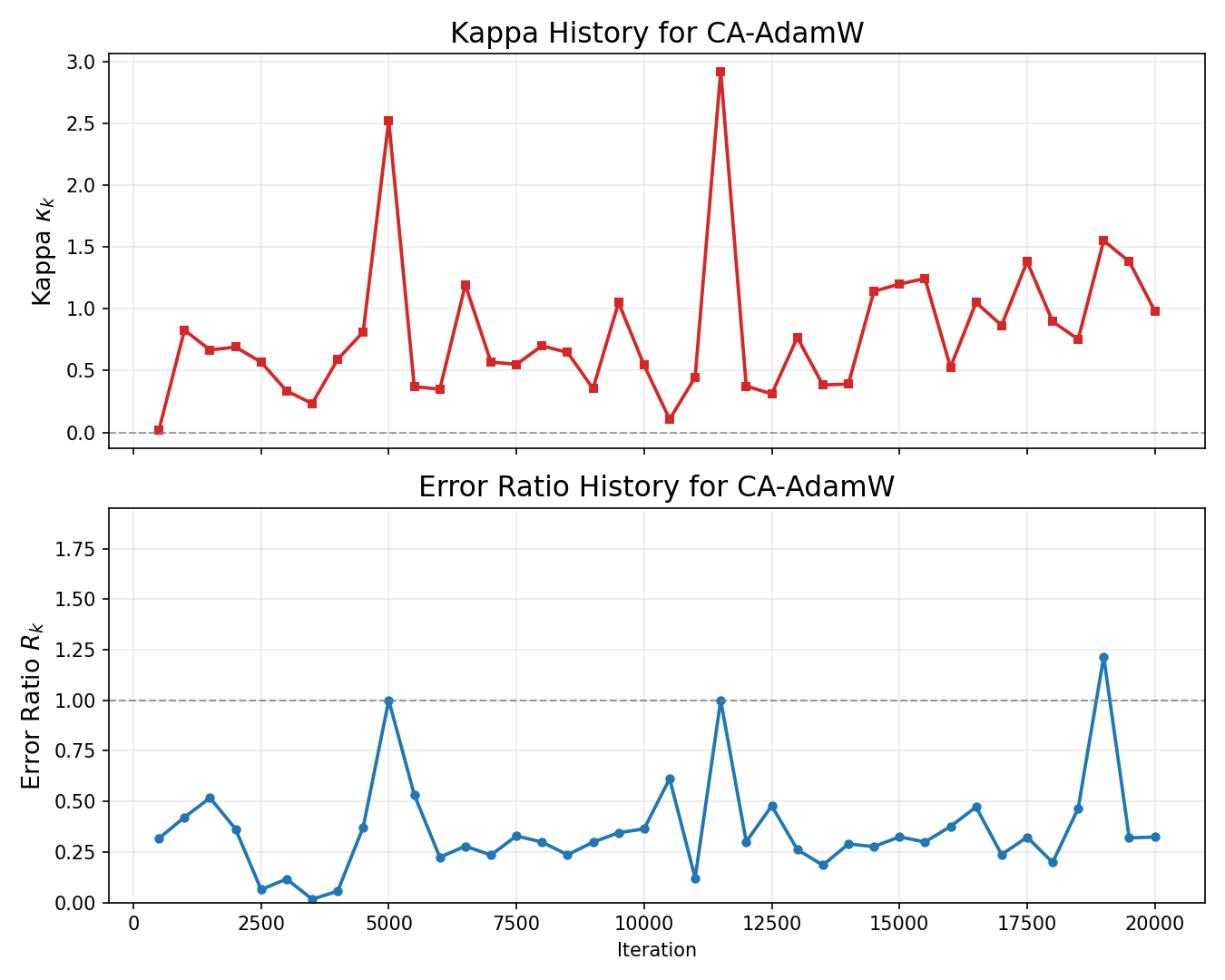
Figure 2: CA-AdamW suppresses large spikes in prediction error ratio κk=∥sk∥22sk⊤yk8, maintaining error below baseline failure for a larger training fraction—demonstrating effective curvature-aware gating.
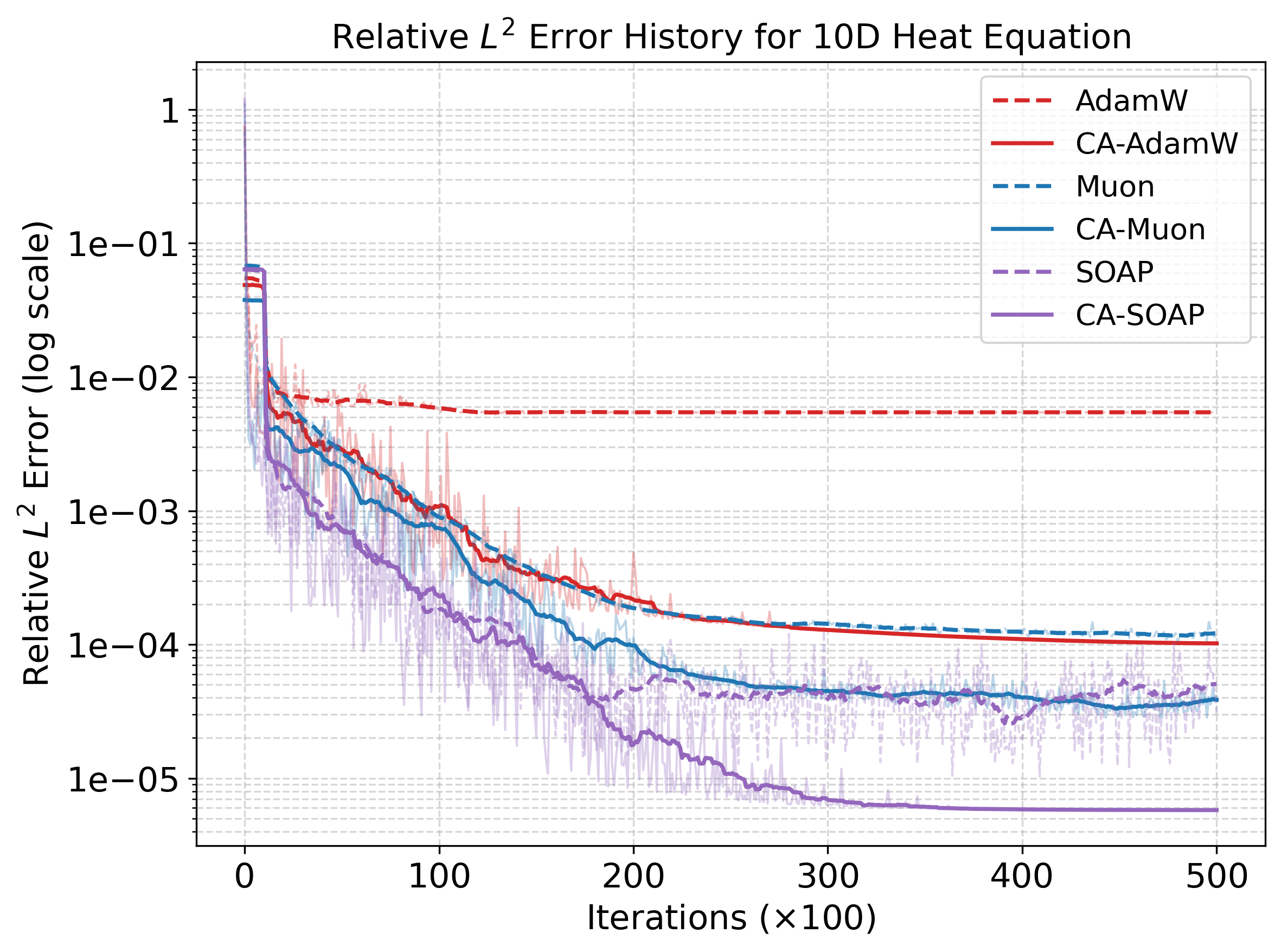
Figure 3: History of relative κk=∥sk∥22sk⊤yk9 errors for the 10D Heat Equation, highlighting accelerated convergence and superior final accuracy for CA-enhanced optimizers.
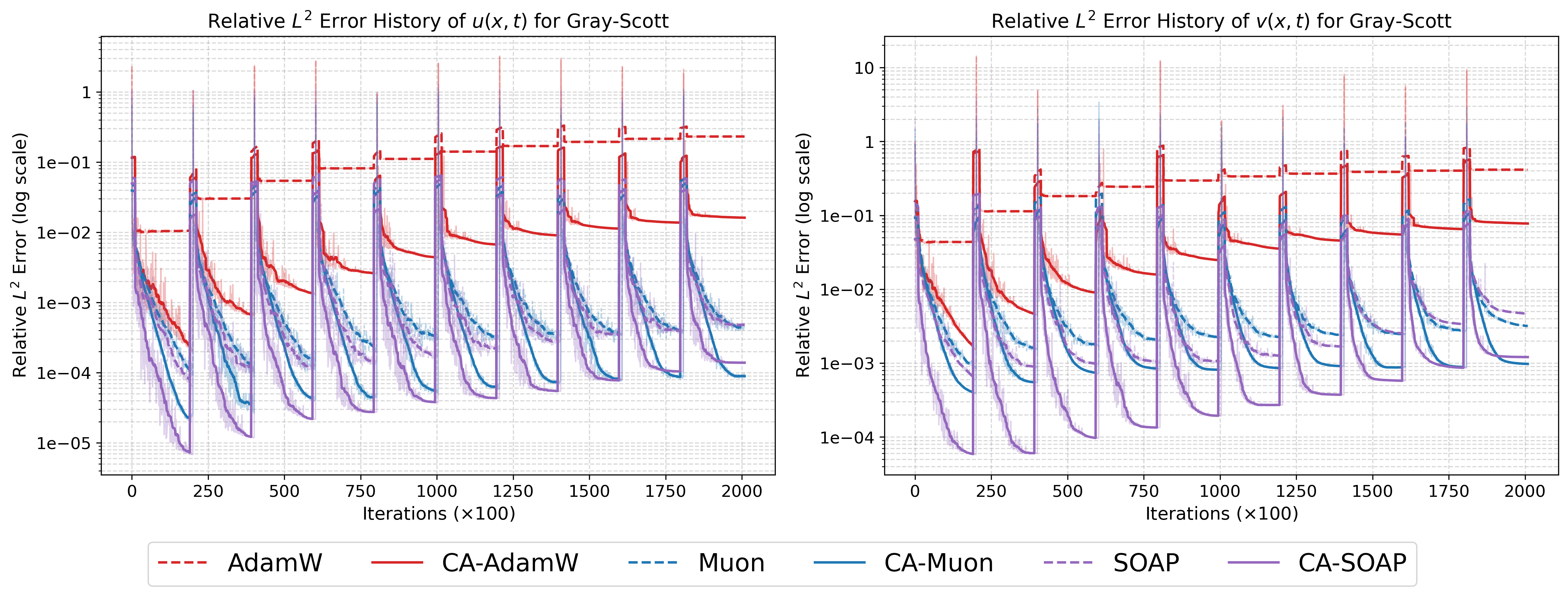
Figure 4: Relative sk0 error history on Gray-Scott system; time-marching strategy induces periodic spikes at window transitions.
