Fleet: Hierarchical Task-based Abstraction for Megakernels on Multi-Die GPUs
Abstract: Modern GPUs adopt chiplet-based designs with multiple private cache hierarchies, but current programming models (CUDA/HIP) expose a flat execution hierarchy that cannot express chiplet-level locality or synchronization. This mismatch leads to redundant memory traffic and poor cache utilization in memory-bound workloads such as LLM inference. We present Fleet, a multi-level task model that maps computation to memory scopes. Fleet introduces Chiplet-tasks, a new abstraction that binds work and data to a chiplet and enables coordination through its shared L2 cache. Wavefront-level, CU-level, and device-level tasks align with existing abstractions, while Chiplet-tasks expose a previously unaddressed level of the hierarchy. Fleet is implemented as a persistent kernel runtime with per-chiplet scheduling, allowing workers within a chiplet to cooperatively execute tasks with coordinated cache reuse. On AMD Instinct MI350 with Qwen3-8B, Fleet achieves 1.3-1.5x lower decode latency than vLLM at batch sizes 1-8 through persistent kernel execution and per-chiplet scheduling. At larger batch sizes, cooperative weight tiling increases L2 hit rate (from 12% to 54% at batch size 32 and from 39% to 61% at batch size 64), reducing HBM traffic by up to 37% and delivering 1.27-1.30x speedup over a chiplet-unaware megakernel baseline.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper explains a new way to run AI programs on modern graphics chips (GPUs) that are built from several smaller “chiplets.” The authors introduce Fleet, a system that organizes work so each chiplet can reuse data in its own local cache, cutting down on long trips to slow memory. This matters a lot for LLMs, where the part that generates each new word (called “decode”) is often slowed by memory, not math.
The big questions the paper asks
- Today’s GPU software treats the whole chip as one flat space, even though the hardware is split into chiplets with separate caches. Can we change the programming model to match the hardware so we waste less memory bandwidth?
- Can this help LLMs generate tokens faster by reusing weights (the big matrices) better?
- Can we do it in a way that avoids launch overhead (waiting to start many small GPU jobs) and keeps latency steady?
How they tackled it (in everyday terms)
Think of the GPU as an apartment building:
- Each apartment (chiplet) has its own fridge (L2 cache).
- The building has a shared pantry downstairs (HBM memory), which is slower to reach.
- If people in different apartments need the same ingredient (weights), you don’t want each person to ride the elevator down to the pantry again and again—you want to share within the same apartment’s fridge.
Fleet reorganizes work so that:
- People in the same apartment cook parts of the same recipe together, sharing what’s already in their fridge.
- A “floor manager” (scheduler) in each apartment hands out tasks to roommates (workers), so they fetch and use the same ingredients at the same time.
A new way to think about GPU work
Fleet breaks work into four levels that match where the data lives:
- Wavefront-task: tiny, runs inside a small team; uses registers/local scratchpad (good for simple element-wise math like activations).
- CU-task: medium, runs on one compute unit; uses shared on-chip memory (good for attention and normalization).
- Chiplet-task: new idea in this paper; runs across all workers inside one chiplet, sharing the chiplet’s L2 cache (great for big matrix multiplies in linear layers).
- Device-task: runs across the whole GPU; coordinates all chiplets.
By making “Chiplet-tasks” a first-class thing, Fleet lets you say “this chunk of work and its data should live together on one chiplet.”
Scheduling inside the GPU “building”
Fleet runs as a single, long-lived “persistent kernel” (think: one big cooking session instead of many tiny ones). In each chiplet:
- One workgroup acts as the scheduler (the floor manager).
- The rest are workers (the cooks).
- The scheduler hands out tasks that are local to the chiplet so workers can reuse the same cached data.
This avoids the delays from launching hundreds of tiny GPU kernels and keeps useful data in the chiplet’s cache between steps.
Sharing data the smart way
For the big matrix multiplies (the heart of LLM layers), Fleet:
- Splits the output columns across chiplets (each chiplet computes its slice).
- Coordinates workers so they process batches in an order that maximizes reuse of the same weight tiles (like all roommates using the same open jar before moving to a new one).
