Benchmarking Optimizers for MLPs in Tabular Deep Learning
Abstract: MLP is a heavily used backbone in modern deep learning (DL) architectures for supervised learning on tabular data, and AdamW is the go-to optimizer used to train tabular DL models. Unlike architecture design, however, the choice of optimizer for tabular DL has not been examined systematically, despite new optimizers showing promise in other domains. To fill this gap, we benchmark \Noptimizers optimizers on \Ndatasets tabular datasets for training MLP-based models in the standard supervised learning setting under a shared experiment protocol. Our main finding is that the Muon optimizer consistently outperforms AdamW, and thus should be considered a strong and practical choice for practitioners and researchers, if the associated training efficiency overhead is affordable. Additionally, we find exponential moving average of model weights to be a simple yet effective technique that improves AdamW on vanilla MLPs, though its effect is less consistent across model variants.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
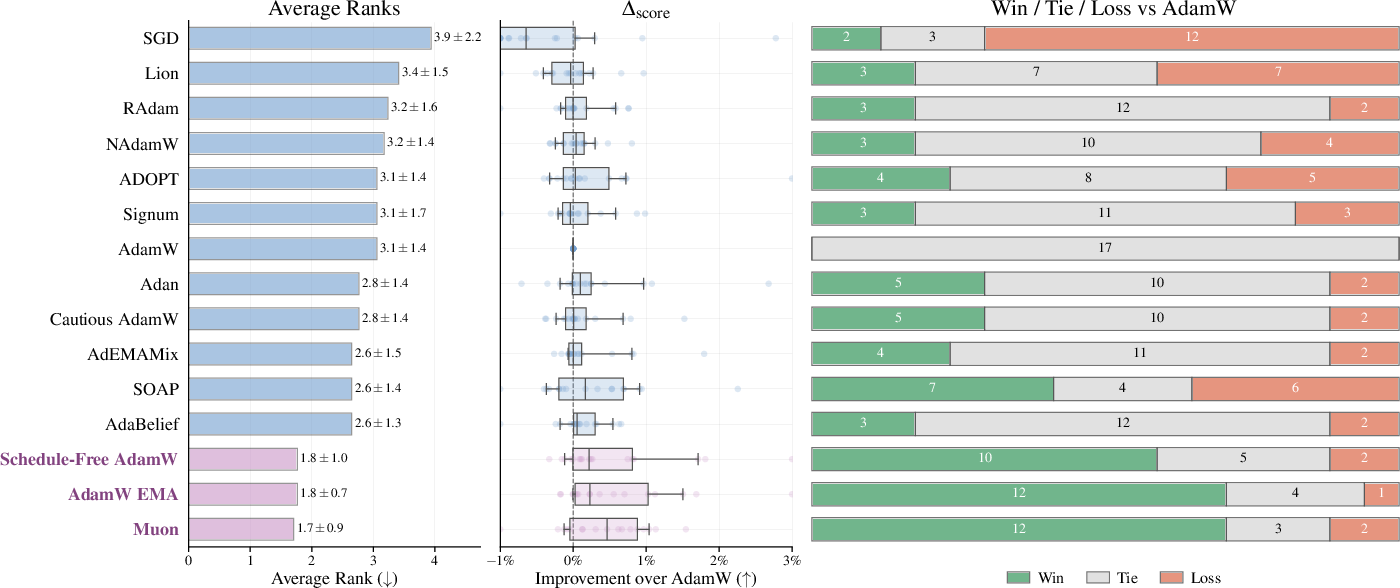
This paper asks a simple question: when training neural networks on spreadsheet-like data (called “tabular data”), which training method works best? The authors focus on training multi-layer perceptrons (MLPs), a very common type of neural network, and compare many “optimizers” (the rules that adjust a model’s weights to learn). The usual choice is an optimizer called AdamW. The paper carefully tests 15 different optimizers on 17 datasets to see if anything beats AdamW.
What the researchers wanted to find out
The authors set out to answer a few practical questions:
- Is AdamW still the best default optimizer for tabular deep learning with MLPs?
- Do newer optimizers (especially one called Muon) actually help on real tabular datasets?
- Do simple tricks like EMA (Exponential Moving Average of model weights) make a noticeable difference?
- Do the best optimizer choices for a plain MLP also help newer MLP-based models?
How they tested their ideas
Here’s the approach in everyday terms:
- Tabular data = spreadsheets: Think of rows as examples and columns as features (like age, price, or category). This is different from images or text.