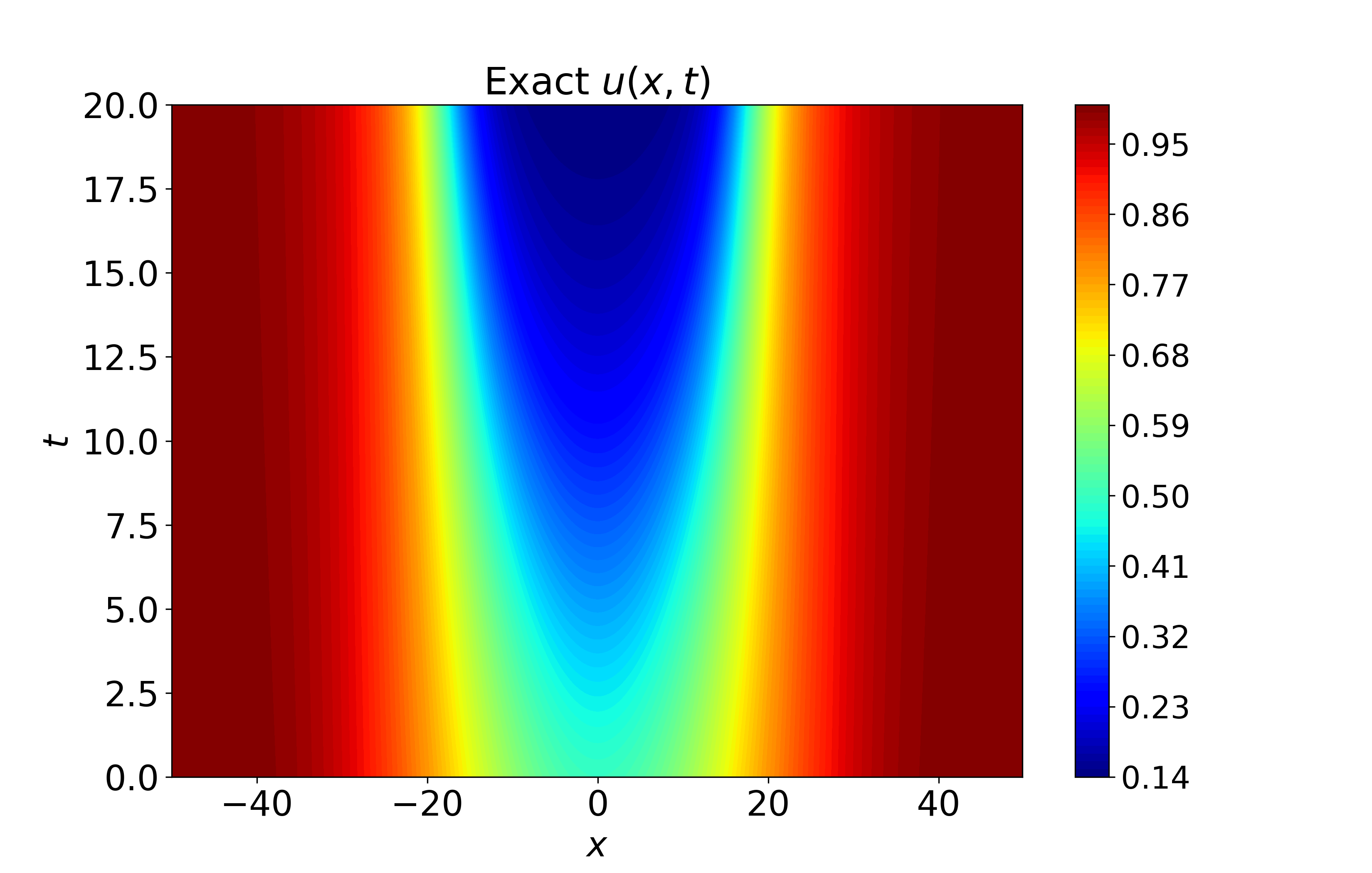
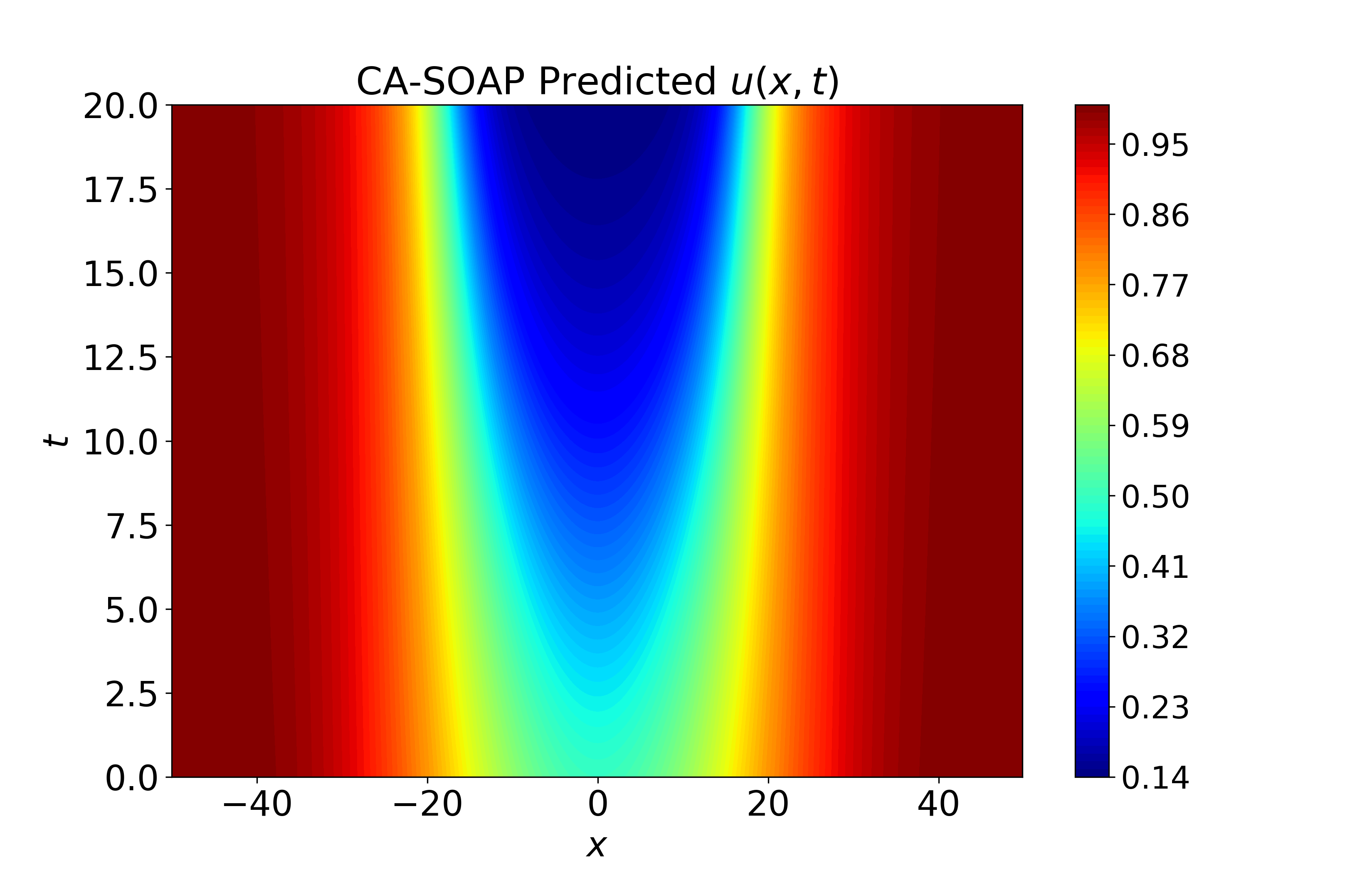
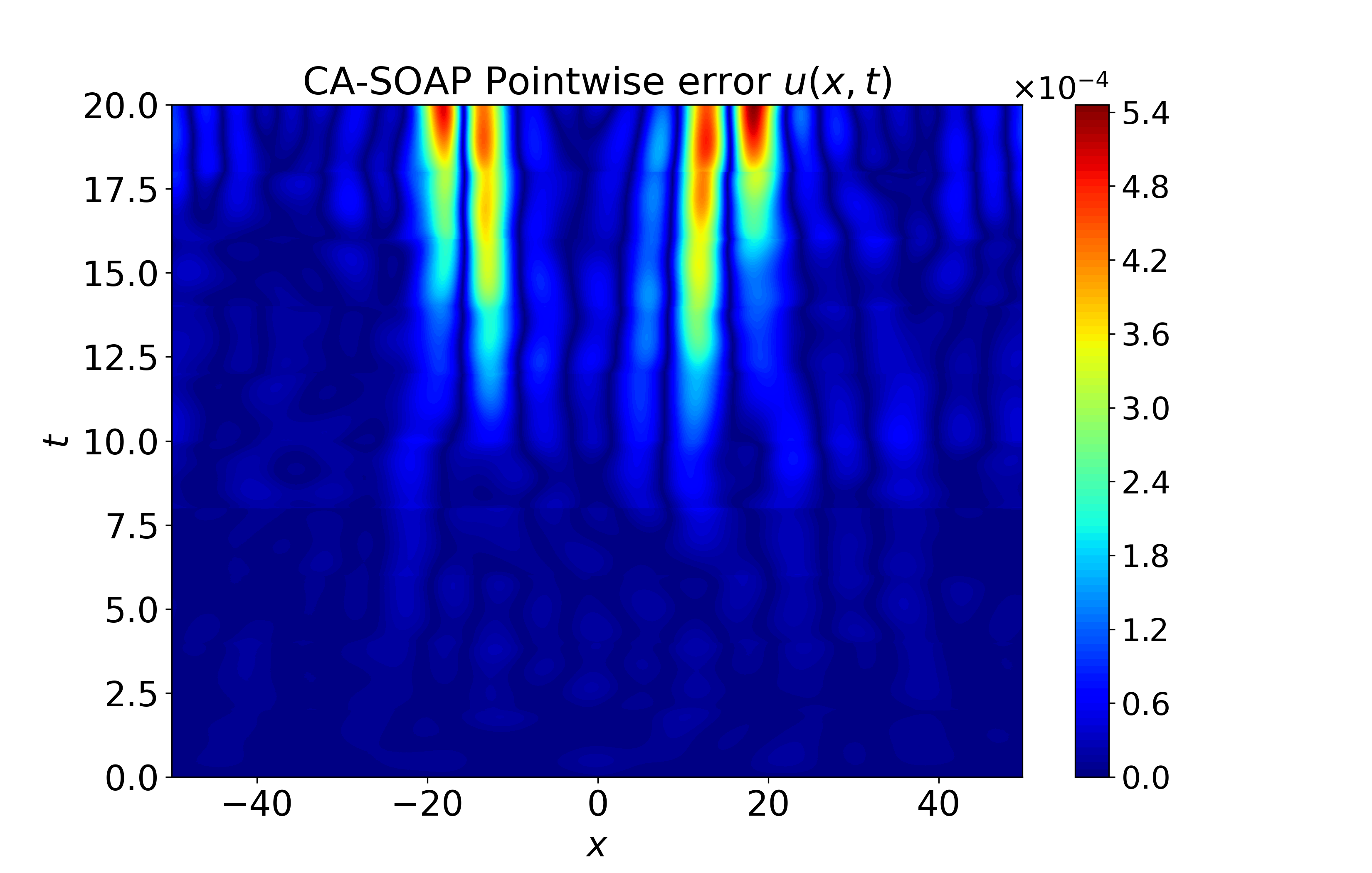
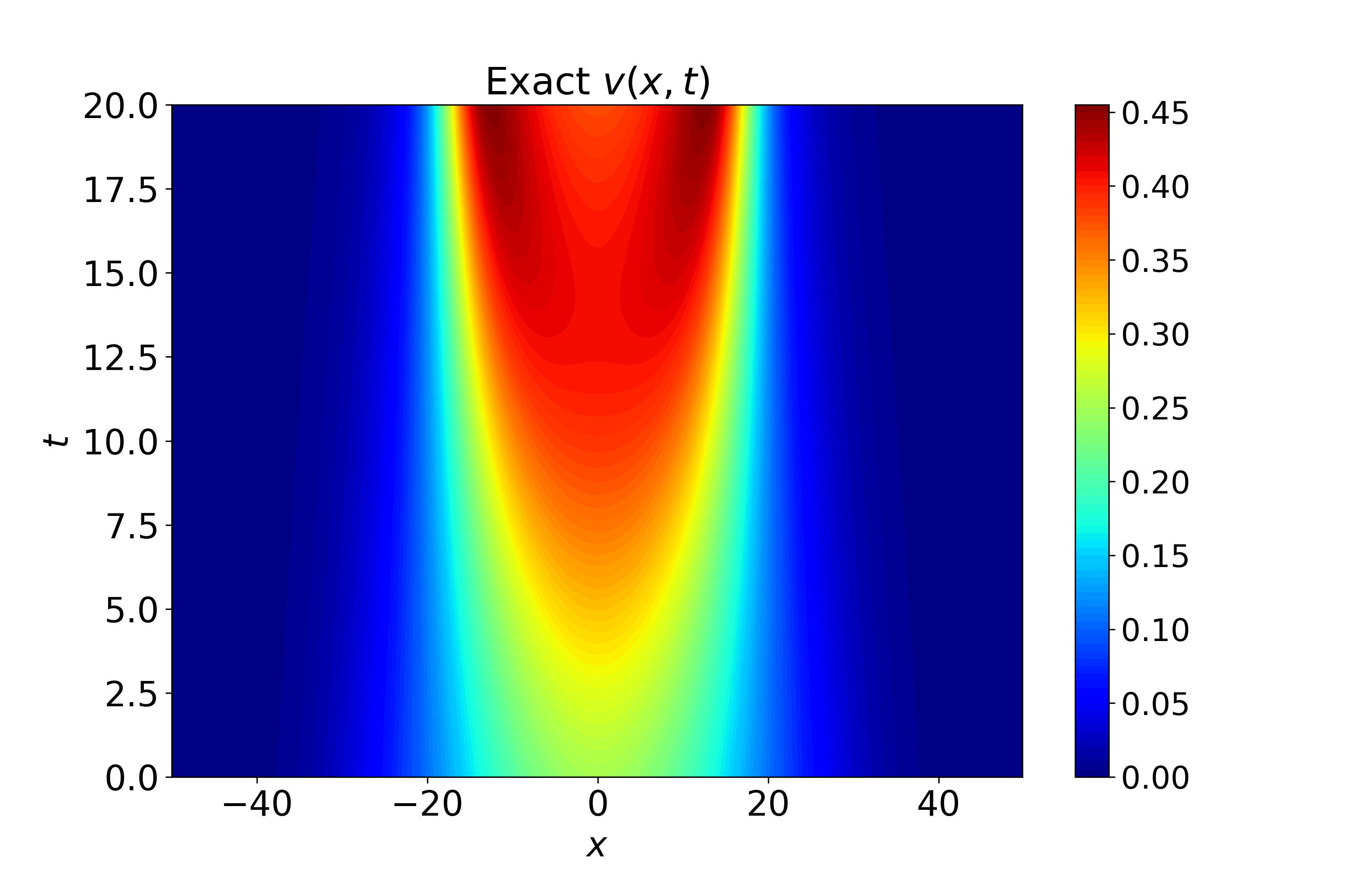