- Uses “streaming” cache hints for weights so they stay just long enough to be reused by neighbors, then make room for the next weights.
- Avoids clutter: temporary results are written in a way that doesn’t evict valuable weight data from the cache.
- Fuses small follow-up steps (like SiLU activation) into the same task so data stays on-chip instead of bouncing out and back.
Keeping communication cheap
Talking across chiplets is slower than talking inside one. Fleet uses a “hierarchical” sync plan:
- Inside a chiplet: workers update local counters (cheap and fast).
- Across chiplets: only one worker per chiplet sends a global signal when the chiplet’s part is done (reduces expensive cross-chiplet messages).
What they found
Tested on an AMD Instinct MI350 GPU running the Qwen3-8B LLM:
- At small batch sizes (1–8), Fleet reduces per-token decode latency by 1.3–1.5× compared to vLLM by using a persistent kernel and per-chiplet scheduling.
- At larger batch sizes, coordinating how weights are shared raises the chiplet cache (L2) hit rate a lot:
- From 12% to 54% at batch size 32
- From 39% to 61% at batch size 64
- This cuts traffic to slow memory (HBM) by up to 37%.
- Overall, Fleet is 1.27–1.30× faster than a similar “megakernel” that doesn’t know about chiplets.
Why this matters: Most time during LLM decode is spent moving weights, not multiplying them. Better cache reuse directly speeds up token generation.
Why it matters
- Faster, steadier responses: Lower latency for token generation helps chatbots, code assistants, and voice agents feel more responsive.
- Better use of modern hardware: Today’s top GPUs are chiplets with separate caches. Fleet’s “Chiplet-task” idea teaches software to use this design well.
- Less wasted memory traffic: Sharing data within a chiplet cuts duplicate loads, saving energy and bandwidth.
- Portable thinking: While chiplet designs differ across companies, the core idea—map work to where the data lives—can apply broadly.
The takeaway
Fleet aligns the way we schedule work with the way modern GPUs are built. By introducing Chiplet-tasks and running everything in a single, persistent session, it keeps hot data local, reduces memory trips, and speeds up LLM inference. It’s a simple idea—keep work and data together—but applied carefully, it delivers real, measurable speedups.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list distills what remains missing, uncertain, or unexplored in the paper, with concrete directions for follow-on research:
- Portability to other vendors: No evaluation on NVIDIA Blackwell or other multi-die GPUs; unclear how Fleet’s chiplet-tasks, cache modifiers, and synchronization map to architectures with globally coherent L2 and different cache hierarchies.
- Generality across chiplet topologies: Behavior with different numbers/sizes of chiplets, varying L2/LLC capacities, and heterogeneous per-die capabilities is not studied.
- Role of the shared LLC (Infinity Cache): The paper alludes to characterizing LLC behavior but provides no quantitative results; how cooperative tiling interacts with LLC, and whether LLC sharing undermines L2-locality gains, remains unclear.
- Auto-selection of partitioning schemes: Criteria and mechanisms for switching between N-split and K-split strategies (batch size, model dimension thresholds) are heuristic and not auto-tuned or formally derived.
- Lack of auto-tuning: Tile sizes, traversal order, and cache modifier settings are fixed or inspired by prior work; no autotuner explores trade-offs across workloads, hardware, and batch sizes.
- Scheduling policy robustness: The per-chiplet scheduler’s round-robin and broadcast strategies are not compared against alternatives (work stealing, load-aware distribution, latency vs. throughput objectives).
- Quantifying scheduling overheads: Only a qualitative note that 3.1% of CUs act as schedulers; no microbenchmarks isolate overheads, especially for very short tasks or high event rates.
- Fairness and multi-tenancy: A persistent megakernel monopolizes CUs; how Fleet behaves with concurrent kernels, MPS/MIG-like partitioning, or time-slicing/preemption is unaddressed.
- Dynamic batching/arrival variability: Handling fluctuating request rates, heterogeneous sequences, and priority scheduling in serving scenarios is not evaluated.