- MLPs = layered calculators: An MLP is a stack of simple math layers that learns patterns from data.
- Optimizers = learning strategies: An optimizer tells the model how big a step to take and in what direction to improve its predictions after each batch of data.
What they did:
- They picked 17 real datasets (some for classification, some for regression) and several MLP-based models, from a plain MLP to stronger modern versions.
- They compared 15 optimizers. These included familiar choices (AdamW, SGD) and newer ones (like Muon), plus techniques like EMA (which keeps a running “smoothed” copy of the model’s weights) and “Schedule-Free” training (which tries to get the benefits of learning-rate schedules without predefining training length).
- Fairness matters: For each dataset and model, they tuned hyperparameters (like learning rate) separately for each optimizer using the same search budget. They used early stopping (stop training when the model stops improving on a validation set) and then reported final performance on a held-out test set (to measure real generalization).
- They repeated training with different random seeds to make results more reliable, then summarized performance across datasets using ranks, relative improvements, and win/tie/loss counts compared to AdamW.
A quick analogy for EMA: imagine you take a test every day. Your “current” score may jump around, but your “average of recent scores” is steadier. EMA does something like that with model weights—keeping a smooth, averaged version that often generalizes better.
What they discovered
Here are the main takeaways:
- Muon is the most consistently strong optimizer: Across 17 datasets, Muon usually beats AdamW for both plain MLPs and more advanced MLP-based models. In other words, if you just want better accuracy or lower error, Muon is a great bet.
- There’s a trade-off: Muon is slower to tune and train (about 3× more time on average in their setup) than AdamW.
- EMA helps plain MLPs with AdamW: Adding EMA to AdamW is a simple change that often gives a solid boost on a basic MLP. However, for more advanced MLP-based models, EMA’s benefits are smaller and less consistent.
- Schedule-Free AdamW also does well: It often outperforms baseline AdamW without needing a preset training schedule.
- Strong across architectures: Muon wasn’t just good for the plain MLP; it remained a top choice for newer, stronger MLP-based architectures too.
Why this matters: On tabular problems, the goal is usually “generalization” (doing well on new, unseen data). The paper shows that optimizer choice can meaningfully affect that goal—and that newer choices can beat the default.
What this means going forward
- If you can afford more training time, try Muon: It’s a strong, practical choice for tabular deep learning with MLPs.
- If you need something simple and faster, try AdamW + EMA on plain MLPs: It’s easy to add and often helps.
- Optimizer choice is not one-size-fits-all: While AdamW has been the default, this study shows you can often do better—especially with Muon—when working with tabular data.
- Future work: The paper is empirical (based on experiments), so a next step is understanding why Muon helps in this setting, and testing beyond MLPs or in larger “foundation model” setups for tabular data.
In short: For training MLPs on spreadsheet-like data, Muon tends to give better results than the usual AdamW, though it takes longer. If you’re sticking with AdamW on a basic MLP, adding EMA is an easy way to get a boost.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following points unresolved; each item is formulated to enable targeted follow-up studies.
- Transfer beyond MLP-based architectures: Do the reported optimizer rankings (e.g., Muon > AdamW) hold for non-MLP tabular models such as SAINT/TabTransformer/TabNet, retrieval-augmented models (e.g., TabR), neural additive models (NAM/NODE-GAM), or hybrid neural–tree methods?
- Tabular foundation models and fine-tuning: How do optimizers compare in pretraining and in-context learning setups (e.g., TabPFN, TabICLv2), and during downstream fine-tuning with limited labeled data?
- Compute- and budget-constrained regimes: Under fixed wall-clock, energy, or trial budgets (rather than equal trial counts), does Muon still dominate in accuracy/ROC-AUC? What are the speed–accuracy Pareto frontiers per optimizer on CPU-only, single-GPU, and multi-GPU hardware?
- Resource profiling: What are the per-step latency, memory footprint, and numerical stability differences (fp32 vs bf16/fp16) across optimizers and architectures? Are there memory bottlenecks or AMP-related instabilities specific to Muon or SOAP?
- Hyperparameter robustness and defaults: How sensitive are optimizers to search-space design, sampler choice, and tuning budget? Can robust, dataset-agnostic default hyperparameters be proposed for Muon/EMA that retain most gains with minimal tuning?
- Early stopping interactions: Does the reliance on early stopping (patience 16) bias against optimizers whose gains emerge later? How do results change with different patience values, no early stopping, or longer horizons?