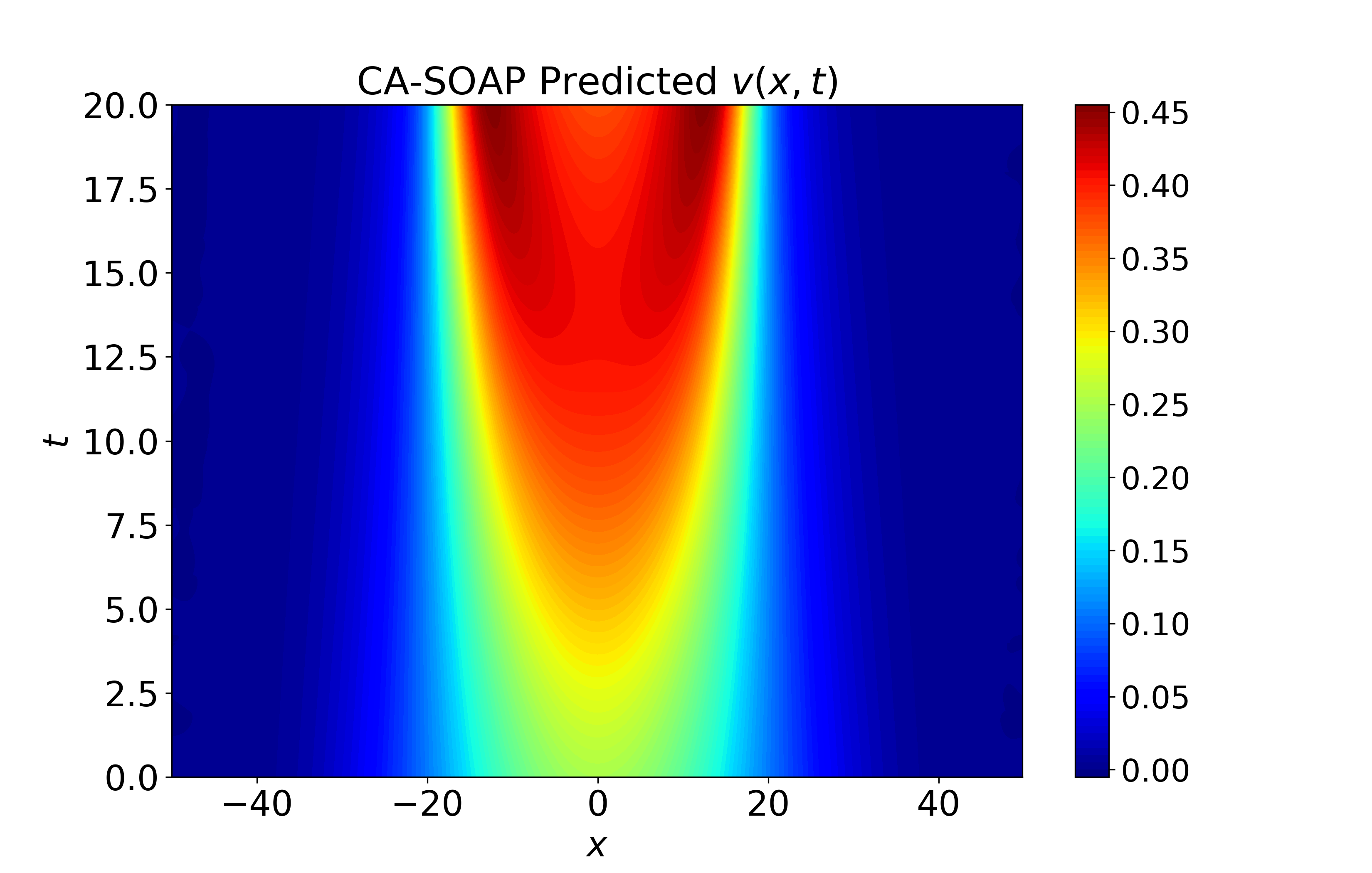
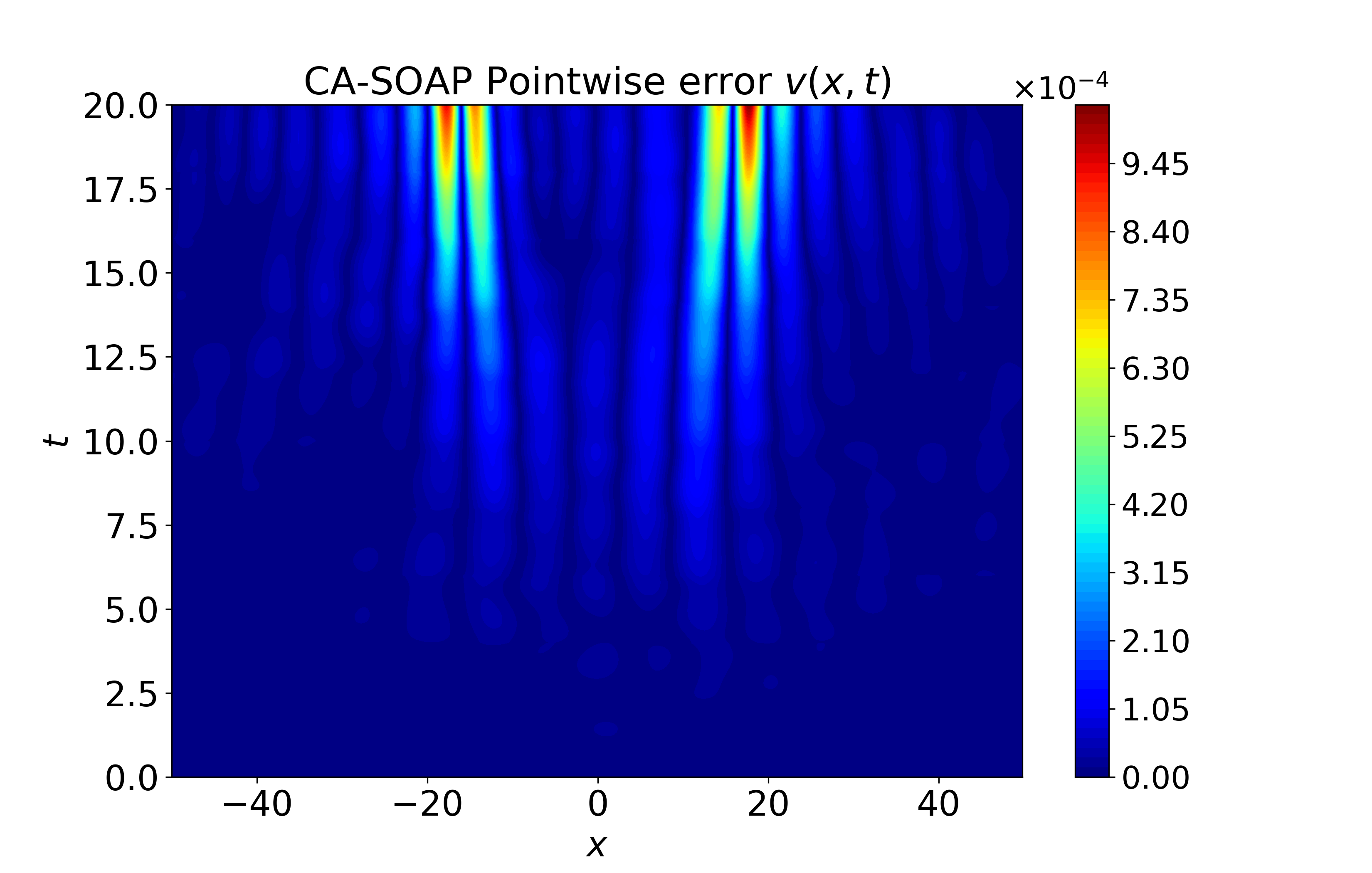
Figure 5: Spatiotemporal heatmaps for Gray-Scott system