- Correctness and memory-model guarantees: The hierarchical synchronization protocol (L2-local vs. device-scope) lacks formal correctness proofs under weak memory models and corner cases (e.g., device preemption, context switches).
- Sensitivity to cache modifiers: The three-tier cache policy (streaming weights, NT stores for activations, scheduler polling) is not sensitivity-tested across models, precisions, and hardware revisions; risks of suboptimal eviction or coherence pitfalls remain.
- Impact on power/energy: Persistent kernels, aggressive polling, and hierarchical fences may affect energy; no measurement of energy-use or thermal effects.
- Limited operator coverage: Focus is on linear layers and some attention/CU tasks; sparse kernels, normalization variants, quantized/decompressed weights, and other ops (e.g., rotary embeddings, KV cache management) receive limited treatment.
- Prefill and training phases: Fleet is optimized for memory-bound decode; compute-bound prefill and training workloads (with different reuse patterns and synchronization) are not analyzed.
- Cross-token reuse opportunities: Whether weights/activations can be kept resident across decode steps to exploit temporal reuse beyond a single token is not explored.
- Interaction with weight compression: Modern inference uses int8/FP8 or W4A8 with on-the-fly dequantization; effects on L2 residency, tiling, and cache modifiers are not investigated.
- Compiler/codegen maturity: The task graph generation and code generation pipeline (e.g., integrating cache-scoped instructions) are not fully described; tooling for safely emitting sc0/sc1/NT variants and verifying correctness is lacking.
- Programmer burden and API design: How developers specify chiplet-tasks, events, and cache policies at a high level (and how errors are prevented) is not elaborated; integration with mainstream frameworks (PyTorch, Triton, TVM) is open.
- Load imbalance at small batch sizes: When bs < number of chiplets, N-split can underutilize chiplets/CUs; mechanisms for elastic repartitioning or hybrid splits are not presented.
- Latency vs. throughput trade-offs: Fleet’s gains are shown for latency; whether similar benefits hold at high-throughput regimes or for large batches with sophisticated cuBLAS-like tiling is unclear.
- Quantifying fence/atomic costs: The hierarchical event design is motivated qualitatively; no direct measurements isolate the overheads of buffer_wbl2 and sc0/sc1 atomics vs. L2-local operations.
- Multi-GPU/scale-out scenarios: How Fleet’s per-chiplet abstraction composes across multiple GPUs (NVLink/xGMI), with cross-device caches and network bandwidth, remains unexplored.
- Failure modes and deadlock/livelock: No analysis of edge cases in event-driven schedules (missed signals, queue overflow, scheduler starvation, or pathological task graphs).
- Security/isolation concerns: Chiplet-local caches and shared LLC raise questions about isolation in multi-tenant settings; Fleet’s implications for side channels or isolation are not discussed.
- Sensitivity across models and sizes: Results are mostly for Qwen3-8B; behavior for larger/smaller models, longer context lengths, mixture-of-experts, and encoder–decoder architectures is not provided.
- Preemption and context switching: Persistent kernels can be preempted; the impact on event counters, L2 state, and correctness after resumption is not addressed.
- Hardware feature dependency: Reliance on AMD-specific HW_ID and sc0/sc1/NT modifiers may limit portability; abstractions for cross-vendor support are not defined.
- End-to-end system evaluation: Integration with realistic serving stacks (scheduler, tokenizer, networking, batching policies) and tail-latency distributions is not shown; reported gains are kernel/device-centric.
Practical Applications
Overview
The paper introduces Fleet, a hierarchical, chiplet-aware task model and persistent-kernel runtime for multi-die GPUs. It exposes a new “Chiplet-task” abstraction that binds work and data to a chiplet’s private L2 cache and adds per-chiplet scheduling, cooperative tiling, and hierarchical synchronization. On AMD Instinct MI350 with Qwen3-8B, Fleet reduces per-token decode latency by 1.3–1.5× at batch sizes 1–8 versus vLLM, increases L2 hit rates substantially at larger batches (e.g., 12%→54% at bs=32), reduces HBM traffic by up to 37%, and delivers 1.27–1.30× speedups over a chiplet-unaware megakernel baseline.
Below are practical applications enabled by these findings, methods, and innovations.