- Learning-rate scheduling: The study eschews schedulers (except Schedule-Free AdamW). How do standard schedules (cosine, warm restarts, step decay) affect each optimizer under early stopping, and do rankings change with schedule usage?
- Weight averaging variants and combinations: Beyond EMA, how do SWA, Polyak averaging, Lookahead, and EMA+SWA hybrids compare on tabular MLPs? Do these techniques consistently help Muon or stronger architectures (TabM, TabM†)?
- Batch size and gradient clipping: The paper fixes dataset-specific batch sizes and uses global clipping at 1.0. What is the optimizer–batch-size interaction surface, and how do different clipping schemes (per-layer, adaptive thresholds) alter outcomes?
- Weight decay and parameter-wise settings: How do decoupled vs coupled L2 penalties, and exclusions (e.g., no decay on biases/embeddings), impact the relative performance of Muon vs AdamW on tabular tasks?
- Dataset characteristic analysis: Which dataset properties (size, feature mix categorical/numeric, cardinality, missingness, label noise, class imbalance, temporal drift) predict when Muon or EMA provides the largest gains? Can a meta-policy be learned for optimizer selection?
- Robustness to noise and outliers: Under controlled synthetic and real noise injections, which optimizers maintain performance? Do robust losses (Huber, MAE, quantile) change optimizer rankings?
- Stability across seeds and failure modes: Which optimizers have lower variance across seeds, fewer catastrophic runs, or more consistent convergence behavior? Provide variance/CI comparisons and failure case analyses.
- Metrics beyond accuracy/ROC-AUC/RMSE: How do optimizers affect calibration (ECE/Brier), AUCPR on imbalanced data, ranking losses (NDCG), or business KPIs relevant to tabular applications?
- Data splitting protocols: Do conclusions hold under k-fold cross-validation, multiple random splits, or alternative temporal splits, especially on smaller datasets where a single split may be brittle?
- OOD generalization and drift: Under covariate/label shift and temporal drift scenarios, do optimizer choices materially affect robustness and degradation rates?
- Scaling studies: Do results persist for much larger tabular datasets and deeper/wider MLPs, and with architectural variants (residual MLPs, different activations like GELU/SELU, normalization layers)?
- Interaction with regularization: How do dropout rates, label smoothing, MixUp/CutMix-for-tabular, stochastic depth, or feature noise interact with optimizer choice?
- Broader optimizer coverage: Evaluate additional contenders (e.g., Sophia, LAMB, AdaFactor, Adafactor+schedule-free, K-FAC/Adahessian, full Shampoo/distributed Shampoo) to map the accuracy–efficiency trade space more completely.
- Differential privacy and constraints: In DP-SGD or fairness-constrained training, do the relative benefits of Muon/EMA persist?
- Reproducibility across frameworks: Are results consistent across PyTorch/JAX/TensorFlow implementations of Muon and others, including fused kernels and numerical details?
- Mechanistic understanding: Why does Muon help on tabular MLPs? Analyze sharpness/flatness (e.g., SAM-style measures), spectral norms/Lipschitz constants, curvature proxies, gradient noise scale, and weight trajectory geometry to connect gains to theory.
- Practical guidance: Provide actionable defaults and decision rules for practitioners (when to pick Muon vs AdamW+EMA, expected slowdown, tuning knobs to try first, fallback options when compute is tight).
- Inference-time implications: Quantify whether EMA or other averaging strategies affect deployment (checkpoint size management, latency due to frequent EMA swaps, or compatibility with quantization/pruning).
Practical Applications
The paper benchmarks 15 optimizers across 17 tabular datasets for MLP-based models and finds that Muon consistently outperforms AdamW on generalization, albeit with an average ~3× tuning-time slowdown, while AdamW+EMA gives a simple, low-overhead improvement—especially for plain MLPs. Below are practical applications derived from these findings and the unified training/tuning protocol.
Immediate Applications
- Industry (software/MLOps, cross-sector): Update tabular DL training recipes to include Muon and AdamW+EMA
- What to do:
- Make Muon the default optimizer for tabular MLPs when training compute is available; retain AdamW+EMA as a strong, low-overhead fallback.
- Adopt the paper’s protocol: early stopping on validation, test-set reporting, gradient clipping, schedule-free where applicable, Optuna-based joint tuning.