using CA-SOAP, revealing close agreement with reference solution and pointwise errors suppressed throughout.
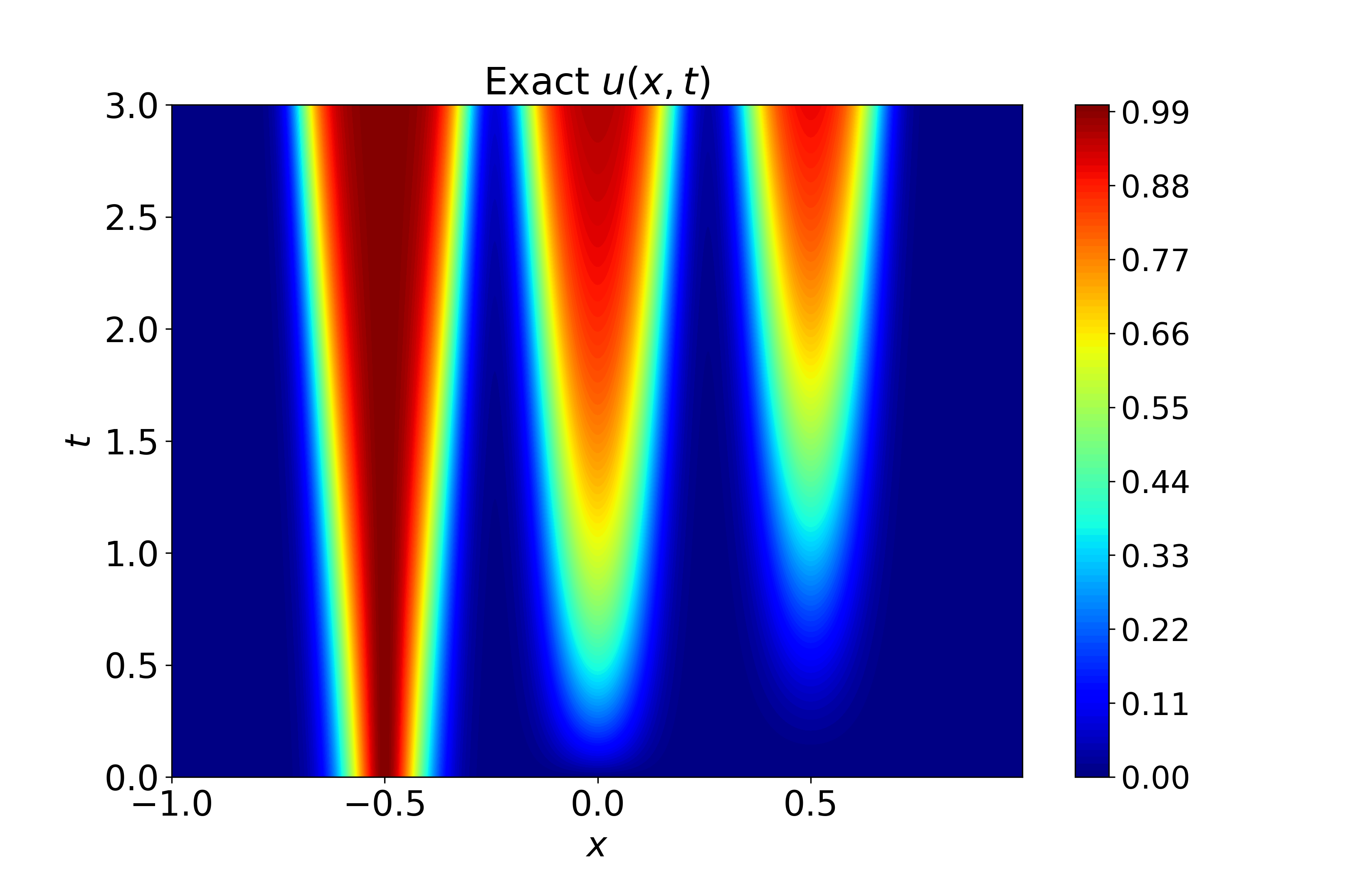