Immediate Applications
These can be deployed now using current AMD MI300/MI350-class GPUs and ROCm/HIP toolchains.
- LLM inference acceleration in production serving stacks (software/cloud, finance, healthcare, education, contact centers)
- Use case: Integrate Fleet’s persistent-kernel runtime and chiplet-aware scheduling into inference frameworks (e.g., vLLM, SGLang, LMDeploy) to reduce per-token latency and HBM traffic for memory-bound decode.
- What to implement:
- Replace per-operator launches with a single persistent megakernel.
- Partition GEMM across chiplets (N-split) and use M-major traversal so workers on the same chiplet access the same weight tiles, converting L2 misses to hits.
- Fuse elementwise ops (e.g., SiLU) into GEMMs to keep intermediates in registers/LDS.
- Apply cache modifiers (e.g., streaming for weights, non-temporal for transient stores).
- Expected impact: 1.3–1.5× lower latency at bs=1–8; 1.27–1.30× speedups and up to 37% HBM traffic reduction at larger batches (bs=32–64).
- Dependencies/assumptions: AMD MI300/MI350 with private, non-coherent L2 per chiplet; ROCm/HIP ISA support for cache scope/NT bits; framework integration effort; persistent kernels may affect preemption/multi-tenancy.
- Cost and energy efficiency improvements for managed AI services (cloud, platforms)
- Use case: Offer Fleet-optimized AMD instances or managed endpoints with lower cost-per-token and lower energy per request due to reduced HBM bandwidth consumption.
- Tools/products/workflows: “FleetRT” runtime library packaged as a backend for popular serving frameworks; autoscaling tuned for deterministic latency across batch sizes.
- Dependencies/assumptions: Datacenter GPUs with multi-die topology; SRE policies accommodating persistent kernels; monitoring to track L2 hits/HBM bandwidth.
- On-prem/enterprise deployments needing strict latency SLAs (healthcare, finance, customer support)
- Use case: Real-time clinical note summarizers, financial copilots, voice/chat assistants with sub-10 ms per-token latency on AMD MI350 nodes.
- Workflow: Deploy Fleet-enabled inference services inside regulated environments to meet latency and data residency constraints.
- Dependencies/assumptions: HIP/ROCm availability on-prem; validation for regulated environments; latency gains most pronounced in memory-bound decode.
- Chiplet-aware BLAS/GEMM kernels and libraries (HPC, scientific computing, energy)
- Use case: Provide a ROCm/hipBLAS add-on that partitions large GEMMs across chiplets with cooperative tiling and hierarchical synchronization.
- Tools/products/workflows: A “chiplet-aware GEMM” library for batched GEMV/GEMM used by recommender systems, physics solvers, or scientific post-processing pipelines that are memory-bound.
- Dependencies/assumptions: Benefits strongest when weight-like operands dominate working set and L2 reuse can be coordinated; tuning for 4 MB L2 per chiplet.
- Compiler/runtime schedule templates (ML compilers)
- Use case: Add Fleet-like “Chiplet-task” schedules and hierarchical sync to TVM/Triton templates for AMD GPUs (e.g., an N-split template for decode GEMMs).
- Tools/products/workflows: Auto-schedule knobs for M-major traversal, device-vs-chiplet task granularity, and cache policies; dynamic selection based on batch size.
- Dependencies/assumptions: Backend access to ISA features (scope bits, buffer_wbl2); per-chiplet ID access for schedulers; correctness testing for hierarchical sync.
- Performance engineering and observability (devtools)
- Use case: Create profiling/monitoring tools that surface per-chiplet L2 hit rates, HBM traffic, and chiplet-task occupancy to validate locality strategies.
- Tools/products/workflows: “Fleet Profiler” plugin for rocprof/Perfetto/Grafana tracking L2/TCC metrics by XCD and kernel segment.
- Dependencies/assumptions: Availability of per-chiplet counters/telemetry; low overhead instrumentation.
- Teaching and curriculum content on chiplet-NUMA GPU programming (academia)
- Use case: Lab modules using Fleet concepts (chiplet tasks, cooperative L2 reuse, hierarchical synchronization) to teach modern multi-die GPU performance engineering.