- Sectors: finance (credit scoring, fraud), healthcare (readmission/mortality risk), retail (churn/CLV), insurance (underwriting), energy (load forecasting), manufacturing (quality/yield).
- Potential tools/workflows:
- Integrate Muon and EMA callbacks into PyTorch/Lightning pipelines; reuse the public code repo (https://github.com/yandex-research/tabular-dl-optimizers).
- Provide a training “optimizer toggle” in internal libraries, with telemetry on accuracy, training time, and cost.
- Assumptions/dependencies: Gains are shown for MLP-based tabular models; expect ~3× tuning cost for Muon (and ~1.3× for AdamW+EMA) vs AdamW; ensure Muon implementation availability/compatibility in your stack.
- AutoML and benchmarking platforms (software): Add Muon and AdamW+EMA as first-class options
- What to do:
- Extend AutoGluon/H2O and internal AutoML systems to try AdamW, AdamW+EMA, and Muon, with compute-aware selection (e.g., prefer EMA under tight budgets).
- Adopt the study’s early-stopping and test-set evaluation protocols and its statistical reporting (ranks, win/tie/loss via Welch’s t-test).
- Potential products: “Optimizer Advisor” that runs small pilot sweeps and recommends AdamW+EMA vs Muon based on accuracy-per-compute.
- Assumptions/dependencies: Requires Optuna or equivalent HPO integration; budget constraints and SLAs may limit Muon sweeps.
- MLOps/DevOps (software): CI/CD gates and dashboards for accuracy–compute trade-offs
- What to do:
- Add CI experiments that compare AdamW, AdamW+EMA, and Muon before major releases; track test-set deltas and training-time multipliers.
- Implement gradient clipping (1.0), schedule-free variants where applicable, and dataset-specific batch sizes as configurable defaults.
- Assumptions/dependencies: Reliable dataset splits and seed management; additional CI time/cost.
- Academic research (academia): Update baselines and protocols for tabular MLP studies
- What to do:
- Include Muon as a strong baseline and report AdamW+EMA for completeness.
- Use the paper’s unified evaluation protocol: early stopping for tuning, final test-set metrics over 10 seeds, aggregated ranks, Δscore, and win/tie/loss.
- Assumptions/dependencies: Focus remains on supervised tabular MLPs; results may not transfer to non-MLP or foundation-model settings.
- Data science practice and competitions (daily life/education): Quick-win recipes
- What to do:
- For Kaggle/competitions or internal POCs: try AdamW+EMA for a quick gain with minimal overhead; use Muon if you can afford longer tuning.
- Reuse the repo’s training scripts; adopt early stopping and gradient clipping by default.
- Assumptions/dependencies: Compute budget and run-time constraints; ensure correct metrics (e.g., ROC-AUC for imbalanced/binary tasks).
- Governance and model documentation (policy/industry compliance): Report optimizer choices and compute costs
- What to do:
- Document optimizer selection, early stopping criteria, test-set performance, and the accuracy–compute trade-off in model cards and validation reports.
- Assumptions/dependencies: Organizational policies must recognize compute-overhead trade-offs; regulator expectations may vary by domain.
Long-Term Applications
- High-efficiency Muon implementations (software/compute): Reduce the 3× tuning overhead
- What to build:
- Optimized kernels and distributed implementations for Muon (multi-GPU, CPU-efficient paths), possibly fused ops in PyTorch 2.
- Budget-aware HPO that allocates trials adaptively based on optimizer speed and learning curves.
- Sectors: cloud ML services, enterprise MLOps platforms.
- Assumptions/dependencies: Engineering effort; upstream framework support; benchmarking to validate speedups without losing gains.
- Optimizer-aware AutoML and meta-learning (software/academia): Data- and budget-adaptive optimizer selection
- What to build:
- A meta-learner that predicts when Muon vs AdamW+EMA is best given dataset size, noise, feature mix, and compute constraints.
- Early-exit strategies that stop exploring Muon if marginal gains are unlikely under budget.
- Assumptions/dependencies: Requires large meta-datasets and generalizable meta-features; stability across domains.
- Extension beyond MLPs (academia/industry): Evaluate in foundation models and non-MLP tabular paradigms
- What to explore:
- Assess Muon and EMA effects in tabular foundation models (e.g., TabPFN/TabICL), retrieval-augmented methods, and hybrid NN–trees approaches.
- Assumptions/dependencies: The paper’s scope is MLP-based supervised learning; transferability is uncertain and needs empirical study.