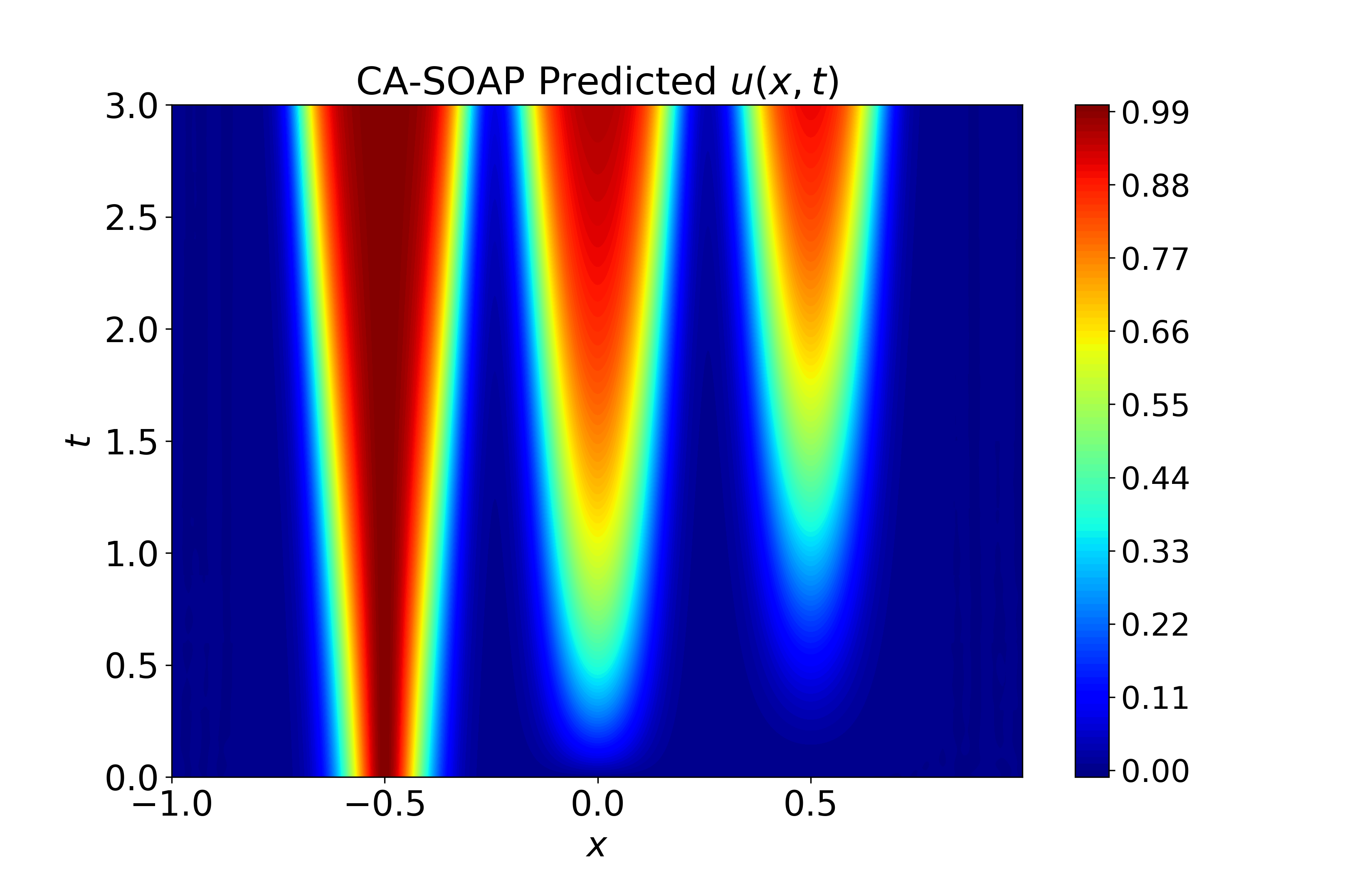
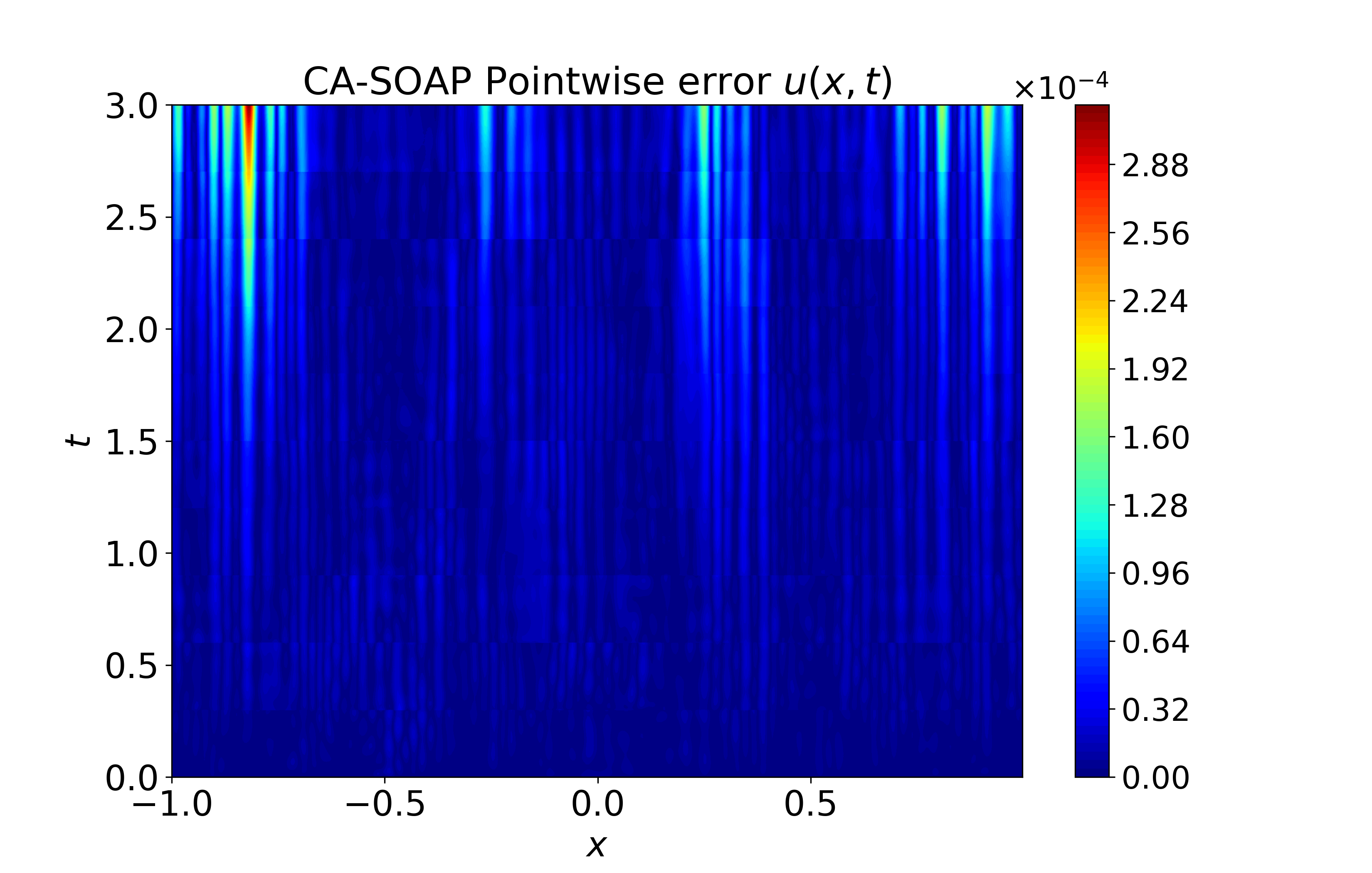
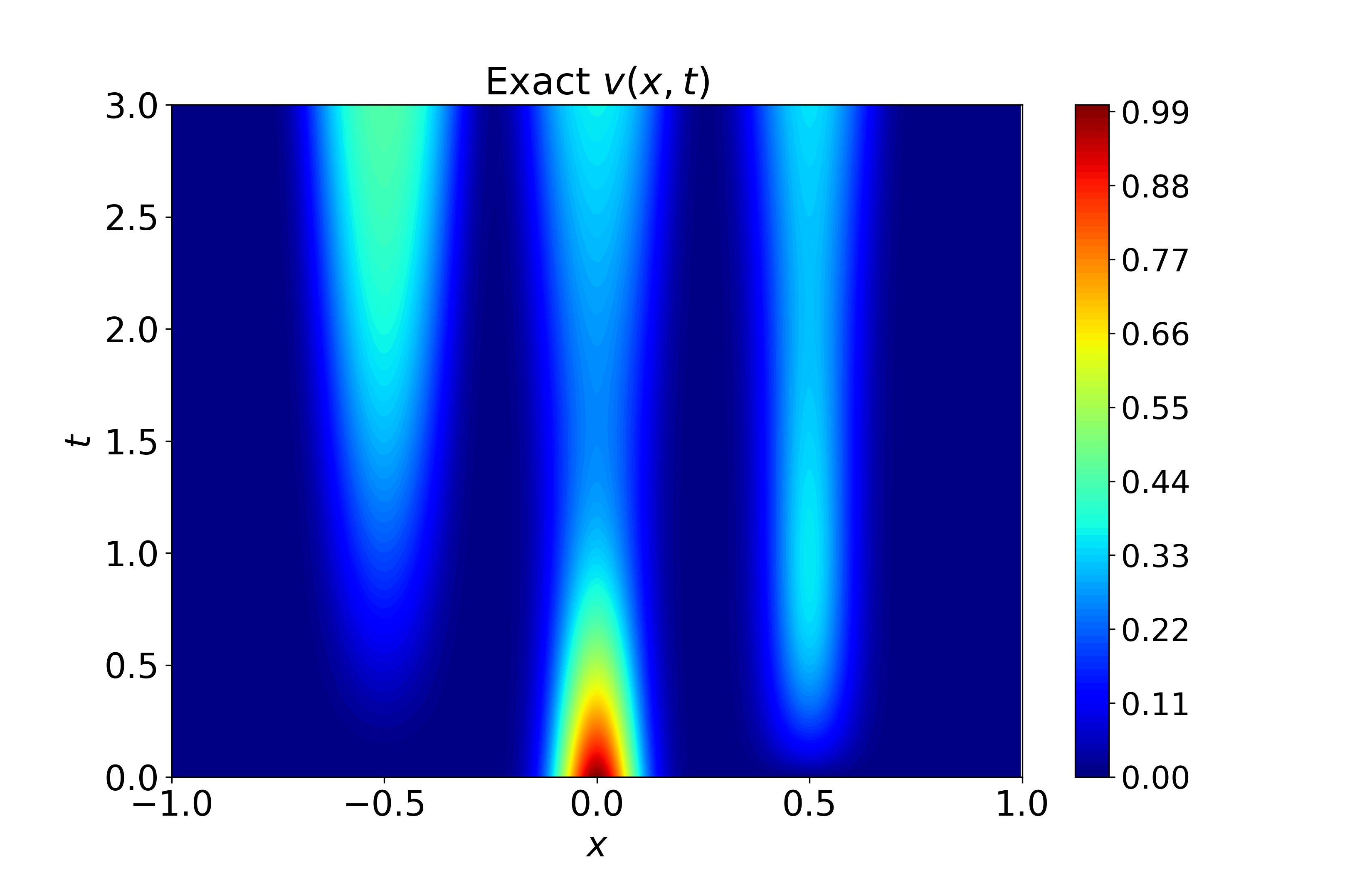
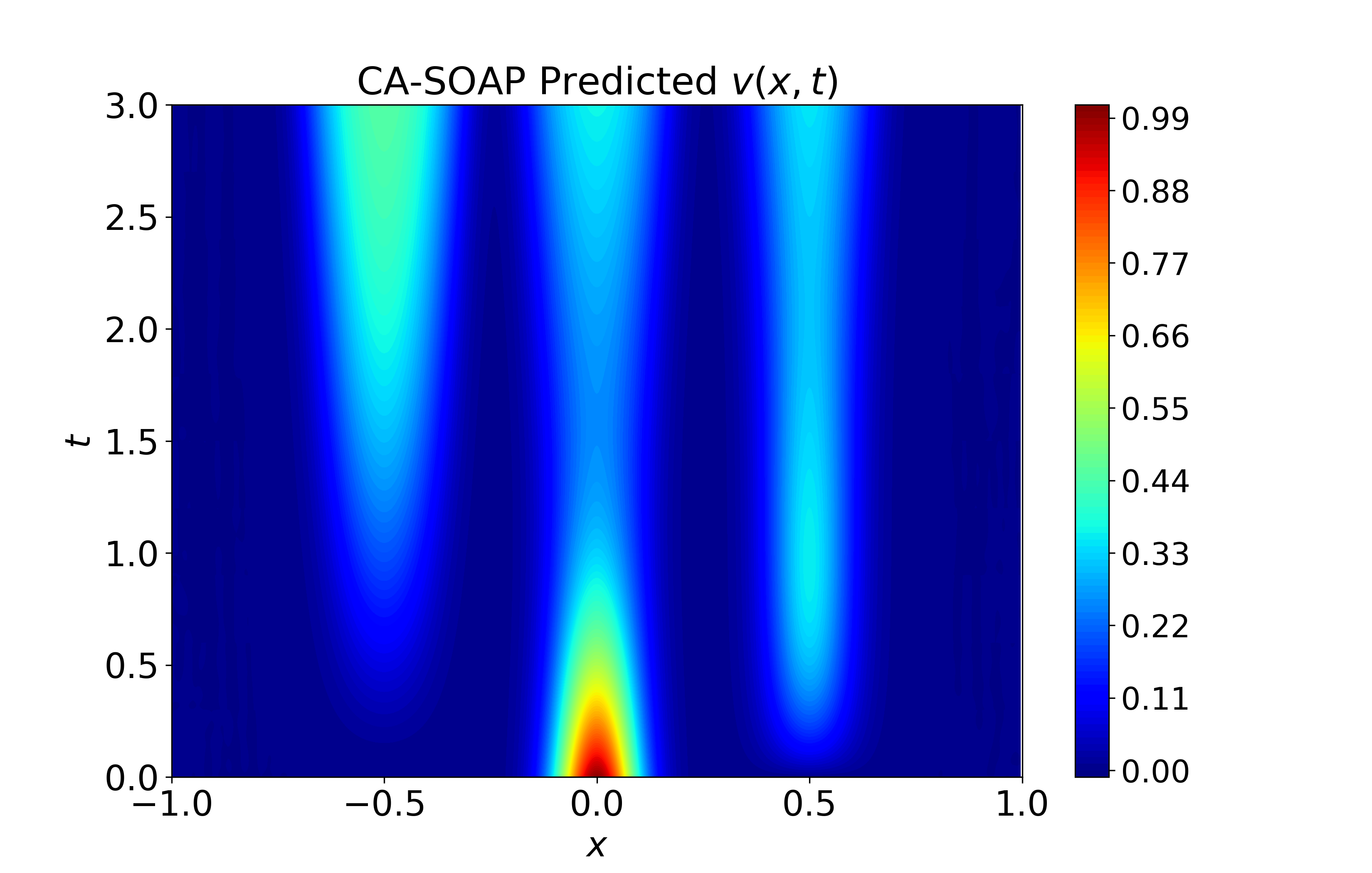