- Dependencies/assumptions: Access to AMD multi-die GPUs in teaching labs; simplified examples (e.g., batched GEMV microbenchmarks).
Long-Term Applications
These require additional research, scaling, portability engineering, or ecosystem changes.
- Standardized chiplet-aware programming models and APIs (ecosystem/policy/standards)
- Use case: Extend CUDA/HIP/SYCL/OpenMP offload with chiplet-scoped tasks, locality hints, and memory scope controls to make chiplet-awareness portable.
- Potential outcomes: API-level “chiplet group” abstractions, per-chiplet synchronization primitives, and standard cache modifier policies.
- Dependencies/assumptions: Vendor and standards-body buy-in; specification and conformance tests; cross-vendor architectural differences (coherent vs. private L2).
- Porting Fleet concepts to other vendors and architectures (software/hardware co-design)
- Use case: Adapt Chiplet-task scheduling to NVIDIA Blackwell (dual-die with globally coherent L2) and future multi-die parts across vendors.
- Expected changes: Different coherence semantics, cache sizes, and per-die latencies; need to tune traversal and synchronization strategies to architecture.
- Dependencies/assumptions: Access to low-level scope controls; profiling hooks for per-die metrics; potential smaller gains with globally coherent L2.
- Automatic task graph partitioning and autotuning in ML compilers (software/ML systems)
- Use case: Integrate auto-partitioners into TVM, PyTorch Inductor, or XLA that map ops to wavefront/CU/Chiplet/Device tasks based on working set and batch size.
- Products/workflows: Learned cost models exploring N-split vs. K-split hybrids, fusion opportunities, and cache policy assignments per op and batch regime.
- Dependencies/assumptions: Robust hardware models for multi-die NUMA effects; generalization across models; training data for cost models.
- Training and multi-GPU/cluster extensions (HPC/AI training)
- Use case: Apply hierarchical tasks to training loops (e.g., optimizer updates, KV cache writes, activation checkpointing) and across devices (per-GPU tasks with NVLink/IF-aware partitioning).
- Workflows: Cluster-level “Device-task” composition to coordinate per-GPU chiplet tasks, reducing interconnect pressure for memory-bound phases.
- Dependencies/assumptions: More complex dependency graphs; interaction with distributed training paradigms (TP/PP/FSDP); careful overlap of comm/compute.
- Datacenter scheduling and multi-tenancy integration (cloud/platforms)
- Use case: K8s/NVML/ROCm operators that recognize persistent, chiplet-aware megakernels and schedule tenants to reduce cross-chiplet interference and maintain fairness.
- Products/workflows: “Chiplet-aware GPU Operator” that controls residency, time-slicing, and isolation; SLA-aware admission control for persistent kernels.
- Dependencies/assumptions: OS/driver-level support for chiplet partitioning; preemption-friendly megakernel designs; telemetry for fairness and isolation.
- Hardware/firmware features co-designed with Fleet-like runtimes (hardware vendors)
- Use case: Hardware support for per-chiplet dispatch queues, fast in-silicon chiplet barriers, and programmable cache policies per access class.
- Outcomes: Lower-latency cross-chiplet synchronization, reduced need for explicit fences (buffer_wbl2), and improved programmability for locality.
- Dependencies/assumptions: Silicon changes across generations; verification effort; balance with general-purpose programming models.
- Sector-specific low-latency applications beyond LLMs (robotics, autonomous systems, AR/VR, healthcare)
- Use cases:
- Robotics/autonomy: On-robot multi-die accelerators running real-time language/vision models with chiplet-locality scheduling for deterministic latency.
- AR/VR and gaming AI: Lower-latency on-device assistants or NPC reasoning on multi-die GPUs.
- Healthcare imaging and decision support: Memory-bound post-processing kernels (e.g., certain transforms) scheduled chiplet-locally for lower turnaround time.
- Dependencies/assumptions: Availability of multi-die accelerators in edge/embedded form factors; model/operator mapping to memory-bound patterns.