- Theory-informed training recipes (academia): Understand why Muon helps generalization in tabular data
- What to explore:
- Connections between Muon’s preconditioning and stability/generalization (e.g., Lipschitz bounds, margin, noise robustness).
- Principled combinations of schedule-free training and weight averaging tailored to tabular regimes.
- Assumptions/dependencies: Requires new theoretical and empirical analyses; outcomes may suggest new optimizers.
- Energy- and carbon-aware training policies (energy/policy/industry): Optimize accuracy per joule
- What to build:
- Policies and tooling that select optimizers by accuracy-per-compute/per-carbon, factoring Muon’s overhead vs accuracy gains.
- Dashboards for sustainability reporting that include optimizer choices and early-stopping savings.
- Assumptions/dependencies: Access to accurate energy metering; organizational incentives for green ML.
- Regulatory and standards development (policy): Benchmarking and reporting standards for tabular ML
- What to codify:
- Standards that require test-set evaluation after early stopping, multiple seeds, and statistical significance reporting for optimizer comparisons.
- Guidance for documenting optimizer-induced trade-offs in regulated sectors (healthcare, finance, insurance).
- Assumptions/dependencies: Multi-stakeholder consensus; alignment with existing AI governance frameworks.
- Productized “Optimizer Advisor” services (software/cloud): Self-serve optimizer benchmarking
- What to build:
- Managed cloud services that pilot-train with AdamW, AdamW+EMA, and Muon on user datasets, then recommend a recipe with expected accuracy and training time.
- Sectors: SMBs without in-house ML ops, enterprise data platforms.
- Assumptions/dependencies: Data privacy/sovereignty; cost models for pilot trials; integration with user MLOps stacks.
- Robustness and fairness audits (healthcare/finance/public sector): Optimizer as a factor in audit pipelines
- What to do:
- Include optimizer choice in fairness/robustness sensitivity analyses; verify that improved generalization does not degrade subgroup performance.
- Assumptions/dependencies: Requires access to subgroup labels and robust evaluation tooling; may need domain-specific constraints.
Notes on dependencies shared across applications:
- Scope limits: Evidence covers MLP-based architectures on supervised tabular tasks; results may not hold for trees, CV/NLP domains, or non-MLP tabular methods.
- Compute budgets: Muon’s average ~3× tuning-time overhead vs AdamW, and ~1.29× for AdamW+EMA, can be material in production; plan budgets accordingly.
- Implementation availability: Ensure Muon and EMA implementations are correct, maintained, and compatible (e.g., with PyTorch 2 and your training stack).
- Evaluation protocol: Gains rely on early stopping and test-set evaluation with multiple seeds; departures from this protocol may change outcomes.
Glossary
- AdaBelief: An Adam-family optimizer that adjusts second-moment estimation to improve stability and generalization. "AdaBelief \citep{zhuang2020adabelief}"
- AdamW: A widely used Adam variant that decouples weight decay from the optimization step. "AdamW is the go-to optimizer used to train tabular DL models."
- ADOPT: An Adam-family optimizer variant that modifies momentum/adaptive updates to improve training dynamics. "ADOPT \citep{taniguchi2024adopt}"
- Adan: An adaptive optimizer that integrates Nesterov momentum into an Adam-like scheme for faster convergence. "Adan \citep{xie2024adan}"
- AdEMAMix: An Adam-style optimizer that mixes parameter averages into the update rule to enhance performance. "AdEMAMix \citep{pagliardini2025the}"
- AlgoPerf benchmark: A standardized evaluation suite comparing optimizers and training strategies across workloads. "the recent AlgoPerf benchmark \citep{kasimbeg2025accelerating} showed that carefully tuned alternatives can outperform strong AdamW baselines across multiple training workloads."
- EMA (Exponential Moving Average): A technique that maintains a smoothed average of model weights over training steps to improve generalization. "We also highlight exponential moving average (EMA) of model weights as a simple way to improve AdamW \citep{loshchilov2018decoupled} for vanilla tabular MLPs."
- Global gradient clipping: A stabilization technique that rescales gradients when their global norm exceeds a threshold. "We apply global gradient clipping with threshold $1.0$"
- Implicit Neural Representations: Neural models that represent signals (e.g., images, 3D shapes) as continuous functions parameterized by networks. "Muon \citep{jordan2024muon} has recently emerged as a strong new optimizer with promising empirical results across several domains ranging from LLM training \citep{modded_nanogpt_2024, liu2025muon} to Implicit Neural Representations \citep{mcginnis2025optimizing} and Information Retrieval \citep{takehi2025fantastic}."