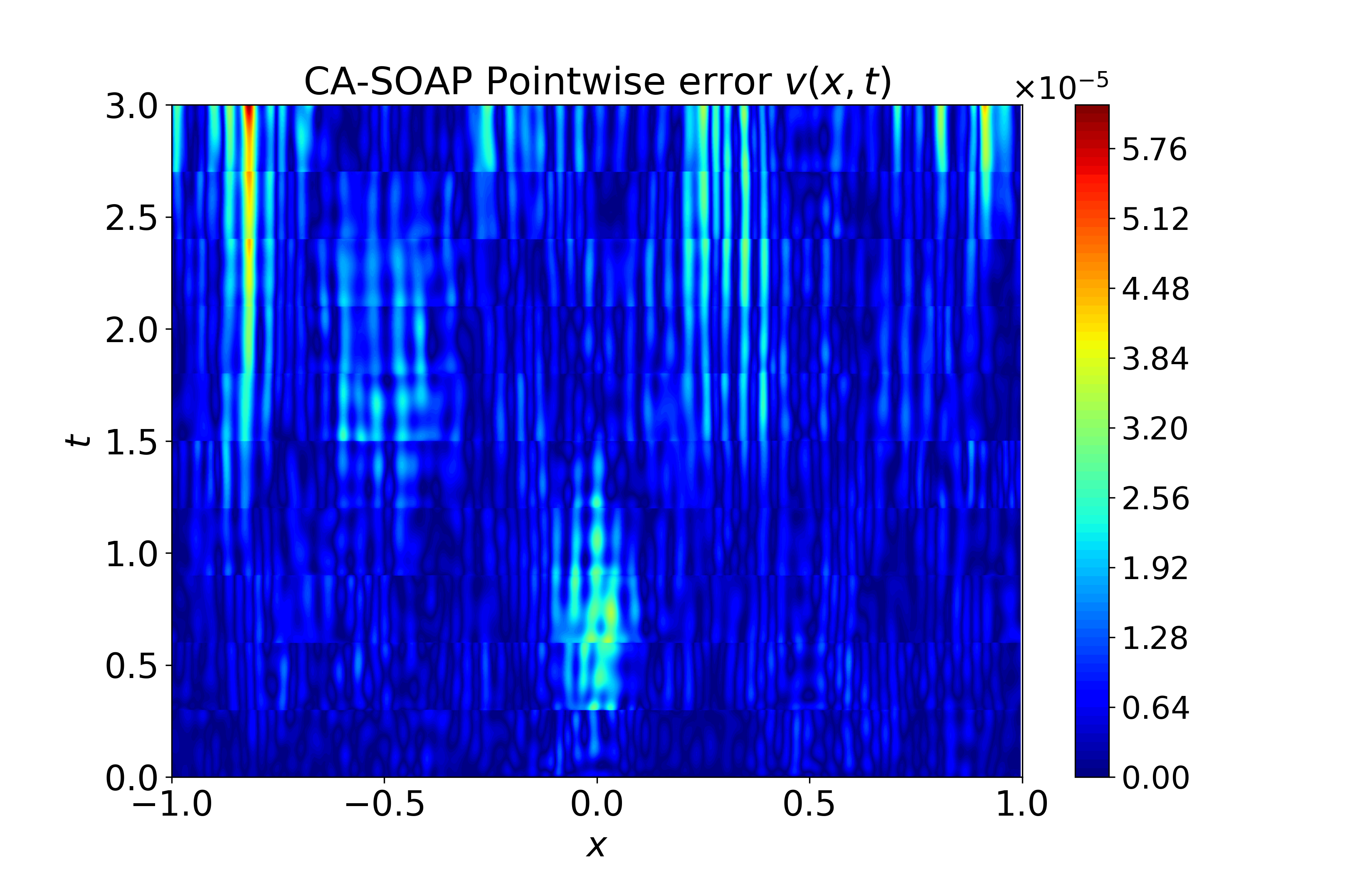
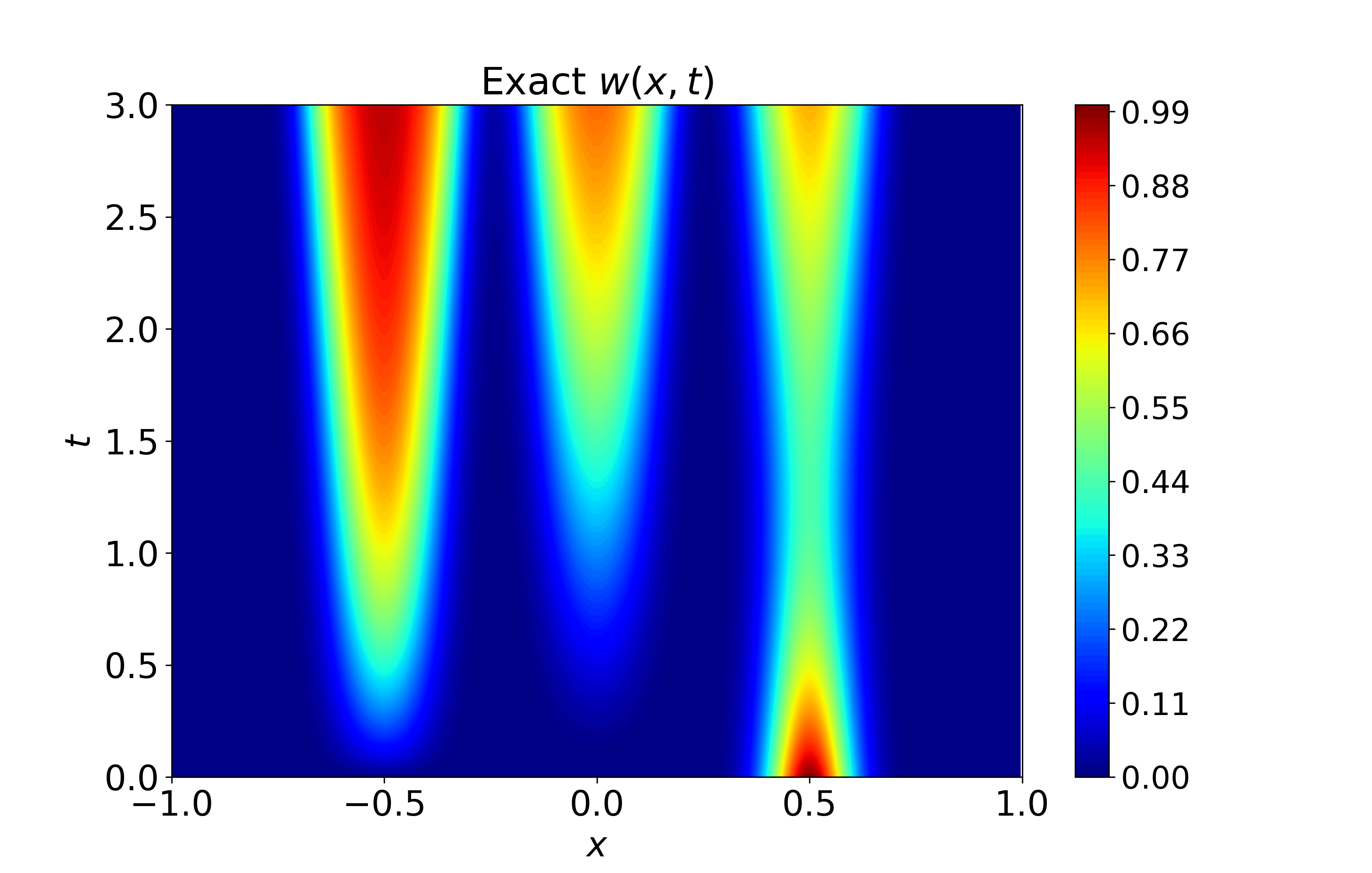
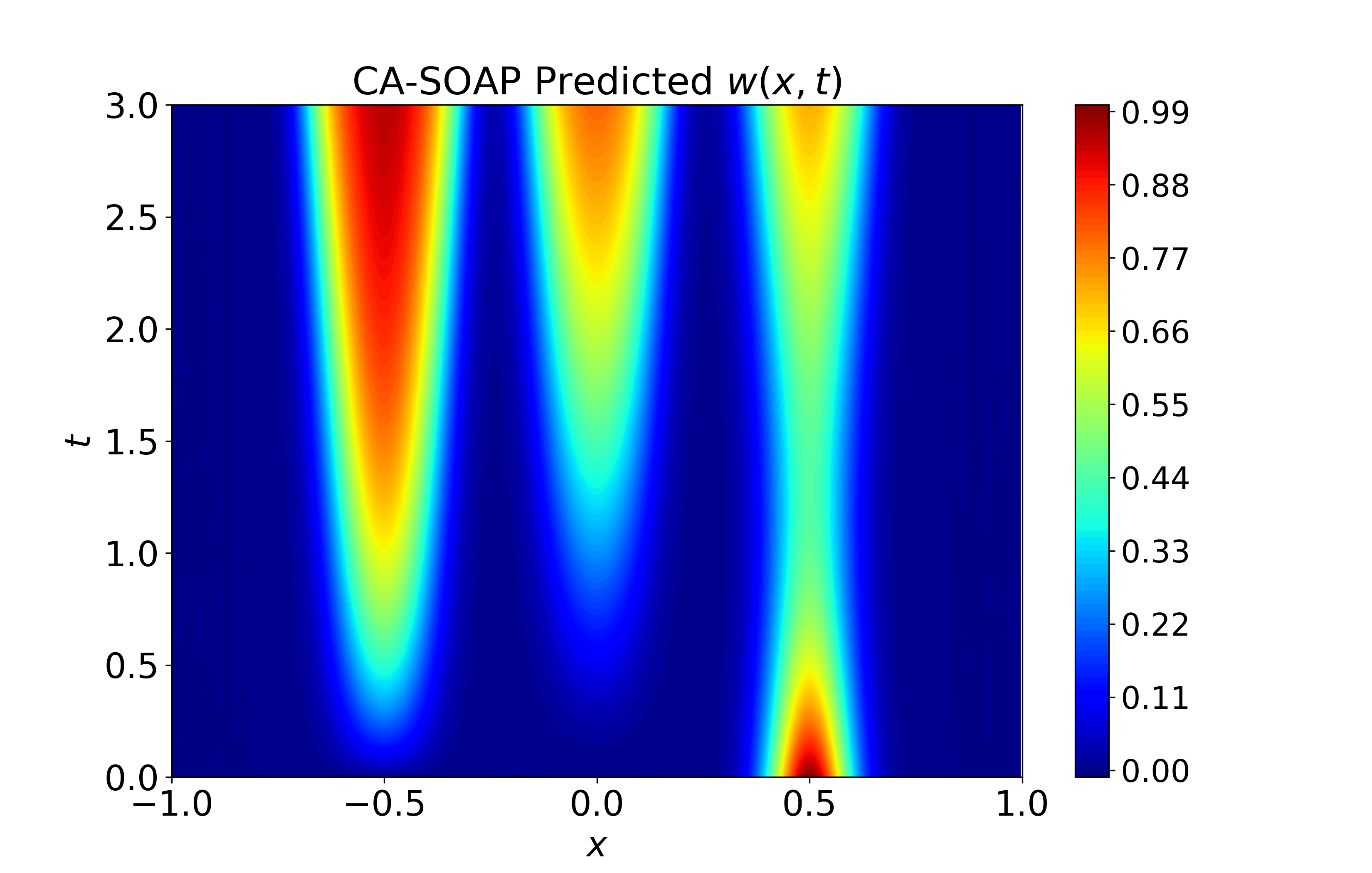
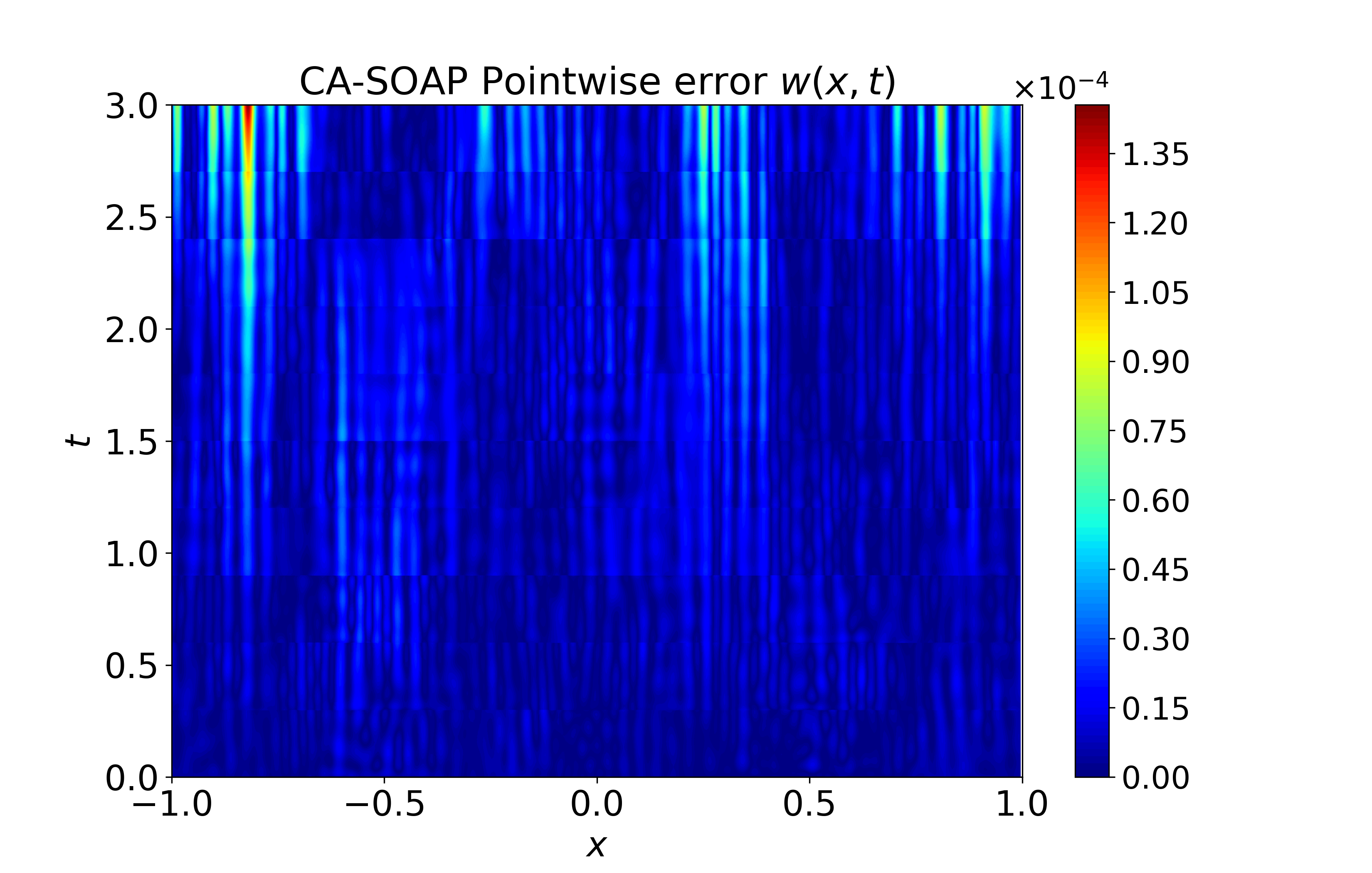
Figure 6: Spatiotemporal heatmaps for BZ system using CA-SOAP, demonstrating faithful reproduction of coupled dynamics and low error.