- Sustainability and public-sector procurement policies (policy)
- Use case: Include chiplet-aware optimization requirements or incentives in “green AI” guidelines and public-sector RFPs to reduce datacenter energy (via lower HBM traffic).
- Dependencies/assumptions: Clear, auditable metrics (e.g., per-token energy); vendor-neutral guidance; training for procurement and compliance teams.
Notes on feasibility across items:
- Gains depend on memory-bound phases (e.g., LLM decode); compute-bound workloads may see limited benefit.
- Batch-size regime matters: persistent-kernel/scheduling reduces overhead at small batches; cooperative L2 reuse increases importance at moderate batches; K-split GEMMs may dominate at very large batches.
- Persistent kernels can complicate preemption, sharing, and debugging; productionization requires careful ops integration.
- Low-level cache scope/NT controls and fences are currently vendor-specific; broad portability requires standardization.
Glossary
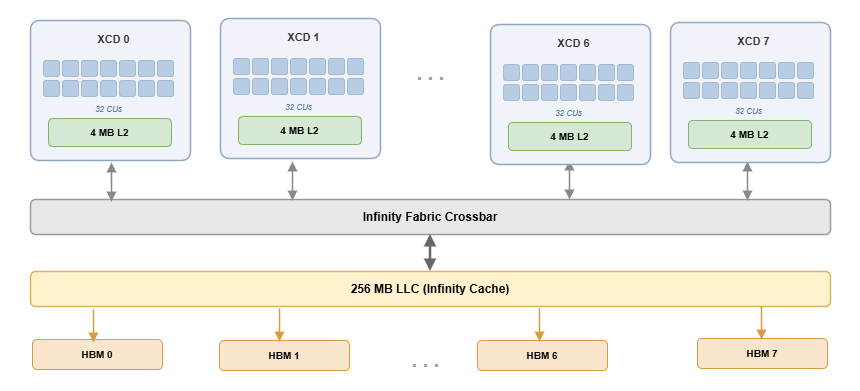
- Accelerator Complex Die (XCD): A chiplet die used in AMD GPUs that integrates multiple compute units and a private L2 cache. "eight XCDs (Accelerator Complex Dies)"
- bf16: A 16-bit floating-point format (bfloat16) commonly used in deep learning to reduce memory bandwidth while maintaining range. "in bf16"
- buffer_wbl2: An AMD GPU ISA instruction that writes back dirty L2 cache lines to make data visible across chiplets. "the producer must issue buffer_wbl2 to write back dirty L2 lines"
- cache-streaming: A cache allocation policy that allows short-lived reuse and prioritizes eviction of streamed lines; on AMD set via sc1=1, nt=1. "cache-streaming (sc1=1, nt=1)"
- chiplet: A separate silicon die within a multi-die GPU package that has its own local resources and caches. "binds work and data to a chiplet"
- chiplet swizzling: A platform-specific technique to remap or distribute data/work across chiplets for locality or balance. "chiplet swizzling"
- Chiplet-task: A Fleet task type that spans all workers on a single chiplet to coordinate via its shared L2. "Chiplet-tasks, a new abstraction"
- Coherent_Cache_Bypass: An AMD L2 cache policy that ensures cross-chiplet visibility by bypassing or writing back modified lines before reissuing reads. "Coherent_Cache_Bypass policy"
- Compute Unit (CU): A GPU execution block that runs workgroups and provides L1/LDS resources. "32 CUs per XCD"
- CUDA/HIP: GPU programming models from NVIDIA and AMD, respectively, that define threads, workgroups, and grids. "The CUDA/HIP programming model was designed for monolithic GPUs"
- CUDA/HIP graph capture: A mechanism to record and replay sequences of GPU kernels to reduce launch overhead. "CUDA and HIP graph capture"
- CU-task: A Fleet task type that occupies a single compute unit and uses LDS/L2 for intra-task data. "CU-tasks occupy a single compute unit"
- Device-task: A Fleet task that coordinates all chiplets on a device, completing only when all chiplet subtasks finish. "a device-task, comprised of eight Chiplet-tasks"
- flat_atomic_add: An AMD GPU atomic operation used here with GPU-scope to update global counters across chiplets. "flat_atomic_add with sc0 sc1"
- GEMM: General Matrix-Matrix Multiply, the core linear algebra operation in neural network layers. "For an [M,K] * [K,N] GEMM"
- GEMV: General Matrix-Vector Multiply; batched forms appear in decode workloads. "Optimizing Batched GEMV"
- HBM: High Bandwidth Memory attached to the GPU package, providing very high throughput to device DRAM. "reducing HBM traffic by up to 37\%"
- Infinity Cache: AMD’s large on-package last-level cache shared across chiplets (also called MALL). "MALL (Infinity Cache)"