- In-context-learning-based foundation models: Large pre-trained models that perform tasks by conditioning on examples within the input context rather than updating weights. "The other direction studies in-context-learning-based foundation models \citep{grinsztajn2025tabpfn,qu2026tabiclv2}."
- Lion: A sign-based optimizer that updates parameters using only the sign of the gradients (and momentum), reducing sensitivity to gradient magnitude. "sign-based methods such as Lion \citep{chen2023symbolic} and Signum \citep{bernstein2018signsgd}"
- Muon: A modern optimizer for neural networks that often improves generalization over AdamW in practice. "Our main finding is that the Muon optimizer consistently outperforms AdamW, and thus should be considered a strong and practical choice for practitioners and researchers, if the associated training efficiency overhead is affordable."
- NAdamW: An AdamW variant incorporating Nesterov momentum to potentially improve optimization speed. "NAdamW \citep{dozat2016incorporating}"
- Optuna: A hyperparameter optimization framework for automated tuning. "we tune hyperparameters with Optuna using the TPE sampler \citep{akiba2019optuna}"
- Parameter-efficient ensemble: An ensemble design that reuses or shares parameters to gain ensemble benefits at lower computational cost. "TabM (a parameter-efficient ensemble of MLPs from \citet{gorishniy2025tabm})."
- Piecewise-linear embeddings: Learned transformations that map numerical features via piecewise-linear functions to improve model expressivity. "piecewise-linear embeddings for numeric features"
- RAdam: Rectified Adam; an Adam variant that stabilizes the variance of adaptive learning rates, especially early in training. "RAdam \citep{liu2019radam}"
- ROC-AUC: Area under the Receiver Operating Characteristic curve; a threshold-independent classification performance metric. "we follow the original paper and report ROC-AUC."
- RMSE: Root Mean Squared Error; a regression metric measuring the square root of the average squared difference between predictions and true values. "For regression, we report RMSE."
- Schedule-Free AdamW: An AdamW variant designed to avoid predefined learning-rate schedules by adapting updates automatically. "We also include Schedule-Free AdamW \citep{defazio2024road} and AdamW with Exponential Moving Averaging (EMA) of model weights."
- Shampoo: A second-order optimizer that applies structured preconditioning using per-dimension (matrix/tensor) statistics. "structured preconditioning methods such as Shampoo \citep{gupta2018shampoo} or SOAP \citep{vyas2025soap}."
- Signum: A sign-based optimizer that updates parameters with the sign of momentum-averaged gradients. "Lion \citep{chen2023symbolic} and Signum \citep{bernstein2018signsgd}"
- SOAP: An optimizer that combines Shampoo’s preconditioning with Adam-like updates to improve stability in language modeling. "SOAP \citep{vyas2025soap}"
- TabM: A state-of-the-art tabular model family based on MLPs, constructed as a parameter-efficient ensemble. "We consider multiple TabM variants: TabM, TabM (TabM with feature embeddings, similarly to ), and TabM$_{\mathrm{Packed}$ (a TabM variant without weight sharing)."
- TabM: A TabM variant that augments the base with feature embeddings for improved representation. "TabM (TabM with feature embeddings, similarly to )"
- TabM$_{\mathrm{Packed}$: A TabM architecture variant that removes weight sharing (the “Packed” configuration). "TabM$_{\mathrm{Packed}$ (a TabM variant without weight sharing)"
- TabReD: A benchmark of industrial tabular datasets with standardized preprocessing and time-aware splits. "For the TabReD datasets, we use the official benchmark preprocessing and temporal splits from \citet{rubachev2025tabred}."
- Temporal splits: Dataset partitions that respect chronological order to better reflect real-world deployment scenarios. "we use the official benchmark preprocessing and temporal splits from \citet{rubachev2025tabred}."
- TPE sampler: Tree-structured Parzen Estimator; a Bayesian optimization method for sampling promising hyperparameters. "we tune hyperparameters with Optuna using the TPE sampler \citep{akiba2019optuna}"
- Welch's t-test: A statistical test for comparing means of two groups with possibly unequal variances. "A win or loss is defined by Welch's -test on the 10 seed-level test scores at significance level "
Collections
Sign up for free to add this paper to one or more collections.