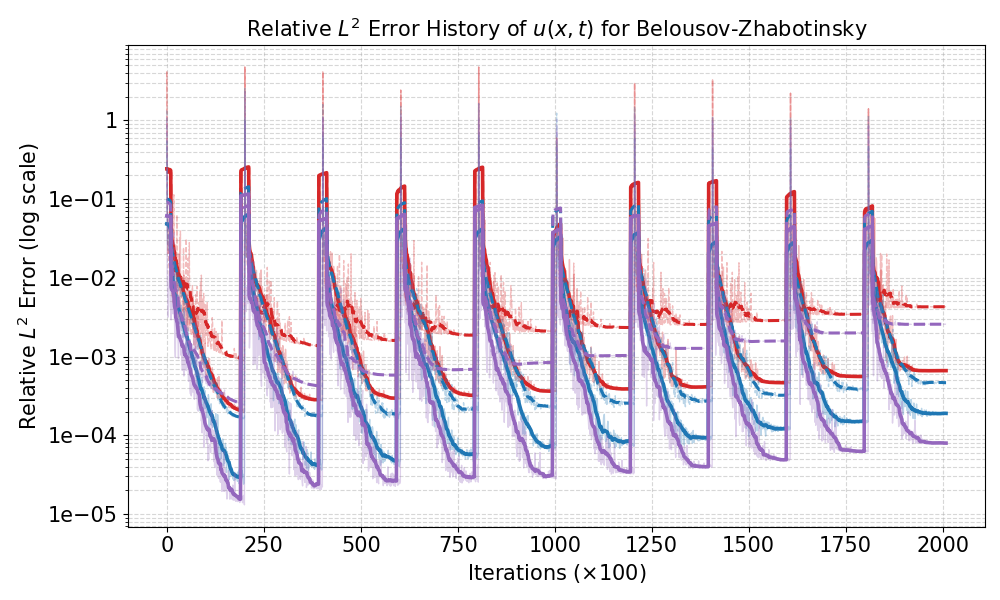
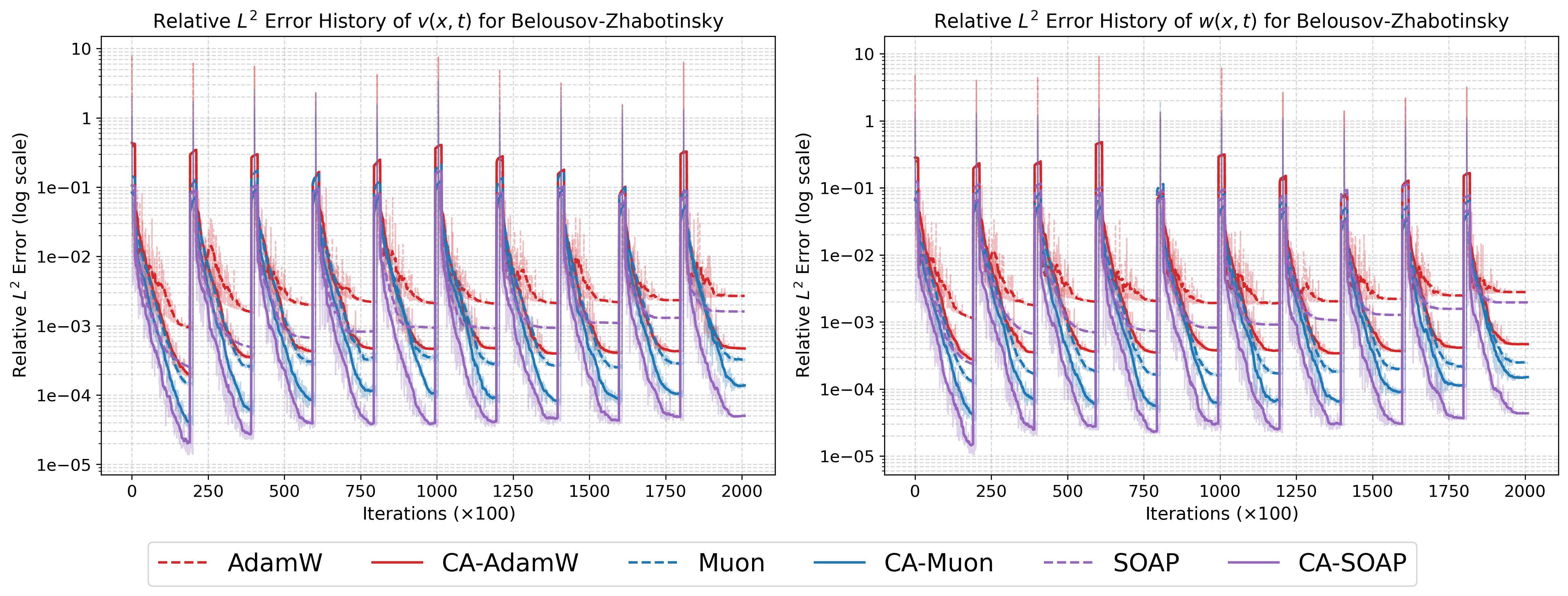
Figure 7: History of relative sk1 errors for BZ system, indicating stable suppression across time windows.
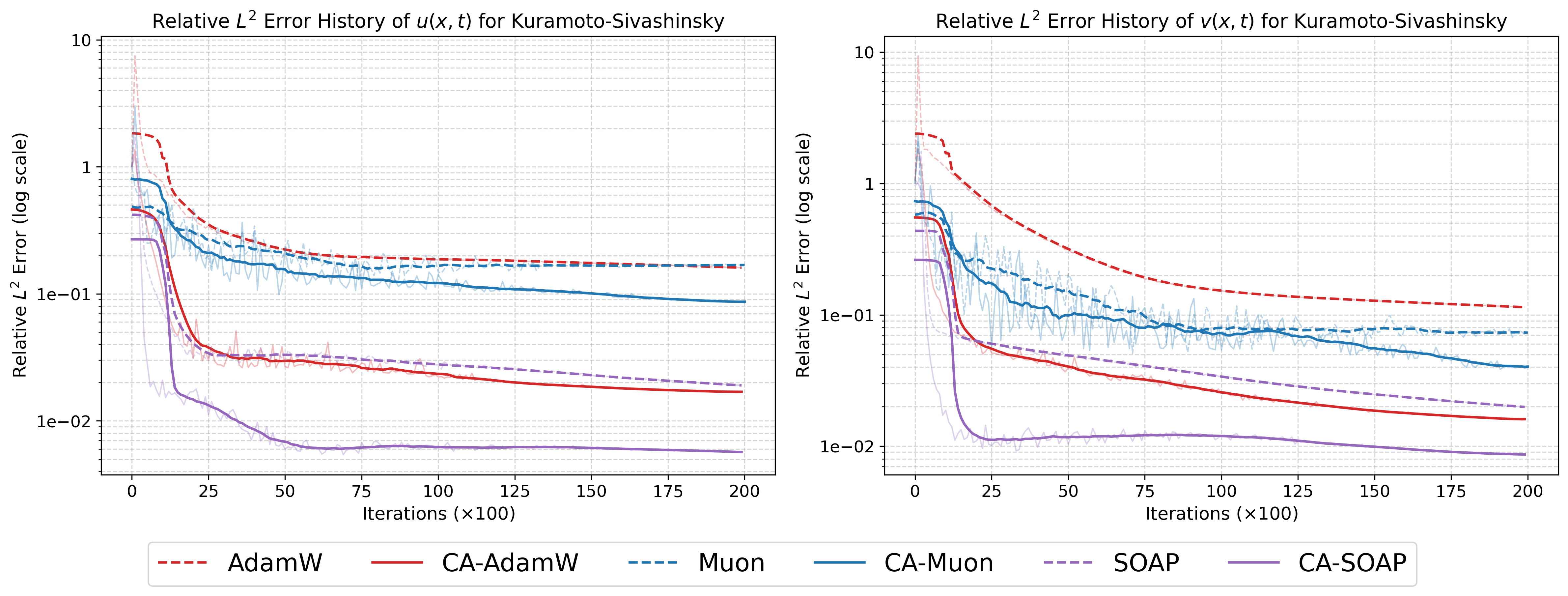
Figure 8: Training evolution for 2D Kuramoto--Sivashinsky system; CA variants consistently reduce relative sk2 errors for both sk3 and sk4.
Additionally, CA-AdamW outperforms related adaptive moment enhancements such as Adan and ALTO on the 2D KS benchmark, underscoring the effectiveness of dynamic geometry gating over fixed correction strategies.
Implications and Path Forward
The study advances a formal rationale for trajectory-sensitive updates in PINN optimization. By bridging the gap between instantaneous gradients and local curvature, the proposed framework offers practical improvements in convergence stability and accuracy with minimal computational overhead. The methodology is broadly compatible with established optimizers, does not require explicit second-order operations, and is readily extensible to operator-based learning and large-scale multiphysics systems.
Practically, the robust gains on stiff, high-dimensional, and chaotic PDEs indicate that lightweight geometric adaptation is a central ingredient for scaling PINNs to more complex regimes and industrial applications. Theoretically, the demonstrated convergence and curvature surrogate properties suggest productive avenues for further optimization algorithm development: more precise curvature gating mechanisms, integration with second-order approximations, and deeper landscape-theoretic understanding.
Conclusion
This paper presents a curvature-aware, secant-based framework for PINN optimization that augments first-order updates with lightweight predictive correction, adaptively gated by explicit trajectory-level curvature indicators. The approach achieves consistent improvement in convergence speed, training stability, and solution fidelity across diverse PDE benchmarks, including settings with pronounced geometric heterogeneity and optimization difficulty. The results substantiate the necessity of dynamic geometric adaptation for PINN training, and highlight its role in advancing physics-informed deep learning toward more demanding scientific and engineering applications (2604.15392).