- Infinity Fabric: AMD’s on-package interconnect that links chiplets and I/O dies. "traverses the Infinity Fabric to the IO die"
- IO die: A die in the GPU package that routes memory and coherence traffic between chiplets and HBM. "to the IO die"
- K-split: A GEMM partitioning strategy that splits along the reduction (K) dimension, requiring partial-result reductions. "An alternative strategy partitions the reduction dimension (K-split)"
- KV cache: The key–value cache holding past attention states for efficient autoregressive decoding. "KV cache"
- last-level cache (LLC): The largest on-package cache level before HBM; on AMD GPUs this is the Infinity Cache. "last-level cache (LLC)"
- L2 cache: A mid-level on-chip cache; on chiplet GPUs it is partitioned and private to each chiplet. "a private 4\,MB L2 cache (TCC)"
- LDS (Local Data Share): On-chip shared memory per CU used for fast intra-workgroup communication. "using registers and LDS"
- megakernel: A single, large persistent kernel that fuses many operators to reduce launch overhead and enable data reuse. "chiplet-unaware megakernel baseline"
- Mirage Persistent Kernel: A system for building persistent kernels that Fleet extends with chiplet-aware features. "extends the Mirage Persistent Kernel system"
- M-major traversal: A tile traversal order that advances primarily along the M (batch/row) dimension to improve weight reuse in L2. "windowed M-major traversal"
- M-split traversal: A strategy assigning disjoint M-tiles to chiplets so each works on different rows without cooperative weight reuse. "M-split traversal."
- multi-die: A GPU packaging style that integrates multiple dies (chiplets) in one package for scalability. "multi-die designs"
- non-temporal (NT): A memory access modifier indicating data should bypass or minimally use cache because it has little reuse. "non-temporal bit (NT)"
- N-major ordering: A tile traversal that advances along the N (column) dimension; here it reduces L2 reuse across workers. "N-major ordering were used instead"
- N-split: A GEMM partitioning strategy that splits the output columns across chiplets, avoiding cross-chiplet reductions. "Fleet partitions GEMM output columns across XCDs (N-split)"
- NUMA-like: Refers to non-uniform memory access effects within a single device due to chiplet-local caches. "introduces NUMA-like programming effects"
- persistent kernel: A kernel that stays resident on the GPU to execute many operations/tasks, amortizing launch costs. "persistent kernel programming"
- RoPE: Rotary positional embeddings, an attention mechanism component for encoding relative positions. "RoPE"
- RMSNorm: Root Mean Square Layer Normalization, a normalization technique used in many transformer models. "RMSNorm"
- SC1/SC0: AMD instruction bits that set the coherence scope (e.g., wave, group, device, system) for memory operations. "two scope bits (SC1, SC0)"
- split-K GEMM: A GEMM technique that splits along K and later reduces partial results, often used to improve parallelism. "split-K GEMM"
- TCC: AMD’s L2 cache controller block; here used to denote the per-chiplet L2. "a private 4\,MB L2 cache (TCC)"
- threadfence: A GPU memory fence that ensures prior writes are visible before proceeding, used before cross-chiplet signaling. "issues a single threadfence"
- wavefront: The SIMD execution grouping on AMD GPUs (typically 64 threads) analogous to a warp. "a single wavefront (64 threads on AMD)"
- wavefront-task: A Fleet task type that runs within one wavefront for fine-grained, element-wise operations. "wavefront-tasks operate within a single wavefront"
Collections
Sign up for free to add this paper to one or more collections.